




OpenAIが対話AIや画像生成AIに使われる「埋め込みモデル」を刷新、性能当たりの価格が99.8%も安価に
AI開発団体のOpenAIが、テキストや画像を数字に変換するEmbedding(埋め込み)モデル「text-embedding-ada-002」を発表しました。text-embedding-ada-002は従来のモデルよりも大幅に機能が向上し、コストパフォーマンスも高くなり、より使いやすくなっているとのことです。
New and Improved Embedding Model
https://openai.com/blog/new-and-improved-embedding-model/
Embeddings - OpenAI API
https://beta.openai.com/docs/guides/embeddings
アルゴリズムがテキストや画像を認識するためには、テキストや画像を数値のデータに変換する必要があります。埋め込みは、テキストや画像を何らかのベクトルに変換する工程で、昨今の自然言語処理モデルや画像生成AIには必要不可欠な技術です。
text-embedding-ada-002にアクセスするには、PythonでOpenAIのAPIを叩ける「OpenAI Python Library」で、モデル名に「text-embedding-ada-002」を指定すればOK。以下は「porcine pals say」という文字列を数値に変換するためのコード。
import openai
response = openai.Embedding.create(
input="porcine pals say",
model="text-embedding-ada-002"
)OpenAIによると、テキスト検索・コード検索・文の類似性において、text-embedding-ada-002は従来のモデルよりもパフォーマンスが優れており、テキスト分類では従来と同等のパフォーマンスを発揮したとのこと。
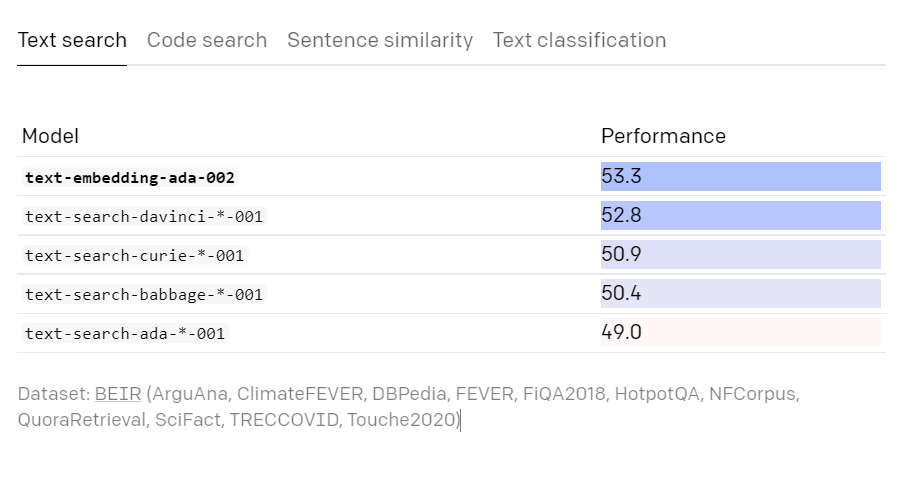
以下はテキスト検索を比較したところ。「Performance」の数字が大きいほど、パフォーマンスが優れていることを示しています。
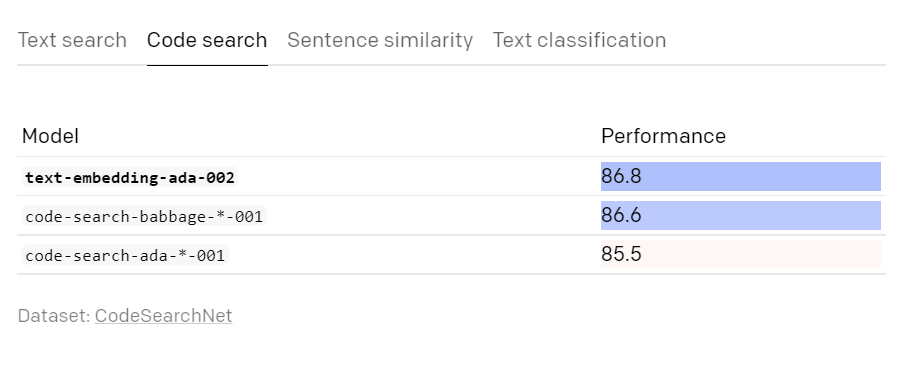
コード検索
文の類似性
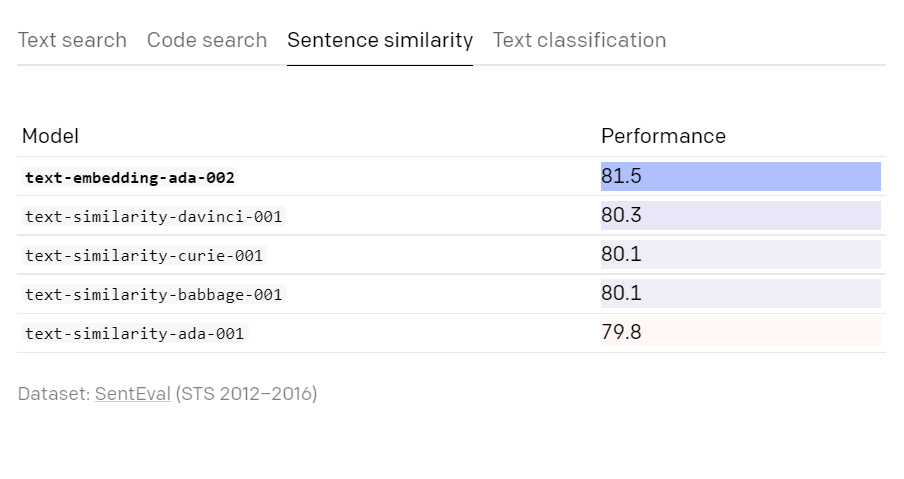
