




無料キャプチャソフト「Webrecorder」はブラウザで閲覧した内容を「そっくりそのまま」キャプチャ可能
気になるウェブサイトをPocketやInstapaperといった「後で読む」サービスに保存したり、削除されてしまったウェブサイトをインターネットアーカイブで閲覧したりしたことがある人は少なくないはず。無料のオープンソースサービス「Webrecorder」を使うと、閲覧したウェブサイトのコンテンツをそのままキャプチャし、後で閲覧することができます。
Webrecorder | Homepage
https://webrecorder.io/
Release Webrecorder Desktop 2.0.1 · webrecorder/webrecorder-desktop · GitHub
https://github.com/webrecorder/webrecorder-desktop/releases/tag/v2.0.1
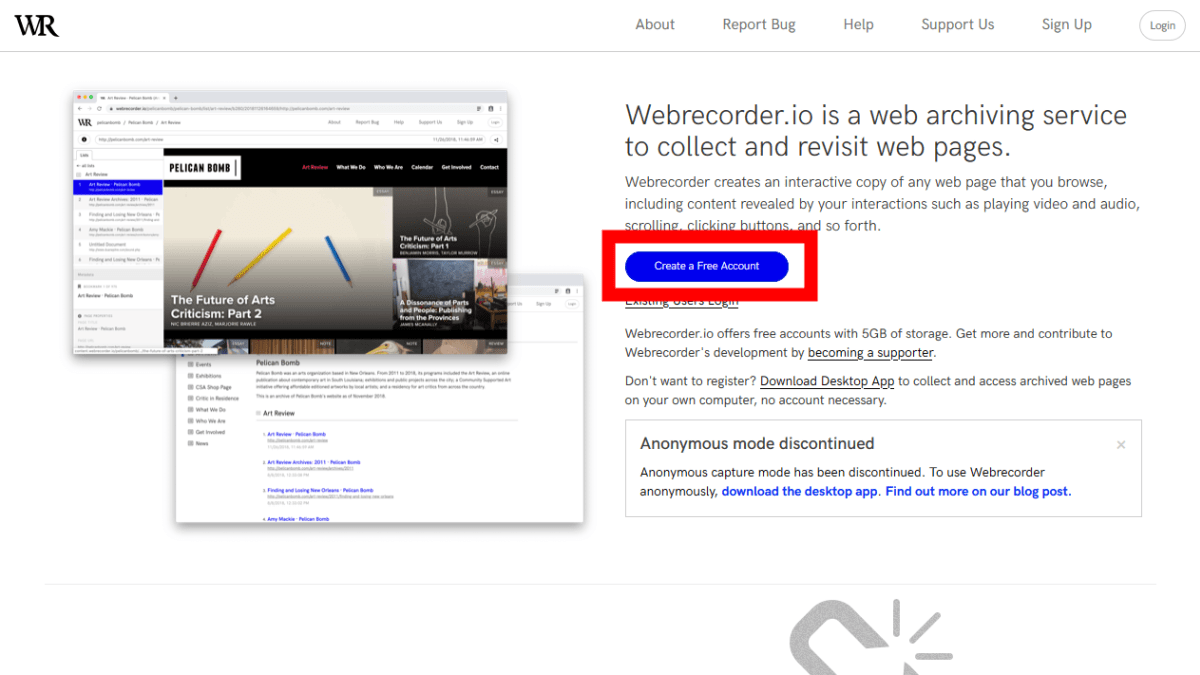
Webrecorderにはクラウド版とデスクトップ版があります。クラウド版はアカウントを登録してクラウドにウェブサイトのコンテンツを保存するのに対し、デスクトップ版はアカウント不要でローカルにコンテンツを保存するとのこと。クラウド版でも後からコンテンツをローカルに保存できるので、今回はクラウド版を使用してみます。