




全ての開発者が知っておくべきUnicodeについての最低限の知識
2003年には「プレーンテキストなんてものは全く存在しない」と言われ、テキストの解読には文字コードの情報が必須となっていました。しかし、2023年になるまでの20年の間に絵文字などのおかげでUnicodeの利用率は98%へと到達し、再び文字コードを気にせずにすむ時代がやってきています。そんな時代において、正しくUnicodeを使うために必要な知識をエンジニアのニキータ・プロコポフさんが解説しています。
The Absolute Minimum Every Software Developer Must Know About Unicode in 2023 (Still No Excuses!) @ tonsky.me
https://tonsky.me/blog/unicode/
Unicodeの歴史と利用率の推移をまとめたグラフは下図の通り。2000年代後半から急速に普及が進んでいったことが分かります。

Unicodeは単純に言うとさまざまな文字にコードポイントと呼ばれる数字を割り当てたテーブルです。例えばラテン文字の「A」は「65」という数字が振られており、アラビア文字の「س」は「1587」、カタカナの「ツ」は「12484」となっています。そのほか、「𝄞(119070)」「💩(128169)」などの記号や絵文字にも番号が振られています。
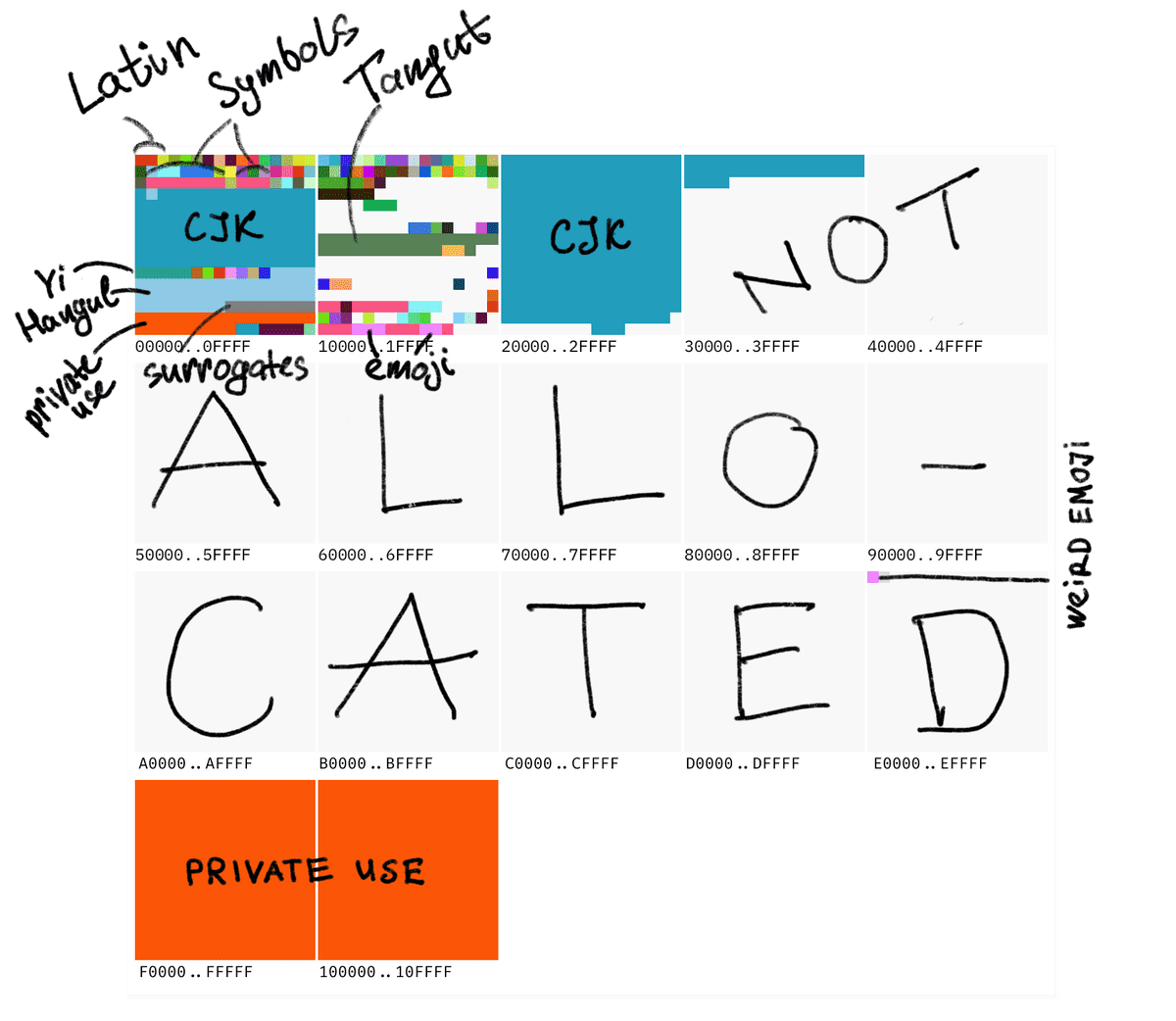
コードポイントの数値は最大で0x10FFFFとなっており、約110万個の文字を登録可能です。2023年時点で登録済みの文字数は約17万件で、その他プライベート用途向けの割り当て部分を除き、追加で登録可能な文字数は約80万個とのこと。
Unicodeのコードポイントは「U+1F4A9」のように表示します。「U+」部分がUnicodeであることを示しており、その後にコードポイントの16進数表記が続きます。
プライベート用途部分についてはUnicodeによっては定義されておらず、それぞれの開発者が自由に利用可能です。例えばAppleはリンゴマークを「(U+F8FF)」と設定しており、Appleのフォントが入った端末でリンゴマークを表示することができます。そのほか、プライベート用途部分はアイコンフォントでもよく利用されているとのこと。
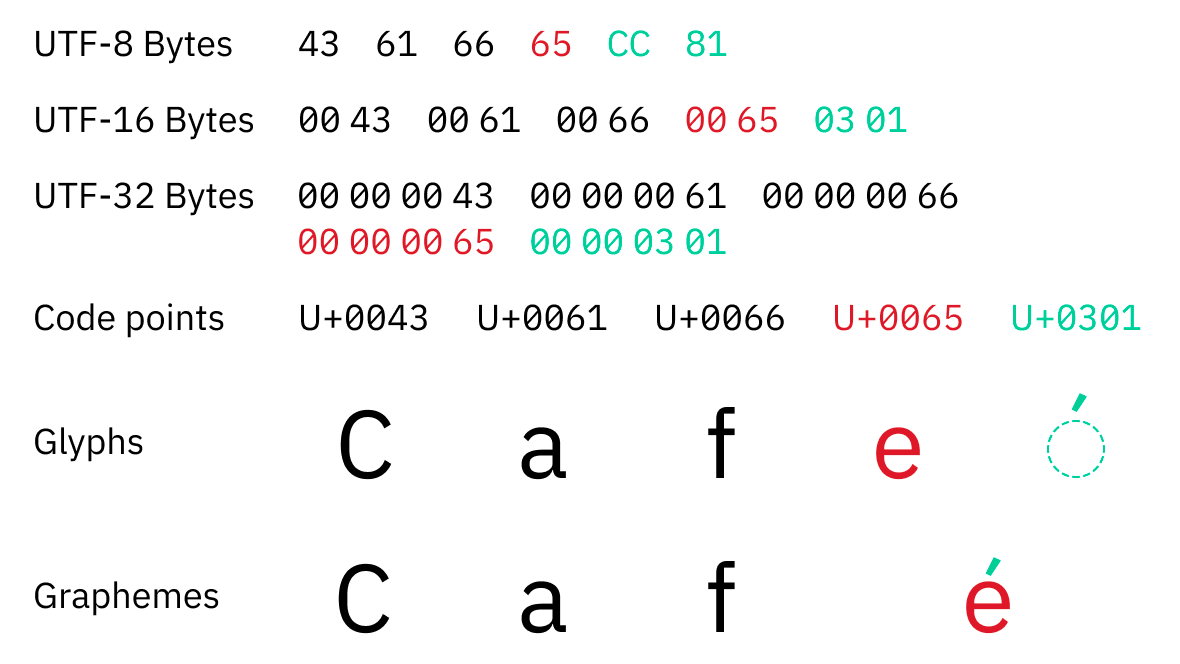
Unicodeの具体的なエンコーディングとして「UTF-8」「UTF-16」「UTF-32」などが存在しています。UTF-32はコードポイントを32ビット整数として格納するだけの一番単純なエンコーディングで、例えば「U+1F4A9」であれば「00 01 F4 A9」という4バイトで情報が保存されます。UTF-8やUTF-16の仕組みはもう少し複雑なものの、コードポイントをエンコードしてバイト列として保存する点は同じです。