テキスト分類は前モデルからややパフォーマンスが下がっていますが、90台をキープしていることから、OpenAIはほぼ同等のパフォーマンスを発揮しているとしています。
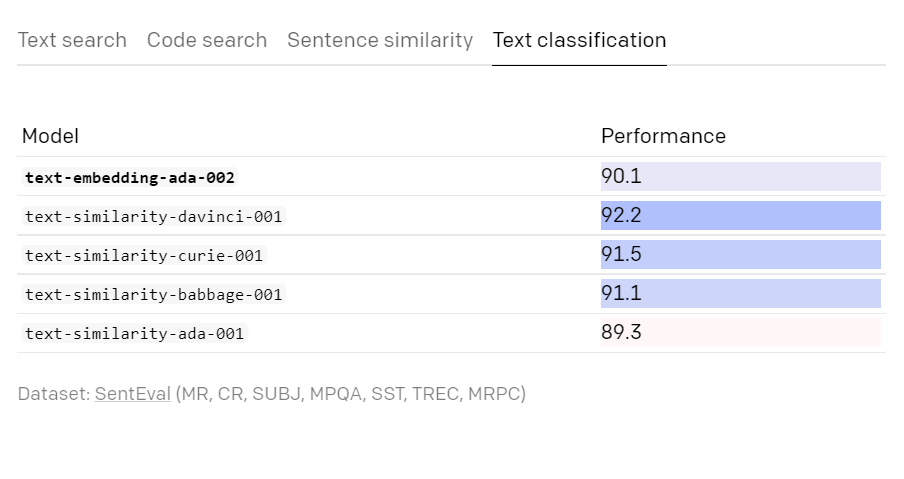
従来のモデルは、「text-search-davinci-*-001」「text-similarity-davinci-001」などのように、目的に応じてモデルが別になっていましたが、text-embedding-ada-002ではテキスト検索・コード検索・文の類似性・テキスト分類が統合され、1つのモデルで行えるようになりました。
また、text-embedding-ada-002はこれまで入力可能なトークン長が2048までだったのが8192にまで増加。これにより、より長い文章を処理できるようになります。さらに、テキストを落とし込むベクトルの次元が1536次元と、前世代モデルの8分の1に抑えられるようになったとのこと。加えて、text-embedding-ada-002の使用料は前世代の「Davinci」から90%値下げされており、コストパフォーマンスで考えると従来よりも99.8%お得になっているとOpenAIは主張しています。
OpenAIは「新しい埋め込みモデルは、自然言語処理とコード タスクのためのはるかに強力なツールです。お客様がそれぞれの分野でさらに優れたアプリケーションを作成するためにそれをどのように使用するかを楽しみにしています」と述べました。
・関連記事
OpenAI開発のテキスト生成AI「GPT-3」がどんな処理を行っているのかを専門家が解説 - GIGAZINE
OpenAIが高性能文字起こしAI「Whisper」を発表、日本語にも対応し早口言葉や歌詞も高精度に文字起こし可能 - GIGAZINE
OpenAIがAI画像ジェネレーター「DALL・E2」の一般向け公開がスタート - GIGAZINE
OpenAIが入力した自然言語から自動でコードを出力するAIシステム「Codex」をリリース - GIGAZINE
オープンソースのニューラルネットワーク向けプログラミング言語「Triton」をOpenAIが公開 - GIGAZINE
OpenAIが開発した画像認識AI「CLIP」の思考の特徴とは? - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by log1i_yk
You can read the machine translated English article OpenAI revamps the ``embedded model'….