Webrecorderのウェブサイトにアクセスして「Create a Free Account」をクリック。
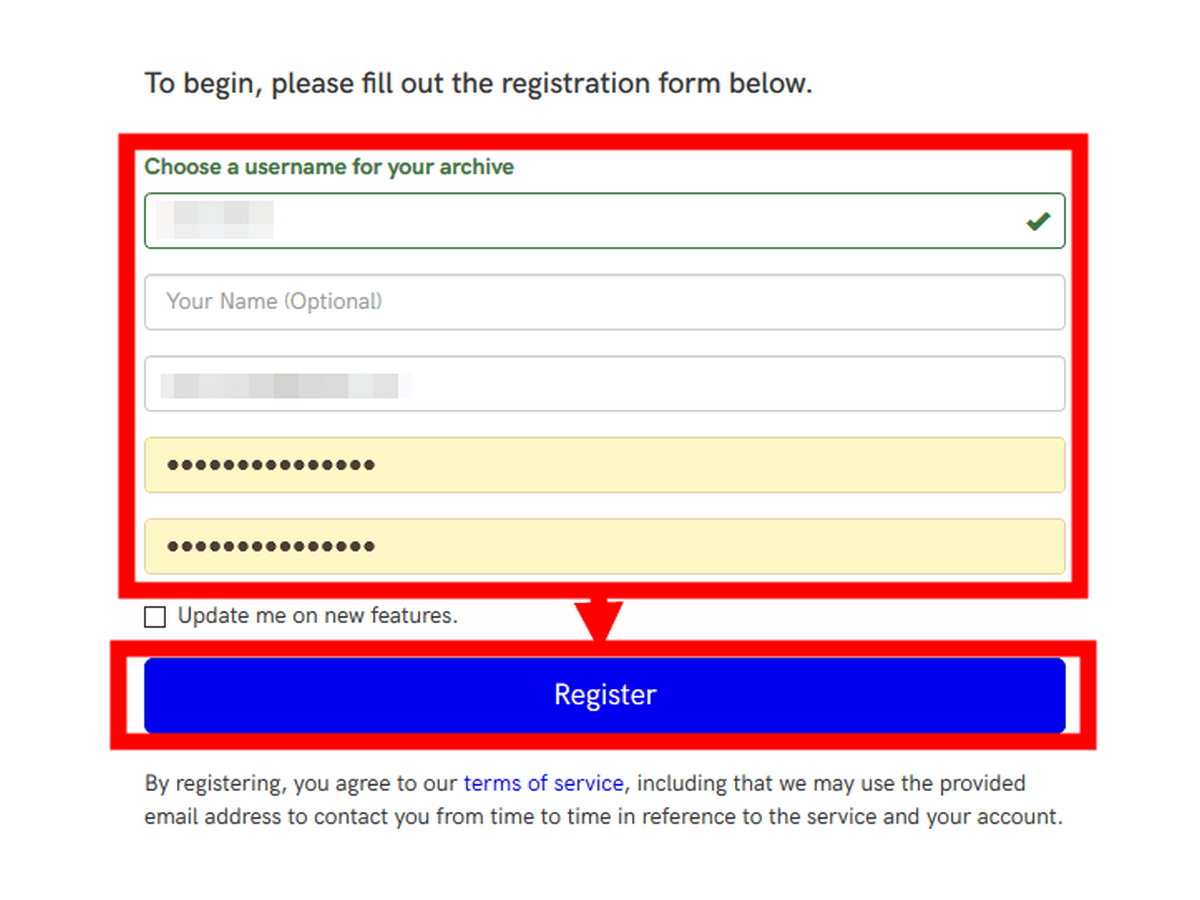
ユーザー名、メールアドレス、パスワードを入力して「Register」をクリックします。
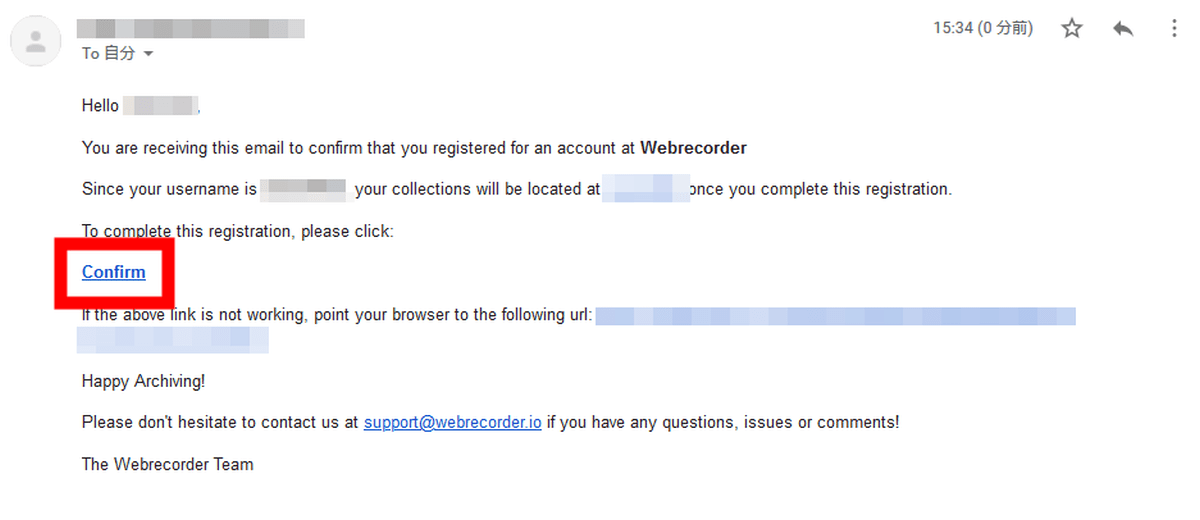
登録したメールアドレスに確認のメールが届くので、「Confirm」をクリック。
登録を完了するため「Complete Registration」をクリックします。
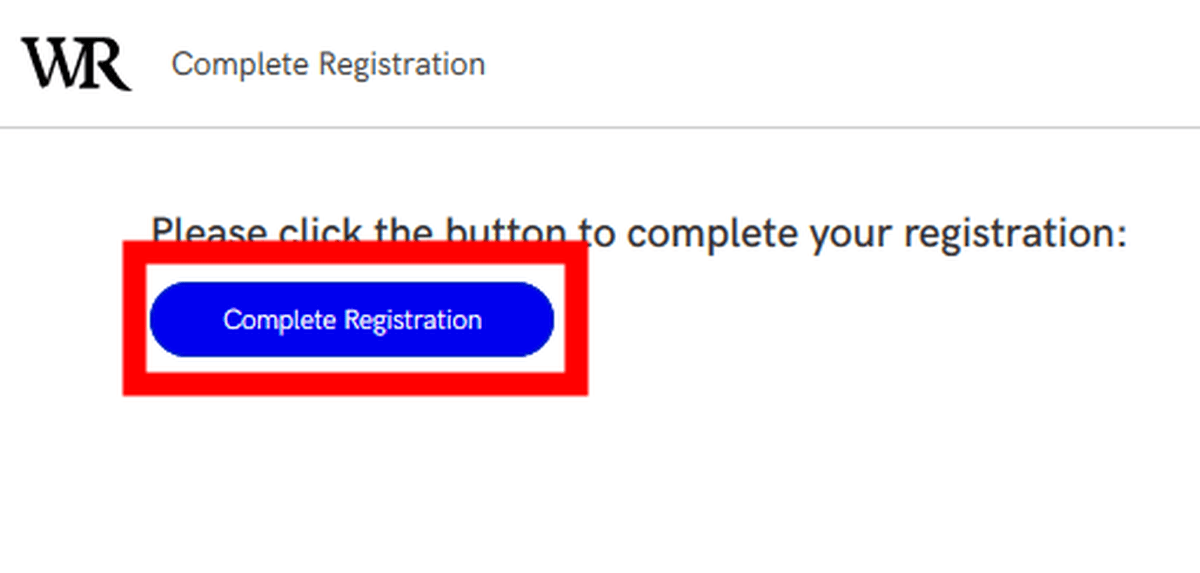
