




無料&セルフホスト可能なブラウザ上で操作できる文字起こしツール「Transcription Stream」レビュー
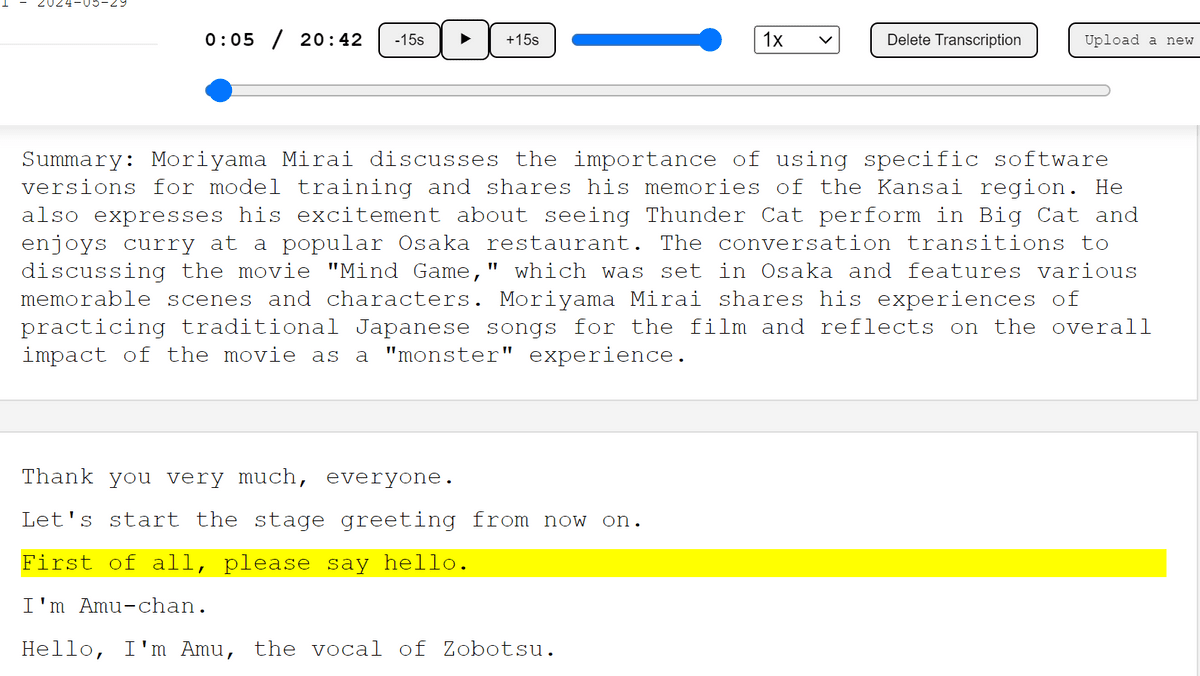
「Transcription Stream」は音声ファイルをアップロードするだけで自動で文字起こしと要約を作成してくれる上、シークバーと文字起こし結果が連動するため人間による聞き取りが必要な場所を一目で見つけられる便利なツールです。無料で使用でき、セルフホスト可能なオープンソース版として「Transcription Stream Community Edition」が用意されているので実際にセルフホストしてみました。
GitHub - transcriptionstream/transcriptionstream: turnkey self-hosted offline transcription and diarization service with llm summary