2023年時点ではUnicodeのエンコーディングの中でUTF-8が最も一般的に使用されていますが、1990年代にUnicodeが登場した時点ではUTF-16の前身である16ビットの固定幅エンコーディングの「UCS-2」が使用されていました。「すべての人間の言語をカバーする固定幅エンコーディング」は非常に魅力的だったので、Microsoft Windows、Objective-C、Java、JavaScript、.NET、Python 2、QT、SMS、CD-ROMなど多くのシステムがUCS-2を採用しました。
しかし、UCS-2の「16ビットの固定幅」では6万5536文字しか表すことができません。Unicodeの考案時には十分に思えた文字数の制限が実際には足りていない事が明らかになると、複数のコードポイントを合わせて1つの文字を表現する「サロゲートペア」が導入され、固定長のUCS-2を可変長のUTF-16へと発展させることになりました。
サロゲートペアは上位の6ビットをマスクとして使用し、残りの10ビットを用いてコードポイントを表現します。
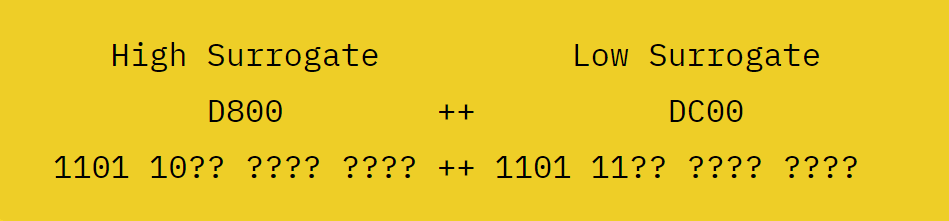
この仕組みを導入したことにより、Unicodeの「U+D800」から「U+DFFF」までの区間はサロゲートペア専用の区間となり、文字を割り当てられなくなっています。