登録完了を表すメッセージが表示されました。「Proceed to Homepage」をクリックしてホームページへ移動します。
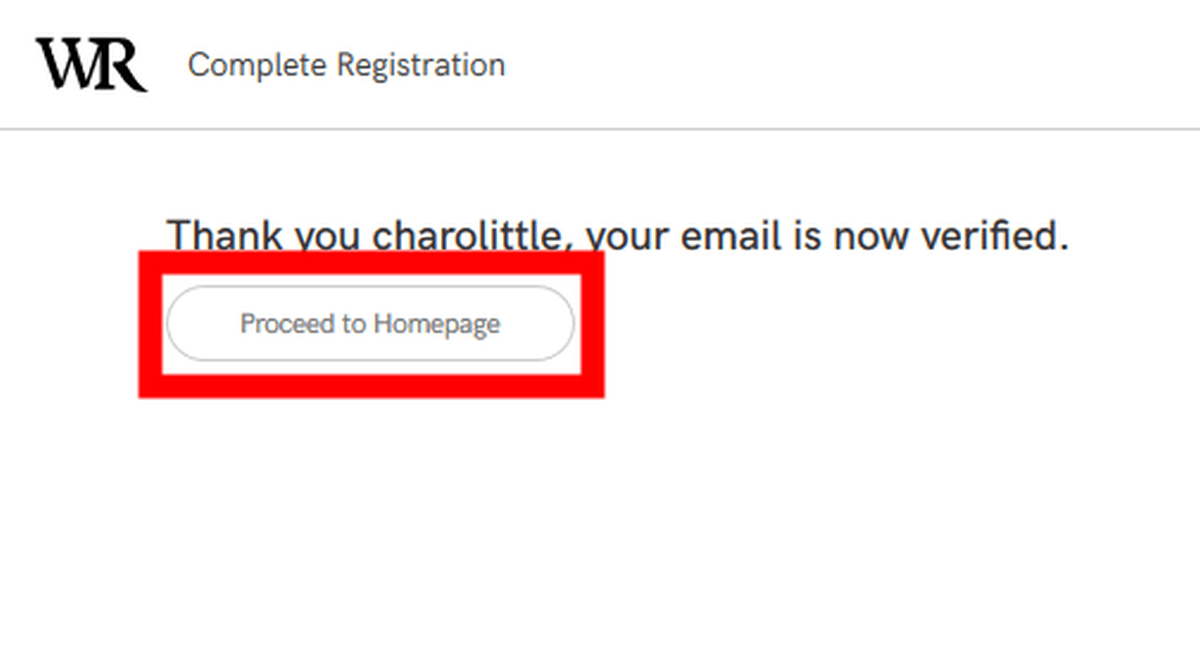
Webrecorderのホームページが表示されました。
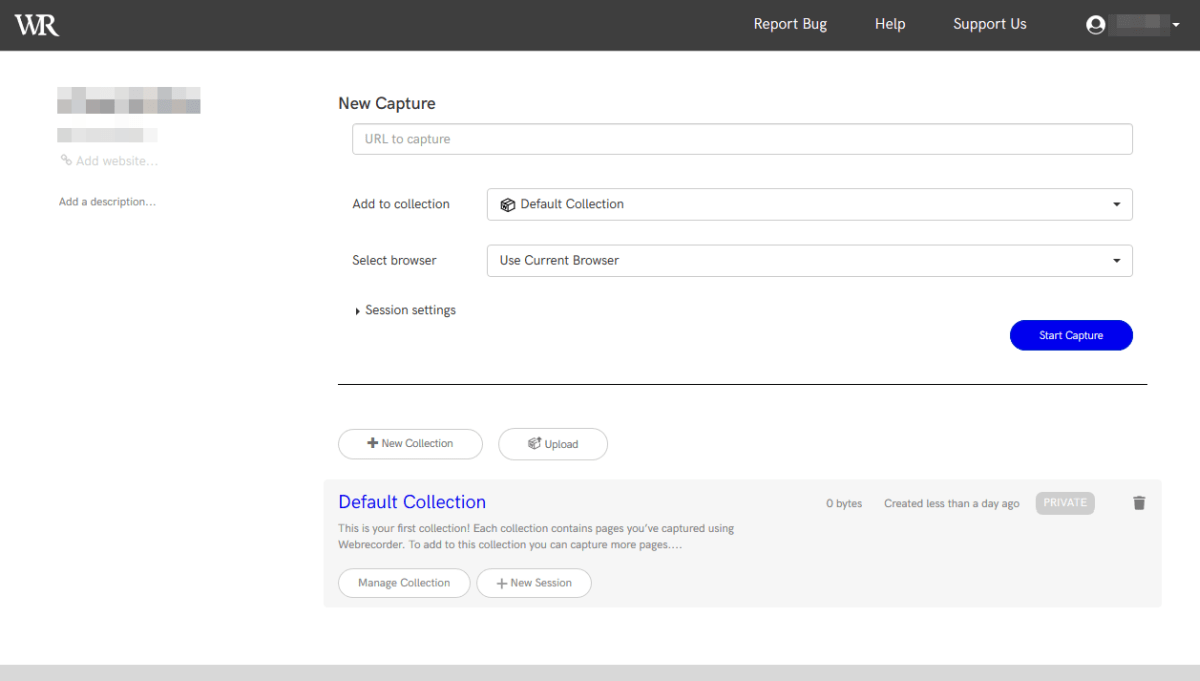
キャプチャしたいウェブサイトのURLを入力します。

「Add to Collection」では、一連のキャプチャ結果に名前を付けて整理することができます。
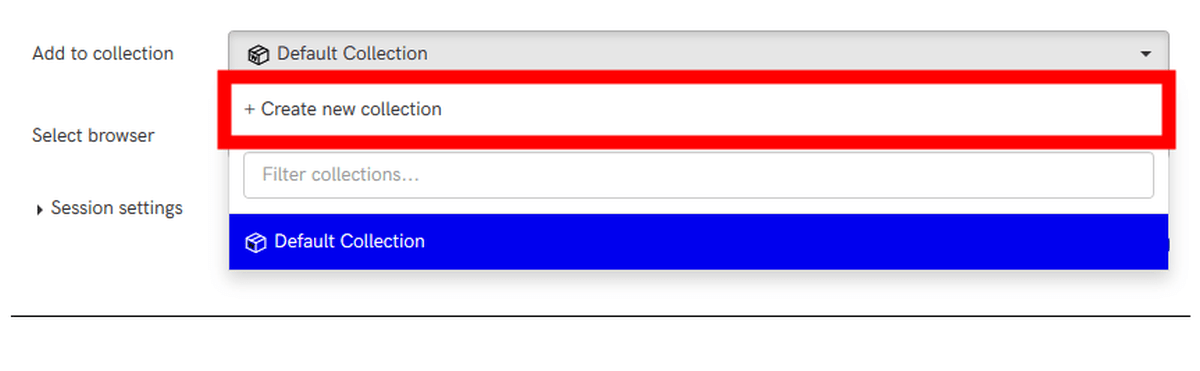
