




画像生成AI「Stable Diffusion」を使って新しいインテリアデザインを作成しまくる試み

入力したテキストに則した画像を生成したり、ある画像から別の画像を生成したりすることができる画像生成AIの「Stable Diffusion」を使い、さまざまなインテリアデザインをAIに生成してもらうという試みをKaren X. ChengさんとJustin Alveyさんが行っています。
Using AI for design inspiration
— Karen X. Cheng (@karenxcheng) December 20, 2022
We used Stable Diffusion Depth to Image to get the consistency - collab with @justLV
See below for our process#ArtificialIntelligence #stablediffusion #interiordesign pic.twitter.com/teImanZsZF
Alveyさんによると、この試みはStable Diffusionのバージョン2.0で登場した、入力画像の奥行きを推測して画像を出力することができる「Depth-Guided」というモデルを利用し、模型で作成した簡易的なインテリアをベースにAIにさまざまなインテリアデザインを提案させています。
I used the #StableDiffusion 2 Depth Guided model to create architecture photos from dollhouse furniture.
— Justin Alvey (@justLV) December 20, 2022
By using a depth-map you can create images with incredible spatial consistency without using any of the original RGB image.
See ???? https://t.co/jAFWSxrCux
Depth-GuidedモデルはStable Diffusionのimg2img機能(ある画像から別の画像を生成する機能)を強化するために追加されたモデル。入力画像の深度情報を推測し、それをベースに別の画像を生成するため、元の画像の構図を出力画像に色濃く反映できるというのが特徴です。以下の画像は左から「入力画像」「入力画像から抽出した深度情報」「深度情報をベースに新しく出力した画像」です。

