




1100以上の言語で音声からの文字起こしや文章の読み上げが可能な音声認識モデル「Massively Multilingual Speech(MMS)」をMetaが発表
AI開発に注力しているMetaが、1100以上の言語で音声からの文字起こしや文章の読み上げが可能な音声認識モデル「Massively Multilingual Speech(MMS)」を発表しました。MMSは従来の大規模多言語音声認識モデルを大幅に上回る言語に対応しており、話者の少ない言語でもさまざまな情報にアクセスしやすくなると期待されています。
Today we're sharing new progress on our AI speech work. Our Massively Multilingual Speech (MMS) project has now scaled speech-to-text & text-to-speech to support over 1,100 languages — a 10x increase from previous work.
— Meta AI (@MetaAI) May 22, 2023
Details + access to new pretrained models ⬇️
Introducing speech-to-text, text-to-speech, and more for 1,100+ languages
https://ai.facebook.com/blog/multilingual-model-speech-recognition/

fairseq/examples/mms at main · facebookresearch/fairseq · GitHub
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
Metaは以前から世界中の言語をリアルタイムで翻訳するAI「Babelfish(バベルフィッシュ)」の開発を発表するなど、音声認識・翻訳AIの開発に力を入れてきました。MMSについて発表したブログ記事の中で、Metaは「音声を認識・生成する能力を機械に持たせることで、音声だけで情報にアクセスしている人を含めて、より多くの人々が情報にアクセスできるようになります」と述べています。
