




TransformerとMamba2のハイブリッドとなる小規模言語モデル「Zamba2-7B」が公開される

アメリカのAIスタートアップであるZyphraが、自然言語処理モデルの「Zamba2-7B」をリリースしました。Zyphraは、Zamba2-7BがGoogleのGemmaやMetaのLlama 3シリーズを上回るパフォーマンスを発揮するとアピールしています。
Zyphra is excited to release Zamba2-7B
https://www.zyphra.com/post/zamba2-7b
Zyphra/Zamba2-7B · Hugging Face
https://huggingface.co/Zyphra/Zamba2-7B
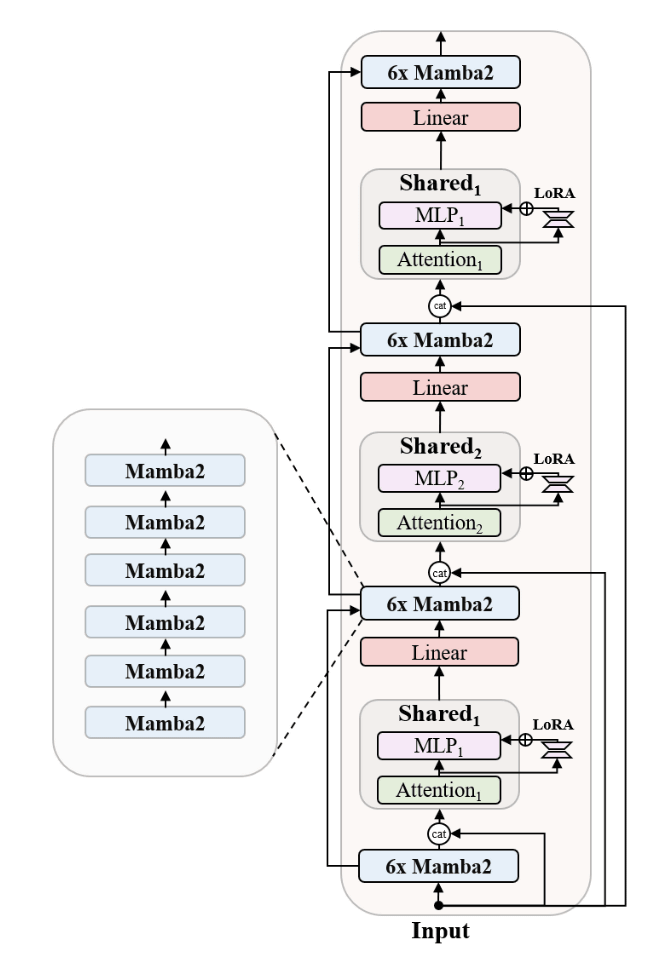
Zamba2-7Bは、従来の言語モデルで広く使用されているTransformerアーキテクチャと2023年12月に発表されたMambaアーキテクチャのハイブリッドである「Zambaアーキテクチャ」で設計されています。
また、Zamba2-7Bは前モデルであるZamba1から進化し、Mamba1ブロックがMamba2ブロックに置き換えられ、さらに2つの交互に配置された共有アテンションブロックを導入しています。この「共有」とは、同じ重みを持つアテンションブロックがモデル内の複数の場所で再利用されることを意味します。この共有アプローチにより、モデルの全体的なパラメーター数を抑えつつ、Transformerアーキテクチャの機能を活用することができ、モデルサイズとパフォーマンスのバランスを取ることができるとZyphraは説明しています。