「Depth-Guidedモデルは、Stable Diffusionのバージョン2.0から微調整されており、深度関連の追加チャンネルが存在しているためユニーク」とAlveyさん。なお、Depth-Guidedモデルは単一の画像から深度を予測するモデルのMiDaSを利用しているそうで、以下のツイートの画像は上が「入力画像」で、下が「入力画像から生成した深度マップ」です。
2/ This model is unique as it was fine-tuned from the Stable Diffusion 2 base with an extra channel for depth.
— Justin Alvey (@justLV) December 20, 2022
Using MiDaS (a model to predict depth from a single image), it can create new images with matching depth maps to your "init image" pic.twitter.com/nq9xuvkUY7
そして深度マップをベースに出力したのが以下のツイートの画像。Alveyさんは「ノイズ除去強度を『1.0』に設定することで、元画像が使用されないようにしました。これによりプロンプトが大きく異なる場合でも、一貫してオブジェクトを生成できました。木製のドールハウス家具など、シンプルでわかりやすい形を入力画像に使用するのが最適でした」とツイートしています。
3/ I set the denoising strength to 1.0 so that none of the original RGB image was used
— Justin Alvey (@justLV) December 20, 2022
Even with widely different prompts it was able to generate consistent objects
Using simple, recognizable shapes such as wooden doll-house furniture worked great for this pic.twitter.com/tFu4IHezR4
通常の写真だと極端な遠近法により、出力画像がドールハウスのようになってしまうそうです。しかし、より長い焦点距離(iPhoneなら3倍ズーム)にして被写体から離れて写真を撮影することで問題は解決できたそうです。
4/ Regular photos ended up having an unavoidable “doll-house” feel to them (even with heavy prompt tweaking) due to the extreme perspective.
— Justin Alvey (@justLV) December 20, 2022
I found that changing to a longer focal length (3x on an iPhone) and capturing from further away resolved this. pic.twitter.com/Hs3VKFFvZn
Alveyさんが画像生成時に入力したテキストの事例も挙げられています。
「A beautiful rustic Balinese villa, architecture magazine, modern bedroom, infinity pool outside, design minimalism, stone surfaces(美しい素朴なバリのヴィラ、建築雑誌、モダンなベッドルーム、屋外のインフィニティ・プール、ミニマリズムデザイン、石の表面)」
5/ Here are a few of the prompts used:
— Justin Alvey (@justLV) December 20, 2022
"A beautiful rustic Balinese villa, architecture magazine, modern bedroom, infinity pool outside, design minimalism, stone surfaces" pic.twitter.com/N7ipTFbXcU
「Luxurious modern studio bedroom, trending architecture magazine photo, colorful framed art hanging over bed, design minimalism, furry white rugs, trendy, industrial, pop art, boho chic(豪華でモダンなスタジオベッドルーム、トレンドの建築雑誌の写真、ベッドにかけられたカラフルなフレームアート、ミニマリズムなデザイン、白いファーのラグ、トレンディ、インダストリアル、ポップアート、ボーホーシック)」
6/ "Luxurious modern studio bedroom, trending architecture magazine photo, colorful framed art hanging over bed, design minimalism, furry white rugs, trendy, industrial, pop art, boho chic" pic.twitter.com/hlcMRQjJcu
— Justin Alvey (@justLV) December 20, 2022
「Retro bedroom studio, arcade, 80's style, vintage framed posters, trending architecture magazine, rugs, metal industrial pipes, murals, guitars and sound equipment, grunge, concrete floor(レトロなベッドルームスタジオ、アーケード、1980年代スタイル、ビンテージのフレーム付きポスター、トレンドの建築雑誌、ラグ、金属製の工業用パイプ、壁画、ギターと音響機器、グランジ、コンクリート床)」
7/ "Retro bedroom studio, arcade, 80's style, vintage framed posters, trending architecture magazine, rugs, metal industrial pipes, murals, guitars and sound equipment, grunge, concrete floor" pic.twitter.com/3YeQL4q8OA
— Justin Alvey (@justLV) December 20, 2022
画像生成時に入力するテキストで、深度マップがどのように変化するかが大きく変化してきます。そのため、入力するテキストにはある程度の創造性が必要になるとAlveyさん。例えば以下のツイートの画像のように、花瓶の深度マップは、入力するテキストによって似たような形のおもちゃやろうそく、彫刻、ギター、ミッキーの被り物をした子どもとして出力されています。
8/ There is some “creativity” in how the depth-map is matched under the prompt.
— Justin Alvey (@justLV) December 20, 2022
Here are a few outtakes where the model tried to match the plant to antlers, toys, candles, statues, a double-necked guitar and even a kid with Mickey ears????
Follow for more creative experiments ???????? pic.twitter.com/XPIwpG7o8d
・関連記事
画像生成AI「Stable Diffusion」のバージョン2.0が登場、出力画像の解像度が拡大&デジタル透かしを入れられる機能も - GIGAZINE
画像生成AI「Stable Diffusion」がどのような仕組みでテキストから画像を生成するのかを詳しく図解 - GIGAZINE
アーティストの権利侵害やポルノ生成などの問題も浮上する画像生成AI「Stable Diffusion」の仕組みとは? - GIGAZINE
画像生成AI「Stable Diffusion」を使いこなすために知っておくと理解が進む「どうやって絵を描いているのか」をわかりやすく図解 - GIGAZINE
・関連コンテンツ




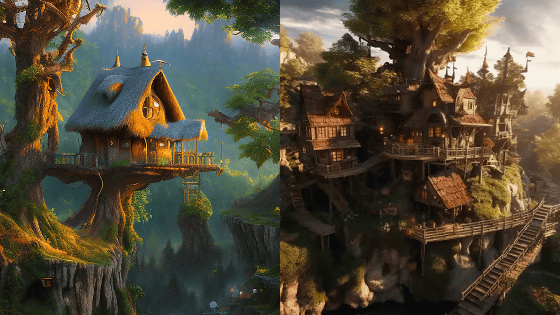



in ソフトウェア, デザイン, 創作, Posted by logu_ii
You can read the machine translated English article An attempt to create a new interior desi….