「Collection Name」に名前を入力し、「Create」をクリック。なお、「Make public (visible to all)?」にチェックを入れると、キャプチャした内容が誰でも閲覧できる状態で保存されます。
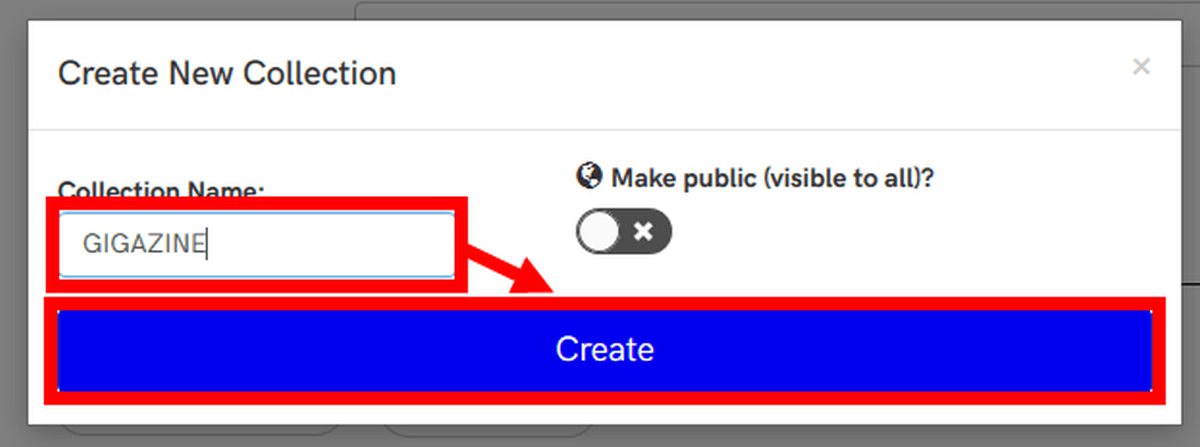
「Select browser」では、キャプチャに使用するブラウザを選択することができます。自分が現在使用しているブラウザのほか、ChromeとFirefoxの特定バージョンをリモートで使うこともできます。ひとまず利用中のブラウザでキャプチャしたいので「Use Current Browser」を選択します。
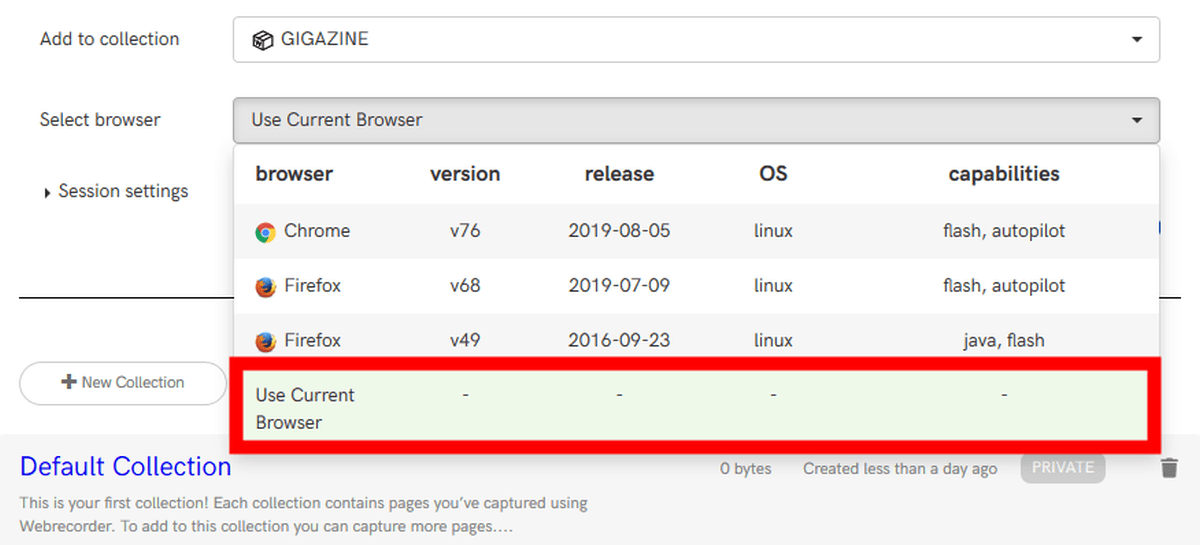