https://github.com/transcriptionstream/transcriptionstream
なお、Transcription Stream Community EditionのホストにはGPUを搭載したPCが必要です。
今回はDebianを使用してTranscription Stream Community Editionを起動します。まずは下記のコマンドでリポジトリをクローンし、ディレクトリへ移動。
git clone https://github.com/transcriptionstream/transcriptionstream.git
cd transcriptionstream
Dockerイメージを自分でビルドするかビルド済みのイメージをプルするかの2通りの方法が存在しているとのこと。今回はビルド済みのイメージを使用するため、下記のコマンドを入力します。
./start-nobuild.sh
「メインのDockerイメージは26GBあってダウンロードに時間がかかる」という注意書きが出現。「y」と入力してエンターキーを押します。

Docker-composeコマンドが見つからないというエラーが出てしまいました。
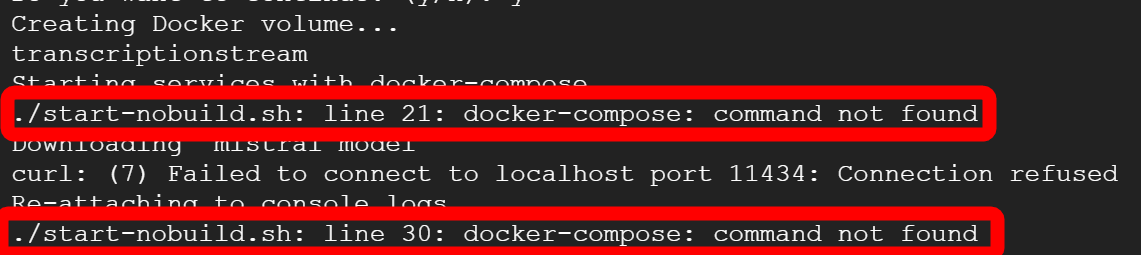
下記のコマンドでDocker Composeをインストール。
sudo apt-get update
sudo apt-get install docker-compose-plugin
また、Compose V2を使用するので「start-nobuild.sh」をテキストエディタで開き、「docker-compose」と書かれている場所2カ所のハイフンを空白にして「docker compose」と書き換えます。
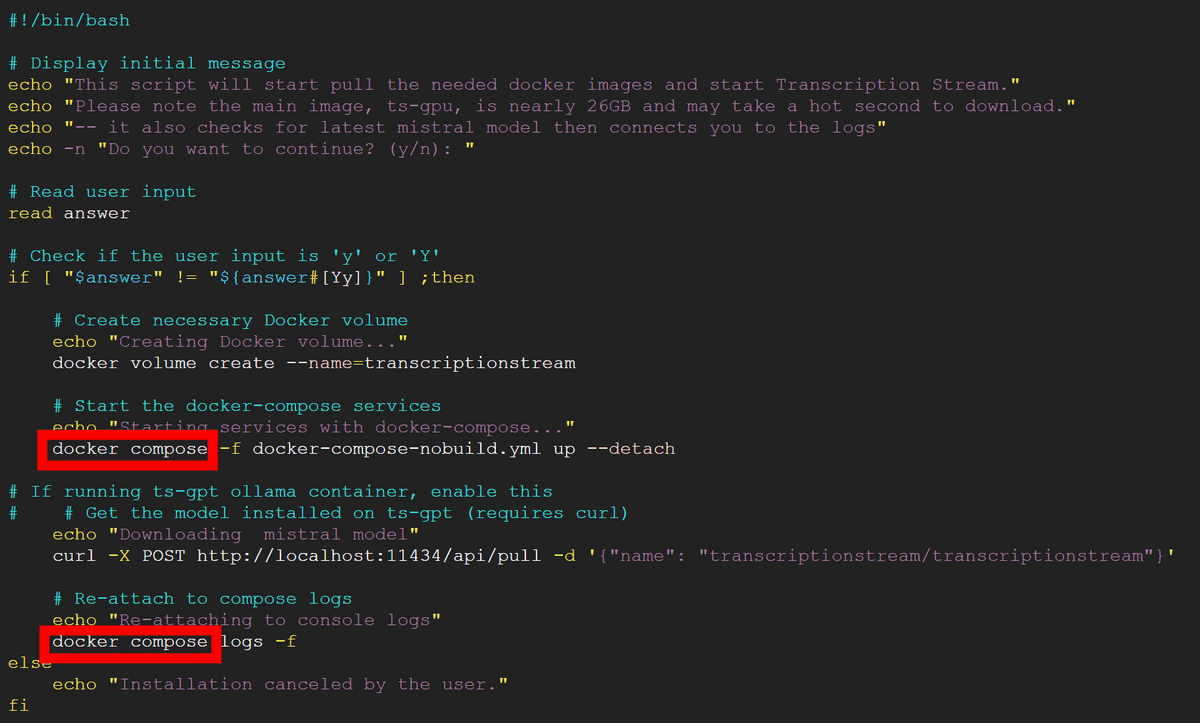
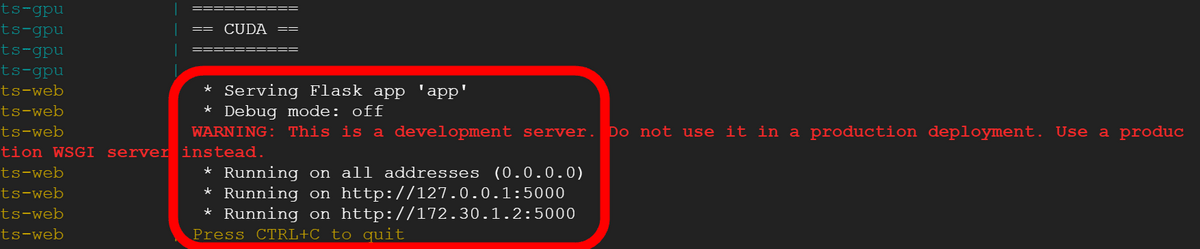
「Serving Flask app 'app'」という表示が出れば起動完了。5000番ポートで待ち受けているという表示が出ていますが、実際には「http://localhost:5006」のように5006番ポートでアクセスします。
