Meta announces self-learning AI 'data2vec' that can adapt to multiple fields such as language, image, voice

Meta, which operates Facebook, announced that it has developed a self-learning AI 'Data2vec' that can be adapted to all fields.
Data2vec: The first high-performance self-supervised algorithm that works for speech, vision, and text
Introducing the First Self-Supervised Algorithm for Speech, Vision and Text | Meta
https://about.fb.com/news/2022/01/first-self-supervised-algorithm-for-speech-vision-text/
According to Meta, most of the AI developed as of 2022 is supervised learning in which humans learn based on the labels of correct and incorrect answers that are attached in advance. However, there is the problem that it is virtually impossible for humans to prepare labels in advance for everything that AI wants to learn. Therefore, the current research is focusing on the development of 'AI that humans can learn by themselves without teaching correct or incorrect answers'.
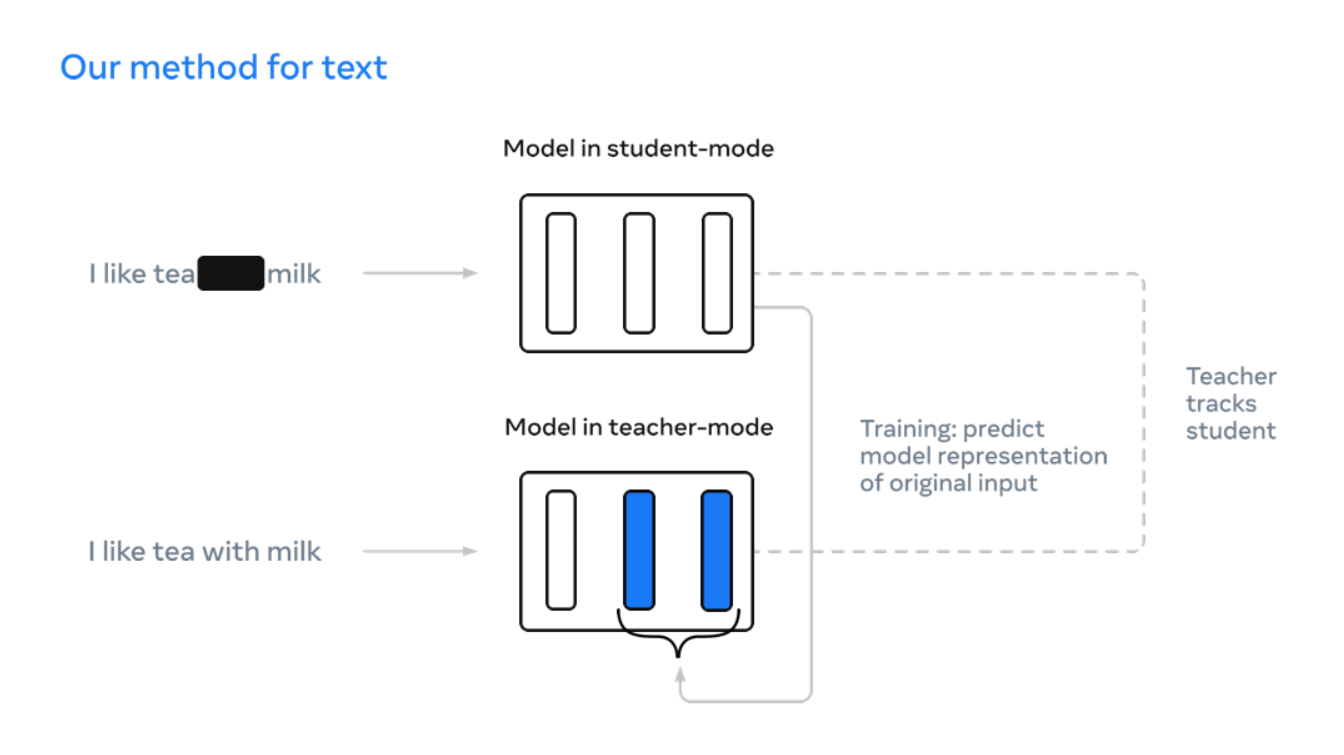
However, according to Meta, even if the purpose of 'development of AI that learns by oneself' is common, the approach has continued to differ greatly depending on the fields of language, image, and voice. Under these circumstances, 'Data2vec' newly developed by Meta is a self-learning AI that functions in the same way in different fields, and is a neural network for images, sentences, and voices. By focusing on layers, a single algorithm can handle different types of input data.
