




Metaがテキストと音声の入出力を統合できる初のオープンソースマルチモーダル言語モデル「Spirit LM」をリリース

Metaが2024年10月18日に、テキストと音声の両方を入力可能で、感情表現を伴う音声出力も可能なAIモデル「Spirit LM」をリリースしました。
SPIRIT-LM: Interleaved Spoken and Written Language Model
(PDFファイル)https://arxiv.org/pdf/2402.05755
Sharing new research, models, and datasets from Meta FAIR
https://ai.meta.com/blog/fair-news-segment-anything-2-1-meta-spirit-lm-layer-skip-salsa-lingua/

Spirit LM Interleaved Spoken and Written Language Model
https://speechbot.github.io/spiritlm/
Open science is how we continue to push technology forward and today at Meta FAIR we’re sharing eight new AI research artifacts including new models, datasets and code to inspire innovation in the community. More in the video from @jpineau1.
— AI at Meta (@AIatMeta) October 18, 2024
This work is another important step… pic.twitter.com/o43wgMZmzK
MetaのFundamental AI Research(FAIR)チームは2024年10月18日に、高度な機械知能(AMI)の実現に向けた最新の研究結果と新たなAIモデルを公開し、画像や動画のセグメンテーションモデル「Segment Anything Model 2(SAM 2)」の更新版である「Segment Anything Model 2.1(SAM 2.1)」をリリースしたことや、ポスト量子暗号標準の安全性研究に必要なコード「SALSA」を共有したことなどを報告しています。
その中でMetaは、音声とテキストをシームレスに統合できるオープンソース言語モデルの「Spirit LM」を発表しました。Metaによると、従来の「音声で会話できるAI」は入力された音声を自動音声認識(ASR)によって文字起こしし、文字起こしデータをもとに大規模言語モデルでテキストを生成し、最終的にテキスト読み上げソフトウェア(TTS)を用いて音声に変換しているとのこと。しかし、従来のプロセスでは生成される音声の表現的側面が損なわれてしまいます。Metaが新たに開発したSpirit LMは、テキストと音声を1つのモデルで処理可能で、ASRにおりょう文字起こしやTTSによる音声変換を介さずに音声での会話を可能としています。
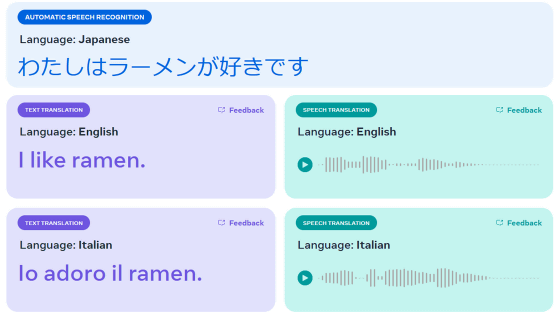
Spirit LMを実際に使用した際のデモは次の通り。以下の例では人間による「1 2 3 4 5」というテキストの入力に対し、Spirit LMは後に続く数字を音声で出力しています。
さらに、「The largest country in the world is(世界最大の国は)」というテキストプロンプトに対し、Spirit LMは詳細な情報を含めた音声を出力することも可能です。
また、与えられたプロンプトをもとに、まるで人間のような感情表現を含んだ音声を生成することもできます。以下は「I can't believe she's gone. I don't know how to cope without her. The pain of losing her is overwhelming. I feel so lost without her(彼女がいなくなってしまったなんて信じられません。彼女なしではどう生きていけばいいのかわかりません。彼女を失った痛みはとても大きく、私には何も残されていません)」というテキストプロンプトに続く音声。
「Did you hear that? What is that sound? I'm really scared. It's so dark, and that noise... it sounds so creepy.(聞こえた?何の音?本当に怖い。とても暗くて、あの音はとても不気味)」とのテキストプロンプトに続く文章を音声で出力した結果が以下。
Spirit LMは音声での入力に対してテキストで応答することも可能。Spirit LMに対し音声で「a b c d e」と入力した場合、「f g h i j k l m n o p q r s t u v w x y z」というテキストが返ってきたそうです。Spirit LMに入力した音声は以下から確認可能。
Metaによると、Spirit LMは音声およびテキストデータセットに対して単語レベルのインターリーブ学習でトレーニングされており、音声の入出力というクロスモダリティ生成を可能にしているとのこと。これを実現するために、Metaは音声をモデル化するために音声トークンを使用する「Spirit LM Base」と、ピッチトークンやスタイルトークンを使用して、興奮や怒り、驚きなどのトーンに関する情報をキャプチャし、そのトーンに合った音声を生成できる「Spirit LM Expressive」を開発しました。
Metaは「Spirit LMは、より自然な音声を生成することができ、自動音声認識、テキスト読み上げ、音声分類などのモダリティ全体で新しいタスクを学習する能力を備えています。私たちの研究が、より大きな研究コミュニティを刺激し、音声とテキストの統合を発展させ続けることを願っています」と述べています。
なお、以下のページからモデルデータのダウンロードを申請することができます。
Spirit LM access request form - Meta AI
https://ai.meta.com/resources/models-and-libraries/spirit-lm-downloads/
また、Spirit LMのソースコードは以下のGitHubページからダウンロード可能です。
GitHub - facebookresearch/spiritlm: Inference code for the paper "Spirit-LM Interleaved Spoken and Written Language Model".
https://github.com/facebookresearch/spiritlm
・関連記事
MetaがAI向けのオープンなハードウェアについての現状と展望について語る - GIGAZINE
Metaが「Llama 3.2」を公開、画像認識性能が向上&スマホ特化の小型版もあり - GIGAZINE
Metaの大規模言語モデル「Llama」の累計ダウンロード数が3億5000万回に迫る - GIGAZINE
MetaがGPT-4超えのAIモデル「Llama 3.1」をリリース - GIGAZINE
Metaがユーザー独自のAIチャットボットを作成・共有できるクリエイター向けツール「AI Studio」を展開 - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Meta releases Spirit LM, the first open ….