設定が完了したら「Start Capture」をクリック。
キャプチャしたいウェブサイトが表示されました。
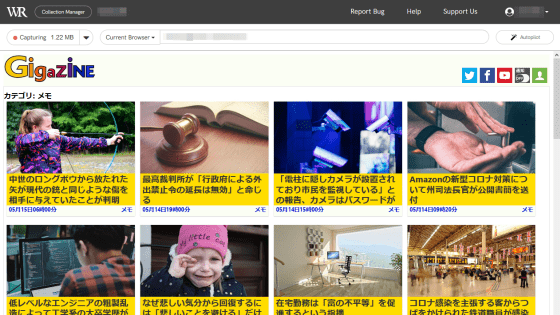
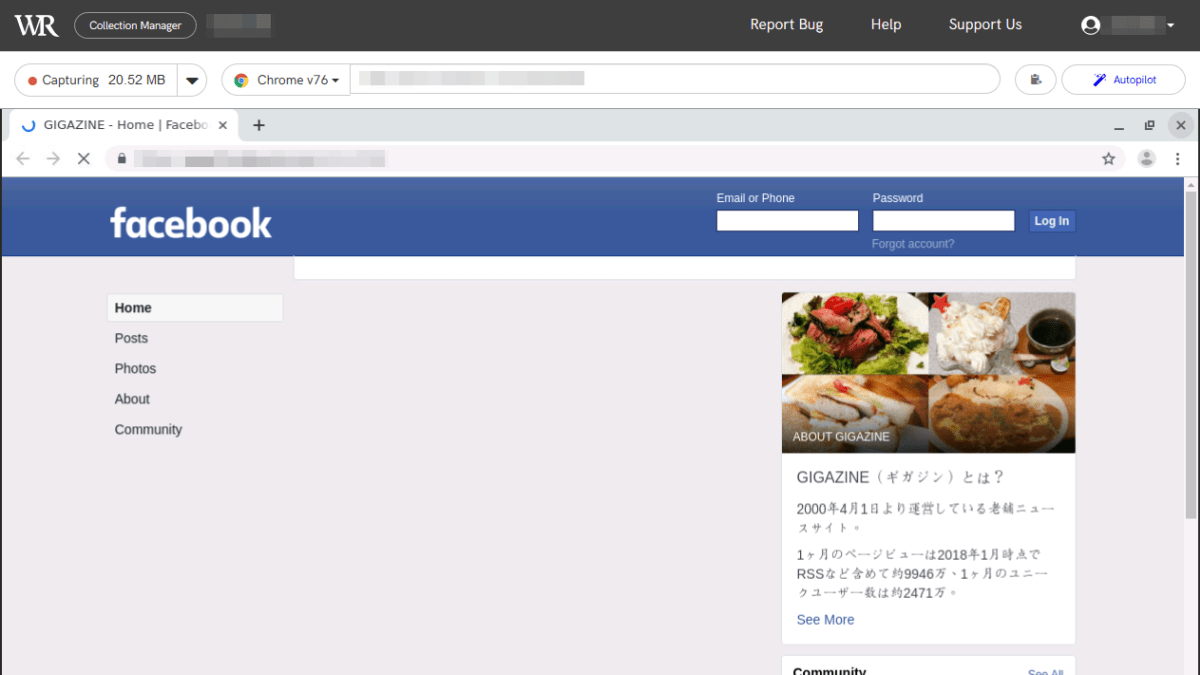
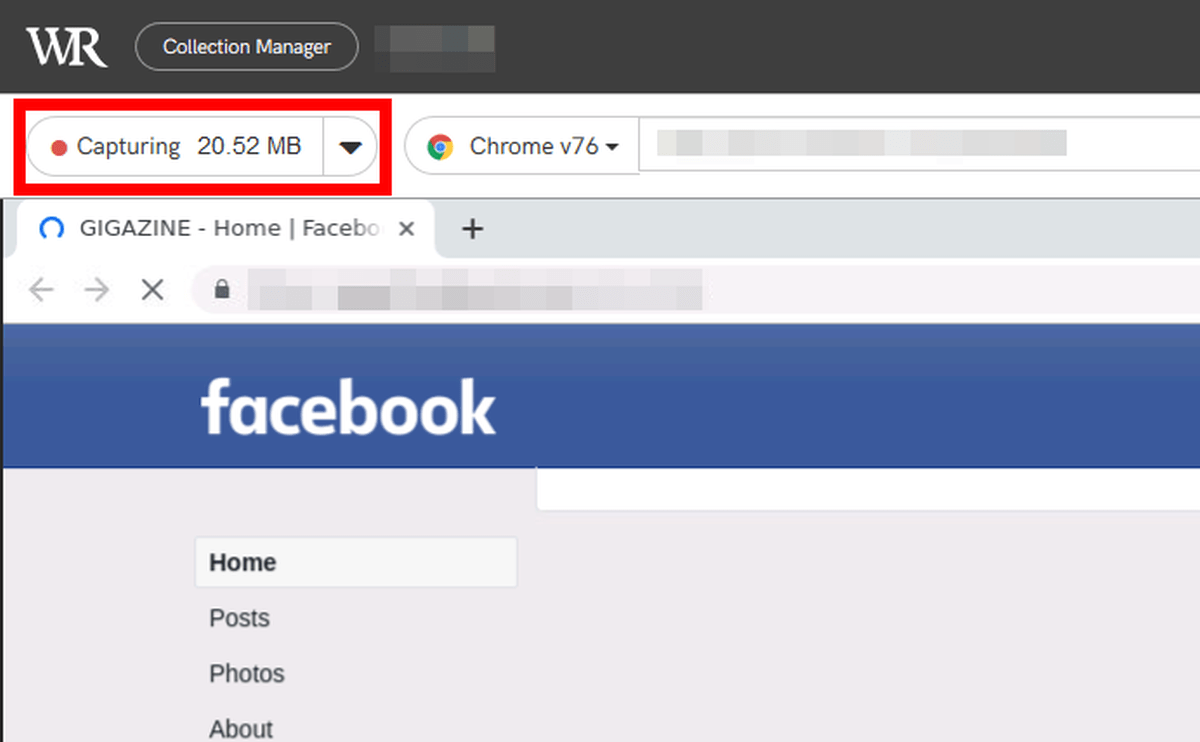
左上にはキャプチャしたデータ容量が表示されています。
画面をスクロールすると読み込まれた新しいコンテンツがWebrecorderによってキャプチャされるので、キャプチャしたデータ容量も増えていきます。なお、Webrecorderのクラウド版では無料でクラウドに保存できるデータ容量は5GBまでとなっています。
