The minimum knowledge about Unicode that every developer should know
In 2003, it was said that
The Absolute Minimum Every Software Developer Must Know About Unicode in 2023 (Still No Excuses!) @ tonsky.me
https://tonsky.me/blog/unicode/
A graph summarizing the history of Unicode and trends in usage rate is shown below. You can see that it has become rapidly popular since the late 2000s.

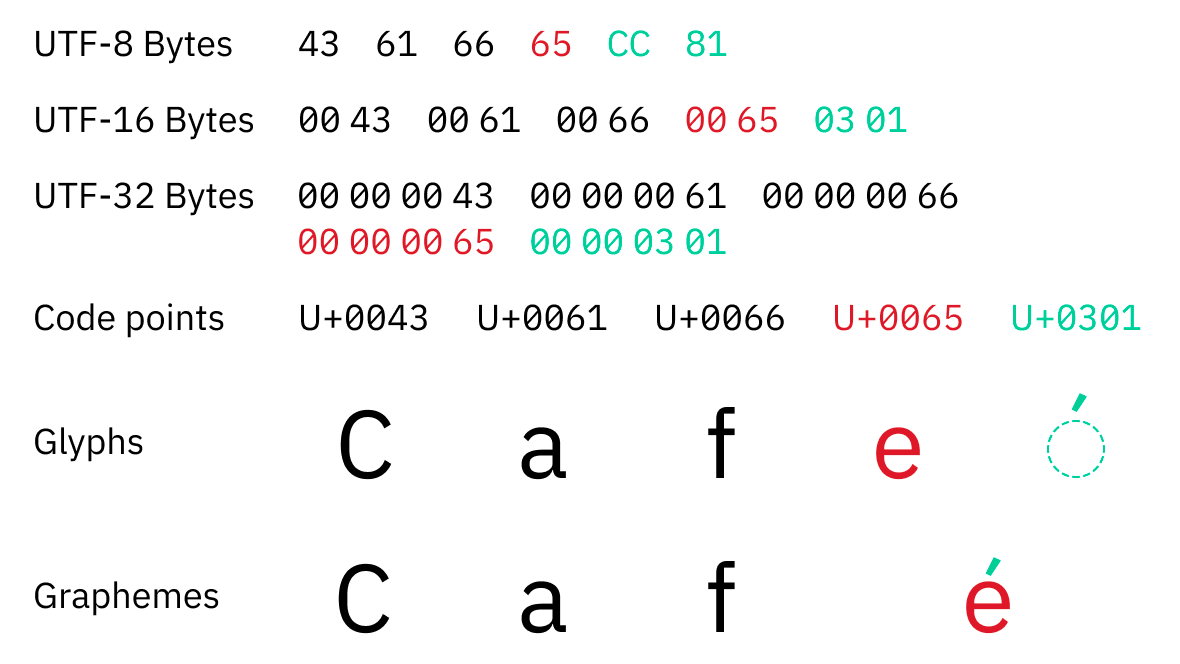
Unicode is simply a table that assigns numbers called code points to various characters. For example, the Latin letter 'A' is numbered '65,' the Arabic letter 'س' is '1587,' and the katakana 'tsu' is '12484.' In addition, symbols and pictograms such as '???? (119070)' and '???? (128169)' are also numbered.
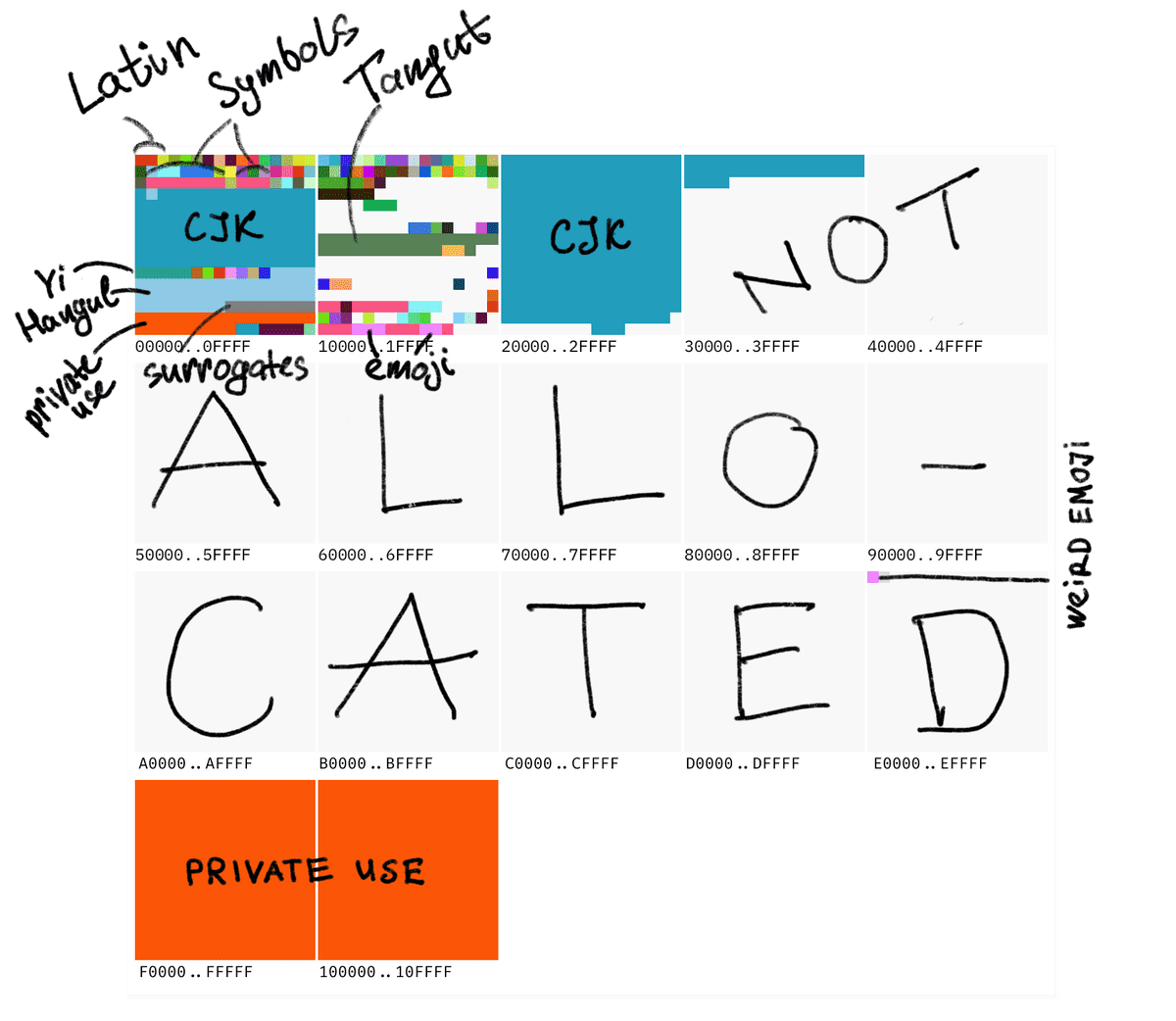
The maximum code point value is 0x10FFFF, and approximately 1.1 million characters can be registered. As of 2023, the number of registered characters is approximately 170,000, and the number of additional characters that can be registered is approximately 800,000, excluding the portion allocated for other private uses.
Unicode code points are displayed like 'U+1F4A9'. The 'U+' part indicates Unicode, followed by the hexadecimal representation of the code point.
The private use part is not defined by Unicode and can be used freely by each developer. For example, Apple has set the apple mark as '(U+F8FF)', which allows the apple mark to be displayed on devices that include Apple's font. In addition, the private use part is also often used in icon fonts.