「http://localhost:5006」にアクセスすると下図の通りのページが開きました。右上の「Upload a new file」をクリック。
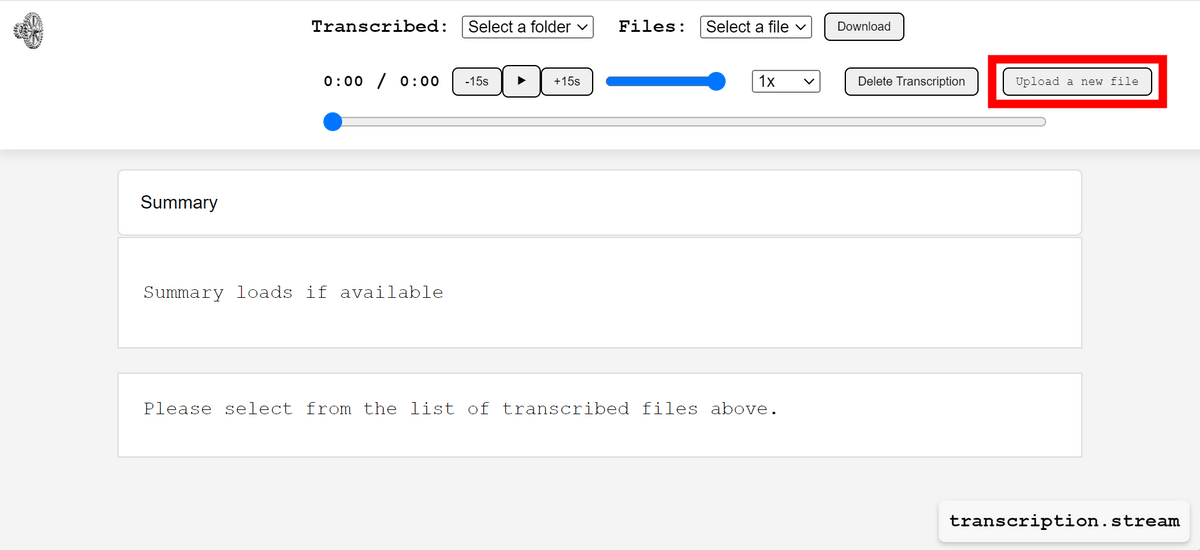
今回は文字起こしをお願いするので、「Upload for Transcribe」の「ファイルを選択」をクリックします。
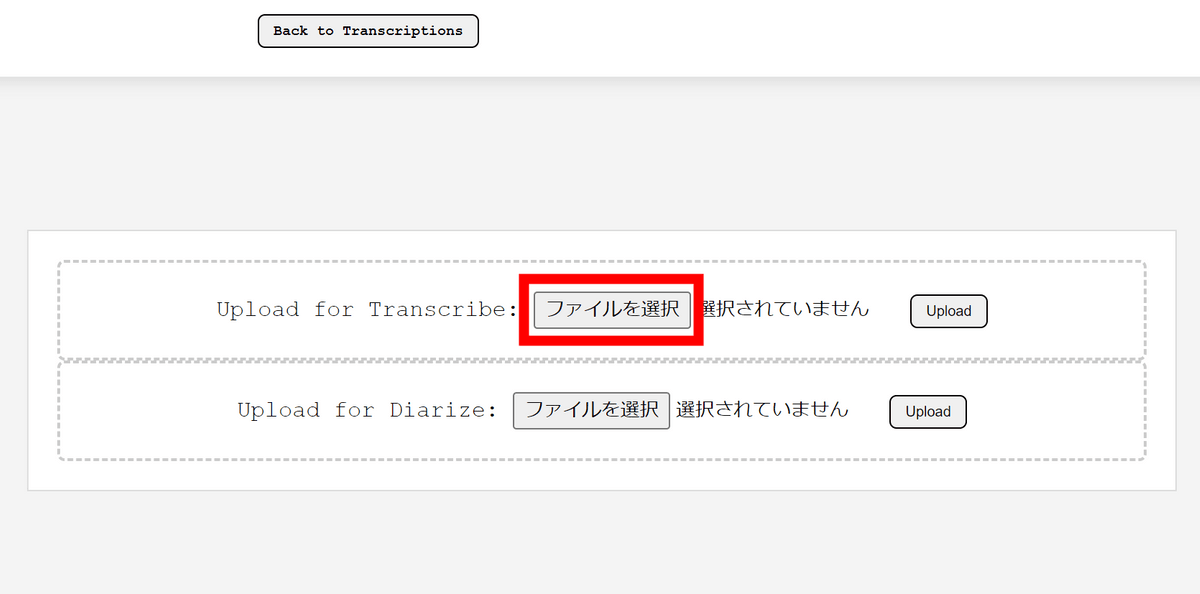
テスト用のファイルとして映画「犬王」舞台挨拶トークのムービーから音声を抜き出したmp3を用意しました。アップロードするファイルを選択し、「開く」をクリック。
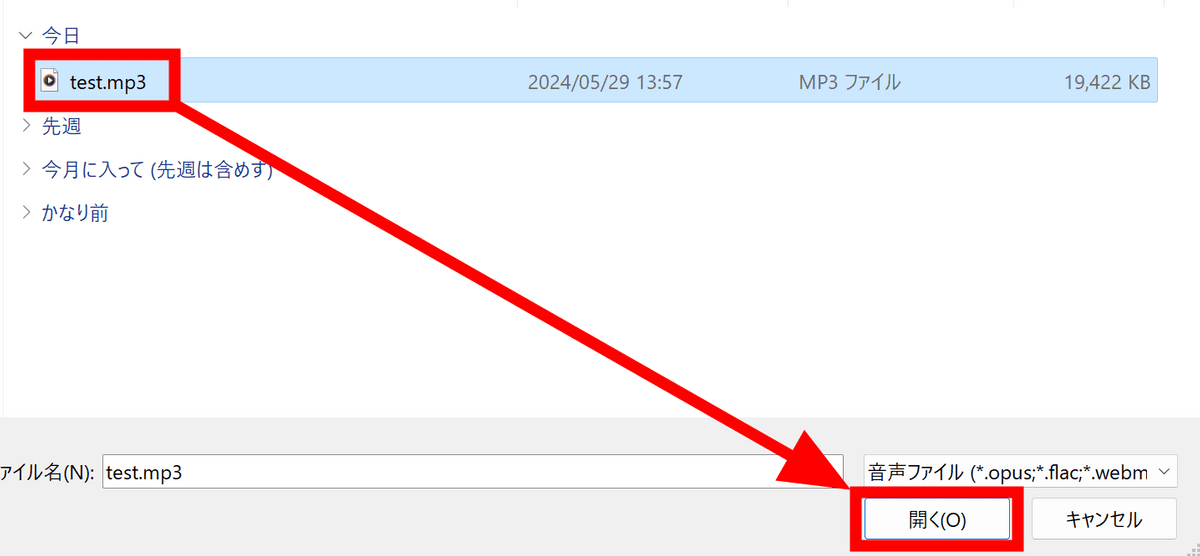
ファイルが選択されたのを確認し、「Upload」をクリックします。

「File uploaded successfully to Transcribe!」と表示が出ました。Transcription Streamは標準で文字起こしAIモデル「Whisper」のlarge-v3を使用して文字起こしを行うとのこと。「Back to Transcriptions」をクリックしてトップページに戻ります。
