




Alibabaが新AIモデル「Qwen2-VL」をリリース、20分を超えるビデオを分析し内容についての質問に要約して回答可能

卓越した画像・動画の理解能力を持つというAIモデル「Qwen2-VL」をAlibabaが発表しました。OpenAIの「GPT-4o」やAnthropicの「Claude 3.5-Sonnet」といった他社モデルと比較して上回る点が多くあり、すでに英語と中国語に加えて日本語や韓国語にも対応済み。無料でデモを試すこともできます。
Qwen2-VL: To See the World More Clearly | Qwen
https://qwenlm.github.io/blog/qwen2-vl/
Today we are thriiled to announce the release of Qwen2-VL! Specifically, we opensource Qwen2-Vl-2B and Qwen2-VL-7B under Apache 2.0 license, and we provide the API of our strongest Qwen2-VL-72B! To learn more about the models, feel free to visit our:
— Qwen (@Alibaba_Qwen) August 29, 2024
Blog:… pic.twitter.com/aBIDeQtWZY
Alibaba's Qwen2-VL AI can analyze videos more than 20 min long | VentureBeat
https://venturebeat.com/ai/alibaba-releases-new-ai-model-qwen2-vl-that-can-analyze-videos-more-than-20-minutes-long/
Qwen2-VLは前モデルの「Qwen-VL」を刷新したもので、「視覚理解ベンチマークの評価向上」「20分以上の動画理解」「スマートフォンやロボットなどで動作するエージェント機能」「多言語サポート」などの機能が追加されています。
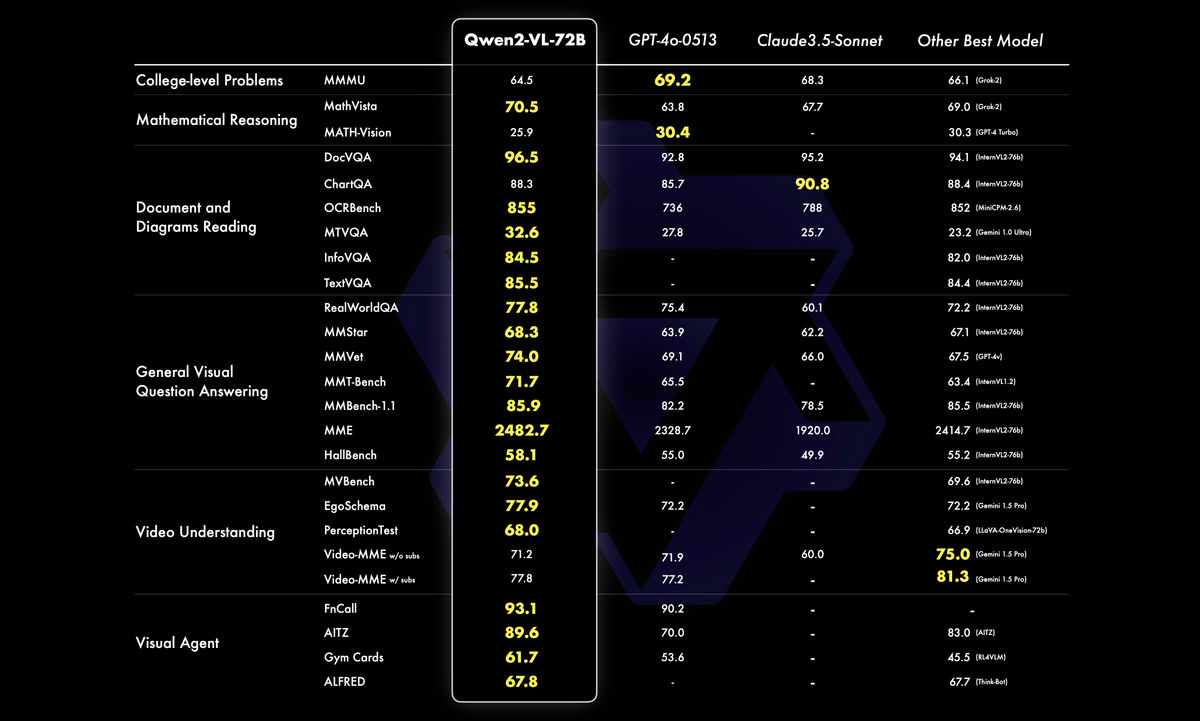
中でも、Qwen2-VL-72Bモデルは複雑な大学レベルの問題解決や数学の能力、文書と表の理解、多言語のテキストと画像の理解、一般的なシナリオの質問応答、動画理解、「エージェント」としての応答という6つの指標で、他社の主要なモデルを上回る性能を示したとのこと。