There are specific Unicode encodings such as 'UTF-8', 'UTF-16', and 'UTF-32'. UTF-32 is the simplest encoding that simply stores code points as 32-bit integers; for example, if it is 'U+1F4A9', the information is stored in 4 bytes as '00 01 F4 A9'. Although the mechanism of UTF-8 and UTF-16 is a little more complicated, they are the same in that they encode code points and store them as byte sequences.
As of 2023, UTF-8 is the most commonly used Unicode encoding, but when Unicode was introduced in the 1990s, UTF-16's predecessor, the 16-bit fixed-width encoding UCS- 2' was used. 'Fixed-width encoding that covers all human languages' was very attractive, so it can be used on many systems such as Microsoft Windows, Objective-C, Java, JavaScript, .NET, Python 2, QT, SMS, CD-ROM, etc. adopted UCS-2.
However, UCS-2's '16-bit fixed width' can only represent 65,536 characters. When it became clear that the character limit, which seemed sufficient when Unicode was invented, was actually insufficient, ``surrogate pairs'' were introduced, which combine multiple code points to represent a single character, and fixed-length UCS- 2 to the variable length UTF-16.
The surrogate pair uses the upper 6 bits as a mask and the remaining 10 bits to represent the code point.
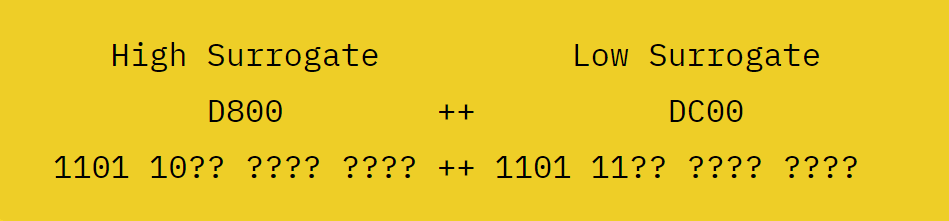
By introducing this mechanism, the Unicode section from 'U+D800' to 'U+DFFF' becomes a section exclusively for surrogate pairs, and no characters can be assigned to it.