質の高い機械学習モデルを生成するためには大量のラベル付きデータが必要であり、音声認識モデルの場合は数千時間もの音声およびその文字起こしデータが求められます。しかし、地球上で話されている7000以上の言語のうち大半はこのような質の高いデータが存在せず、既存の音声認識モデルは約100ほどの言語をカバーしているにとどまっているそうです。
そこでMetaは、ラベルのないデータから学習を行うことができる自己教師あり学習を採用した音声認識フレームワーク「Wav2vec 2.0」を使用し、MMSプロジェクトにおいて話者の少ない言語におけるラベル付きデータの不足を克服したと述べています。また、Metaはプロジェクトの一環として1100以上の言語にわたる「新訳聖書の読み上げデータセット」を作成し、MMSをトレーニングしています。新訳聖書をはじめとする宗教文献はさまざまな言語に翻訳されており、テキストベースの言語翻訳研究のために広く研究されているため、音声認識モデルの開発においても有用だとのこと。
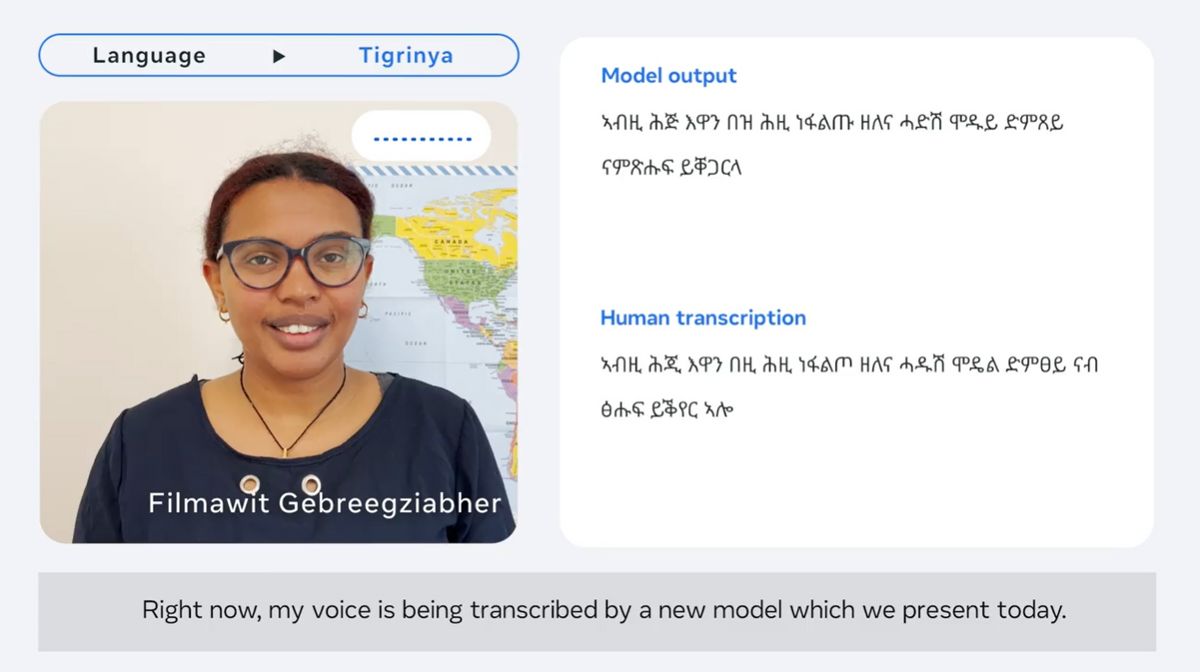
Metaが公開している動画では、MMSがさまざまな言語をリアルタイムで文字起こししている様子を見ることができます。エリトリアやエチオピアで話されているティグリニャ語はこんな感じ。