効率性を高めるため、大規模言語モデルのファインチューニングに使われるLoRA(Low-Rank Adaptation)プロジェクターを各共有多層パーセプトロン(MLP)とアテンションブロックに適用し、ネットワークの深さに応じた特殊化を可能にしています。また、共有アテンションレイヤーにRotary Position Embeddingsを導入することで、性能をさらに向上させています。
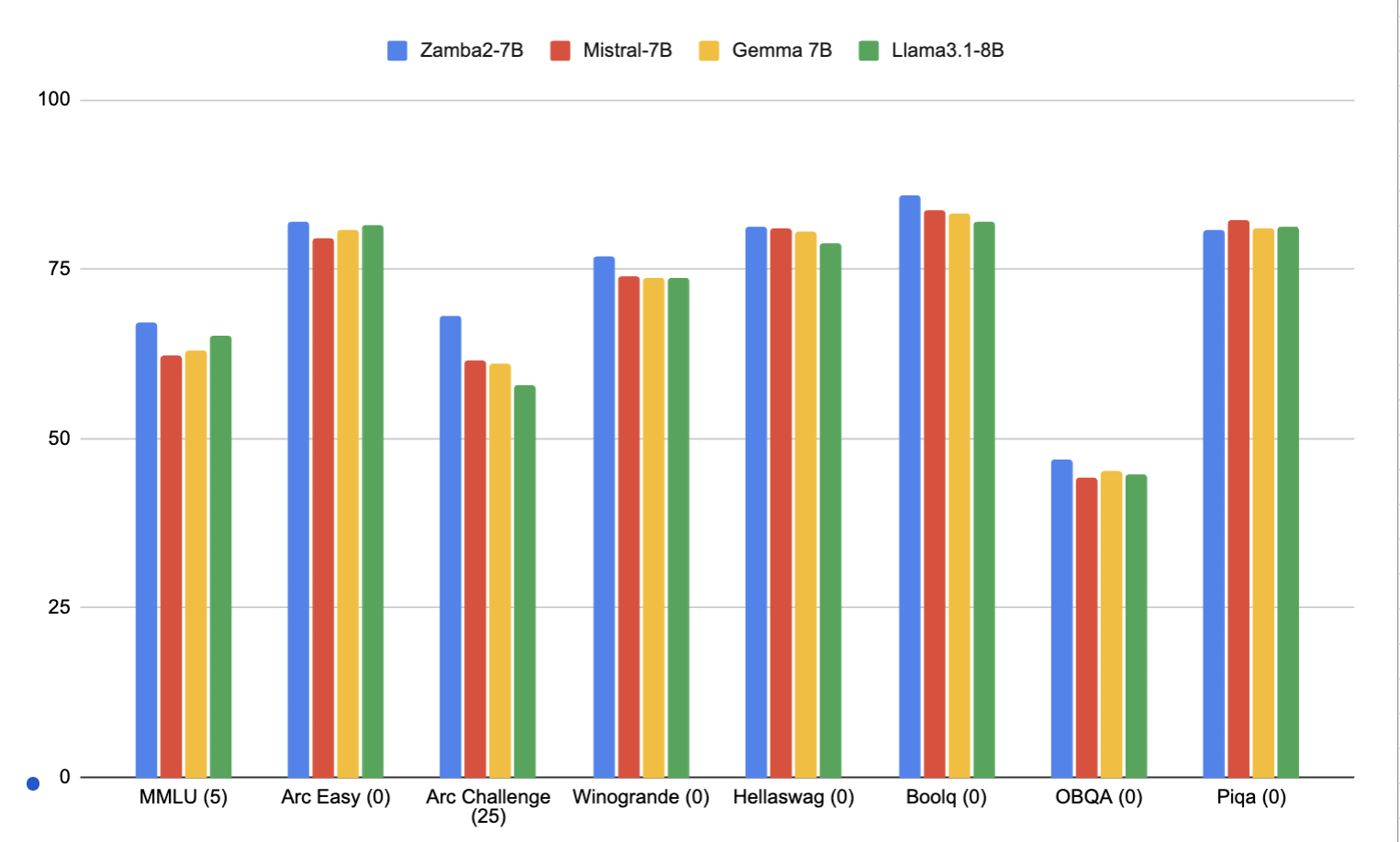
Zamba2-7Bは約74億のパラメータを持ち、2兆トークンのテキストとコードデータで事前学習を行い、その後約1000億の高品質トークンを用いて追加の学習フェーズを実施しているとのこと。この結果、Zamba2-7B(青)は8B以下のパラメータを持つモデルの中で、Mistral-7B(赤)やGemma 7B(黄)、Llama 3.1-8B(緑)などを上回る性能を示しているとZyphraは主張しています。
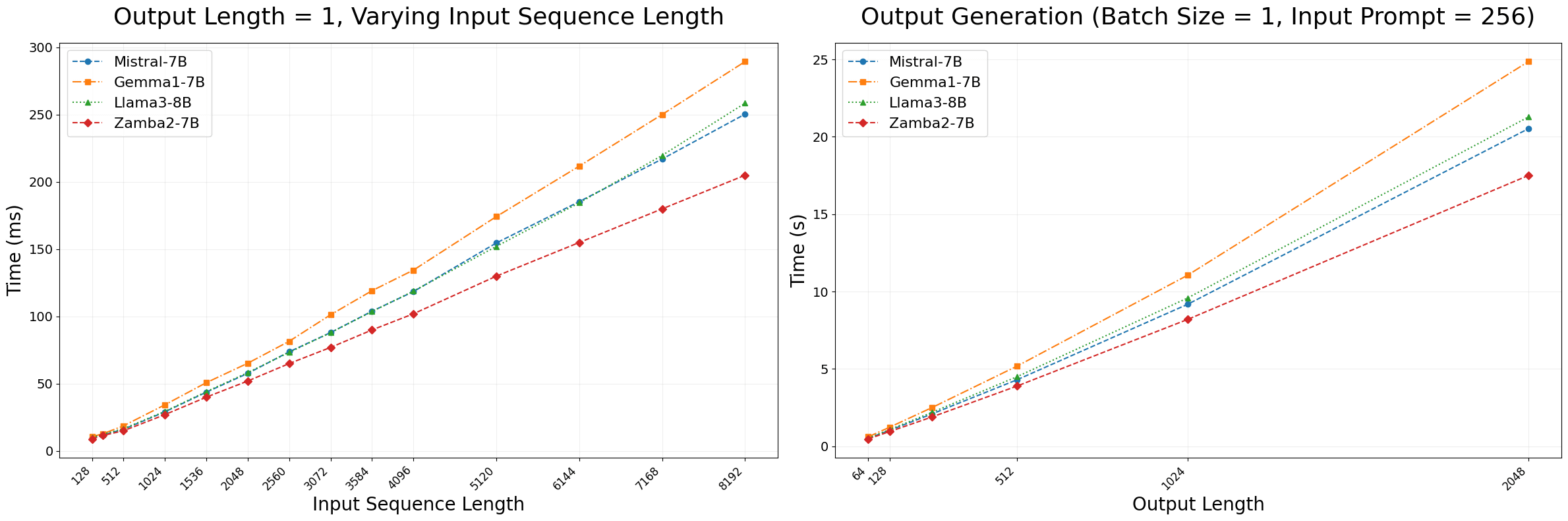
特に、ZyphraはZamba2-7Bの推論効率に注目。以下のグラフで示されている通り、Zamba2-7B(赤)は、従来のTransformerベースのモデルと比較して大幅に小さいメモリフットプリントで高速な生成が可能となっており、トークン生成までの時間(左)が25%短縮、トークン生成速度(右)が20%向上しています。