UTF-8 is also an encoding in which the number of bytes changes depending on the code point; English is encoded in 1 byte, but Cyrillic, Latin European languages, Hebrew, Arabic, etc. are encoded in 2 bytes, Chinese, Japanese, Korean, etc. Asian languages such as words and emojis are encoded in 3 to 4 bytes. Because the number of bytes in both UTF-8 and UTF-16 is variable, it is not possible to determine the length of a string simply by counting the number of bytes, nor is it possible to read by skipping parts of the string.

If part of the string is missing and cannot be decoded correctly, the character '�' will be displayed.
UTF-32 always encodes one code point as 4 bytes, so it seems like you can get the number of characters from the number of bytes using UTF-32. However, in Unicode, one code point is not necessarily one character; for example, 'é' is displayed as a combination of two code points: 'e(U+65)' and '́(U+301)'.
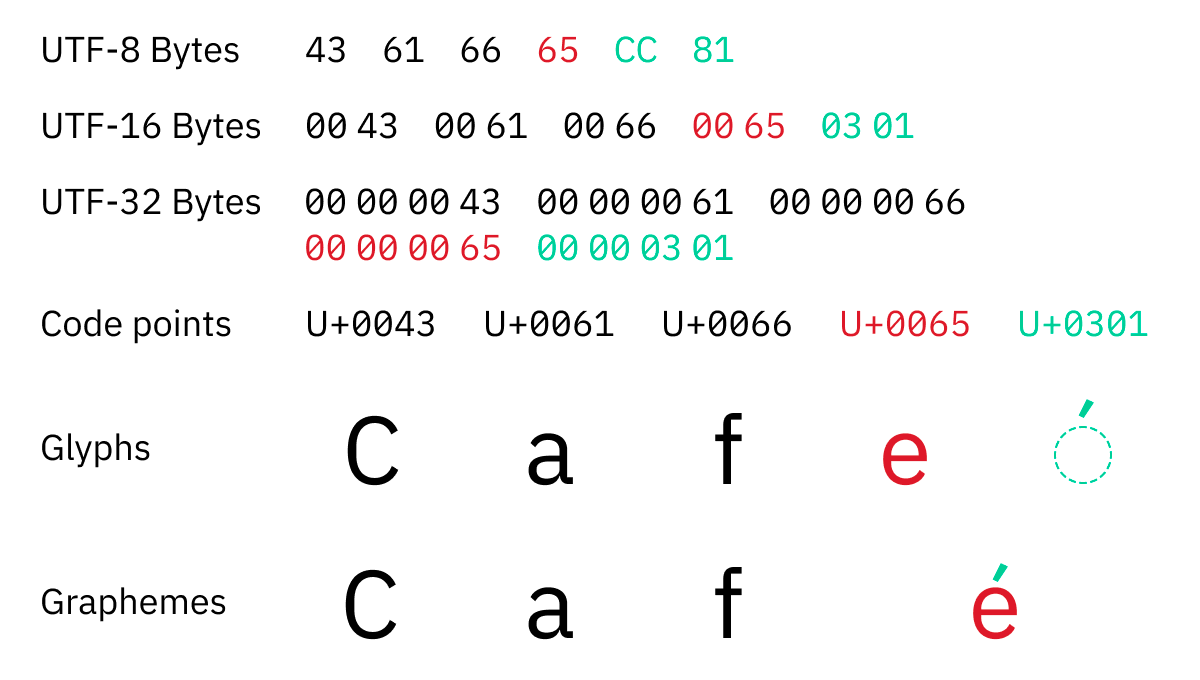
There are many ways to combine code points: 'U+0079', 'U+0316', 'U+0320', 'U+034D', 'U+0318', 'U+0347', 'U+0357', 'U+030F', ' There is virtually no limit to the number of combinations, such as combining U+033D, U+030E, and U+035E to display y̖̠͍̘͇͗̏̽̎͞.
It is difficult to determine the number of characters based on these code points. When determining the length of characters using various programming languages, the results are as follows.
・Python 3