フィリピンのルソン島北部で話されているイロカノ語。

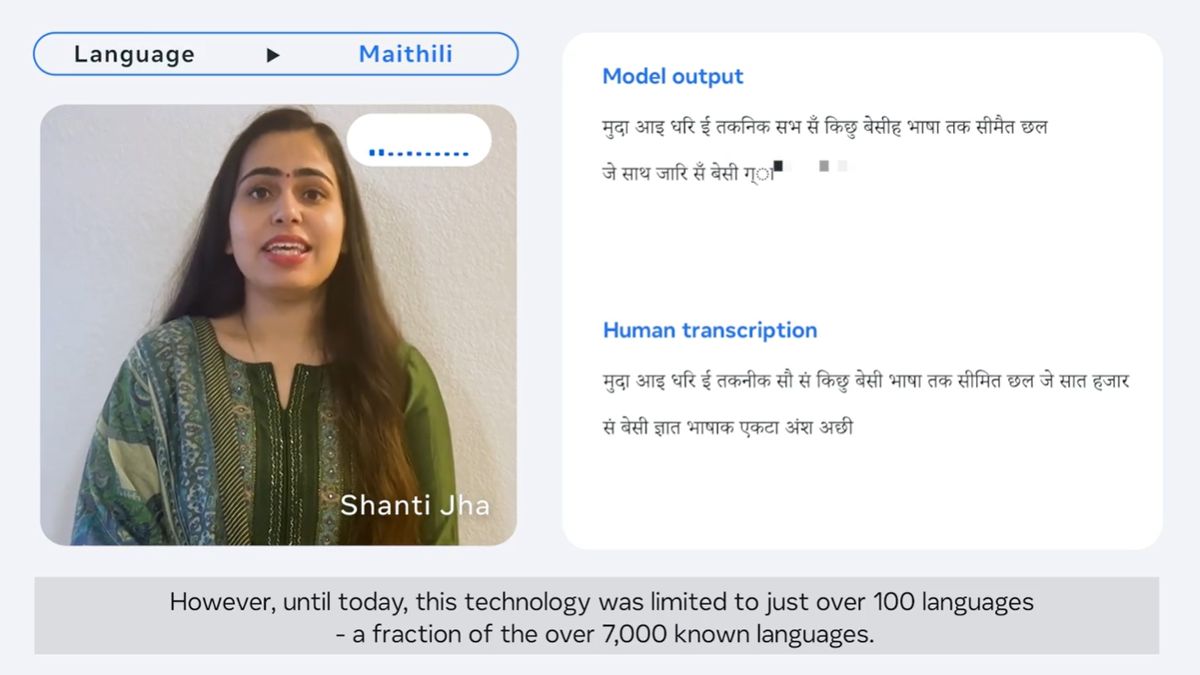
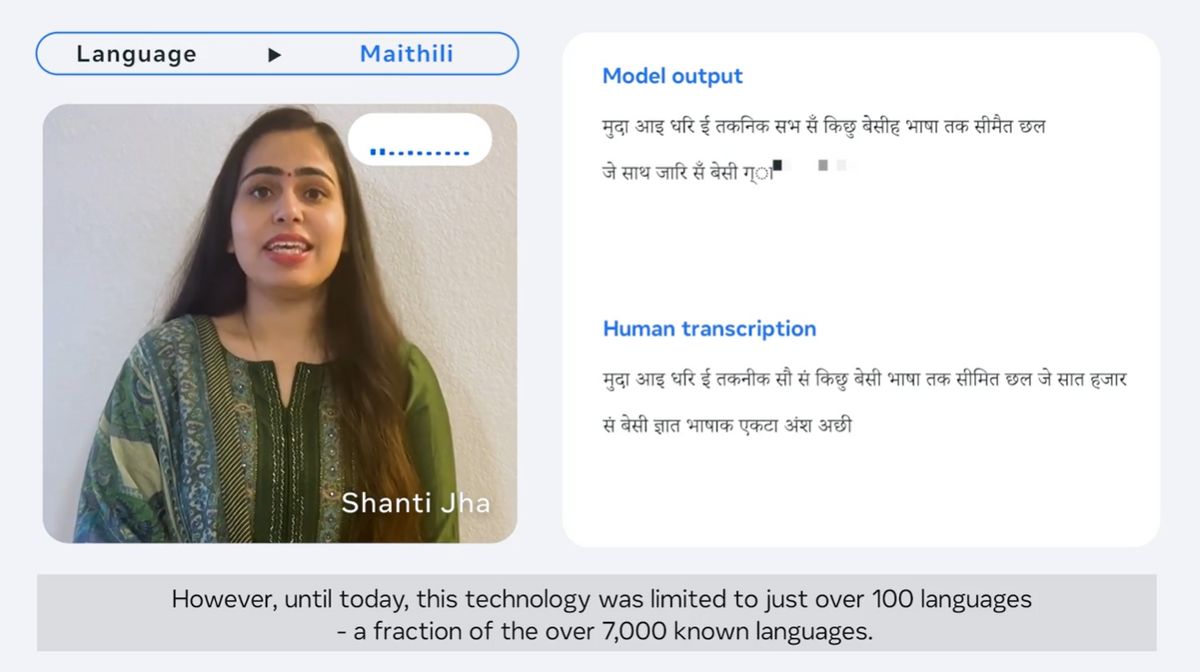
インドやネパールの一部で話されているマイティリー語。
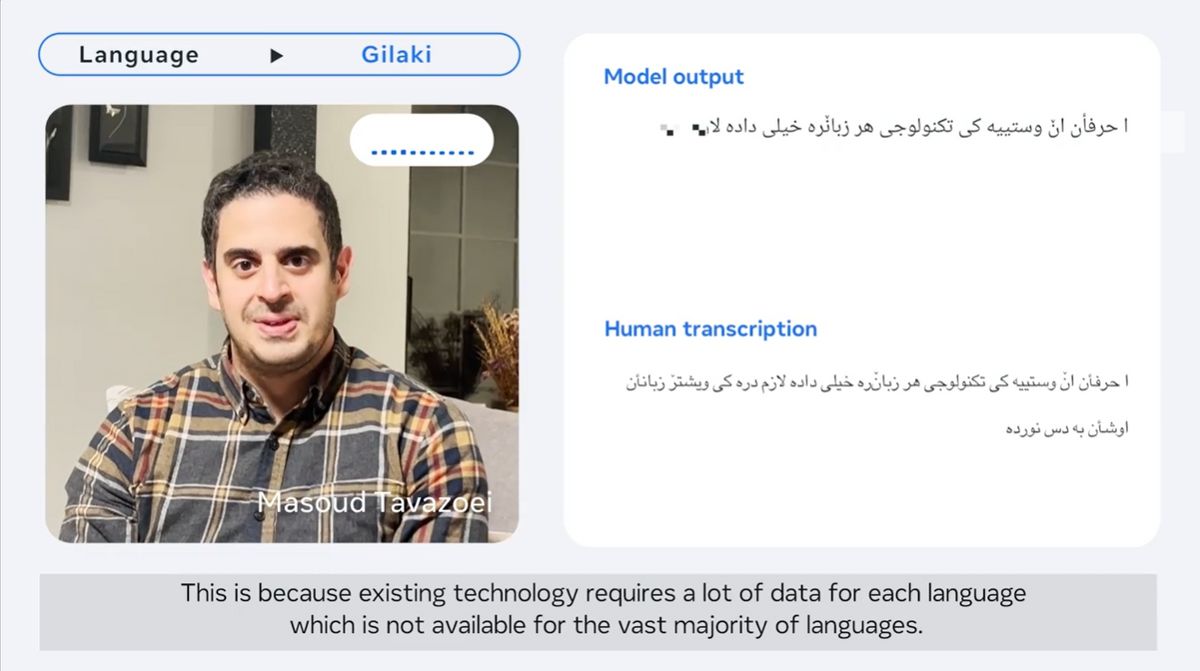
イラン北部から西部にかけて話されているギラキ語。
ナイジェリアやベナン、トーゴに住むヨルバ人が使用するヨルバ語。
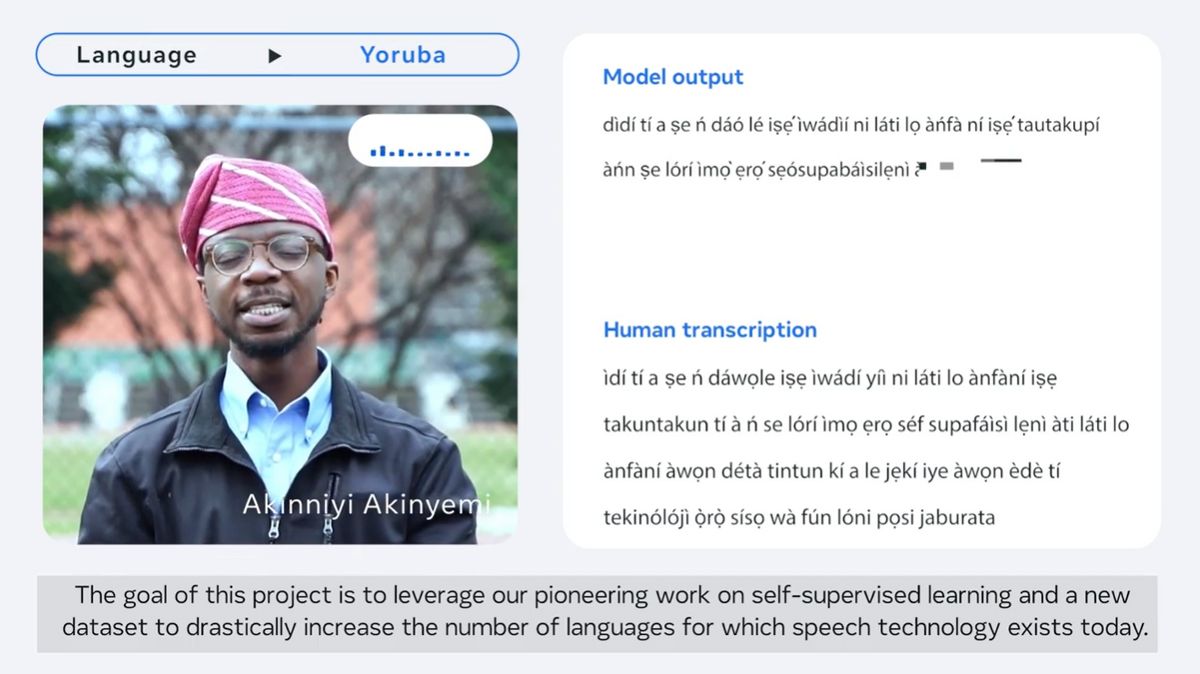
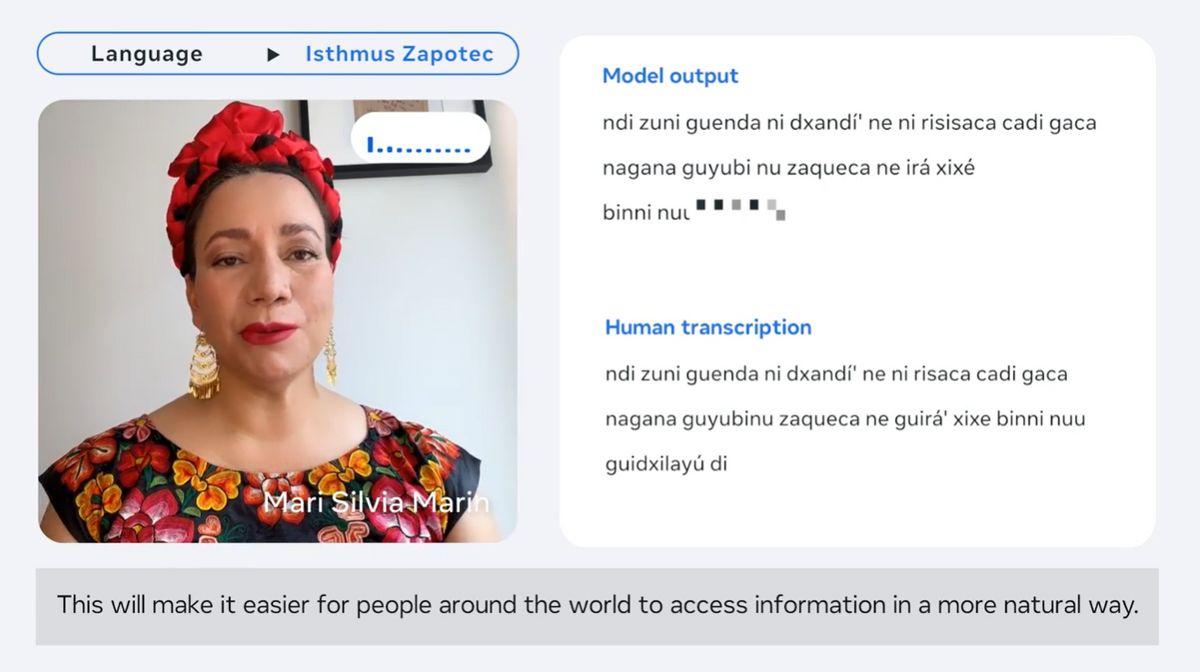
メキシコの先住民族であるサポテコ族のうち、約8万5000人ほどが話すという地峡サポテク語。
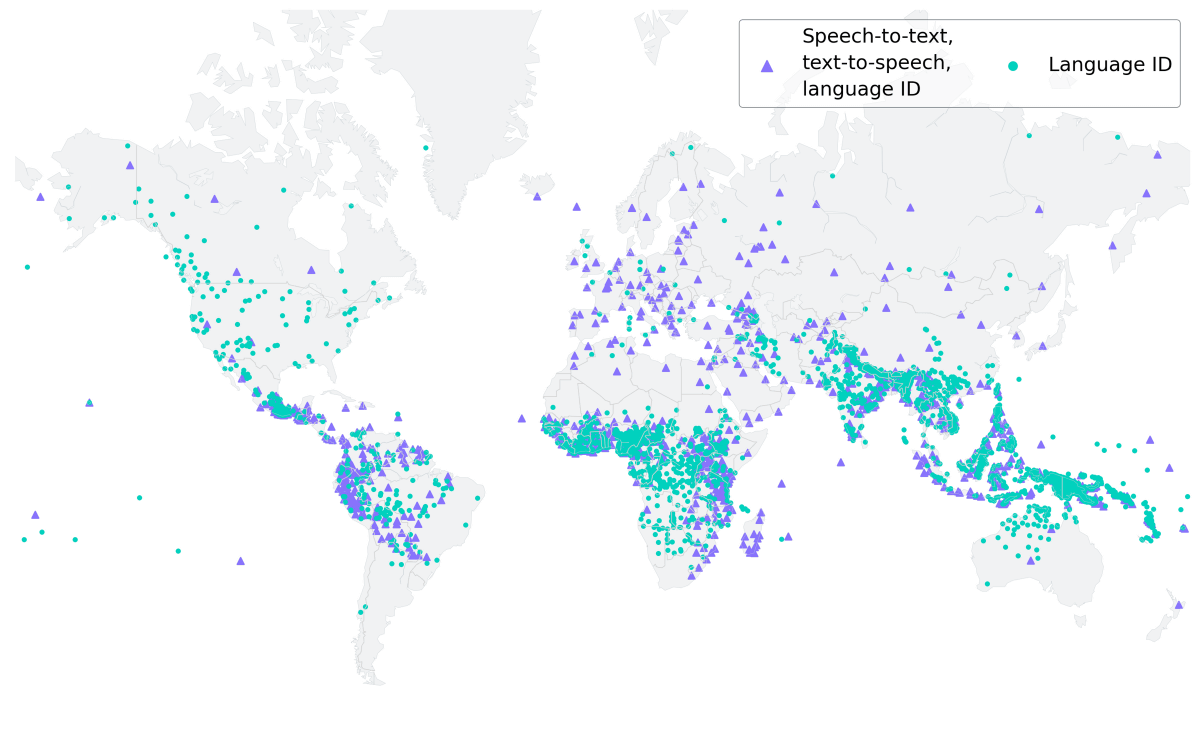
MMSでは、以下の世界地図に紫色の三角形で示されている1107の言語で文字起こしや文章読み上げに対応しており、緑色の丸で示された4000以上の言語を識別することができるとのこと。
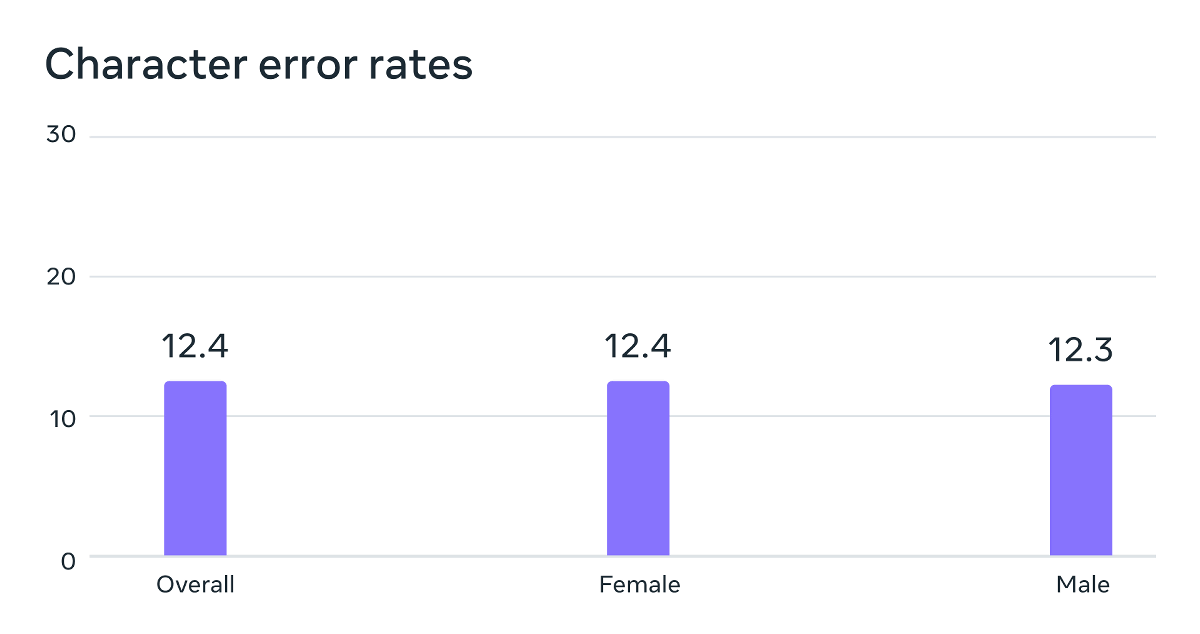