UTF-8もコードポイント次第でバイト数が変化するエンコードで、英語は1バイトでエンコードされますがキリル文字やラテン系ヨーロッパ言語、ヘブライ語、アラビア語などは2バイト、中国語、日本語、韓国語などのアジア言語や絵文字は3バイトから4バイトでエンコードされます。UTF-8・UTF-16ともにバイト数が可変のため、単純にバイト数を数えるだけでは文字列の長さを決定できず、また文字列の一部を飛ばして読むこともできません。

文字列の一部が欠落して正しくデコードできない場合、「�」という文字が表示されます。
UTF-32は1コードポイントを常に4バイトでエンコードするため、UTF-32を使用すればバイト数から文字数を取得できるように思えます。しかし、Unicodeでは1コードポイントが1文字とは限らず、例えば「é」は「e(U+65)」と「́(U+301)」の2つのコードポイントを組み合わせて表示されています。
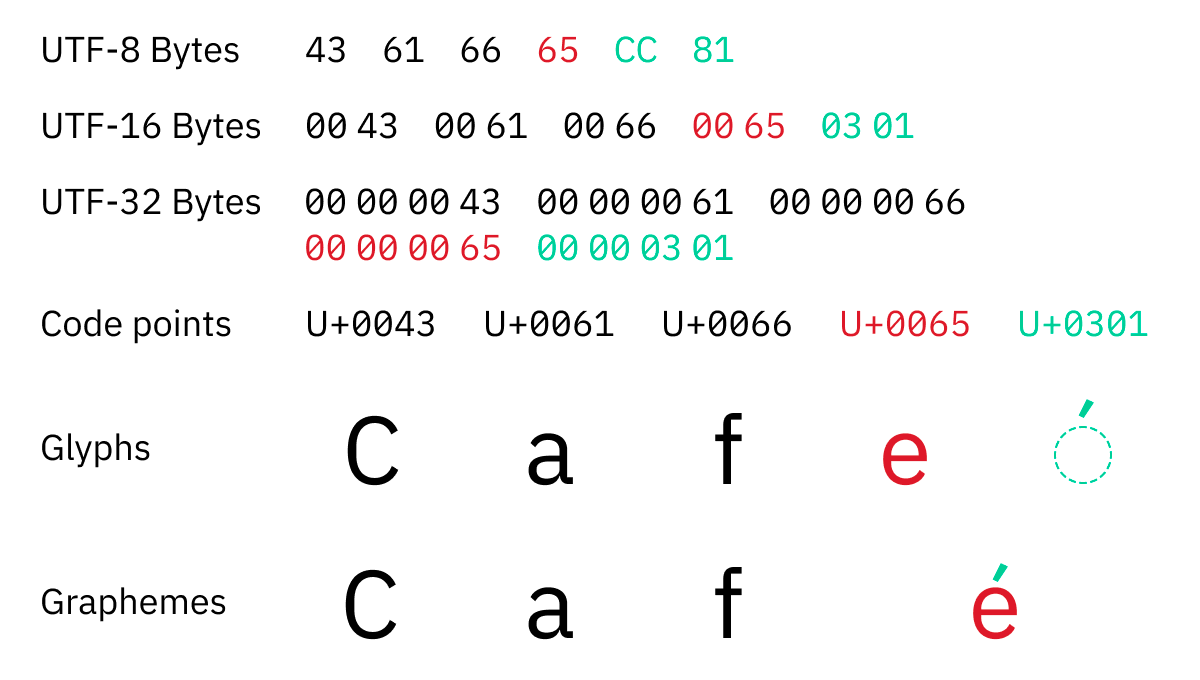
コードポイントの組み合わせ方は多数あり、「U+0079」「U+0316」「U+0320」「U+034D」「U+0318」「U+0347」「U+0357」「U+030F」「U+033D」「U+030E」「U+035E」を組み合わせて「y̖̠͍̘͇͗̏̽̎͞」と表示することができるなど、組み合わせる数には事実上制限がありません。
こうしたコードポイントを元に文字数を判別するのは難しく、「U+1F926」「U+1F3FB」「U+200D」「U+2642」「U+FE0F」を組み合わせるとできる「🤦🏻♂️」という文字をさまざまなプログラミング言語で長さを判定すると下記のようになります。
・Python 3