The specific training method is as follows. First, AI is divided into two roles, 'teacher side' and 'student side', and on the teacher side, the work of 'turning down a part of the theme' such as blackening the dog's face if it is a dog image is done. Let me do it. Next, the students are asked to perform the work of 'predicting and filling the hidden part', and by repeating this, self-learning will be deepened.

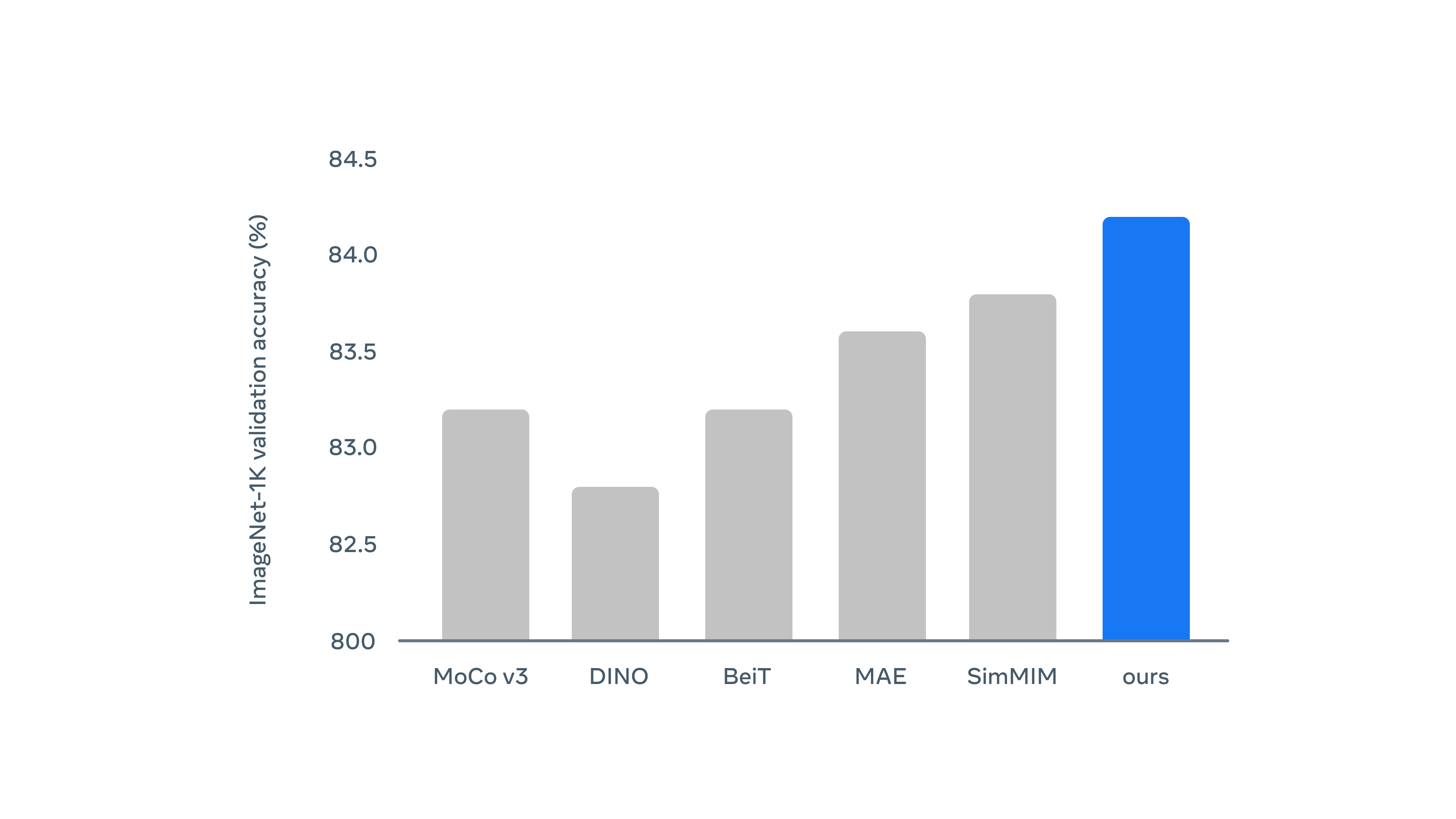
Data2vec seems to get better results than existing algorithms when it comes to image recognition ...
