




Googleが「ガビガビの低解像度画像を高解像度画像に変換するAIモデル」の性能を改善、人間が判別できないレベルに

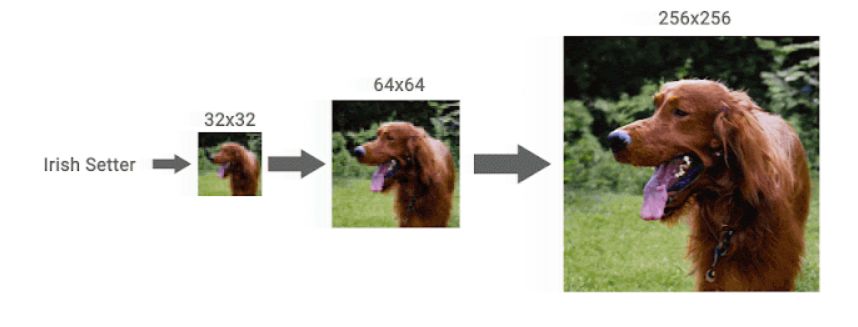
GoogleのAI研究チームであるGoogle AIが、低解像度画像にあえてノイズを追加して「純粋なノイズ」になるまで加工し、そこから高解像度画像を生成する「diffusion model(拡散モデル)」という手法を改善する新たなアプローチを発表しました。「画質の悪い低解像度画像から高解像度画像を生成する技術」には、古い写真の復元から医療用画像の改善まで幅広い用途が想定され、機械学習の活躍が期待されているタスクの1つです。
Google AI Blog: High Fidelity Image Generation Using Diffusion Models
https://ai.googleblog.com/2021/07/high-fidelity-image-generation-using.html
Enhance! Google researchers detail new method for upscaling low-resolution images with impressive results: Digital Photography Review
https://www.dpreview.com/news/0501469519/google-researchers-detail-new-method-upscaling-low-resolution-images-with-impressive-results
Google's New AI Photo Upscaling Tech is Jaw-Dropping | PetaPixel
https://petapixel.com/2021/08/30/googles-new-ai-photo-upscaling-tech-is-jaw-dropping/
一般に、低解像度画像から高解像度画像を復元するタスクには敵対的生成ネットワーク(GANs)、変分オートエンコーダー(VAE)、自己回帰モデルなどの生成モデルが使われています。しかし、GANsには生成する画像の多くが複製になってしまうモード崩壊が生じる場合があるほか、自己回帰モデルには合成速度が遅いといった問題点があるなど、これらの生成モデルには欠点があるとのこと。
一方でGoogle AIが2015年に発表した「拡散モデル」という生成モデルは、トレーニングにおける安定性と生成する画像および音声の品質が高いことから、近年見直されているそうです。そして新たに、Google AIは「Super-Resolution via Repeated Refinements(SR3)」および「Cascaded Diffusion Models(CDM)」という2つの新たな拡散モデルアプローチを用いることで、拡散モデルの画像合成品質を向上させることに成功したと述べています。
SR3はまず、低解像度の画像にガウス雑音を徐々に追加していき、「純粋なノイズ画像」になるまで破損させるとのこと。その後、トレーニングしたニューラルネットワークで画像の破損プロセスを逆転させることでノイズを取り除いていき、当初の解像度を超える高解像度画像を生成するという仕組みです。
左が入力データである64×64ピクセルの低解像度画像であり、右は低解像度画像にガウス雑音を追加して「純粋なノイズ画像」にしたもの。
徐々に「純粋なノイズ画像」からノイズを取り除いていき……