以下の画像はQwen2-VL-72Bの各種ベンチマークの結果を他社モデルと比較したもので、ほとんどのベンチマークにおいてQwen2-VL-72Bが優れた性能を示していることがわかります。特にGPT-4oやClaude 3.5-Sonnetといったクローズドモデルを、オープンソースモデルであるQwen2-VL-72Bが上回ったという点が際立っています。
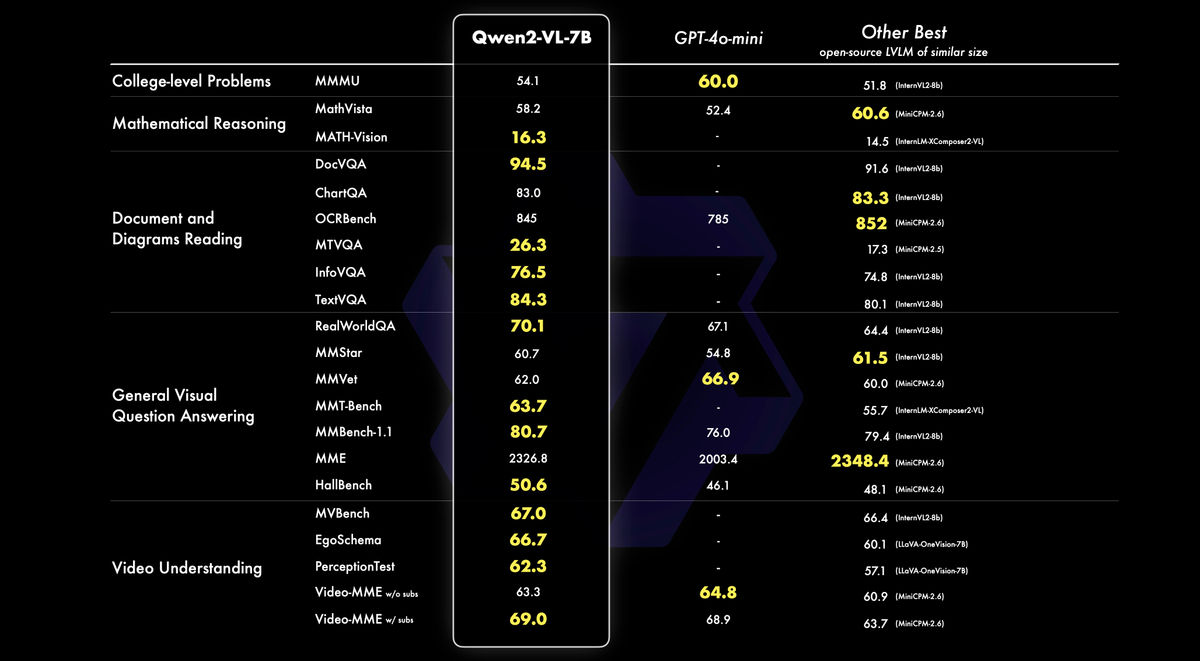
Qwen2-VL-7Bモデルでも、同等の性能を持つ他社モデルと比較して、文書理解や画像からの多言語テキスト理解などのベンチマークで優れた性能を示しました。
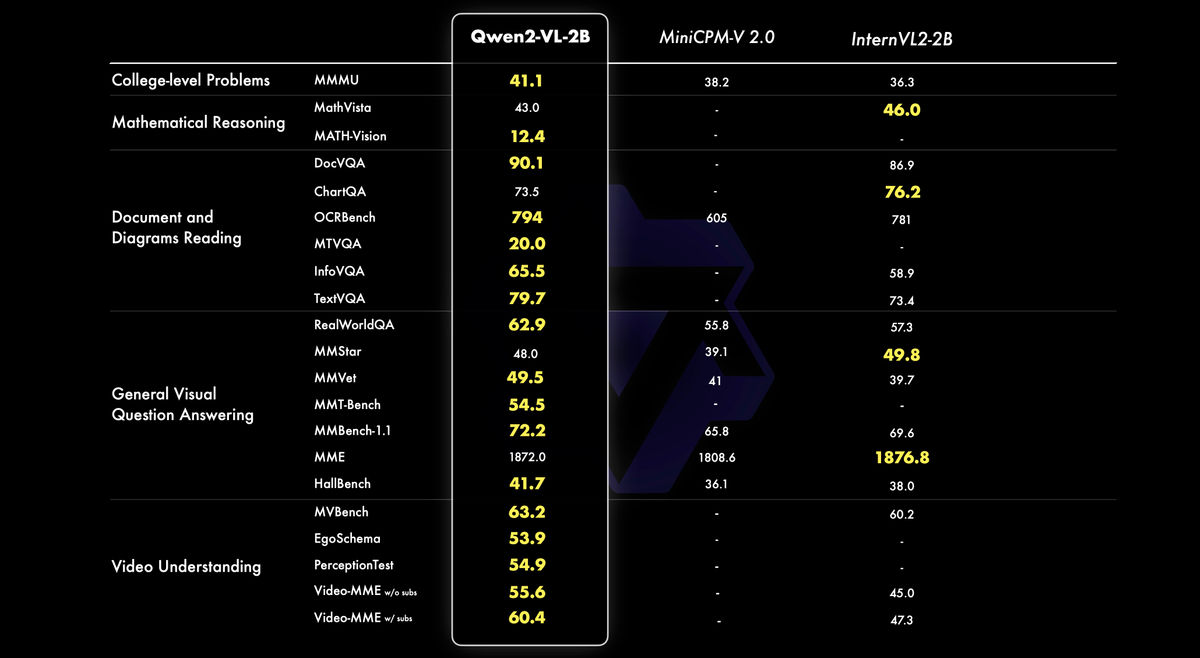
さらに、モバイル向けに最適化されたQwen2-VL-2Bモデルも登場しています。Alibabaはこのモデルを「画像、動画、多言語理解において高い性能を誇ります。特に、動画関連タスク、文書理解、一般的なシナリオの質問応答において、同規模の他のモデルと比較して優れています」と紹介しました。