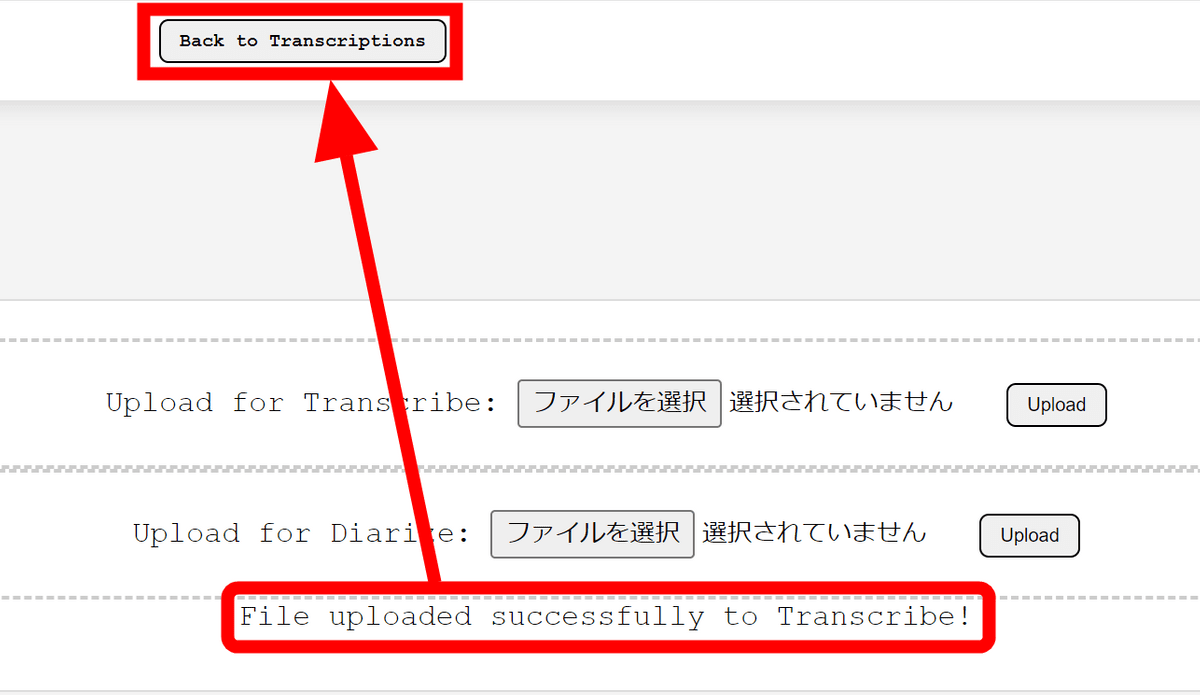
しばらく音沙汰が無く、ちゃんと動いているのか不安でしたがいつの間にか左上に文字起こしが完了したという通知が出ていました。文字起こしの完了後は「Transcribed」の項目を選択すればOK。
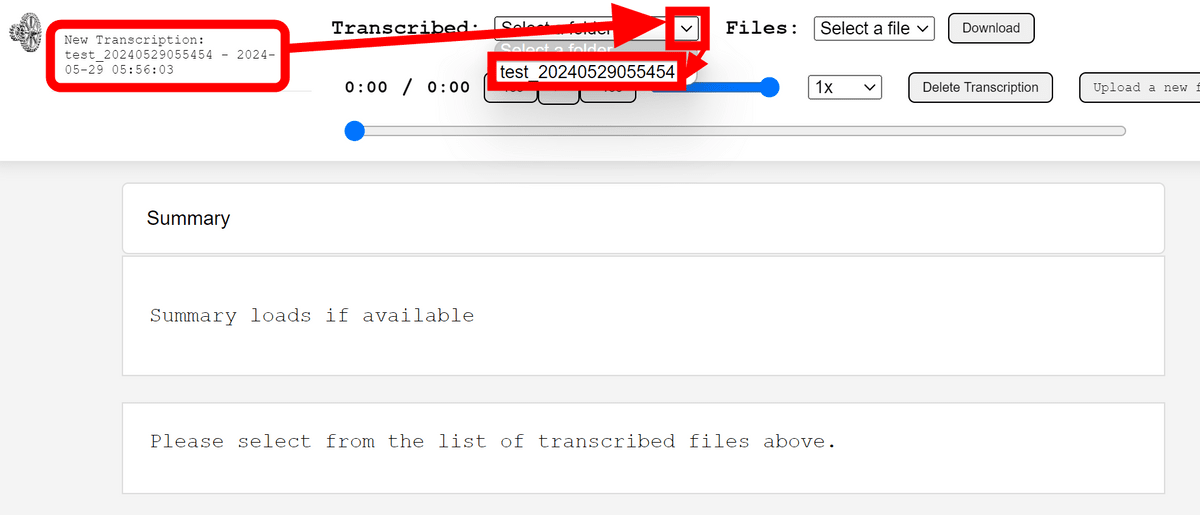
文字起こしの結果が英語で出力されていました。英語への翻訳の影響もあるためか、冒頭の数秒だけでも「恐れ入りますが、アブちゃん、お願い致します」が抜けていたり、拍手の部分で前と同じ文章を連続で出力したりとあまり精度が良くなさそうです。日本語にする方法もある模様なのですが、先にウェブアプリの動作を確認していきます。まずは再生ボタンをクリック。
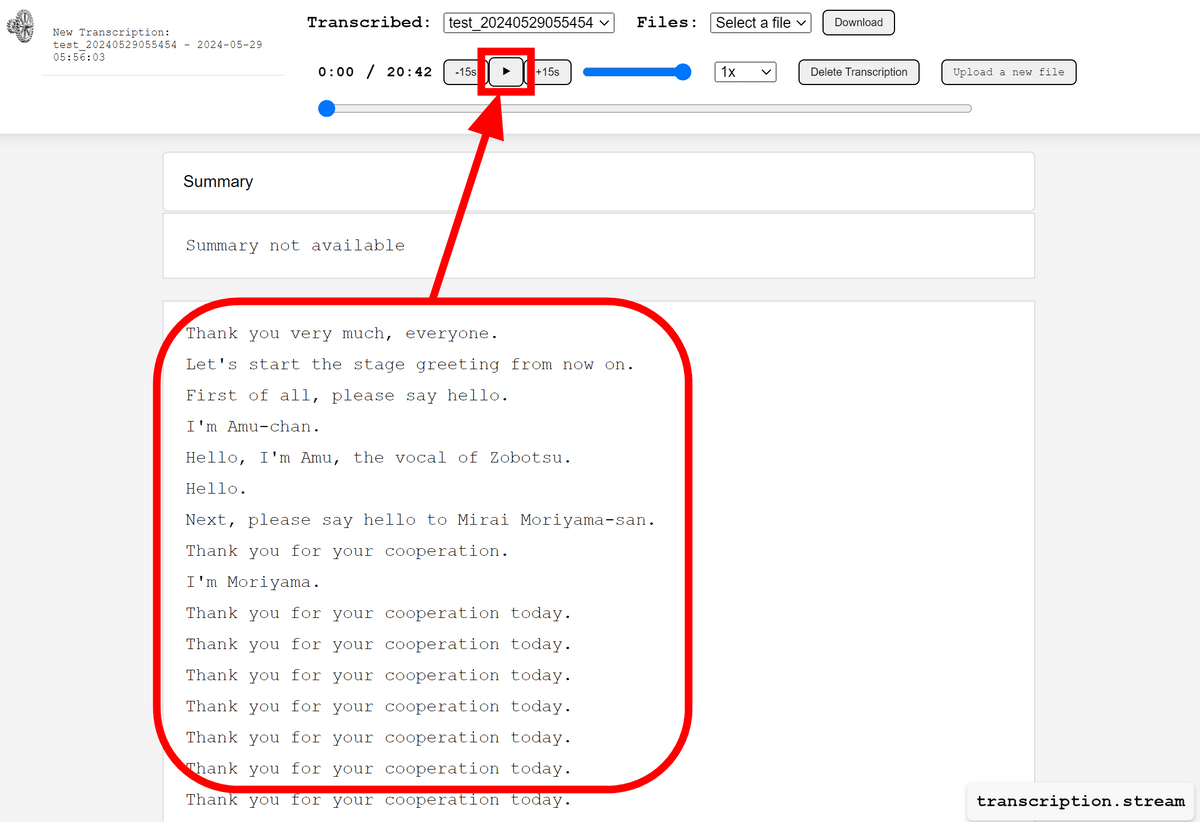
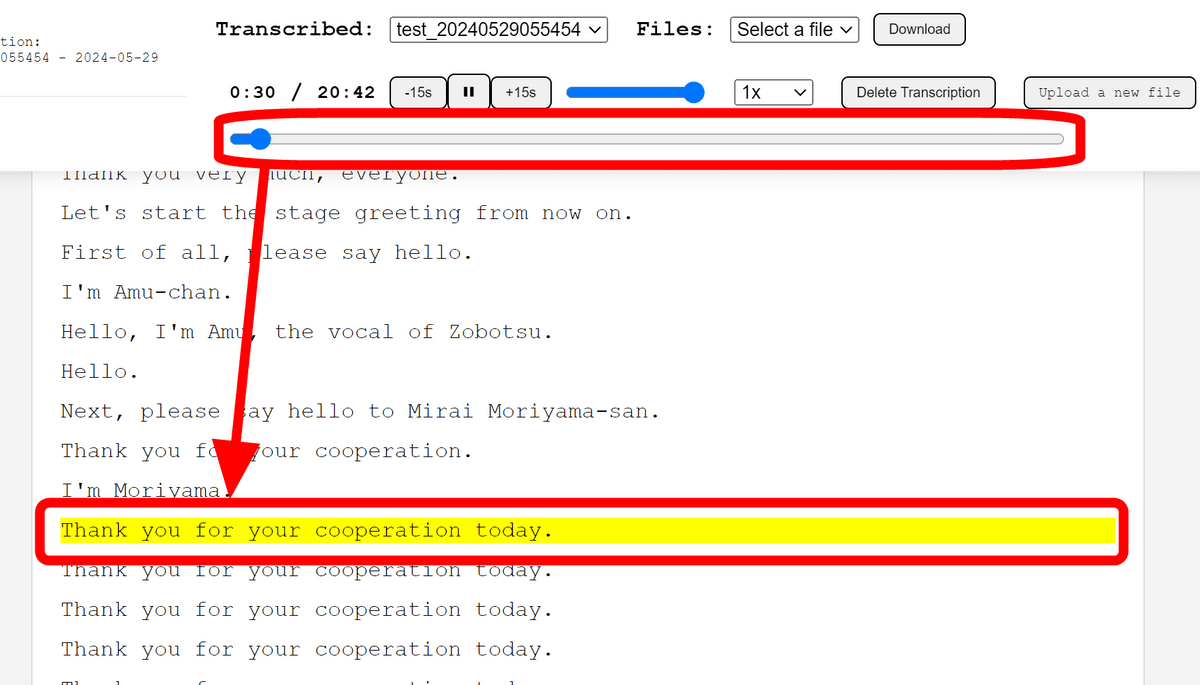