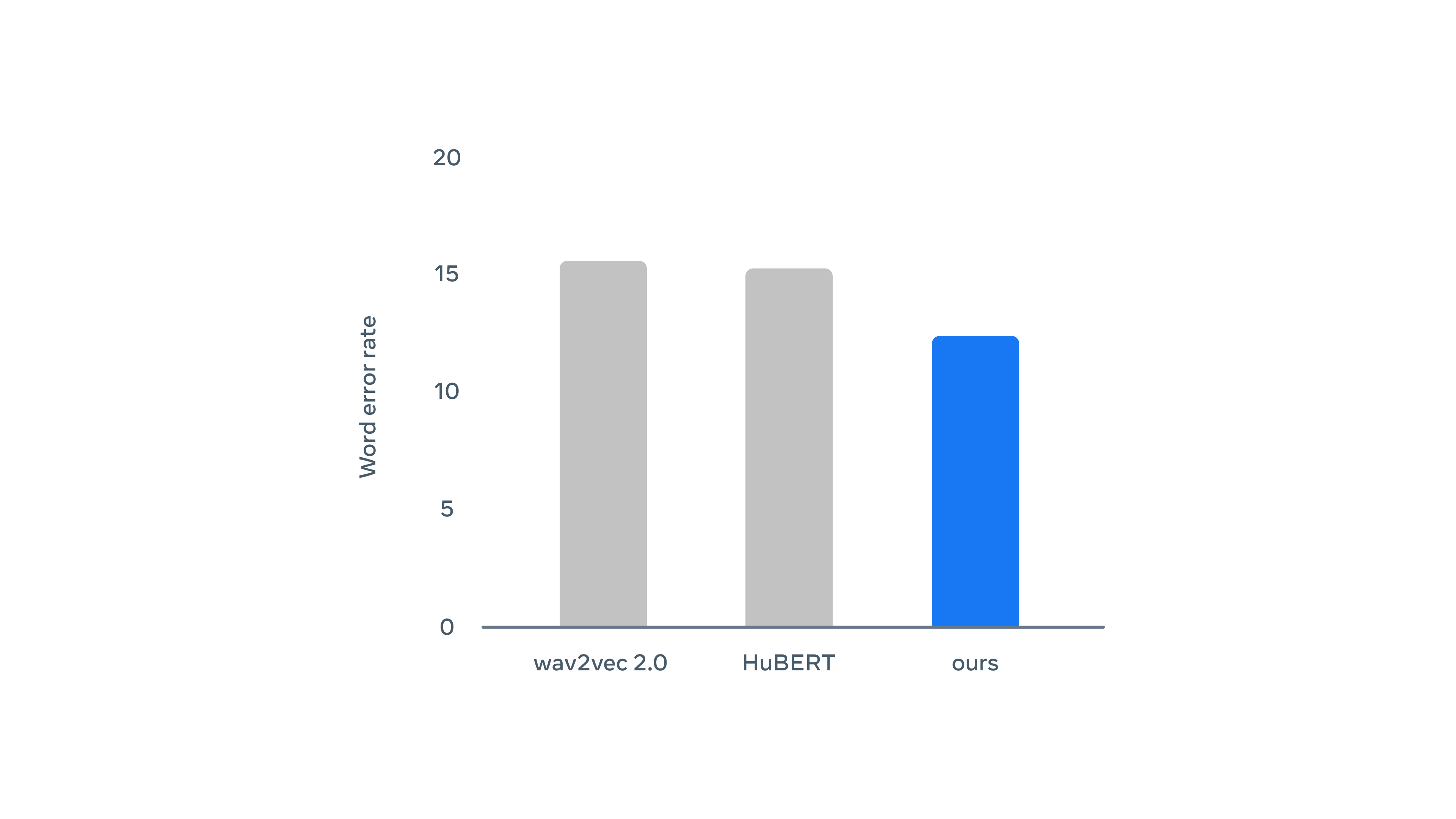
Lost to wav2vec 2.0 and HuBERT for voice detection.