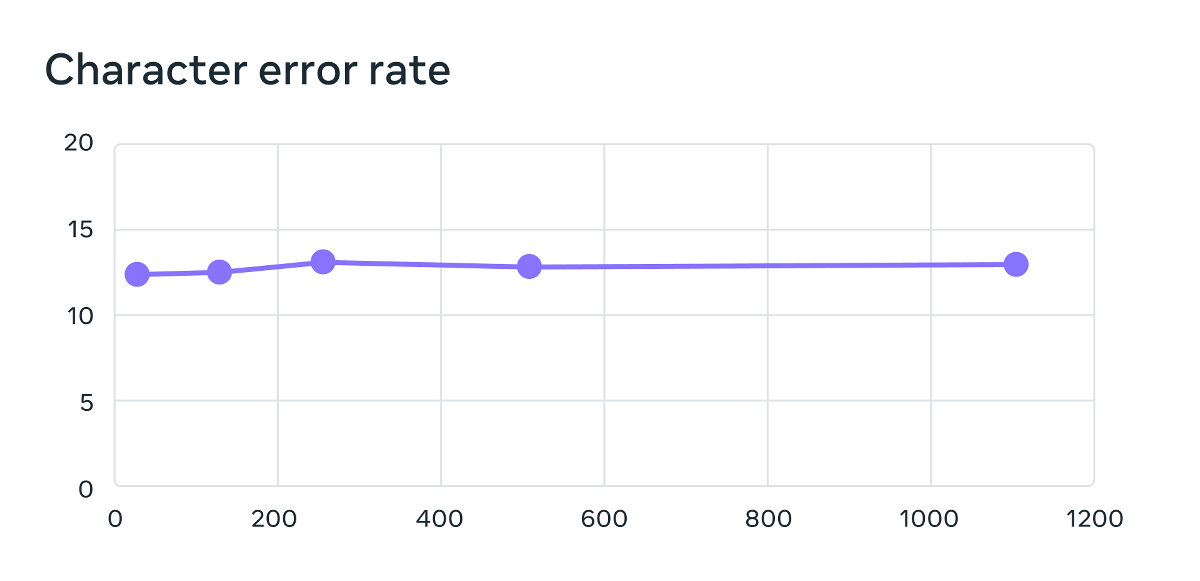
トレーニングに使用した音声データは男性話者によって読み上げられたものが多かったそうですが、Metaの分析によると、MMSは男性の声と女性の声に対してほぼ同等に機能することが示されています。音声認識のエラー率を調べた以下のグラフを見ると、男性(Male)のエラー率は12.3であり、女性(Female)のエラー率は12.4となっています。
また、自己教師あり学習を採用したWav2vec 2.0を用いてトレーニングされたMMSは、言語の数が61から1107に増えてもエラー率が0.4%しか増加しなかったとMetaは述べています。
Metaは、「世界中で数多くの言語が消滅の危機に直面しており、音声認識や音声生成技術の限界がこの傾向をさらに加速させるでしょう。私たちは、テクノロジーがこの傾向を逆転させる効果をもたらし、人々が自分の好きな言語で情報にアクセスし、テクノロジーを利用できることで、言語が維持される世界を構想しています。MMSはこの方向への大きな一歩を踏み出すものです」と述べました。
Metaは研究コミュニティがMMSに基づいてさらなる研究を進められるよう、モデルとコードをGitHubで公開しています。