シークバーが進み始め、同時に文字起こしの「再生中の部分」がハイライトされました。シークバーを動かすとハイライトも同時に移動するため、再生したい部分を探しやすくなっています。
上のUIは左から「再生時間」「合計時間」「15秒前に戻る」「再生・停止」「15秒後に飛ばす」「音量調整」「再生速度」「文字起こしを削除」となっています。
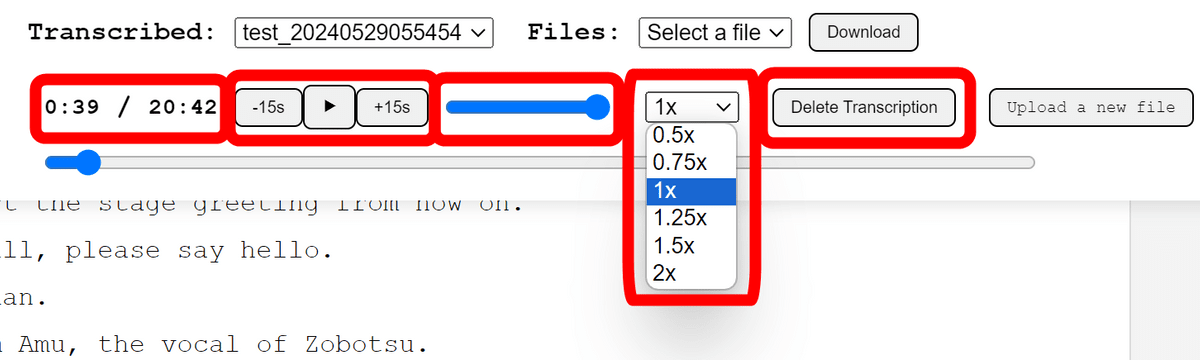
右上の「Files」欄で出力結果や元の音声ファイルを選択し、「Download」をクリックするとダウンロード可能。文字起こしの出力結果としては「vtt」「srt」「tsv」「json」「txt」形式が選択できるようになっていました。
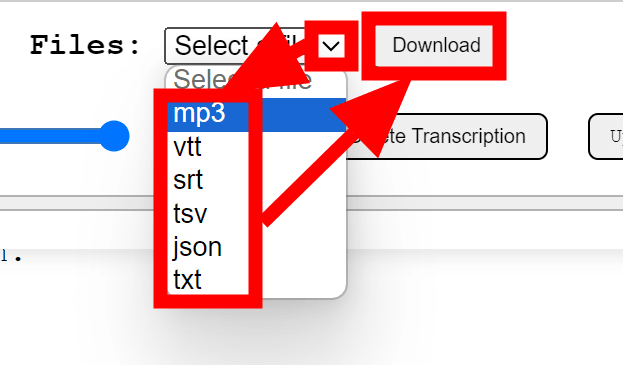
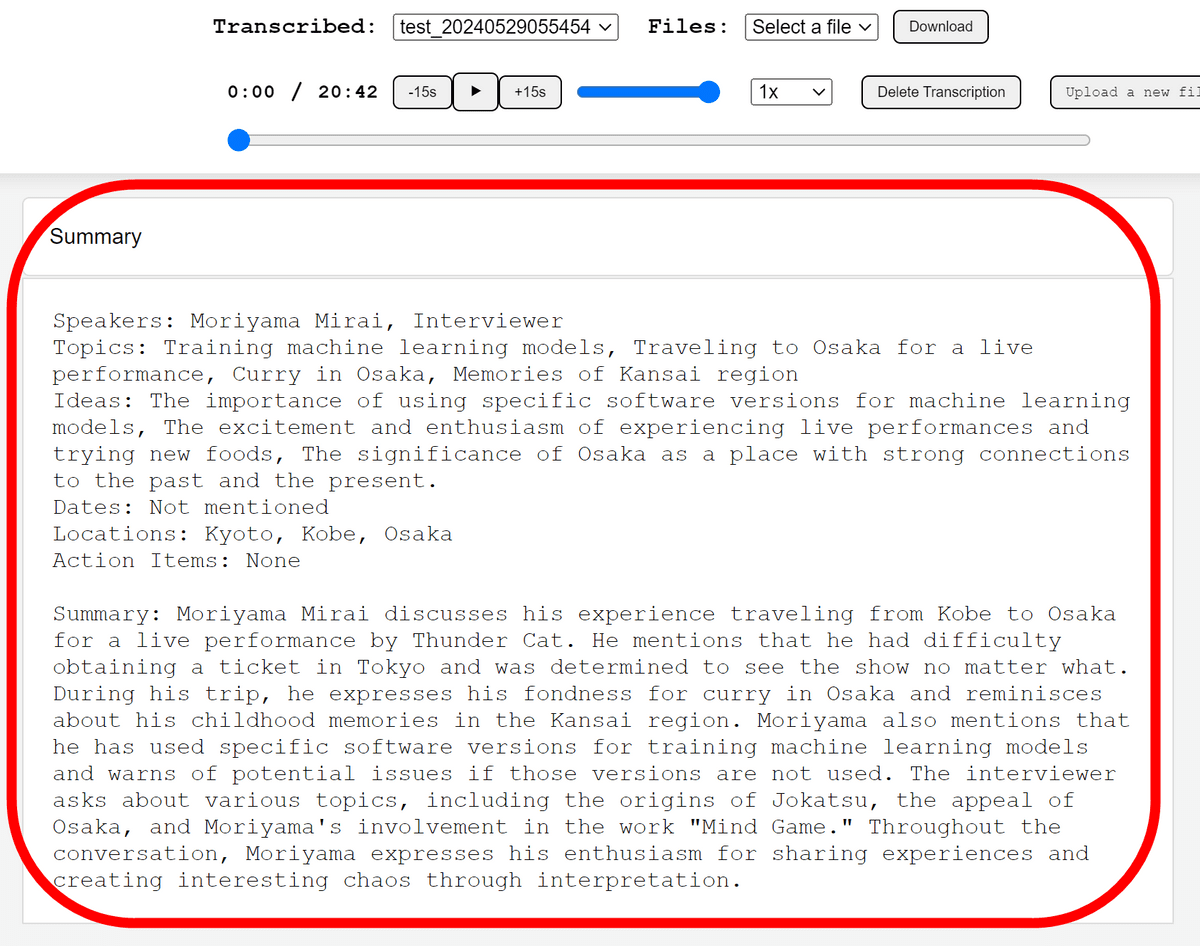
また、最初は要約が出力されていませんでしたが、しばらく待ってからページをリロードすると要約が出現していました。
