Alibaba releases new AI model 'Qwen2-VL' that can analyze videos longer than 20 minutes and summarize and answer questions about the content

Alibaba has announced the AI model ' Qwen2-VL ' which has outstanding image and video understanding capabilities. It has many advantages over other models such as OpenAI's 'GPT-4o' and Anthropic's 'Claude 3.5-Sonnet', and already supports Japanese and Korean in addition to English and Chinese. You can also try the demo for free.
Qwen2-VL: To See the World More Clearly | Qwen
Today we are thriled to announce the release of Qwen2-VL! Specifically, we opensource Qwen2-Vl-2B and Qwen2-VL-7B under Apache 2.0 license, and we provide the API of our strongest Qwen2-VL-72B! To learn more about the models, feel free to visit our:
— Qwen (@Alibaba_Qwen) August 29, 2024
Blog:… pic.twitter.com/aBIDeQtWZY
Alibaba's Qwen2-VL AI can analyze videos more than 20 min long | VentureBeat
https://venturebeat.com/ai/alibaba-releases-new-ai-model-qwen2-vl-that-can-analyze-videos-more-than-20-minutes-long/
The Qwen2-VL is an updated version of the previous model, Qwen-VL , and adds features such as improved visual comprehension benchmark evaluation, video comprehension of more than 20 minutes, agent functionality that works on smartphones, robots, etc., and multilingual support.
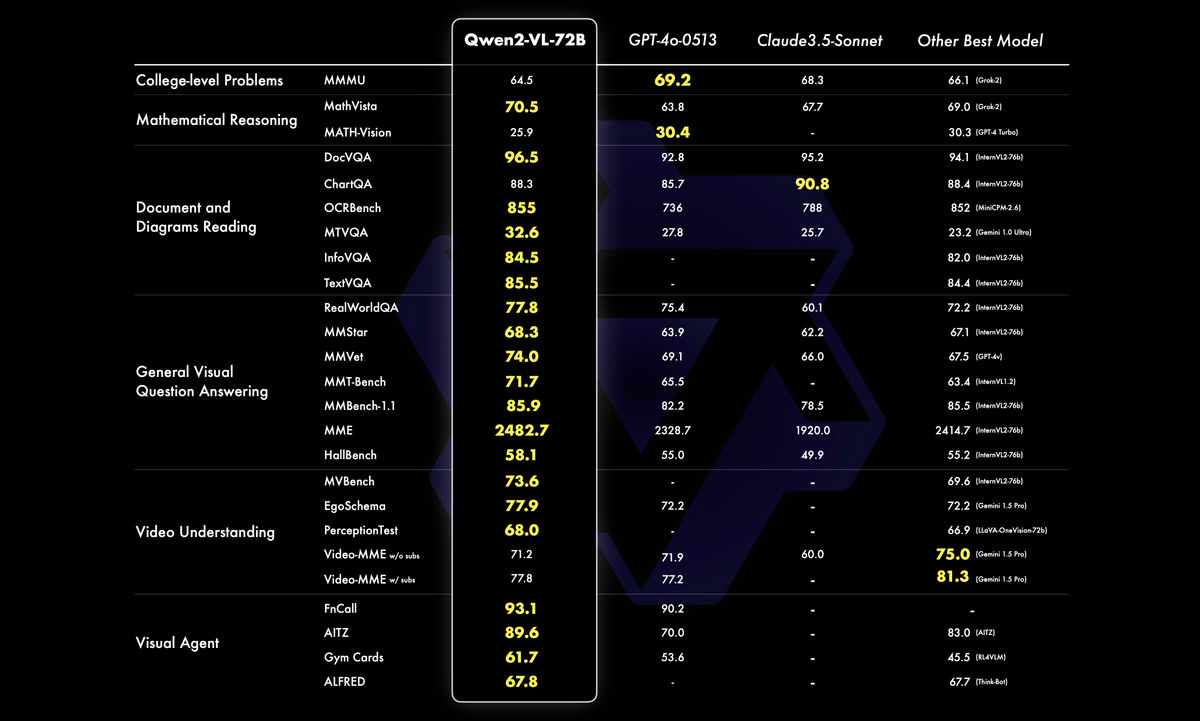
In particular, the Qwen2-VL-72B model outperformed other companies' leading models in six areas: complex university-level problem solving and mathematical ability, document and table understanding, multilingual text and image understanding, question answering for common scenarios, video understanding, and responding as an 'agent.'
The image below compares the results of various benchmarks of Qwen2-VL-72B with other models, and shows that Qwen2-VL-72B shows superior performance in most benchmarks. In particular, it stands out that the open source model Qwen2-VL-72B outperforms closed models such as GPT-4o and Claude 3.5-Sonnet.
