




大規模言語モデルへの入力プロンプトを意味を保ったまま高度に圧縮する技術「LLMLingua」をMicrosoftが開発

近年はさまざまな大規模言語モデルが台頭し、入力するプロンプトを工夫することで高精度な回答を得る方法も数多く生み出されています。しかし、入力プロンプトがあまりにも長くなりすぎると、チャットウィンドウの上限を超えてしまったり、APIのコストが増大してしまったりするデメリットも生じます。そこでMicrosoft Researchの研究チームは、意味を保ったまま入力プロンプトを圧縮する新たな技術「LLMLingua」を開発しました。
LLMLingua | Designing a Language for LLMs via Prompt Compression
https://llmlingua.com/
LLMLingua - Microsoft Research
https://www.microsoft.com/en-us/research/project/llmlingua/
LLMLingua: Innovating LLM efficiency with prompt compression - Microsoft Research
https://www.microsoft.com/en-us/research/blog/llmlingua-innovating-llm-efficiency-with-prompt-compression/
大規模言語モデルで高精度の回答を得るためには、入力プロンプトを工夫する必要があるということが広く知られています。その中でChain-of-Thought(CoT:思考の連鎖)やIn-context Learning(ICL:コンテキスト内学習)といった技術が登場し、高品質の回答を引き出すために長いプロンプトを書くケースが増えています。
場合によってはプロンプトが数万トークンに達することもありますが、プロンプトが長くなりすぎると「チャットウィンドウの上限を超えてしまう」「文脈を保持した回答が難しくなる」「API応答の遅延が発生する」「入力や出力に必要なAPI使用料が高額になる」といった問題も発生します。
Microsoft Researchの研究チームは、大規模言語モデルへの入力プロンプトが長くなりすぎる問題に対処するため、意味を保持したままプロンプトを圧縮する技術「LLMLingua」を開発しました。
研究チームはLLMLinguaの開発にあたり、言語の整合性とプロンプト内のモジュール感度のバランスを取るため、「budget controller(予算コントローラー)」という仕組みを採用しました。これはGPT2-smallやLLaMA-7Bといった十分にトレーニングされた小さな言語モデルを使用し、重要でないトークンを識別してプロンプトから排除するというもの。さらに、残ったトークンを個別に圧縮すると共に、反復的なトークンレベルの圧縮アプローチを採用し、個々のトークン間の関係をより洗練させているとのこと。
これにより、大規模言語モデルが理解できる情報量を保ちつつ、人間が普段扱っている自然言語にありがちな冗長性を排除し、入力プロンプトを圧縮できるというわけです。たとえば以下の図を見ると、オリジナルのプロンプトは2366トークンを使用していたのに対し、LLMLinguaによる処理後のプロンプトはわずか117トークンまで圧縮されています。
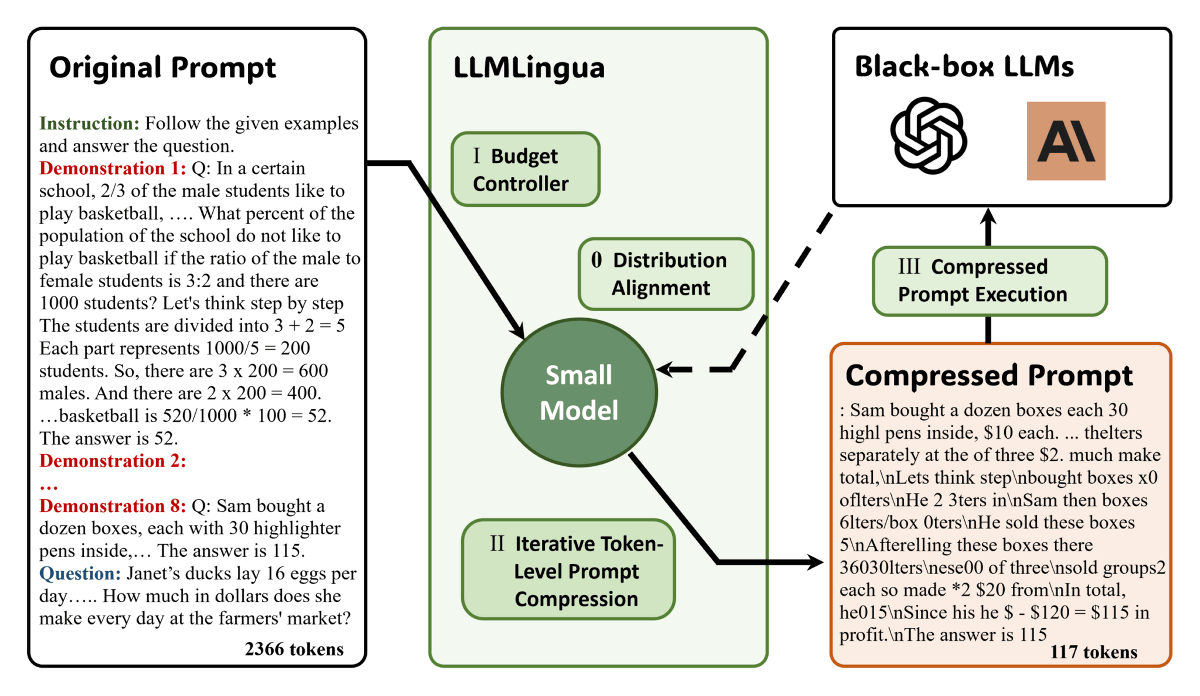
処理後のプロンプトは、人間にとっては読み取るのが困難ですが、大規模言語モデルが回答を出力するには十分な情報量が保たれているとのこと。ソーシャルニュースサイトのHacker Newsには、この圧縮されたプロンプトを指して「講義内容を箇条書きでメモしている人が書くような、少し文字化けしたような文章のように見えます。人間が最適化した入力と機械が最適化した入力がこれほど似ているのはとても珍しいです」と形容するコメントもみられました。

研究チームはLLMLinguaのパフォーマンスを評価するため、GSM8K・BBH・ShareGPT・Arxiv-March23という4つの異なるデータセットを用いて、LLMLinguaが生成した圧縮プロンプトをテストしました。予算コントローラーに使用する小型言語モデルにはLLaMA-7Bを、大規模言語モデルにはGPT-3.5-Turbo-0301を使用したとのこと。
テストの結果、LLMLinguaは特にICLと推論で元のプロンプトの意味を維持しながら最大20倍の圧縮率を達成し、対話や要約でもプロンプトの意味を維持し続けることができました。また、入力だけでなく大規模言語モデルが生成する回答のトークン数も、入力プロンプトの圧縮に伴って減少したと報告されています。

さらに、LLMLinguaで圧縮した入力プロンプトをGPT-4で復元したところ、9段階にわたるCoTプロンプト全体からすべての重要な推論情報を復元できたとのことです。
LLMLinguaのソースコードなどはGitHubで公開されています。
GitHub - microsoft/LLMLingua: To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss.
https://github.com/microsoft/LLMLingua
・関連記事
大規模言語モデルで「無限の入力」を受け付けることを可能にする手法「StreamingLLM」が開発される - GIGAZINE
AIに「それがファイナルアンサーなの?」「全力を尽くして」といった感情的な命令文を伝えるとパフォーマンスが向上する - GIGAZINE
AIに「深呼吸しよう」といった人間っぽい言葉をかけると問題の正答率が上昇するという研究結果 - GIGAZINE
ChatGPTの性能低下はホリデーシーズンに休むことを学習したからだという「冬休み仮説」が浮上 - GIGAZINE
画像生成AI「DALL-E」のシステムメッセージが発見され「プロンプトは大文字にした方がいいのか?」などと指摘されてしまう事態に - GIGAZINE
画像生成AIでプロンプトのフォントサイズ・色・スタイル・脚注を反映して画像を調整する技術が登場 - GIGAZINE
イーロン・マスクの人工知能企業xAIがプロンプトエンジニアリング用統合開発環境「PromptIDE」を発表 - GIGAZINE
AIの力だけでAngry Birdsのコピーゲームを作成したエンジニアが登場、作成時に使用したプロンプトも公開中 - GIGAZINE
・関連コンテンツ








in ソフトウェア, ネットサービス, Posted by log1h_ik
You can read the machine translated English article Microsoft develops ``LLMLingua''….