・JavaScript / Java / C#

・Rust

・Swift

You need to use a Unicode library to properly determine the number of characters. Prokopov recommends the following libraries for each language.
・C/C++/Java
We use the Unicode library
・C#
It is OK to use 'TextElementEnumerator'.
・Swift / Erlang / Elixir
I can successfully determine the number of characters using the standard library.
・Other languages
You can use a library based on ICU or create your own system to count the number of characters based on Unicode rules .
Note that Unicode has been updated every year since 2014, and the rules for determining the boundaries between characters have also changed, so it is necessary to use a library that is compatible with the appropriate version.
Unicode also allows the same character to be represented in multiple ways. For example, 'Å' and 'Å' appear to be the same character at first glance, but the former is a single code point 'U+C5', and the latter is a ligature 'U+' that is a combination of 'A' and '̊'. 41 U+30A', the contents are different. If this difference exists, a comparison such as ''Å' === 'Å'' will return 'False', so it is necessary to perform normalization before the comparison.
This kind of normalization that unifies characters that are visually and functionally the same is called 'normalization based on
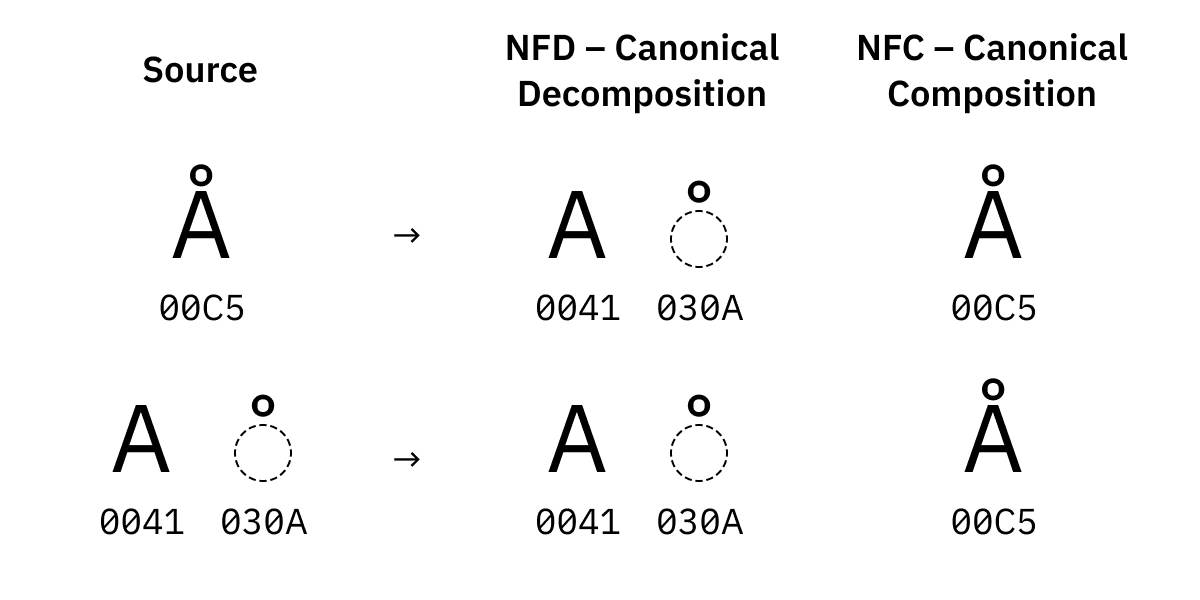
Some characters have multiple versions, and normalization absorbs these differences.

