At first glance, Unicode points out that it is possible to embed a 'secret message' in a normal character

Paul Butler – Smuggling arbitrary data through an emoji
https://paulbutler.org/2025/smuggling-arbitrary-data-through-an-emoji/
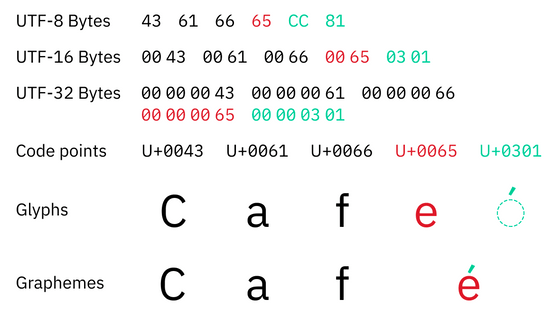
In Unicode, certain characters, symbols, emojis, etc. are assigned numbers called 'code points.' Code points are written in the format 'U+XXXX,' where the 'U+' indicates that it is Unicode, and the 'XXXX' that follows indicates the code point in hexadecimal notation.
For simple Latin characters (alphabet), there is a one-to-one correspondence between Unicode code points and the characters displayed on a device screen, for example, 'U+0067' represents the letter 'g'. On the other hand, a single character may be represented by a combination of multiple code points, for example, the character 'की', one of the Devanagari characters , is represented by the consecutive pair 'U+0915' and 'U+0940'.
Furthermore, Unicode provides a selector called a ' variation selector ' to specify the glyph of a character in more detail. There are two types of variation selectors: Standardized Variation Sequence (SVS) and Kanji Variation Sequence (IVS), and there are a total of 256 variants ranging from 'VS-1 (U+FE00 in hexadecimal notation)' to 'VS-256 (U+E01EF in hexadecimal notation)'.
These variant selectors are added after the code points that represent normal characters, and are retained even if the code they are processing cannot be converted. In other words, if 'U+0067', which represents the letter 'g', is followed by the variant selector 'U+FE01', which represents VS-2, it will be rendered as 'g' just like 'U+0067' alone, but if you copy and paste the text, the 'U+FE01' at the end will also be copied.
By using variant selectors, which are not visible in the rendering but are included in the Unicode characters, it is possible to embed a 'secret message' in the character. Butler said, '256 is enough variation to represent one byte, which allows you to 'hide' one byte of data in other Unicode code points.'
For example, let's say you want to encode the string 'hello' in ASCII , which is the American character code, as '0x68, 0x65, 0x6c, 0x6c, 0x6f'. In that case, you can convert the bytes you want to embed into a variant selector by executing the following Rust code:
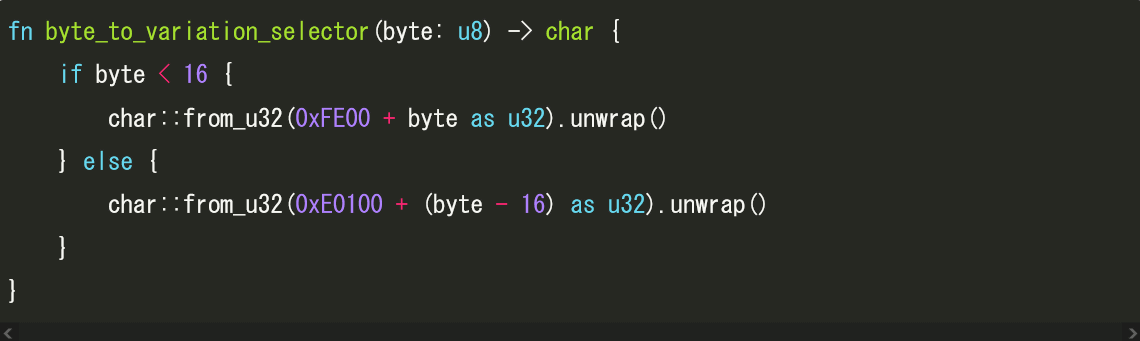
To encode a byte, we need to concatenate many of these variant selectors after the base code point.
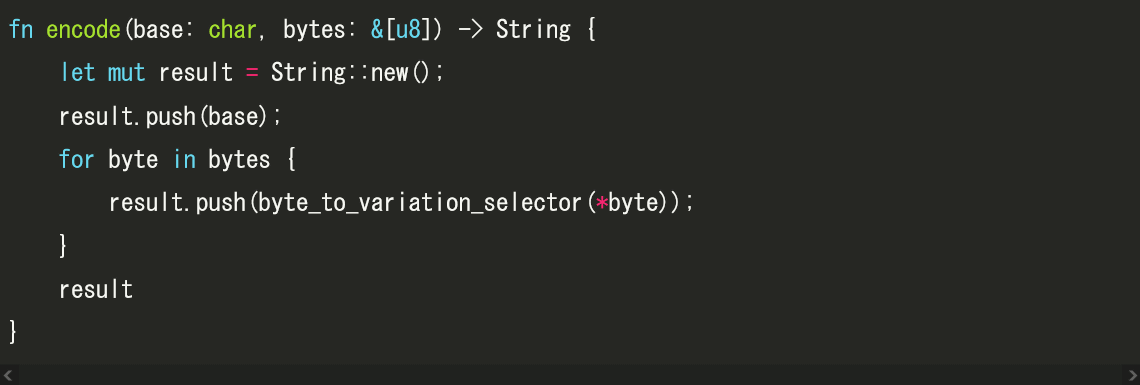
The following command can be used to encode the bytes '0x68, 0x65, 0x6c, 0x6c, 0x6f' which means 'hello'.

The resulting emoji looks like a normal emoji at first glance, but it actually contains the secret data 'hello.' When Butler pasted the emoji into the input field of his decoder , it indeed contained the string 'hello.'
Butler warns that embedding secret messages using variant selectors is an abuse of Unicode and should not be used in real life. He goes on to say that the following use cases could be considered for the abuse of this technique:
1: Bypassing content filters
Messages encoded in this way are invisible when rendered, allowing messages to be sent and received without being checked by human moderators or reviewers.
2: Text Watermark
Already, there are techniques for 'watermarking' messages sent to a large number of people by making subtle changes to each message, allowing researchers to trace the source of any leaks. Unicode-based secret messages can be used for more advanced watermarking because they are preserved even when copied and pasted.
Related Posts:







in Software, Web Service, Posted by log1h_ik