




Metaが言語・画像・音声など複数分野に適応できる自己学習型AI「data2vec」を発表

Facebookを運営するMetaがあらゆる分野に適応できる自己学習型AI「Data2vec」を開発したと発表しました。
Data2vec: The first high-performance self-supervised algorithm that works for speech, vision, and text
https://ai.facebook.com/blog/the-first-high-performance-self-supervised-algorithm-that-works-for-speech-vision-and-text
Introducing the First Self-Supervised Algorithm for Speech, Vision and Text | Meta
https://about.fb.com/news/2022/01/first-self-supervised-algorithm-for-speech-vision-text/
Metaによると、2022年時点で開発されているAIの多くは人間があらかじめ付けた正解・不正解のラベルに基づいて学習していく……という教師あり学習です。しかし、AIに学んで欲しいありとあらゆる事柄に対して人間が前もってラベルを用意しておくというのは実質的に不可能という問題が存在します。そこで、現行の研究が焦点を合わせているのが「人間が正解・不正解を教えずとも自分で学習してくれるAI」の開発です。
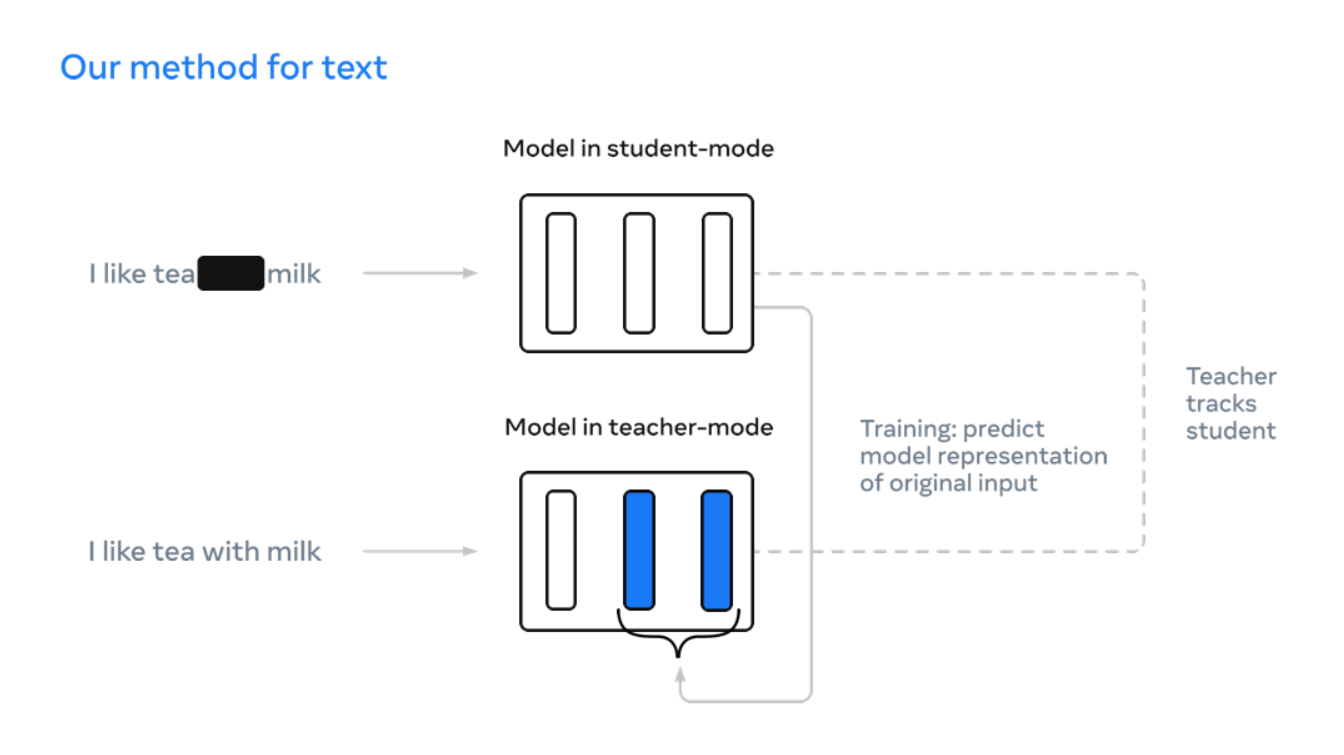
ところがMetaによると、「自分で学習してくれるAIの開発」という目的は共通していたとしても、言語・画像・音声という分野によって、アプローチが大きく異なる状態が続いていたとのこと。