Zamba2-7BはApache 2.0ライセンスでオープンソースとして公開されており、研究者や開発者、企業が自由に利用できるようになっています。Zephraは、Zamba2-7Bが小規模ながら高性能で効率的な言語モデルとして、オンデバイス処理や消費者向けGPU上での実行、さらには多くのエンタープライズアプリケーションに適した選択肢になると述べました。
・関連記事
AppleのAI研究者らが「今のAI言語モデルは算数の文章題への推論能力が小学生未満」と研究結果を発表 - GIGAZINE
Googleが大規模言語モデル「Gemma 2」のコンパクトバージョン「Gemma 2 2B」の日本語版をリリース - GIGAZINE
AI検索エンジン「Perplexity」の中の人に「どんな広告を表示するの?」「日本ではどう展開するの?」などいろいろ聞いてきた - GIGAZINE
Mistralが初のマルチモーダルAIモデル「Pixtral 12B」リリース、GitHub・Hugging Face・APIサービスプラットフォームLe Chat・Le Platforme経由で利用可能 - GIGAZINE
Alibabaが新AIモデル「Qwen2-VL」をリリース、20分を超えるビデオを分析し内容についての質問に要約して回答可能 - GIGAZINE
大規模言語モデルの仕組みが目で見てわかる「Transformer Explainer」 - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article A small language model 'Zamba2-7B', a hy….