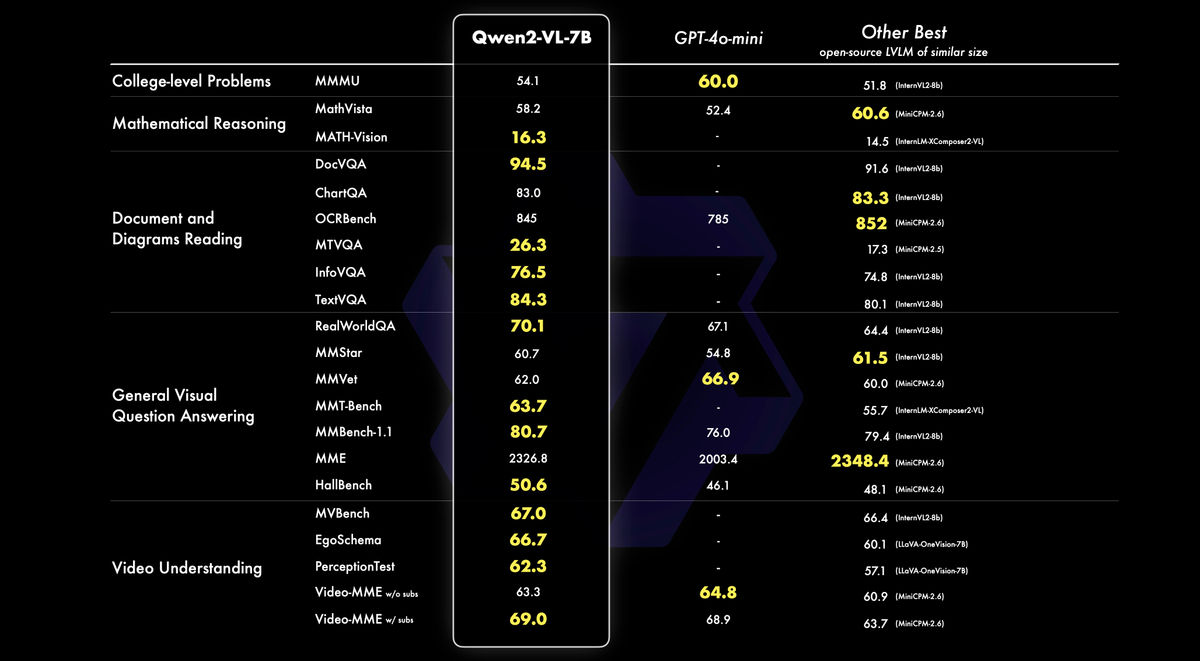
The Qwen2-VL-7B model also demonstrated superior performance in benchmarks such as document understanding and multilingual text understanding from images, compared to other models with similar performance.
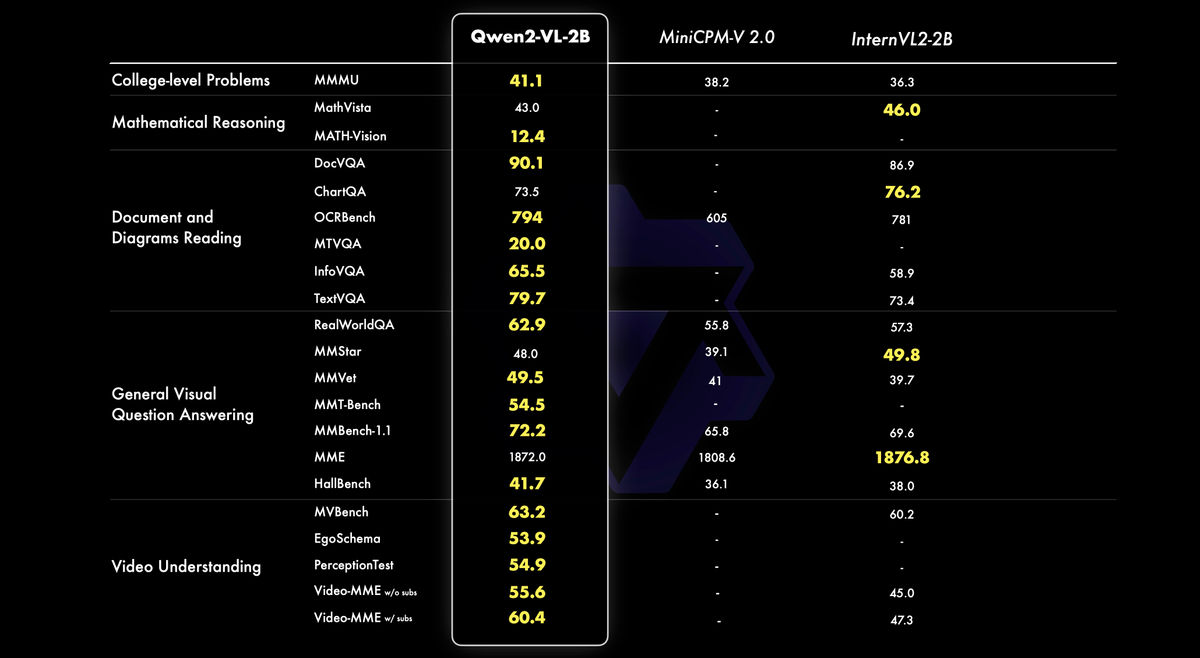
Additionally, the mobile-optimized Qwen2-VL-2B model has also been released, which Alibaba describes as 'high performance in image, video, and multilingual understanding. In particular, it outperforms other models of the same scale in video-related tasks, document understanding, and question answering for general scenarios.'