fairseq/examples/mms at main · facebookresearch/fairseq · GitHub
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
TwitterユーザーからはMMSについて称賛する声が多数寄せられており、あるユーザーはMMSがオープンソースで公開されている点を高く評価していました。
They're open and available for everyone ???? Meta is the greatest most generous tech company ever https://t.co/U0cOEevCGH pic.twitter.com/46CEL4m2U4
— Bryan Cheong (@bryancsk) May 22, 2023
・関連記事
Metaの「LLaMA」と同規模のAIモデル構築をオープンソースで目指す「RedPajama」開発元のTogetherが2000万ドルの資金調達に成功 - GIGAZINE
Metaが200の言語で機能するAI翻訳モデルをオープンソース化、 メタバースで世界中の人々が交流できることを目指す - GIGAZINE
AIを駆使した音声翻訳システムをMetaが公開、テキストデータの収集が困難なマイナー言語にも対応 - GIGAZINE
Metaが大規模言語モデル「LLaMA」を発表、GPT-3に匹敵する性能ながら単体のGPUでも動作可能 - GIGAZINE
Metaが言語・画像・音声など複数分野に適応できる自己学習型AI「data2vec」を発表 - GIGAZINE
無料でOpenAIの「Whisper」を使って録音ファイルから音声認識で文字おこしする方法まとめ - GIGAZINE
文字起こしAI「Whisper」を誰でも簡単に使えるようにした超高精度文字起こしアプリ「writeout.ai」使い方まとめ、オープンソースでローカルでも動作OK - GIGAZINE
・関連コンテンツ






in AI, 動画, ソフトウェア, Posted by log1h_ik
You can read the machine translated English article Meta announces `` Massively Multilingual….