こうした状況の中、新たにMetaが開発した「Data2vec」は、異なる分野でも同じように機能するという自己学習型AIで、画像であっても文章であっても音声であっても、ニューラルネットワークのレイヤーに焦点を当てることにより、単一のアルゴリズムによって異なる種類の入力データをさばけるとのこと。
具体的なトレーニング方法は以下。まず、AIを「教師側」「生徒側」の2つの役割に分け、教師側には犬の画像ならば犬の顔部分を黒塗りにするといった「お題の一部を伏せる」という作業を行わせます。続いて生徒側には「伏せられた部分を予測して埋める」という作業を行わせ、この繰り返しによって自己学習を深めていくとのこと。

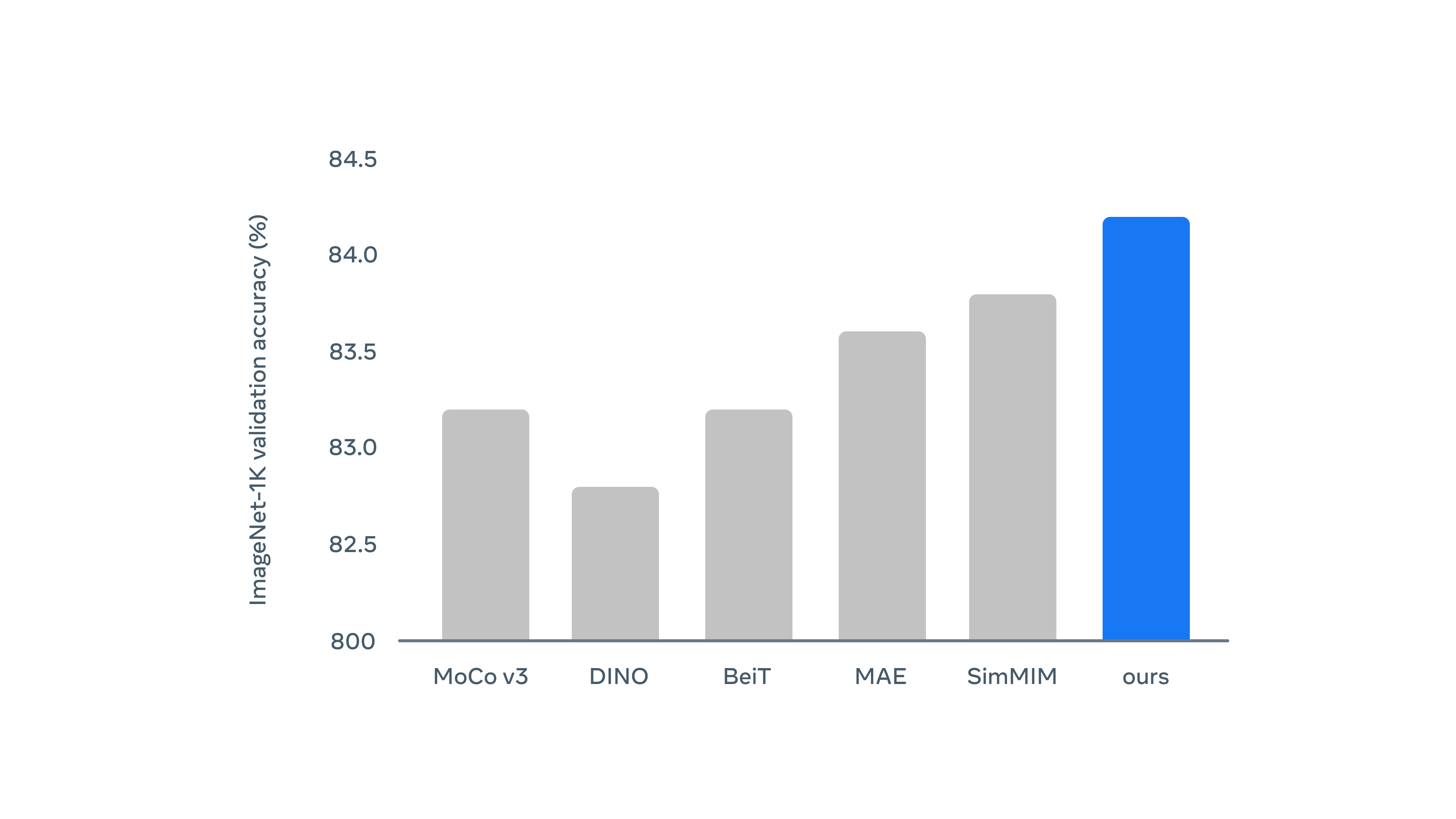
Data2vecは画像認識に関しては既存のアルゴリズムよりも優秀な成績が得られるそうですが……