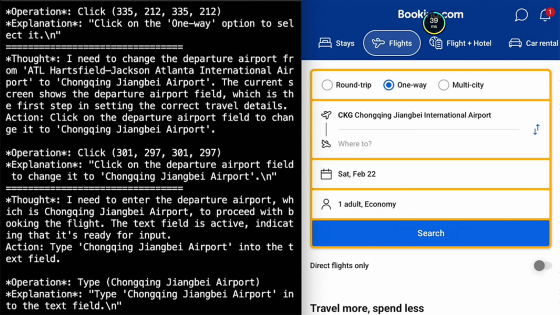
There are also some examples showing the recognition capabilities of Qwen2-VL. Below, a picture of a block with numbers written on it was presented and the question was asked, 'Please output the color and number of each block.' Qwen2-VL output, 'The image is a pile of colorful blocks with numbers written on them. From the top, we will introduce the color and number of each block. Top row (1 block): Blue, number 9. Second row (2 blocks): Light blue is the number 7, green is the number 8. Third row (3 blocks): Purple is the number 4, pink is the number 5, yellow-green is the number 6. Bottom row (4 blocks): Red is the number 0, orange is the number 1, yellow is the number 2, light green is the number 3.'

You can actually test the performance of Qwen2-VL at the following site.
Qwen2-VL-72B - a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen2-VL
If you want to try out image/video comprehension, click 'Upload' to upload an image or video file.
When the file is displayed on the screen, enter text in the 'Input' field and click 'Submit.' Japanese commands are also supported.
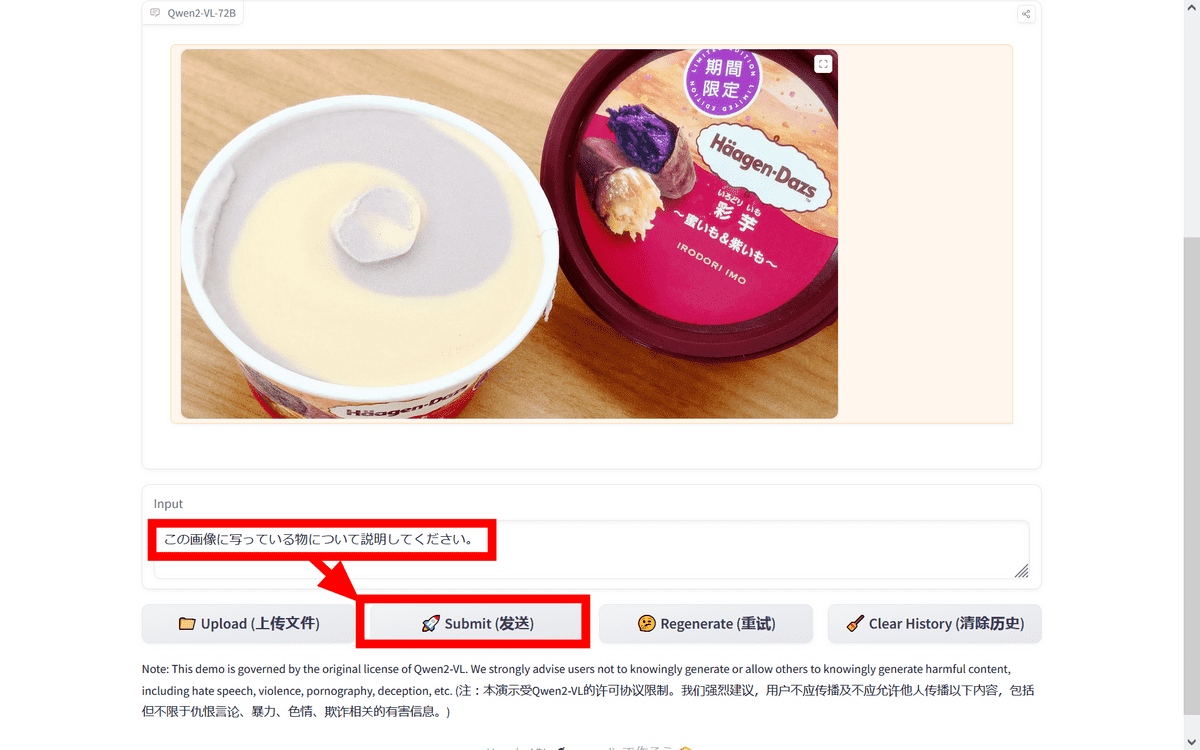
After a while, the results will be displayed. This time, I used a photo I took for

It also supports videos.