・JavaScript / Java / C#

・Rust

・Swift

適切に文字数を判別するにはUnicodeライブラリを使用する必要があります。プロコポフさんはそれぞれの言語について、下記のライブラリを推奨しています。
・C / C++ / Java
テキストのセグメンテーションに関するすべてのルールをエンコードするUnicodeライブラリのICUを使用します。
・C#
「TextElementEnumerator」を使えばOKとのこと。
・Swift / Erlang / Elixir
スタンダードライブラリで正常に文字数を判別できます。
・その他の言語
ICUに基づいたライブラリを使用するか、Unicodeのルールに基づいて文字数をカウントする仕組みを自分で作成すればOK。
なお、Unicodeは2014年以降毎年バージョンアップを繰り返しており、文字と文字の境界を決めるルールも変化しているため、適切なバージョンに対応したライブラリを使う必要があります。
また、Unicodeは同じ文字を複数のやり方で表すことが可能です。例えば「Å」と「Å」は一見同じ文字に見えますが、前者は単体のコードポイントである「U+C5」で、後者は「A」に「̊」を組み合わせた合字の「U+41 U+30A」というように中身が異なっています。この違いがあると「"Å" === "Å"」の様な比較をした際に「False」となってしまうため、比較の前に正規化を行う必要があります。
このように視覚的・機能的に同じ文字を統一する正規化のことを「正準等価での正規化」といいます。正準等価での正規化の手法は2種類あり、「NFD」で正規化を行うとできる限りコードポイントを分解するように正規化され、一方「NFC」ではできる限り事前に作成されたコードポイントを使用するように正規化を行います。
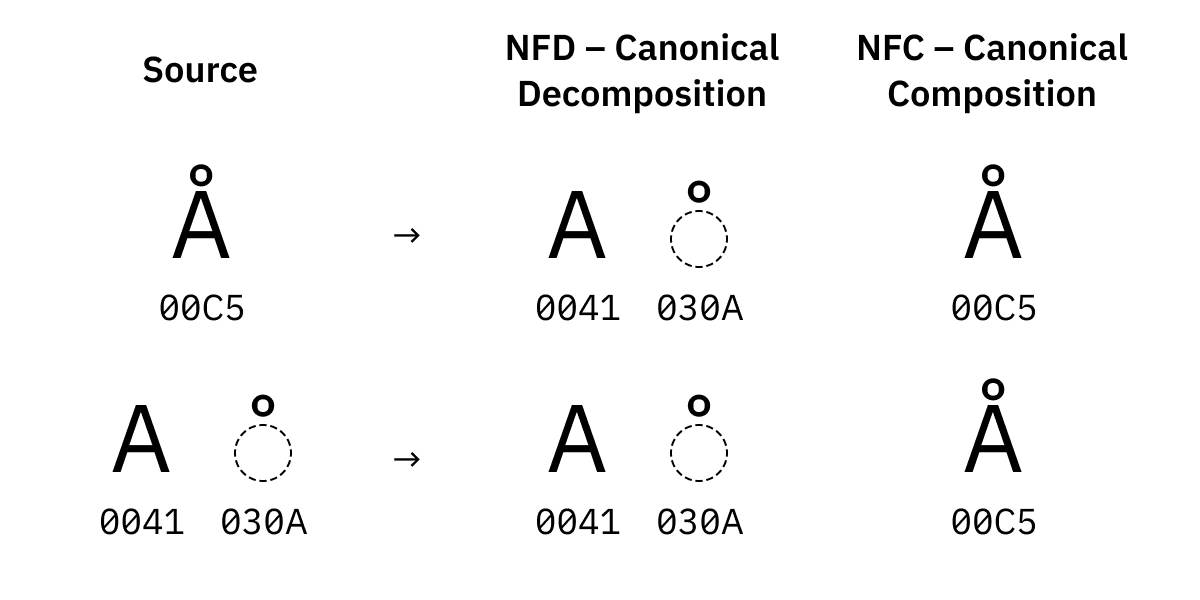
一部の文字は複数のバージョンが存在していますが、正規化を行うとそうした違いを吸収してくれます。

さらに、正準等価よりも広い概念として互換等価という概念があり、互換等価での正規化では「NFD」「NFC」の正規化に加えて視覚的に通常とは異なった表現の文字を標準の文字に置き換える手順が含まれます。「NFKD」はNFD同様にできる限りコードポイントを分解するように正規化し、「NFKC」はNFC同様に事前に作成されたコードポイントを使用する正規化です。