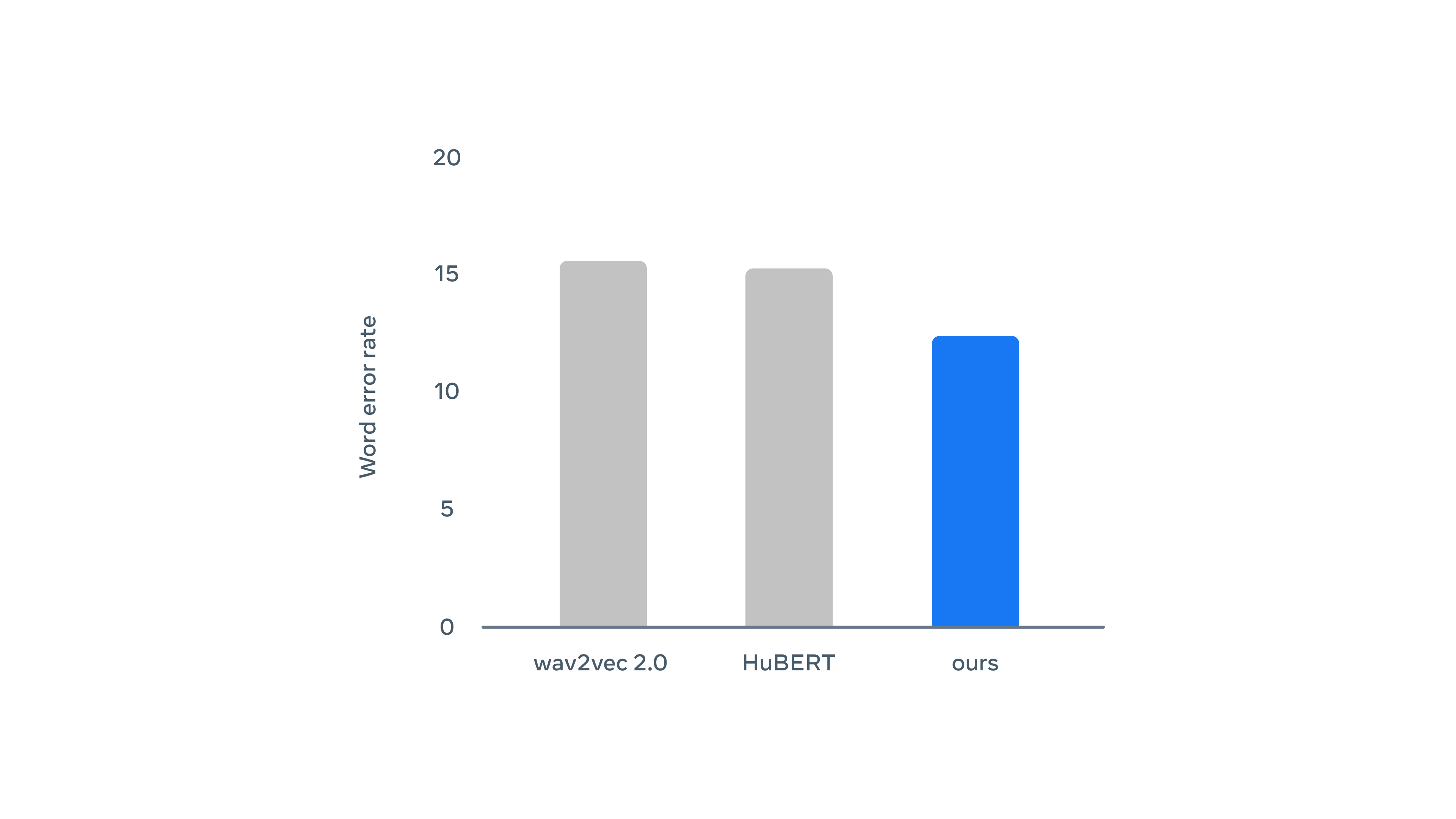
音声検出に関してはwav2vec 2.0とHuBERTに敗北。
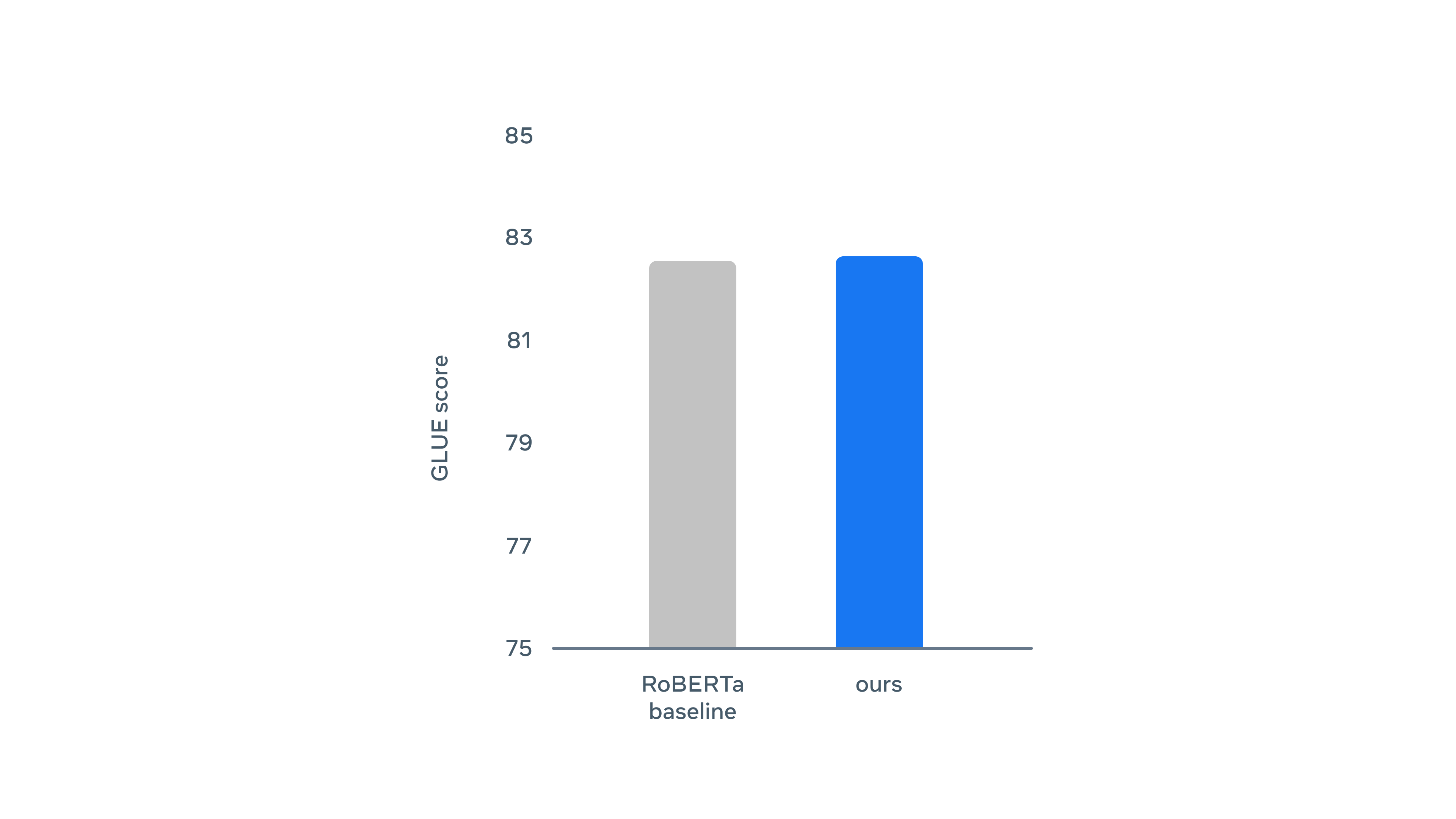
自然言語理解についてはBERTの改良版であるRoBERTaとほぼ同等とのことでした。
・関連記事
Facebookが「写真に写り込んだ単語を違和感なく置き換えるAI」を開発 - GIGAZINE
10億枚以上のInstagramに投稿された写真を用いて学習した画像認識モデル「SEER」をFacebookが発表 - GIGAZINE
Facebookが英語を経由せずに100個の言語を直接翻訳できる新しい機械翻訳システムを開発 - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Meta announces self-learning AI 'data2ve….