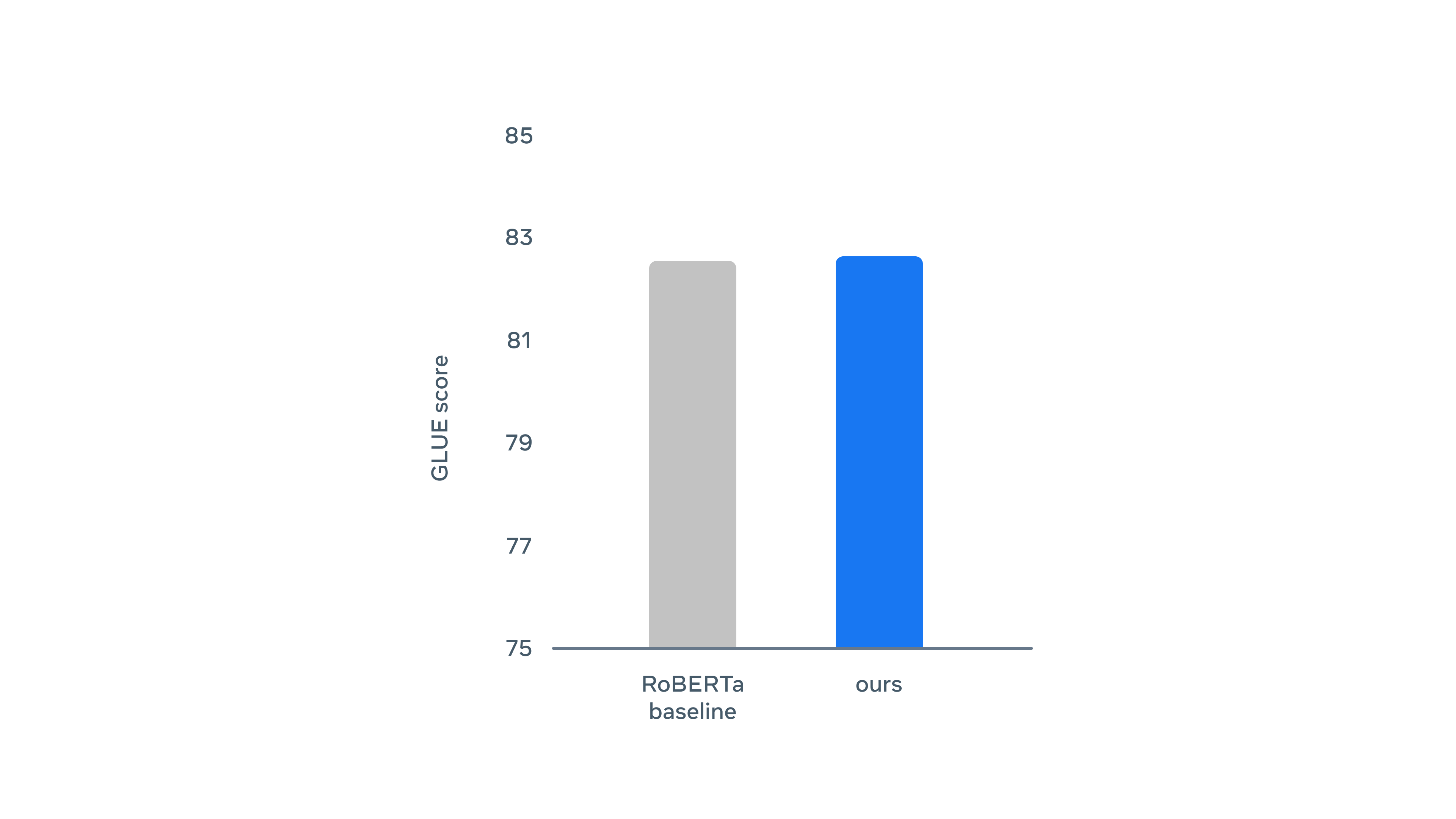
Regarding natural language understanding, it was almost the same as RoBERTa, which is an improved version of BERT.
Related Posts:






in Software, Posted by darkhorse_log