Unicodeには同じ文字を指す視覚的に異なる表現のコードポイントが多数存在しており、例えば下図は全て「X」を指す視覚的に異なった表現です。こうした文字を正規化して比較しやすくするのが互換等価での正規化というわけです。
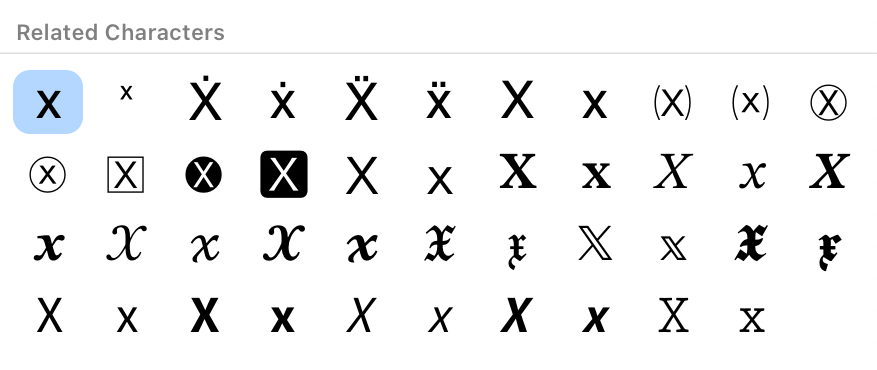
また、Unicodeの表現はロケールに依存します。例えば「ニコライ」をロシア語で書くと下記の通り。これはUnicodeで「U+041D 0438 043A 043E 043B 0430 0439」と表現されます。
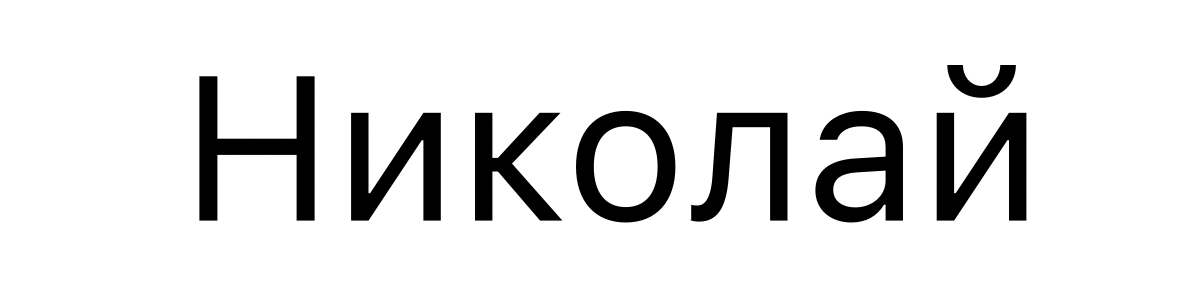
一方、ブルガリア語で「U+041D 0438 043A 043E 043B 0430 0439」を表示すると下図の通り異なる文字が出現します。これはブルガリア語での「ニコライ」の表現で、Unicodeのコードポイントが同じでもロケールが異なれば違う文字になります。
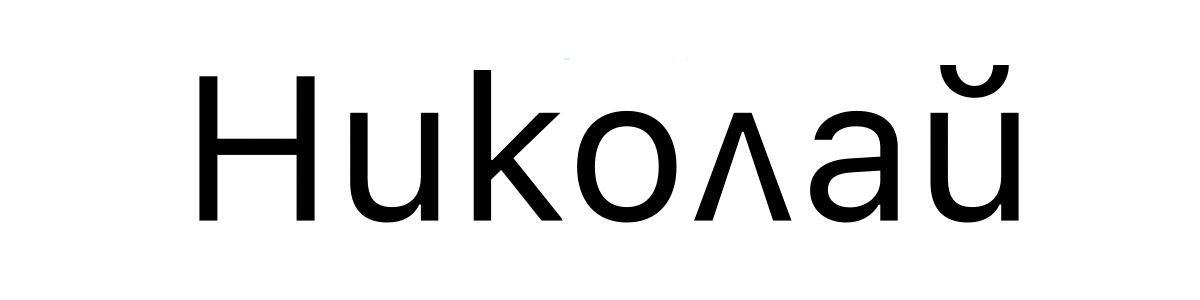
多くの漢字には、地域によってまったく異なった書き方をするにも関わらず、Unicode上は同じコードポイントが割り当てられています。コードポイントの情報からどの種類の漢字を表示すれば良いのかをロケール情報に依存してしまうわけですが、ロケール情報はメタデータのため失われやすく、意図と異なった文字が表示されてしまう問題がしばしば発生します。

Unicodeが完璧な仕組みとは言えませんが、全ての言語をカバーしており、全世界の人々が使用していてエンコードや変換について完全に忘れる事ができるという状況を達成しているのも事実です。こうした点を踏まえて、プロコポフさんは「プレーンテキストは存在しており、それはUTF-8でエンコードされている」と結論を述べていました。
本記事に関連するフォーラムをGIGAZINE公式Discordサーバーに設置しました。誰でも自由に書き込めるので、どしどしコメントしてください!
• Discord | "「文字コード」で困った経験を教えて!" | GIGAZINE(ギガジン)
https://discord.com/channels/1037961069903216680/1159778701353955380
・関連記事
絵文字の偉大な功績の1つは「文字コードを統一したこと」 - GIGAZINE
目に見えないUnicode文字をコピペして使えたり元のUnicode文字を検索したりできる「Invisible Characters」 - GIGAZINE
日本語翻訳の「漢字表記の間違い」を海外の開発者にも端的に説明してくれる「Your Code Displays Japanese Wrong」 - GIGAZINE
2021年に最も使われた絵文字ランキングが発表 - GIGAZINE
Unicodeに含まれる謎の記号「⍼」の起源を追ったレポートが公開中 - GIGAZINE
・関連コンテンツ







in ソフトウェア, ウェブアプリ, Posted by log1d_ts
You can read the machine translated English article The minimum knowledge about Unicode that….