




大規模言語モデルをLoRAで低コストかつ効率的に微調整できる「Punica」が登場

Low Rank Adapation(LoRA)はAIへの追加学習を少ない計算量で行うためのモデルです。このLoRAを使って、事前トレーニングされた大規模言語モデルに低コストかつ効率的にファインチューニング(微調整)を行えるシステム「Punica」を、ワシントン大学とデューク大学の研究チームが公開しました。
GitHub - punica-ai/punica: Serving multiple LoRA finetuned LLM as one
https://github.com/punica-ai/punica
[2310.18547] Punica: Multi-Tenant LoRA Serving
https://arxiv.org/abs/2310.18547
企業や開発者が特定のタスクに適した大規模言語モデルを用意したい場合、事前学習済みの大規模言語モデルをファインチューニングする必要があります。しかし、大規模言語モデルは数十億というパラメータ数をもち、すべてのパラメータを直接ファインチューニングするには膨大な演算コストが求められます。
Punicaには、さまざまなLoRAモデルのバッチ処理を可能にするCUDAカーネル設計が含まれているとのこと。これによって、複数の異なるLoRAモデルを処理する際にベースとなる事前トレーニング済みの大規模言語モデルのコピーを1つだけ保持できるようになり、メモリと計算の両方でGPUコストパフォーマンスが大幅に向上するそうです。
事前に訓練された大規模言語モデルは100GB規模のストレージを消費します。しかし、LoRAで微調整されたモデルは数GBのストレージとメモリのオーバーヘッドを追加するだけでいいとのこと。Punicaを使えば、1つのモデルを実行するコストで複数のLoRA微調整モデルを実行することができるそうです。
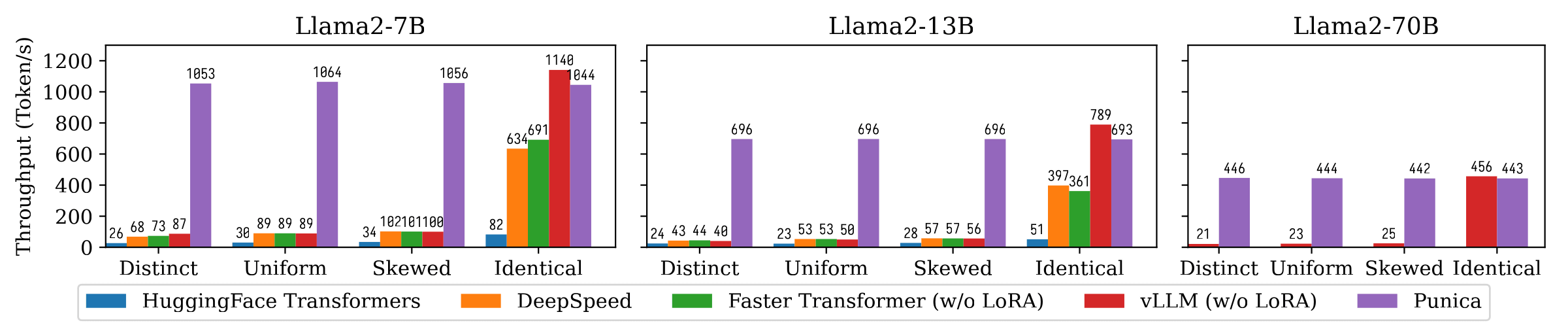
以下はHuggingFace Transformers(青)、Microsoft DeepSpeed(オレンジ)、NVIDIA Faster Transformer(緑)、vLLM(赤)、Punica(紫)で、Metaの大規模言語モデルであるLlama2の7Bモデル・13Bモデル・70Bモデルのテキスト生成のスループットを比較した棒グラフです。Punicaは他のシステムと比較して12倍のスループットを達成していると研究チームは述べています。
LoRAを大規模言語モデルに応用する研究はPunicaだけではなく、他の研究チームも行っています。2023年11月6日には、Punicaと同様にLoRAを活用してGPU上で低コストかつ効率的に大規模言語モデルをファインチューニングする「S-LoRA」についての論文が、未査読論文リポジトリであるarXivで公開されました。
[2311.03285] S-LoRA: Serving Thousands of Concurrent LoRA Adapters
https://arxiv.org/abs/2311.03285
なお、LoRAによって低コストで効率的に大規模言語モデルを扱えるようにする技術については、すでにGoogleが登場を予言していたことが報じられています。Googleは内部文書の中で、LoRAの登場によってオープンソースの大規模言語モデルの性能が向上し、自社開発のAIモデルがオープンソースのモデルに敗北する可能性すらあると指摘しています。
「オープンソースは脅威」「勝者はMeta」「OpenAIは重要ではない」などと記されたGoogleのAI関連内部文書が流出 - GIGAZINE

・関連記事
大規模言語モデルが「幻覚」を引き起こすリスクを客観的に検証できるオープンソースの評価モデルをVectaraがリリース - GIGAZINE
OpenAIがGPT-4のアップグレード版大規模言語モデル「GPT-4 Turbo」を発表、2023年4月までの知識を持ちコンテキストウィンドウは128Kで価格は控えめ - GIGAZINE
大規模言語モデル「Phind」がコーディングにおいてGPT-4を上回る - GIGAZINE
Appleは2年で7500億円を投資してAI開発競争に追いつくことを計画している - GIGAZINE
Baiduが大規模言語モデル「Ernie 4.0」を発表、全ての点でGPT-4に匹敵する実力を持つ - GIGAZINE
ニューラルネットワークの中身を分割してAIの動作を分析・制御する試みが成功、ニューロン単位ではなく「特徴」単位にまとめるのがポイント - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Introducing 'Punica,' a low-cost and eff….