




200万トークンを入力可能なGemini 1.5 Proが全開発者に開放&オープンモデルのGemma 2公開

2024年6月28日、200万トークンのコンテキストウィンドウを利用できる「Gemini 1.5 Pro」がすべての開発者向けに公開されました。また同日、90億(9B)と270億(27B)のパラメーターサイズを持つ大規模言語モデルの「Gemma 2」も公開され、Google AI StudioやHugging Faceを通じて利用できるようになりました。
Gemini 1.5 Pro 2M context window, code execution capabilities, and Gemma 2 are available today - Google Developers Blog
https://developers.googleblog.com/en/new-features-for-the-gemini-api-and-google-ai-studio/
Google launches Gemma 2, its next generation of open models
https://blog.google/technology/developers/google-gemma-2/
2024年2月に発表されたGemini 1.5 Proは5月のアップデートでコンテキストウィンドウが100万から200万に倍増し、Google AI StudioまたはVertex AIのウェイトリストに登録したユーザー向けに限定公開されていました。
このGemini 1.5 Proが6月28日より全開発者向けに公開されることとなりました。

また、Googleはコンテキストウィンドウの拡大に応じて入力コストが増大してしまうことを懸念し、Gemini 1.5 Proの公開に合わせて「コンテキストキャッシュ」と呼ばれるコスト削減システムを導入しています。
コンテキストキャッシュをオンにすると、コード実行機能がモデルによって動的に活用され、望ましい最終出力に到達するまで結果を反復的に学習することができるとのこと。開発者はモデルからの出力トークンに基づいてお金を払うだけでよくなります。
コンテキストキャッシュはGemini APIおよびGoogle AI Studioの「詳細設定」項目から利用可能で、Gemini 1.5 ProとGemini 1.5 Flashの両方で有効化できます。
Gemini 1.5 Proの開放と同時に登場した「Gemma 2」は、前世代の「Gemma」よりも高性能かつ効率的な推論が可能とされており、27Bモデルは314Bの「Grok」以上、9Bモデルは8Bの「Llama 3」をしのぐ性能を発揮するそうです。
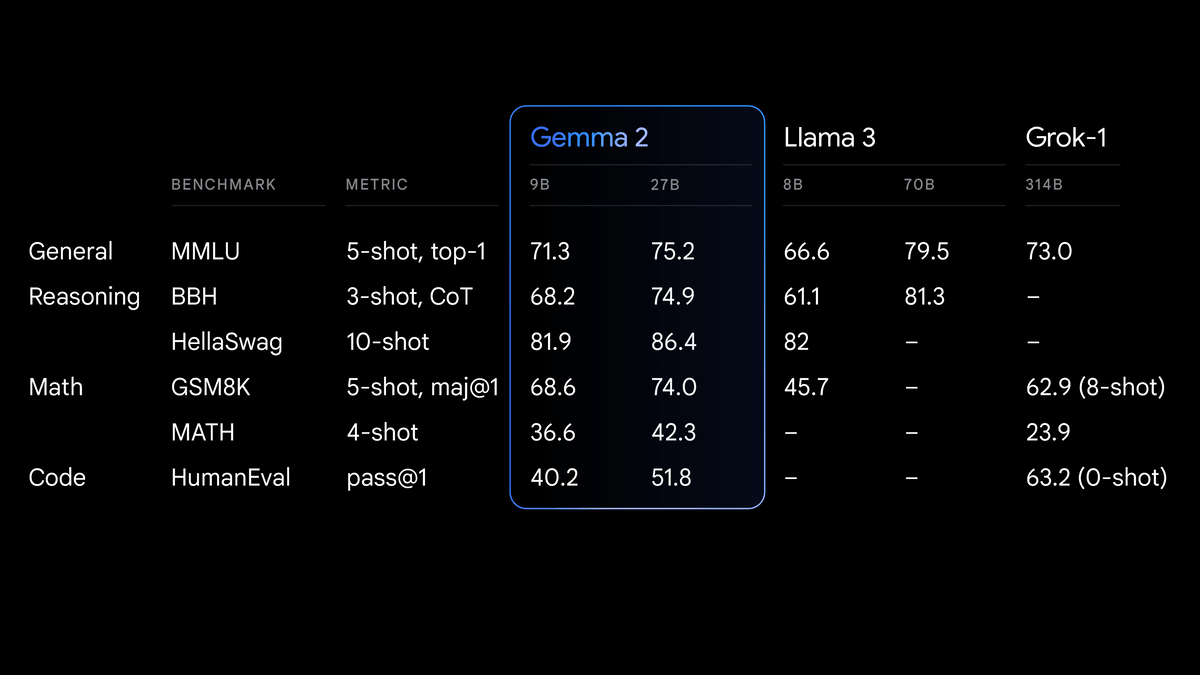
また、27BのGemma 2は単一のGoogle Cloud TPUホスト、NVIDIA A100 80GB Tensor Core GPU、またはNVIDIA H100 Tensor Core GPU上で効率的に推論を実行するように設計されており、高い性能を維持しながらコストを大幅に削減できるとのこと。これにより、ますます利用しやすくなり、Googleは「各社の予算に応じたAIの導入が可能になる」と案内しています。
合わせて、Google AI StudioでもGemma 2モデルが利用できるようになっています。Googleは「Gemma 2をGoogle AI Studioでフル精度で試したり、Hugging Face Transformersを介してNVIDIA RTXやGeForce RTXを搭載したホームコンピュータで試したりしてみてください」と述べました。
なお、Gemma 2は商用に適したライセンスに基づいて提供されています。
・関連記事
「オープンソース」を称するAIモデルは実際どのくらいオープンなのか? - GIGAZINE
Googleがオープンソースのビジュアル言語モデル「PaliGemma」を公開&Llama 3と同等性能の大規模言語モデル「Gemma 2」を発表 - GIGAZINE
Googleが高速かつ高性能な軽量AIモデル「Gemini Flash」を発表、Gemini Proの10分の1の価格で性能は同等クラス - GIGAZINE
GoogleがGemini 1.5 Proのアップデートを実施、コンテキストウィンドウを従来の100万トークンから200万トークンに拡張 - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, Posted by log1p_kr
You can read the machine translated English article Gemini 1.5 Pro, capable of inputting 2 m….