Qwen2-VLの認識能力を示す例もいくつか紹介されています。以下は、数字が書かれたブロックの写真を提示して「各ブロックの色と番号を出力してください」と質問したもの。Qwen2-VLは「画像は数字が書かれたカラフルなブロックの山です。上から順に、それぞれのブロックの色と番号を紹介します。最上段(ブロック1個):青、数字は9。2段目(ブロック2個):水色は数字の7、緑は数字の8。3段目(3ブロック):紫は数字の4、ピンクは数字の5、黄緑は数字の6。最下段(ブロック4個):赤は数字の0、オレンジは数字の1、黄色は数字の2、薄緑は数字の3」と出力しました。

実際に以下のサイトでQwen2-VLの性能を試すことができます。
Qwen2-VL-72B - a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen2-VL
画像・動画理解を試す場合、「Upload」をクリックして画像または動画ファイルをアップロードします。
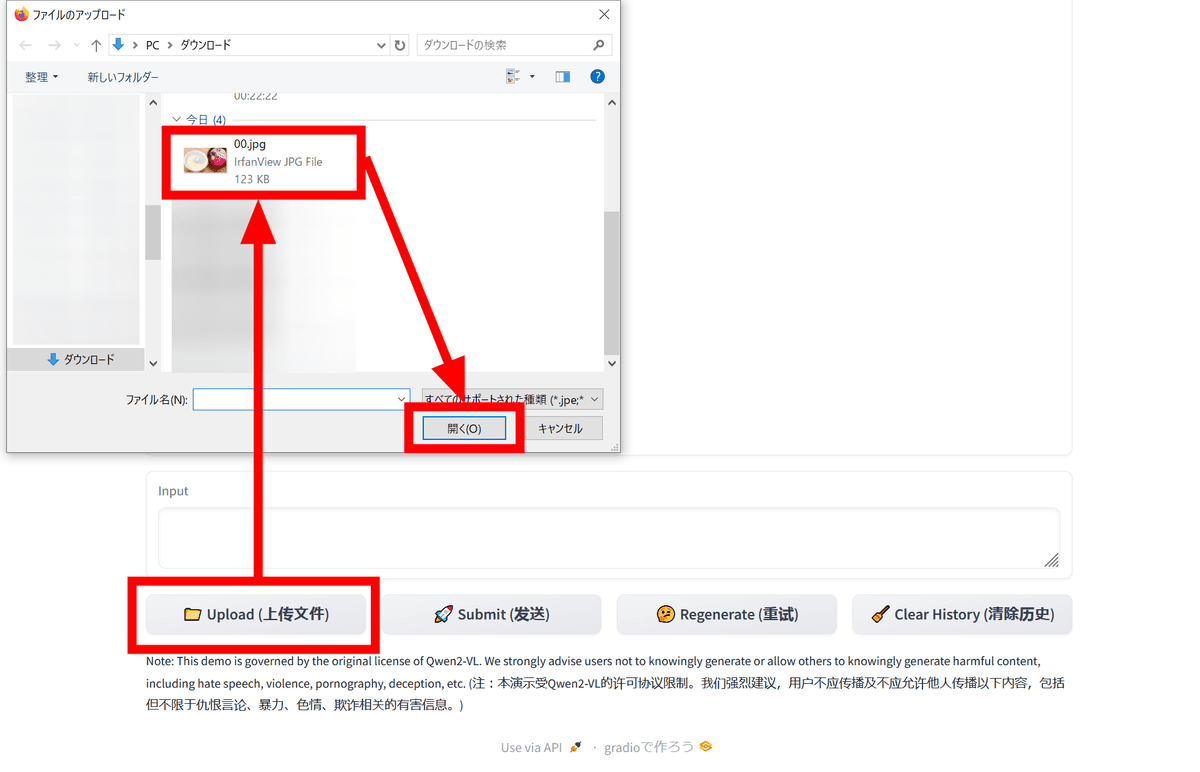
画面内にファイルが表示されたら、「Input」欄に文字を入力して「Submit」をクリックします。日本語の命令文にも対応しています。
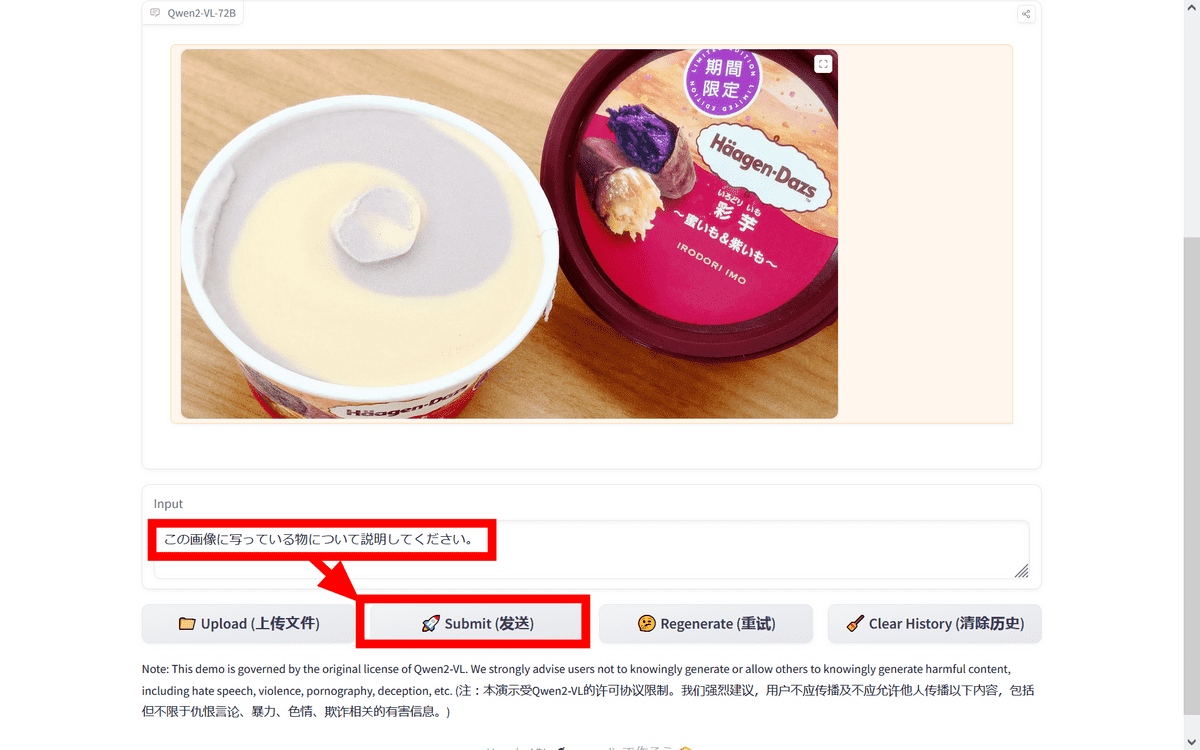
しばらく待つと結果が表示されます。今回はハーゲンダッツの「彩芋~蜜いも&紫いも~」の試食レビューで撮影した写真を使ったのですが、パッケージに書かれている文言からアイスの特徴まで、かなり正確に描写してくれました。

動画にも対応しています。
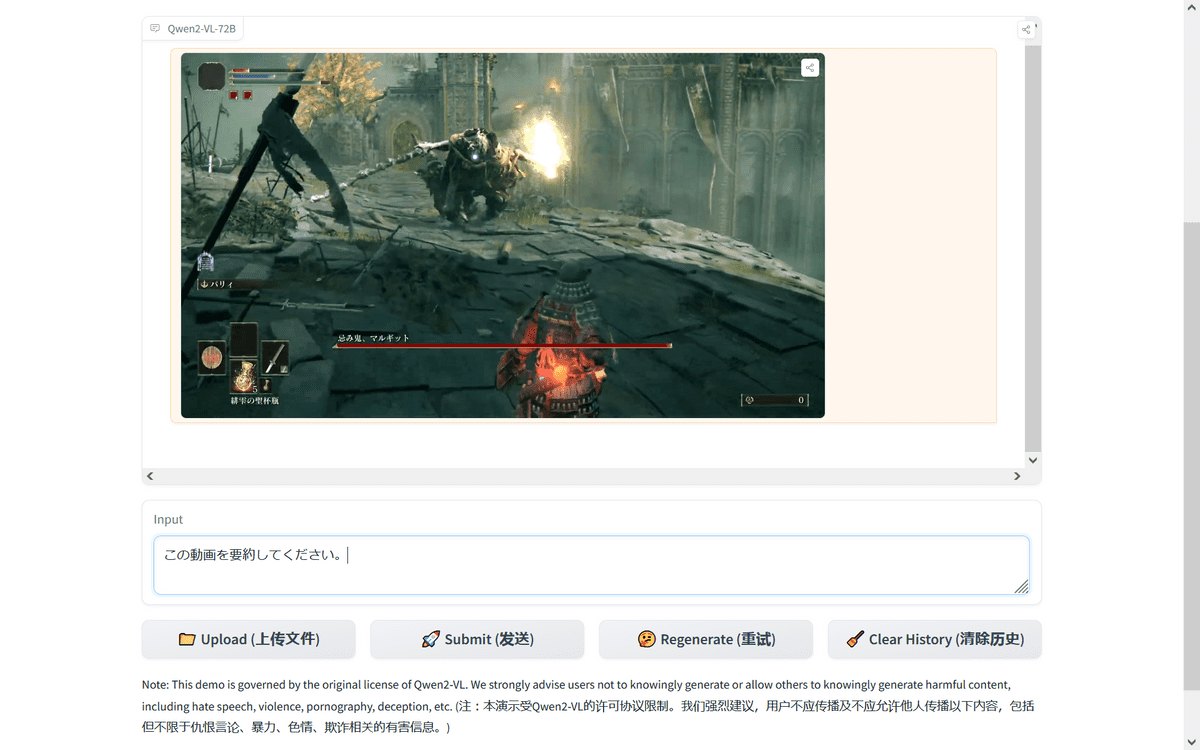
今回は「ELDEN RING」のプレイ動画を使用したのですが、「DARK SOULS」だと認識されてしまいました。
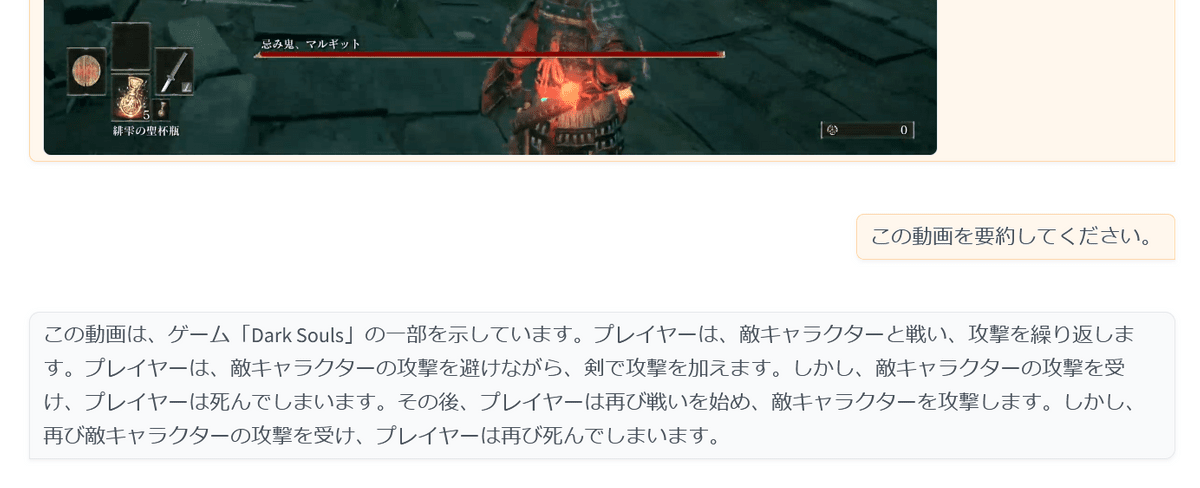
文字認識はある程度正確でした。

今回試したHugging Faceのデモ版だと、2分程度の動画のテキスト生成に50秒ほどかかり、20分以上の動画だと応答時間が5分を超えました。
AlibabaはQwen2-VLについて「植物やランドマークだけでなく、シーン内の複数の物体間の複雑な関係を理解する優れた物体認識能力を備えています。また、画像内の手書き文字や多言語の認識能力も大幅に向上し、世界中のユーザーがより利用しやすくなりました。数学的能力とコーディング能力も大幅に向上しており、ただ問題を解決できるだけでなく、チャート分析によって複雑な数学的問題を解釈することもできます。視覚認識と論理的推論の融合により、実用的な問題に取り組むことができるようになりました」などと説明しました。
なお、Qwen2-VLは2023年6月までの知識しかないとのこと。Alibabaは「ユーザーからのフィードバックと、Qwen2-VLを使用した革新的なアプリケーションを楽しみにしています。近い将来、私たちは次のバージョンの言語モデルに基づいてより強力なビジョン言語モデルを構築し、視覚と音声の両方にわたって推論できる『オムニモデル』に向けてより多くの機能を統合する予定です」と述べました。
・関連記事
数学を解ける言語モデル「Qwen2-Math」が登場、GPT-4o超えの数学性能 - GIGAZINE
Hugging FaceのAIモデルをテストする「Open LLM Leaderboard v2」で中国Qwenのモデルがトップに - GIGAZINE
CerebrasがNVIDIA H100の22倍高速な爆速AI推論サービスを発表、デモページも公開されたので使ってみた - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, レビュー, Posted by log1p_kr
You can read the machine translated English article Alibaba releases new AI model 'Qwen2-VL'….