ついに元画像よりはるかに精細な顔写真が生成されました。

女性の画像でも同様に機能する模様。

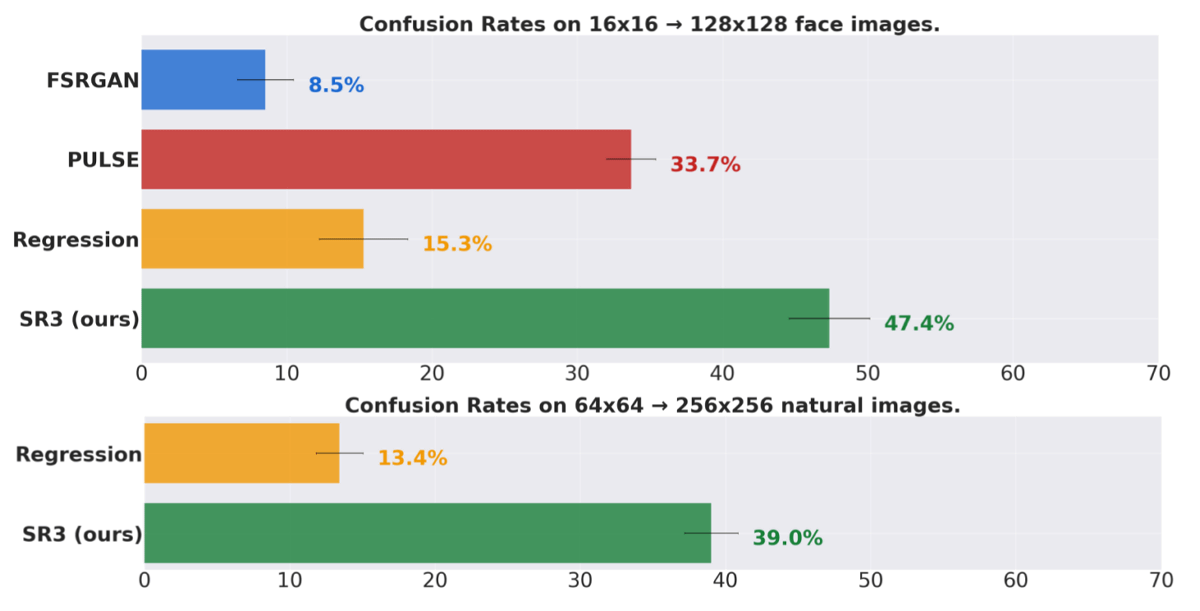
実際に研究チームが、人間の被験者に「元の画像」と「低解像度画像からさまざまな手法で生成した画像」を見せて、どちらが元の画像かを判別してもらった結果がこれ。被験者の誤答率(混乱率)が50%に近いほど、AIが生成した画像と元の画像のどちらが本物か判別がつかなくなっているということになります。SR3はFSRGAN(Face Super-Resolution Generative Adversarial Network)やPULSE、Regression(自己回帰生成モデル)といった手法と比較して、「16×16ピクセルの画像を128×128ピクセルにした場合」(上)と「64×64ピクセルの画像を256×256ピクセルにした場合」(下)のいずれにおいても混乱率が高くなっています。特に16×16ピクセルの画像を128×128ピクセルにした場合の混乱率は47.4%であり、被験者はほとんどAIモデルが生成した画像を判別できなかった模様。
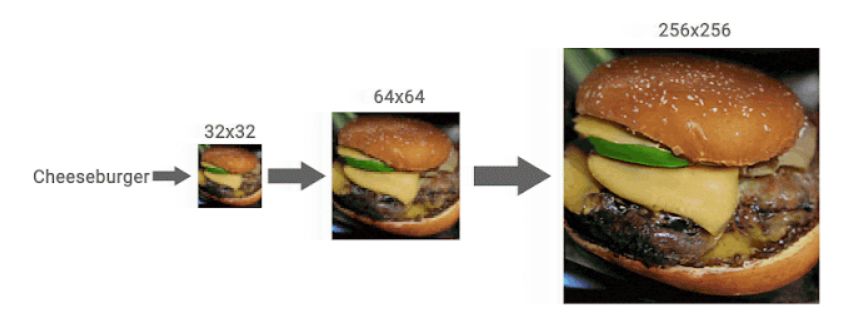
さらにGoogle AIは、大規模な画像認識データセットのImageNetでトレーニングしたクラス条件付き(ラベル付き)の拡散モデルであるCDMも発表しています。ImageNetには多様なデータセットが含まれているため、生成する画像が元画像からかけ離れたものになる可能性がありますが、CDMはラベル情報と共に生成モデルを複数の空間解像度で徐々にアップスケーリングすることで、品質の高い画像を生成できるとのことです。

・関連記事
8×8ピクセルに縮小した画像から元の画像を予想する技術をGoogle Brainが開発 - GIGAZINE
Googleが低解像度画像を爆速で高画質化する機械学習を使った技術「RAISR」を発表 - GIGAZINE
モザイク画像の解像度を64倍にして限りなく高品質の画像を生み出す技術が開発される - GIGAZINE
「モザイク画像の解像度を64倍にする研究」が人種差別の議論に発展、非難を集めた研究者はアカウントを停止 - GIGAZINE
無料で粗い画像を機械学習したAIがきれいに補完して拡大してくれる「Let’s Enhance」を使ってみた - GIGAZINE
ガビガビの低解像度写真を高解像度な写真に変換できる「EnhanceNet-PAT」が登場 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, サイエンス, Posted by log1h_ik
You can read the machine translated English article Google improves the performance of 'AI m….