Furthermore, there is the concept of

Unicode has many code points that have visually different representations of the same character. For example, the image below shows all visually different representations of 'X'. Compatible equivalence normalization normalizes these characters to make them easier to compare.
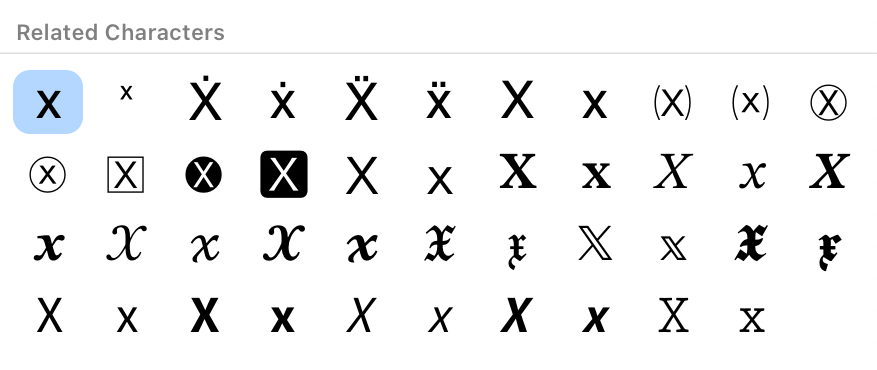
Also, Unicode representation is
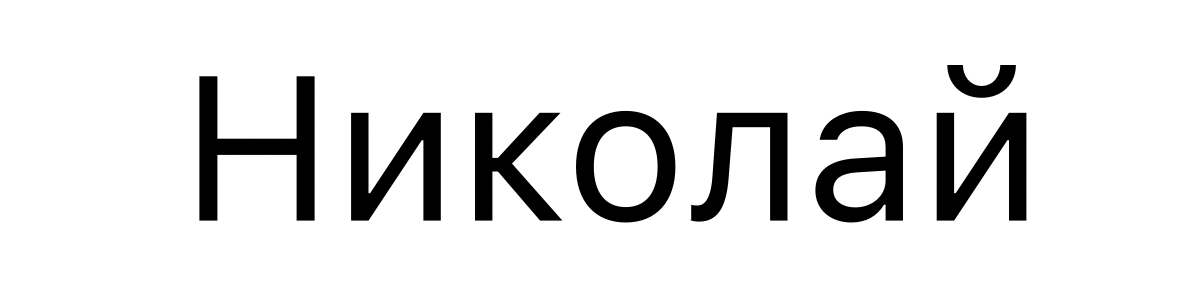
On the other hand, when displaying 'U+041D 0438 043A 043E 043B 0430 0439' in Bulgarian, different characters will appear as shown below. This is the Bulgarian expression for 'Nikolai', and even if the Unicode code point is the same, it will be a different character in different locales.
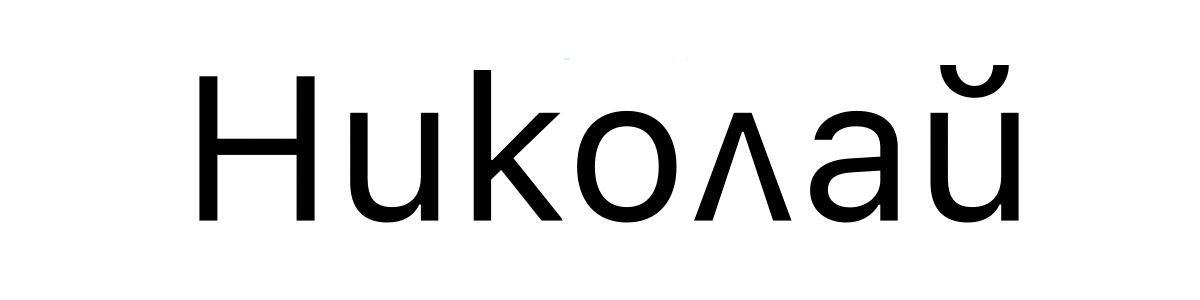
Many kanji are written completely differently depending on the region, but are assigned the same code point in Unicode. It depends on locale information to determine which type of kanji to display based on code point information, but locale information is metadata and is easily lost, resulting in the problem of characters being displayed that are different from the intended ones. It happens often.

Unicode is not a perfect system, but it covers all languages, is used by people all over the world, and has achieved a situation where you can completely forget about encoding and conversion. is. Based on these points, Mr. Prokopov concluded that ``Plain text exists, and it is encoded in UTF-8.''
A forum related to this article has been set up on the GIGAZINE official Discord server. Anyone can write freely, so please feel free to comment!
• Discord | “Tell me about your experience of having trouble with “character codes”! ' | GIGAZINE
https://discord.com/channels/1037961069903216680/1159778701353955380
Related Posts:







in Software, Web Application, Posted by log1d_ts