




AIコードレビューツール「Open Code Review」、既存のAIに各種ルールを設定してレビュー能力を底上げ可能&Alibabaグループで100万件のコード欠陥を検出済み

AIエージェントを用いたソフトウェア開発が爆発的に普及しつつあり、コードレビューも人力ではなくAIに任せる流れができつつあります。しかし、AIを用いたコードレビューではチェック漏れや品質のばらつきが発生しがちです。そんな問題を解決するべく中国有数のテクノロジー企業であるAlibabaが開発したコードレビューエージェントシステムが「Open Code Review」で、すでにAlibabaグループの数万人の開発者によって使用され100万件のコード欠陥を検出しているそうです。
Open Code Review — Agent Native Code Review
https://alibaba.github.io/open-code-review/
AlibabaはClaude CodeなどのAIエージェントにコードレビューを任せた際の問題点として以下の3点を挙げています。
網羅性の不足:複数のファイルが関係する大規模な変更をレビューする際に、エージェントが一部のファイルにのみ着目してしまい、他のファイルの変更を見逃してしまう
位置ずれ:問題報告時に、行番号やファイル参照を誤って報告してしまう
品質が不安定:プロンプトのわずかな変更でレビュー品質が大きく変動してしまう
Alibabaは既存のエージェントで問題が発生する原因ついて「言語モデルに基づくロジックでは、レビュープロセスに関する厳格な制約が欠けてしまう」と指摘。Open Code Reviewではファイル選択やルールマッチングなどに言語モデルベースではなくエンジニアリングロジックベースの仕組みを取り入れることで、AIエージェントシステムでありながら決定論的なレビューを実行できるようにしています。
Open Code Reviewでは任意のAIモデルを用いてレビューを実行可能で、既存のエージェントと比べてトークン使用量を5分の1に抑えることができます。すでに2万人以上のAlibabaグループ社員によって使用されており、100万件以上の欠陥を検出することに成功しています。

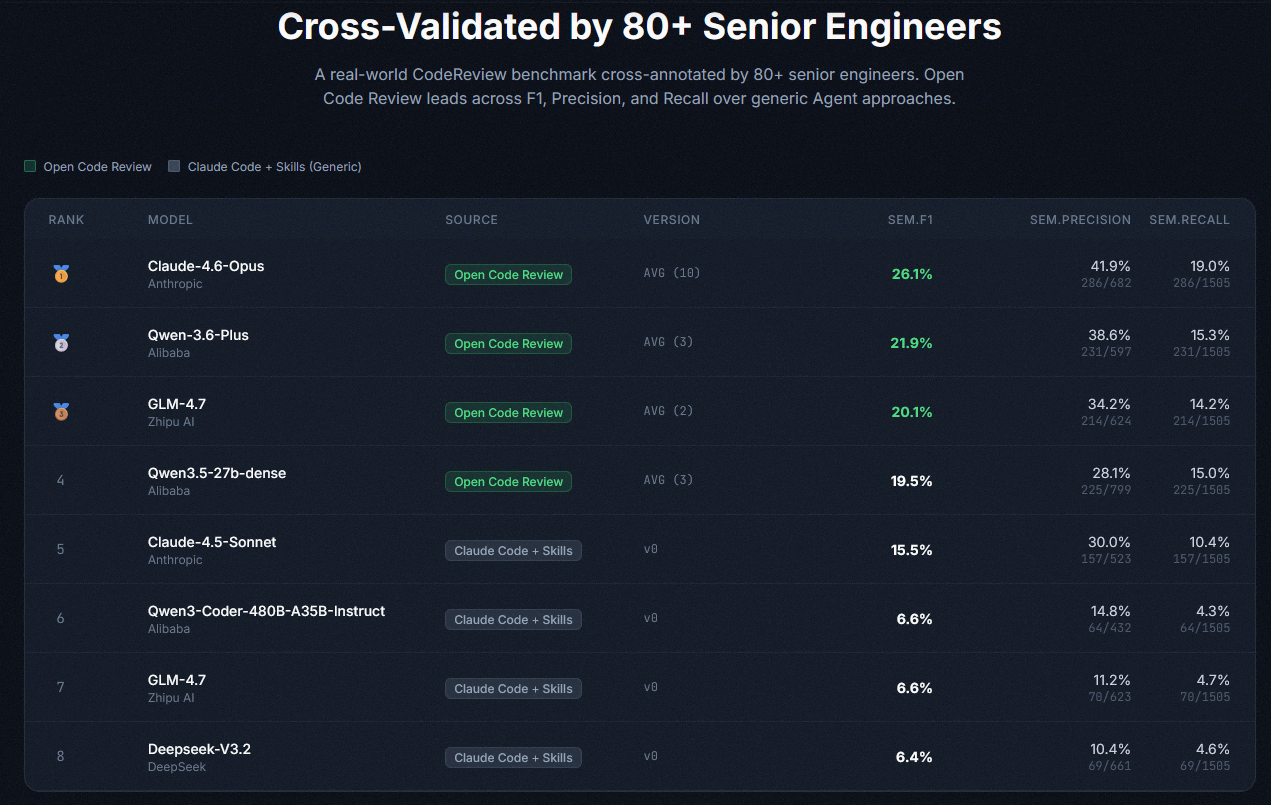
Open Code ReviewとClaude Codeのレビュー性能ベンチマーク結果を示した表が以下。Open Code ReviewでClaude Opus 4.6を使用した際に最もレビュー品質が高くなり、同じGLM-4.7を使用した場合でもClaude CodeよりOpen Code Reviewの方が性能が高くなりました。
Open Code Reviewのソースコードは以下のリンク先で公開されています。
GitHub - alibaba/open-code-review: Battle-tested at Alibaba's scale. Hybrid architecture code review tool: deterministic pipelines + LLM Agent, precise line-level comments, built-in fine-tuned ruleset (NPE, thread-safety, XSS, SQL injection), OpenAI & Anthropic compatible. · GitHub
https://github.com/alibaba/open-code-review
・関連記事
Anthropicがプルリクエストのバグを自動検出する「Code Review」を発表、1回あたりのトークン使用量は平均2400円分から - GIGAZINE
GitHub Copilotが「AIアシスタント」から「AI開発チーム」へ進化、専用アプリの全貌が明らかに - GIGAZINE
Anthropicが「AIがAIを作る」自己改善ループのリスクを警告、AI開発をAI自身が加速する可能性を論じる - GIGAZINE
ソフトウェア開発でAI丸投げがダメな理由 - GIGAZINE
・関連コンテンツ






in Posted by log1o_hf