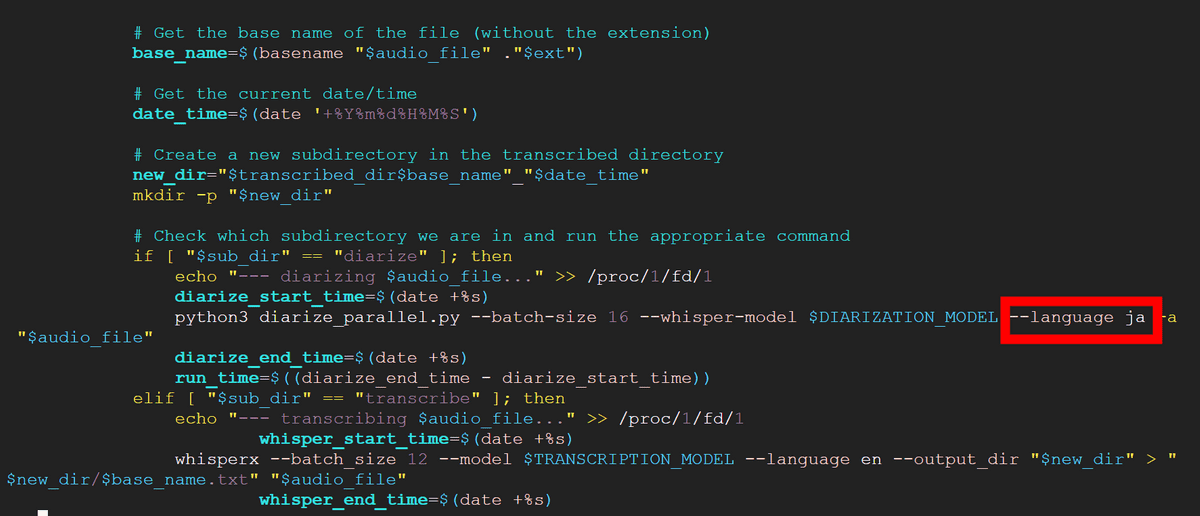
続いて日本語にできないかを試してみます。Issuesのページによると、「ts-gpu」ディレクトリ内にある「transcribe_example_d.sh」の46行目の「--language」部分で言語を設定しているとのこと。テキストエディタでファイルを開き、「--language ja」と日本語に設定しました。
言語設定を変更したい場合は自分でDockerイメージをビルドする必要があるとのこと。ビルドは下記のコマンドで行えます。
chmod +x install.sh
./install.sh
ところが、ビルドに失敗してしまいました。

作者によると「次回のアップデートで環境変数で言語を選択できるようにする予定」とのことなので、アップデートを待てば日本語で利用できそうです。
・関連記事
文字起こしAI「Whisper」を誰でも簡単に使えるようにした超高精度文字起こしアプリ「writeout.ai」使い方まとめ、オープンソースでローカルでも動作OK - GIGAZINE
超高精度な国産音声認識AI「ReazonSpeech」が無償公開されたので文字起こし機能を使ってみた - GIGAZINE
AppleがiOS 17.4をリリース、新しい絵文字・ポッドキャストの文字起こし対応・デフォルトブラウザの選択・サードパーティーブラウザエンジンのサポートなど - GIGAZINE
自分の行動を毎日24時間録音してWhisperで文字起こしする「全自動口述日記」を1週間つけつづけたエンジニアの報告 - GIGAZINE
1100以上の言語で音声からの文字起こしや文章の読み上げが可能な音声認識モデル「Massively Multilingual Speech(MMS)」をMetaが発表 - GIGAZINE
・関連コンテンツ



in AI, ソフトウェア, レビュー, ウェブアプリ, Posted by log1d_ts
You can read the machine translated English article Review of 'Transcription Stream', a free….