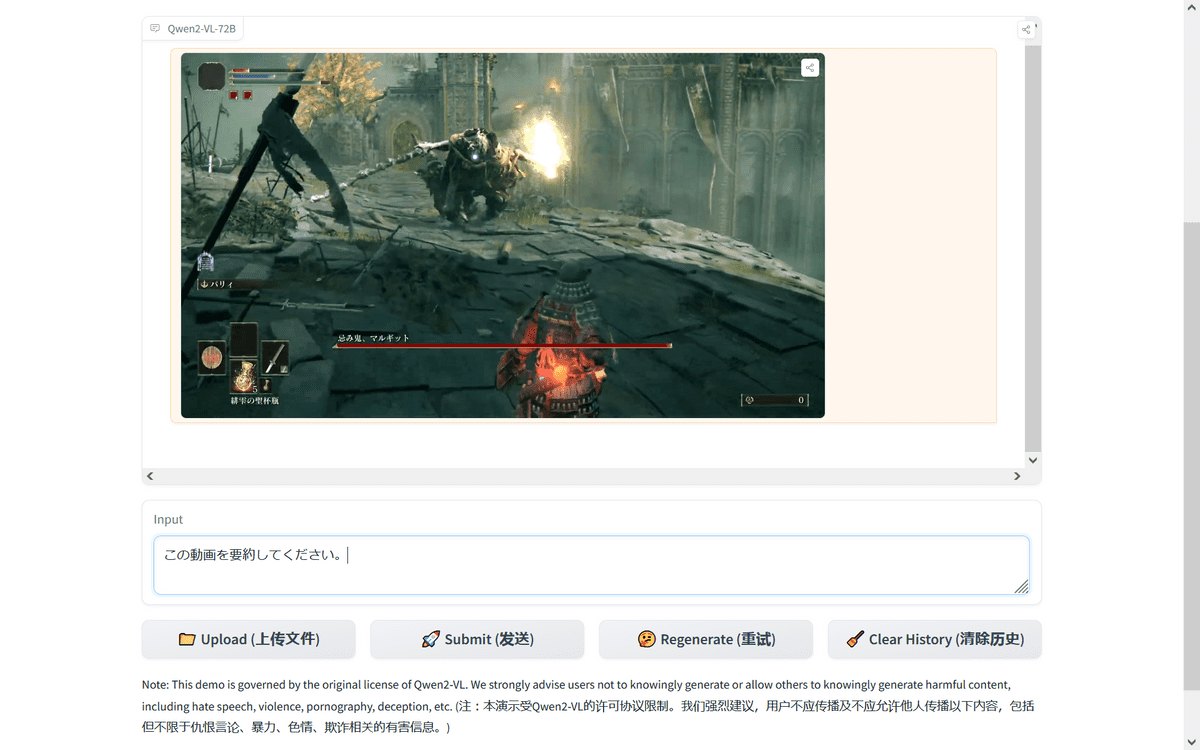
This time I used
Character recognition was reasonably accurate.

In the demo version of Hugging Face that I tried out, it took about 50 seconds to generate text for a video of about two minutes, and the response time for videos longer than 20 minutes was over five minutes.
Alibaba explained about Qwen2-VL, 'It has excellent object recognition capabilities, not only for plants and landmarks, but also for understanding the complex relationships between multiple objects in a scene. It also has significantly improved recognition of handwritten characters and multiple languages in images, making it more accessible to users around the world. Its mathematical and coding abilities have also been significantly improved, so it can not only solve problems but also interpret complex mathematical problems through chart analysis. The combination of visual recognition and logical reasoning has enabled it to tackle practical problems.'
In addition, Qwen2-VL only has knowledge up to June 2023. Alibaba said, 'We look forward to user feedback and innovative applications using Qwen2-VL. In the near future, we plan to build a more powerful vision language model based on the next version of the language model and integrate more features toward an 'omni model' that can infer across both vision and speech.'
Related Posts: