




わずか4GBの実行ファイル1つで大規模言語モデルによるAIを超お手軽に配布・実行できる仕組み「llamafile」をWindowsとLinuxで簡単に実行してみる方法

「llamafile」は大規模言語モデルのモデルやウェイトの情報が1つの実行ファイルにまとまった形式のファイルです。Linux・macOS・Windows・FreeBSD・NetBSD・OpenBSDという6つのOS上でインストール不要で大規模言語モデルを動作させることが可能とのことなので、実際にWindowsおよびLinuxディストリビューションの1つであるDebian上で動かしてみました。
Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.
https://github.com/Mozilla-Ocho/llamafile#readme
Introducing llamafile - Mozilla Hacks - the Web developer blog
https://hacks.mozilla.org/2023/11/introducing-llamafile/
llamafile形式で配布されているモデルは下記の通り。今回はこのうち、画像を認識できるモデルの「LLaVA 1.5」を動作させてみます。
| Model | License | Command-line llamafile | Server llamafile |
|---|---|---|---|
| Mistral-7B-Instruct | Apache 2.0 | mistral-7b-instruct-v0.1-Q4_K_M-main.llamafile (4.07 GB) | mistral-7b-instruct-v0.1-Q4_K_M-server.llamafile (4.07 GB) |
| LLaVA 1.5 | LLaMA 2 | (提供なし) | llava-v1.5-7b-q4-server.llamafile (3.97 GB) |
| WizardCoder-Python-13B | LLaMA 2 | wizardcoder-python-13b-main.llamafile (7.33 GB) | wizardcoder-python-13b-server.llamafile (7.33GB) |
◆Windowsで動かしてみた
llava-v1.5の実行ファイルをダウンロードし、名前を編集して最後に「.exe」を加えます。
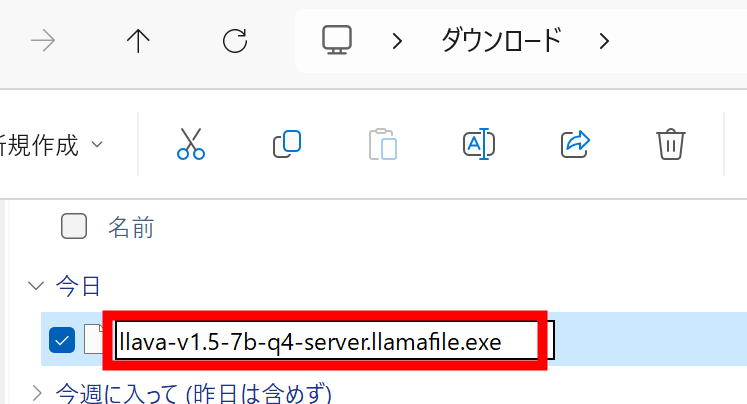
警告が出るので「はい」をクリック。
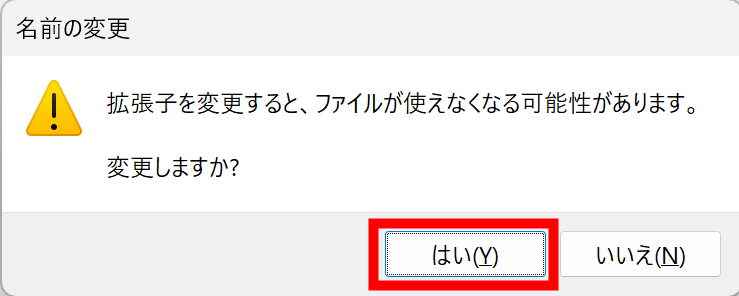
ダブルクリックして実行するとMicrosoft Defender SmartScreenの画面が表示されます。「詳細情報」をクリックします。
「実行」ボタンが出現するのでクリックして実行します。

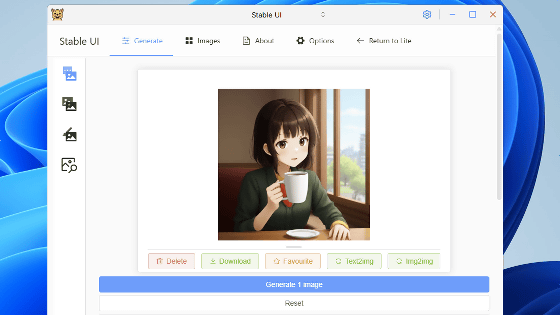
無事サーバーが起動してブラウザが自動で開き、下図のようにllama.cppのUIが出現しました。
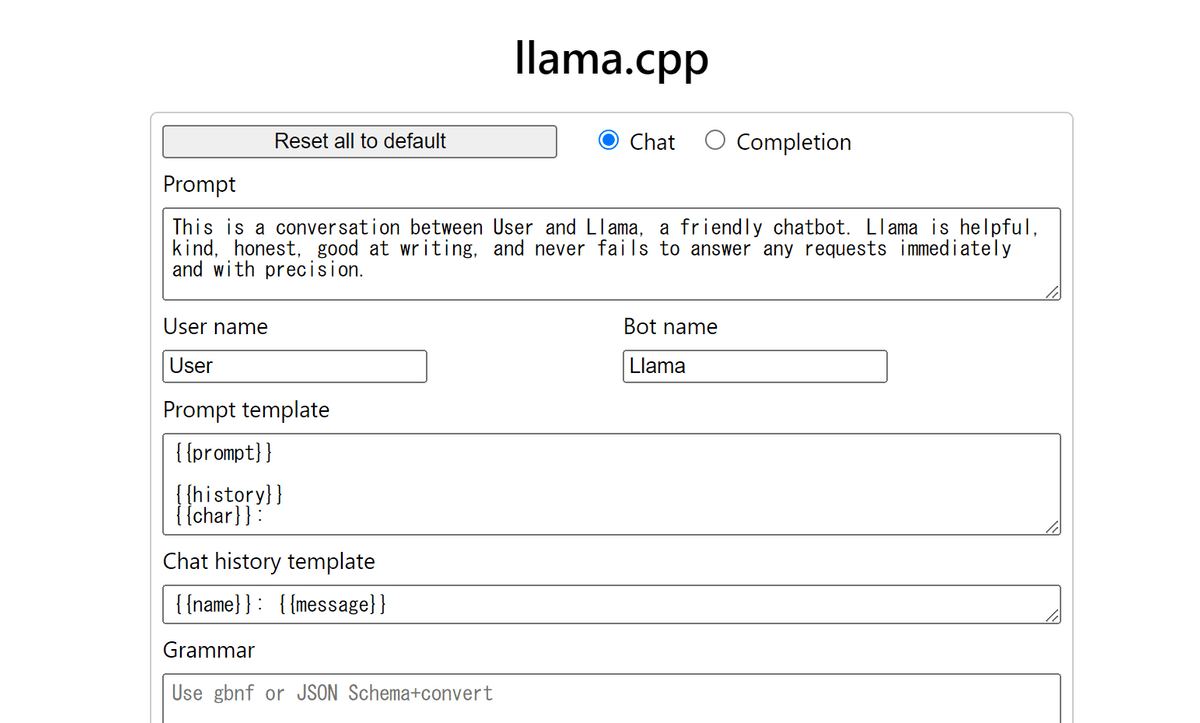
今回は画像を認識できるモデルのLlavaを試すということで、下の画像の説明を依頼してみます。

最下部にある「Upload Image」をクリックし、画像を選択して「開く」をクリック。
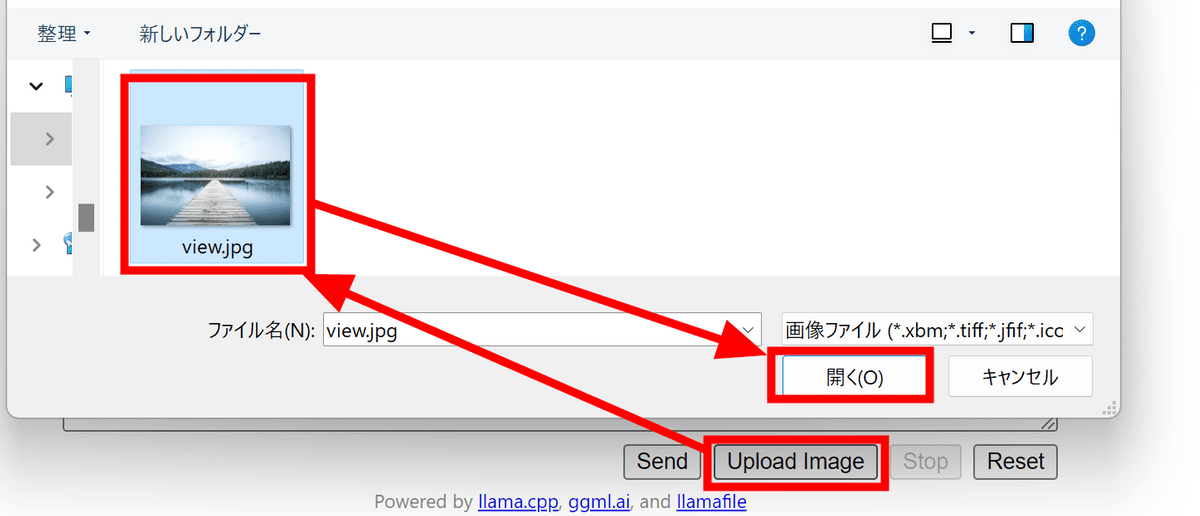
UIが変化しないため正しくアップロードされているのか不安ですが、テキストを入力して「Send」をクリックします。
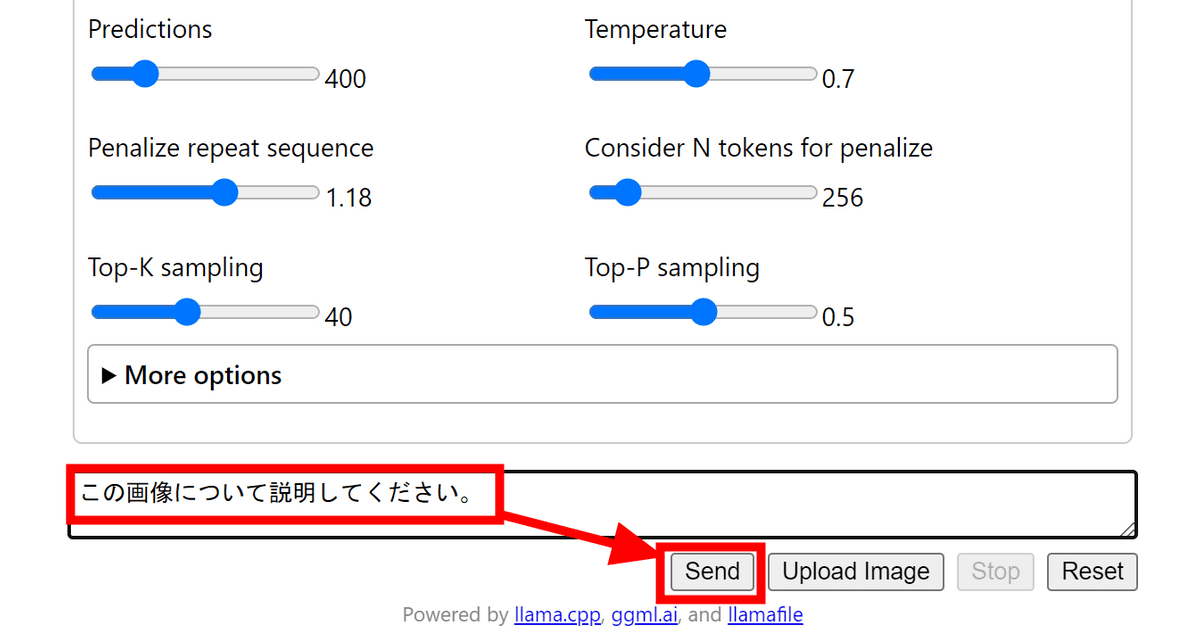
すると下図のように画面が切り替わり、画像とプロンプトが入力されました。
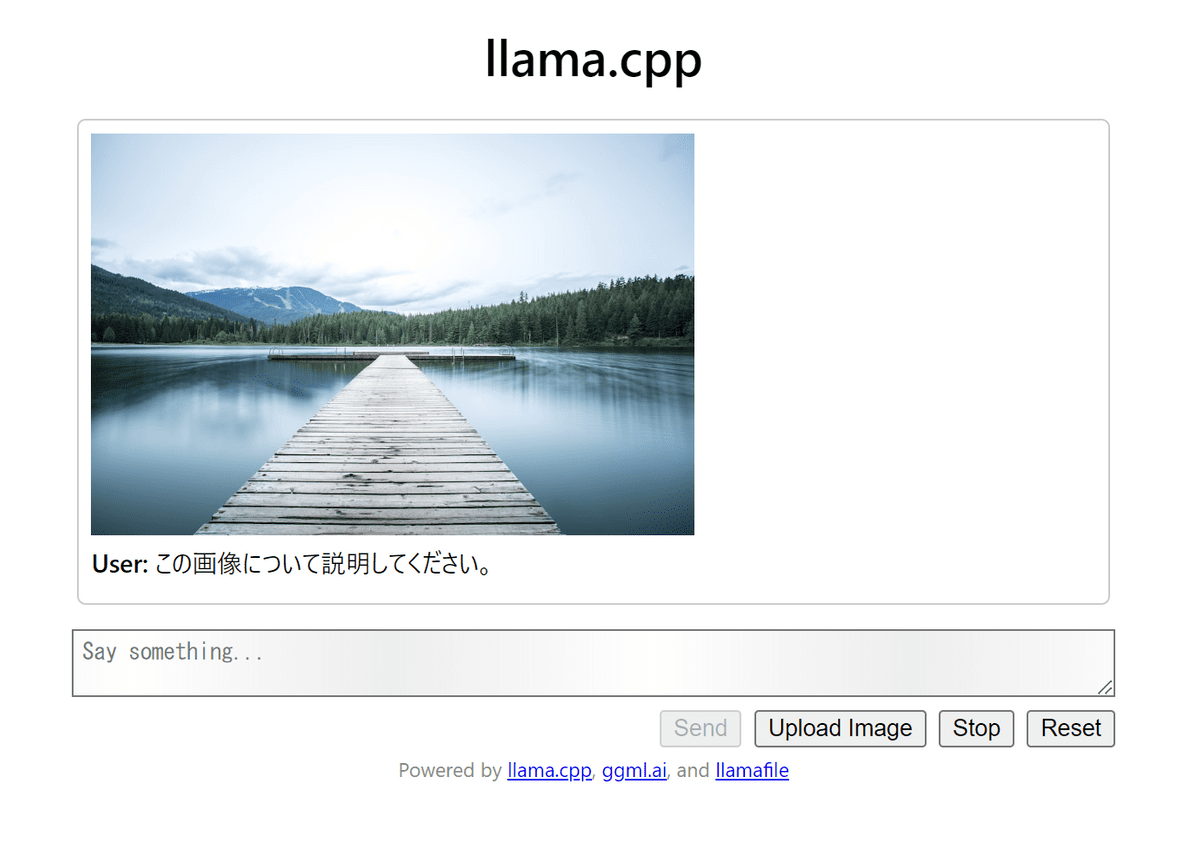
推論中のCPU使用率とメモリ使用量はこんな感じ。CPU使用率は高い物のメモリの消費量はほぼゼロと表示されています。
他のプロセスとして表示されているのかなと思いましたが、メモリの使用量順に並べ替えてみても特にそれらしいプロセスはありませんでした。

もちろんメモリを使わないわけではなく、PC全体を見るとほぼ上限までメモリが使用されています。
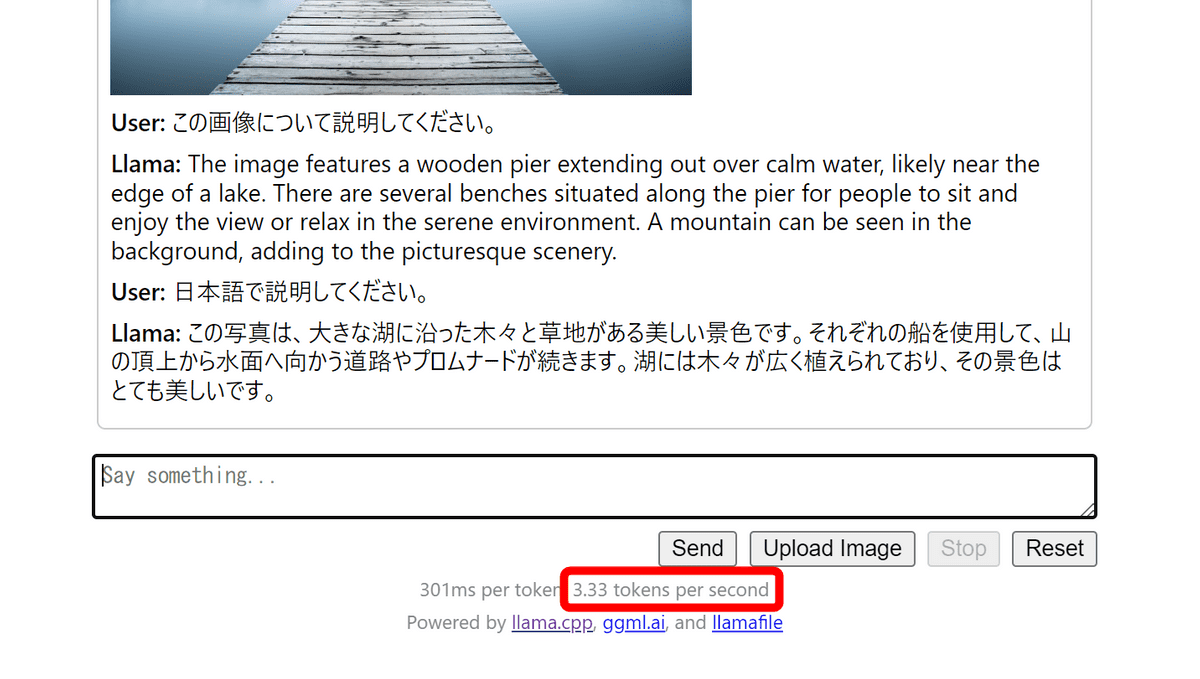
数分程度で推論が完了。「日本語で」と指定することで日本語でも出力することができます。Intel Core i7-8650Uプロセッサー搭載のノートPCで毎秒3.33トークンの速度で回答が生成されました。
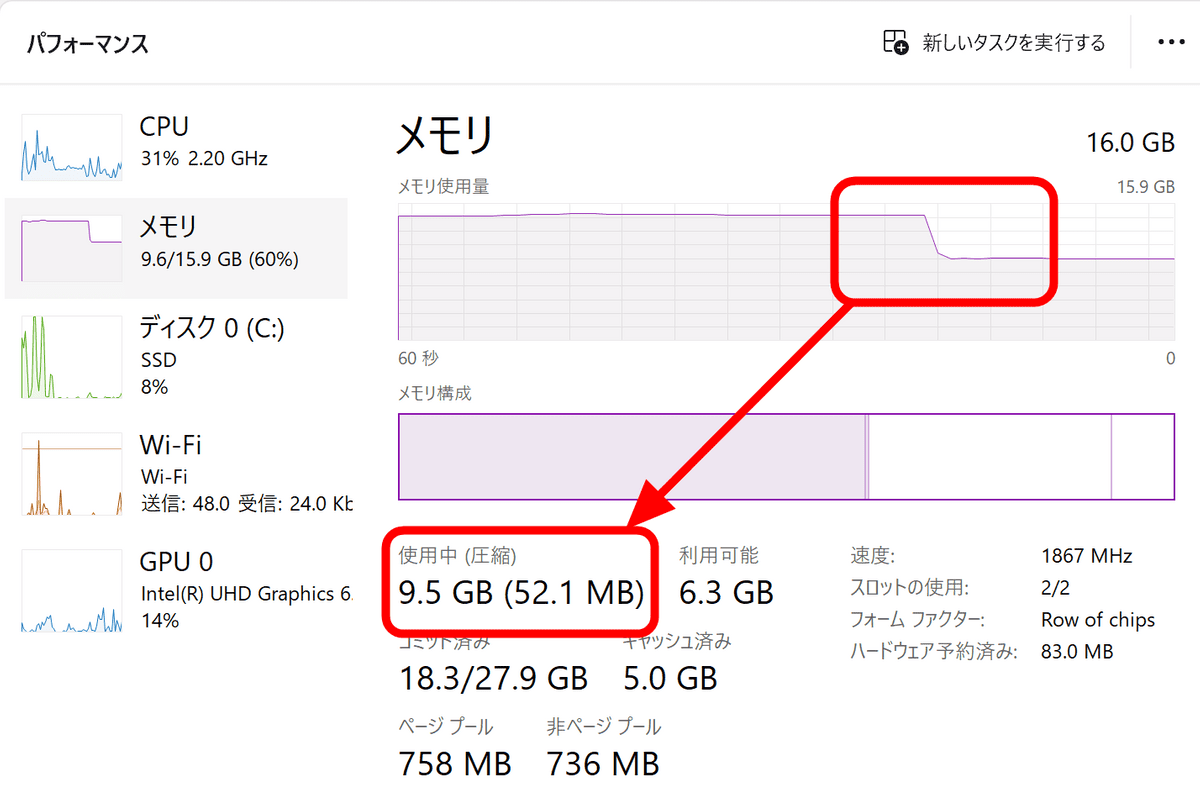
llamafileを終了するとメモリの使用量が15.5GBから9.5GBに減少したので、逆算すると最大で約6GBが使用されていた模様でした。
◆Debianで動かしてみた
Google Cloud Platform上のインスタンスで動作を試すので、コンソールにアクセスして「VMを作成」をクリック。
名前欄に「test-llava」と入力し、マシンの構成でGPUを選択します。今回は16GBのVRAMを搭載しているNVIDIA T4を使用することにしました。
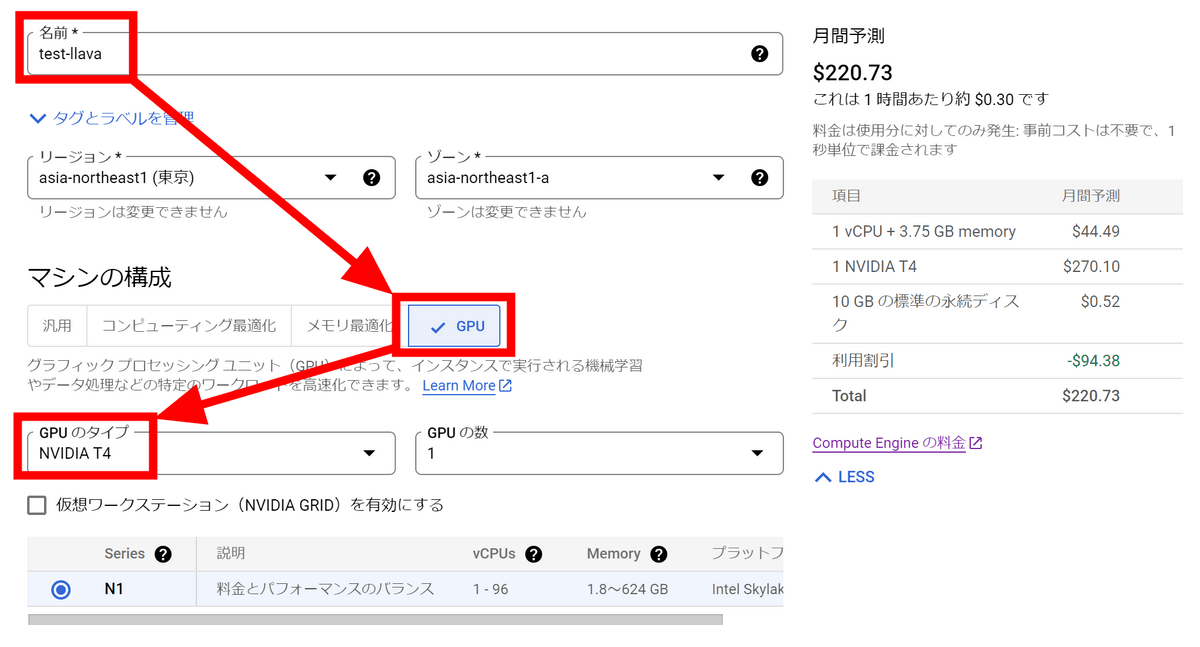
マシンタイプは「n1-standard-4」を選択。今回はテスト用ということで、VMプロビジョニングモデルは「スポット」にしました。GCPの都合で突然インスタンスが止まる可能性があるものの、料金を安く抑えることができます。
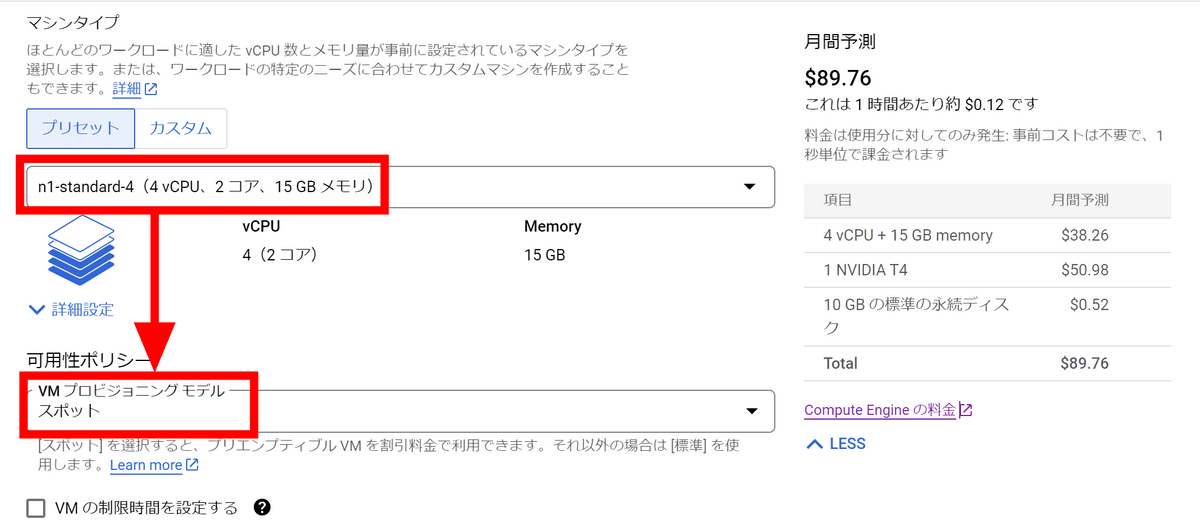
NVIDIA CUDAスタックを手動でインストールする代わりにインストール済みのイメージを使用してブートするので、「イメージを切り替え」をクリックします。
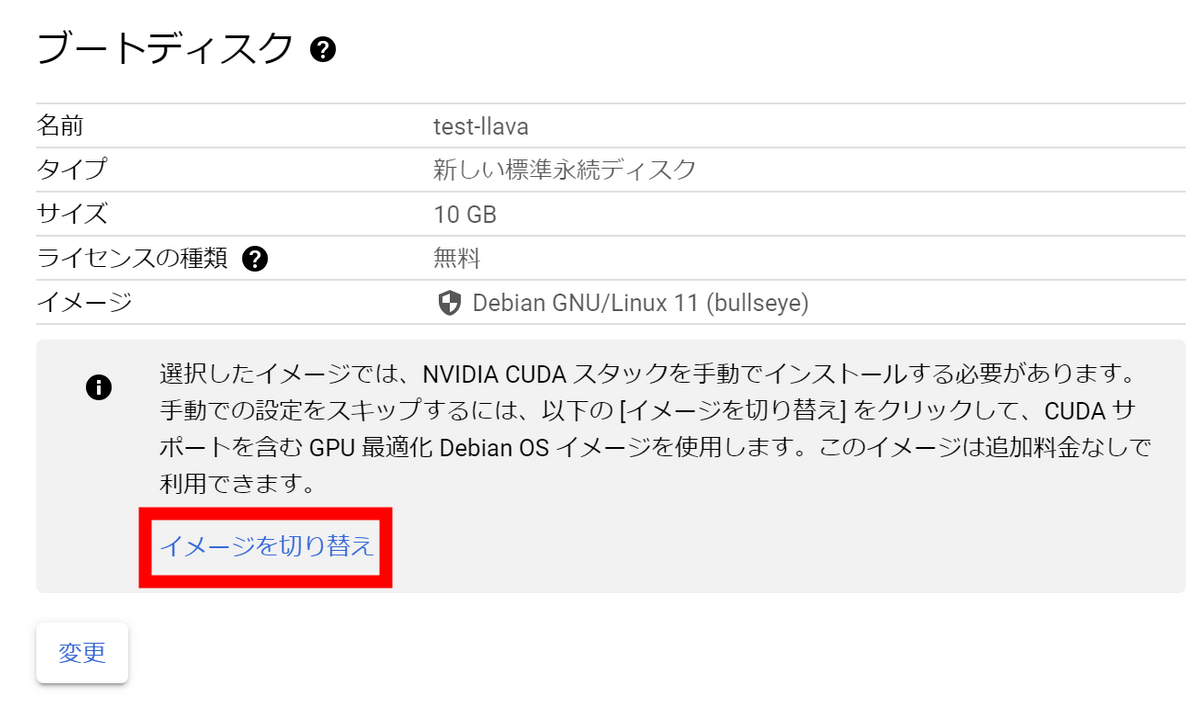
CUDAがプリインストールされているイメージが選択されているので、ディスクのサイズを決めて「選択」をクリック。
画面下部の「作成」ボタンをクリックしてインスタンスを作成します。

インスタンスが起動したら「SSH」ボタンをクリック。

別ウィンドウが開き、インスタンスにSSHで接続できました。最初にNvidiaのドライバをインストールするか聞かれるので「y」と入力してエンターキーを押します。
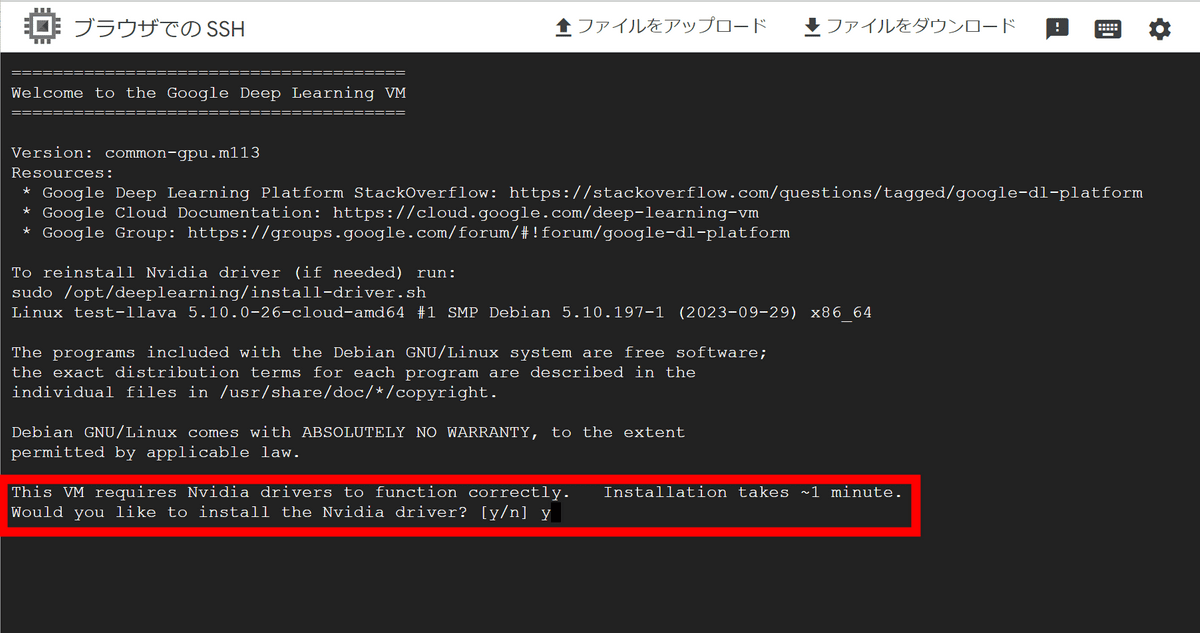
下記のコマンドでLlava 1.5のllamafileをダウンロード。
wget https://huggingface.co/jartine/llava-v1.5-7B-GGUF/resolve/main/llamafile-server-0.1-llava-v1.5-7b-q4
そして実行権限を付与します。
chmod 755 llamafile-server-0.1-llava-v1.5-7b-q4
続いて下記のコマンドで実行します。
./llamafile-server-0.1-llava-v1.5-7b-q4
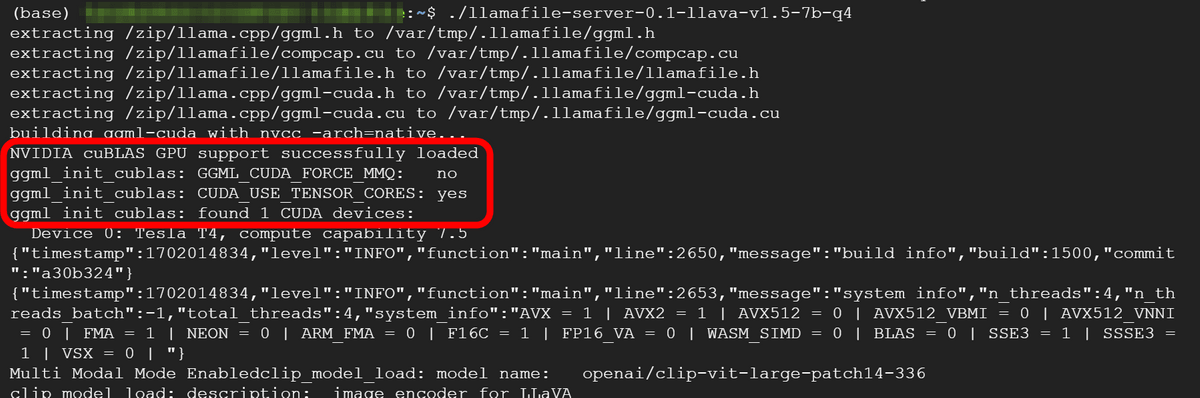
起動するとメモリへモデルがロードされていきます。出力されるログの中にはGPUの存在を認識していそうなログも存在していました。
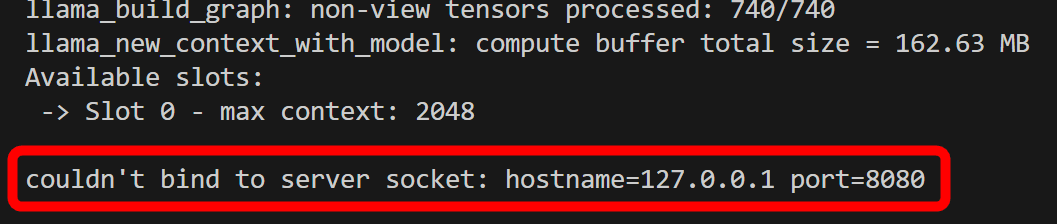
しかし、ロード終了と同時に「couldn't bind to server socket: hostname=127.0.0.1 port=8080」というエラーが出て終了してしまいました。既に使用中のポートを使おうとしてしまった模様。
内部でllama.cppが動作しているとのことなので、llama.cppのドキュメントを参考に「--port」オプションをつけて再度実行します。
./llamafile-server-0.1-llava-v1.5-7b-q4 --port 8181
今度は無事にサーバーが起動しました。Windowsで行ったのと同様の画像・プロンプトで推論を行います。
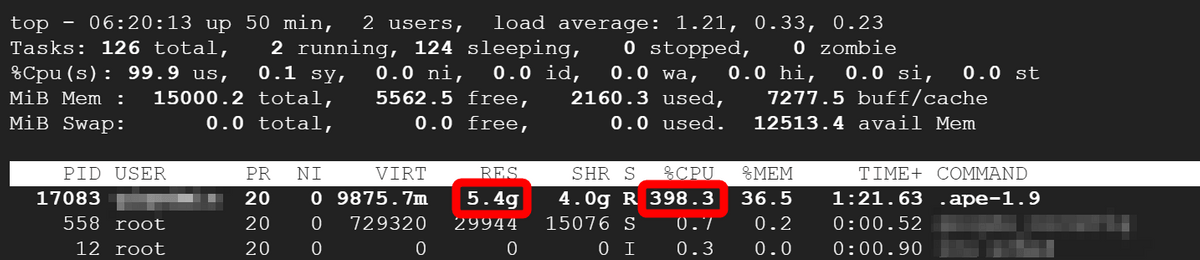
推論中のCPUの様子を確認してみると下図の通り。メモリの使用量は5.4GBでCPU使用率は約400%まで上昇しています。
一方GPUは下図の通り消費メモリ2MBで実行中のプロセスも存在せず、CPUのみでの推論となっていました。
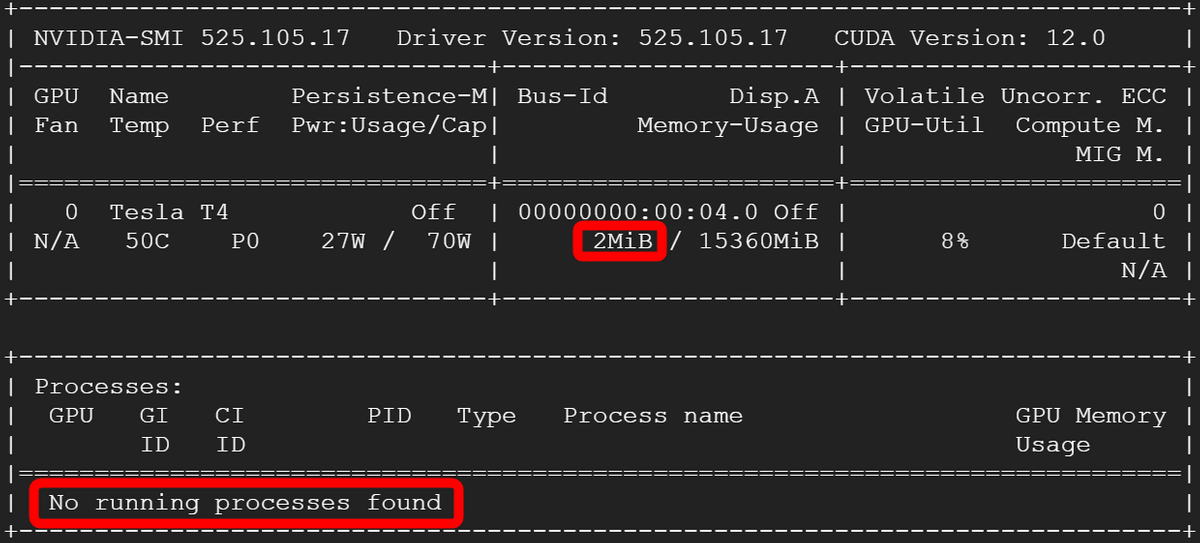
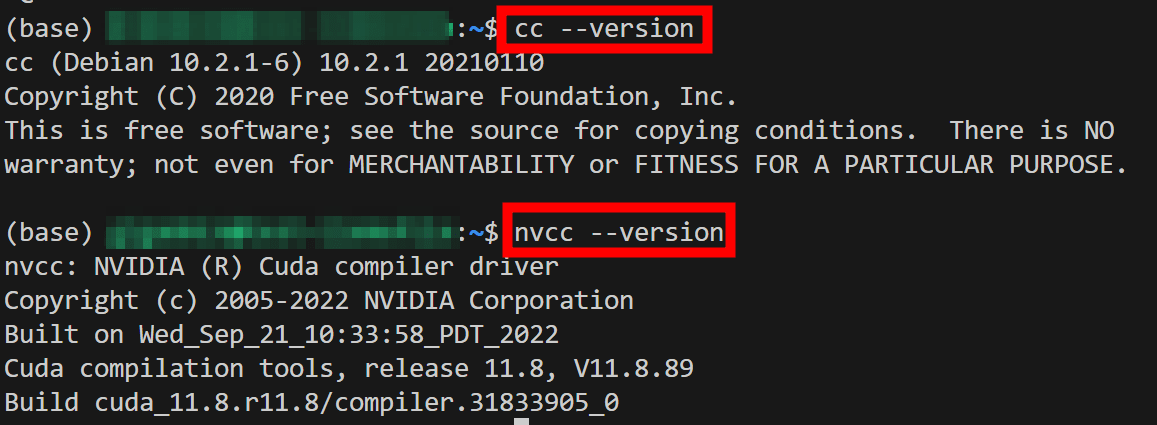
GPUが利用される条件を再確認してみると、「cc」と「nvcc」が必要で、さらに「--n-gpu-layers 35」というフラグを付ける必要があるとのこと。ccとnvccについては下図の通り使用可能な状態になっています。
「--n-gpu-layers 35」フラグを付けてもう一度推論を実行へ。
./llamafile-server-0.1-llava-v1.5-7b-q4 --port 8181 --n-gpu-layers 35
ところが、相変わらずGPUが使用されない状態のままとなってしまいました。「何らかの事情でGPUサポートをコンパイルできない場合はCPUでの推論になる」と記載されており、今回のパターンはその「何らかの事情」を踏んでしまったようでした。
llamafileのリポジトリでは「どうやって同時に多数のプラットフォームで実行できる形式の実行ファイルを作成したのか」やllamafile形式の実行ファイルの作成方法などが解説されているので、興味のある人は確認してみてください。
・関連記事
本当にオープンソースのライセンスで利用&検証できる大規模言語モデル「Mistral 7B」が登場、「Llama 2 13B」や「Llama 1 34B」を上回る性能のAI開発が可能 - GIGAZINE
ChatGPTを超えるという大規模言語モデル「OpenChat」をローカルで動作させて実力を確かめてみた - GIGAZINE
1万種類を超える大規模言語モデル(LLM)をまとめてダウンロード数や類似性などを分かりやすく視覚化したデータライブラリが公開される - GIGAZINE
Stability AIがChatGPTと同等の性能を持つオープンソースの大規模言語モデル「FreeWilly」を公開 - GIGAZINE
「医療」に特化したオープンソースの大規模言語モデル「Meditron」が登場 - GIGAZINE
・関連コンテンツ




in ソフトウェア, レビュー, Posted by log1d_ts
You can read the machine translated English article How to easily run 'llamafile', a system ….