キャプチャしたいページを開いて、どんどんコンテンツを保存していきます。
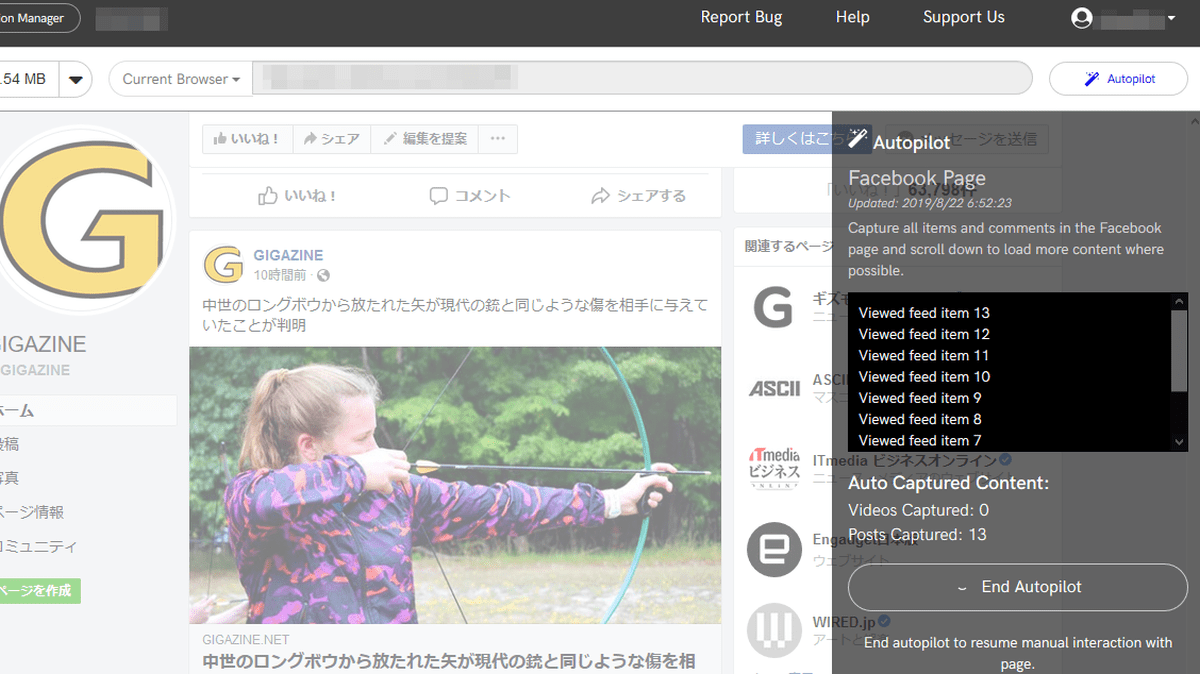
Webrecorderはページ単位ではなくブラウザ上の行動単位でウェブサイトをキャプチャするので、異なるウェブサイトをまたがって保存することが可能。試しにFacebookを開いてみます。
別タブでFacebookの画面が表示されました。Facebookのページでのキャプチャ内容は、先ほどまで閲覧していたページのキャプチャ内容と合わせて保存され、後でまとめて閲覧できます。

Twitter、Instagram、Facebookなど一部のウェブサイトでは、自動でブラウザ画面を操作しキャプチャを行ってくれる「Autopilot」のボタンが現れます。Autopilotを利用するため、ボタンをクリックして「Start Autopilot」をクリック。
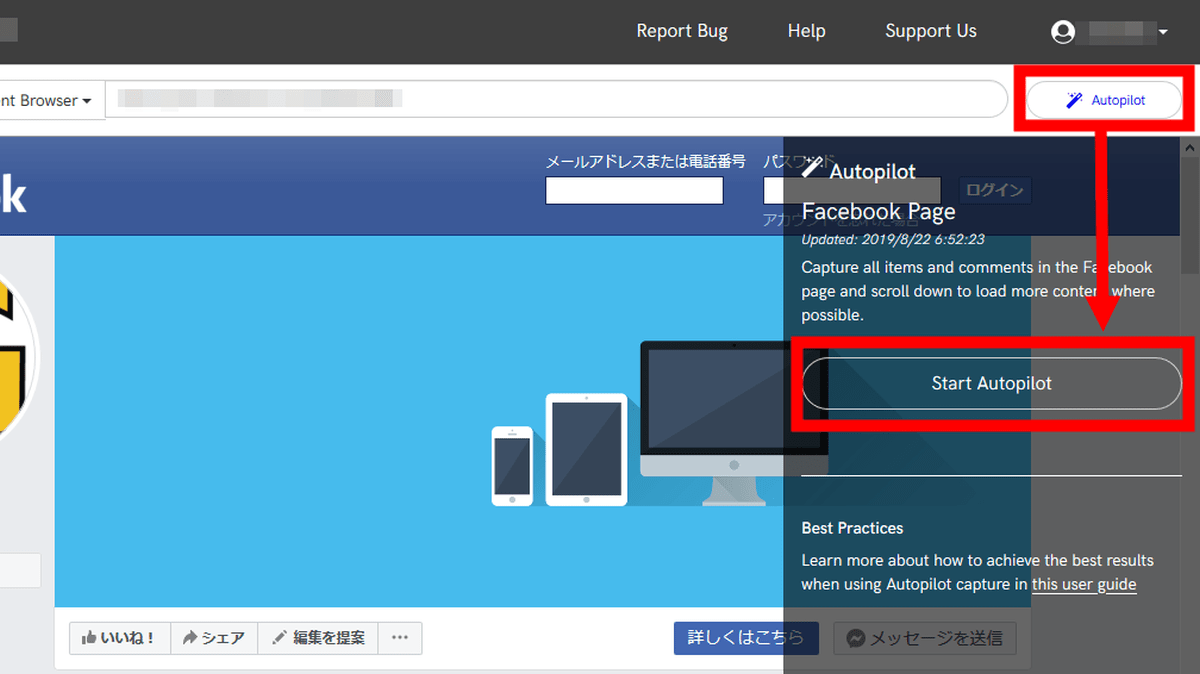
クリックすると、自動で画面がスクロールし、ページの読み込みとキャプチャが始まります。
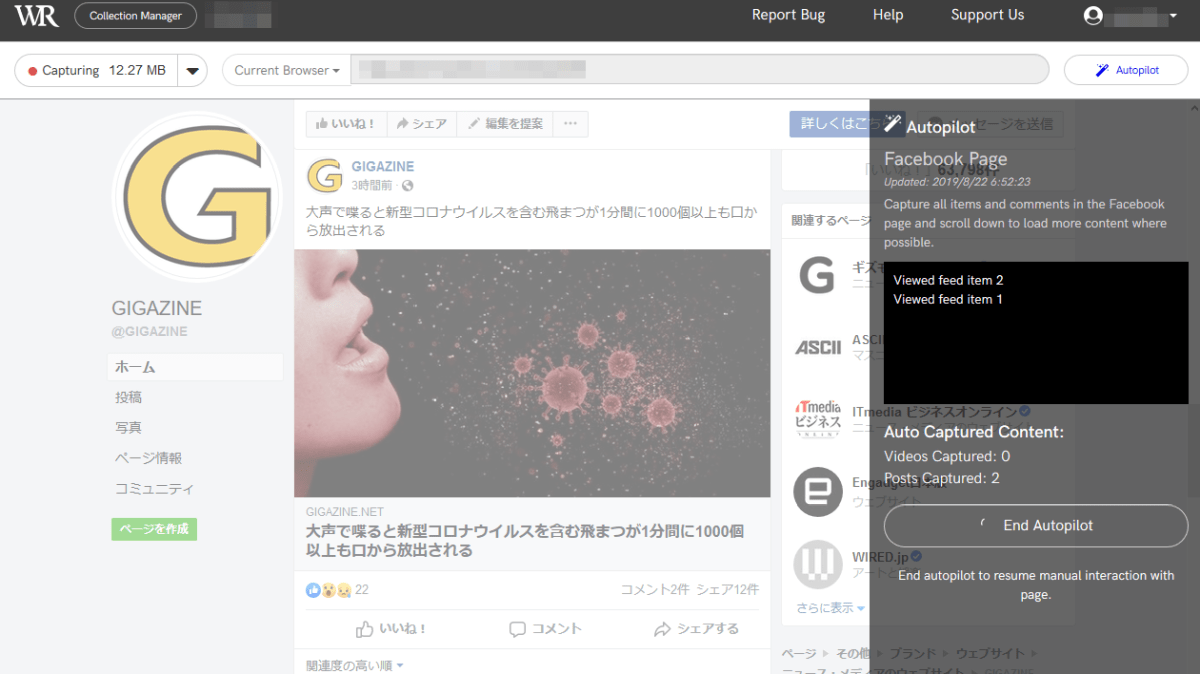
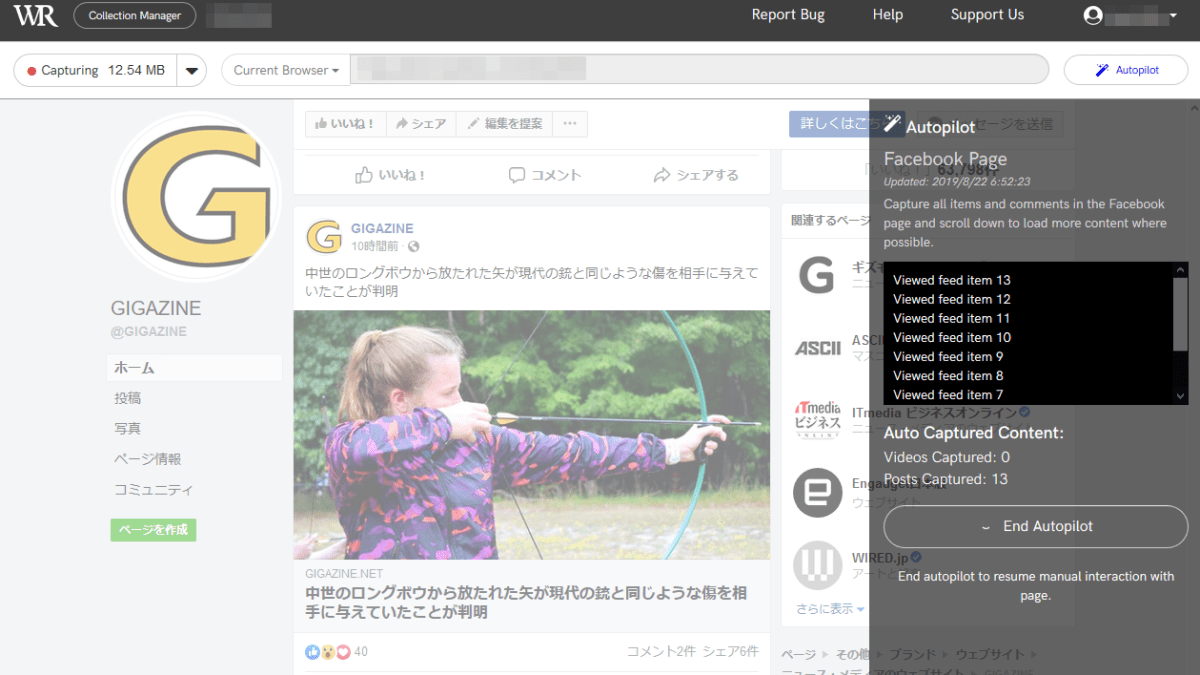
自動で次々とキャプチャされていくので、ユーザー側の操作は何も必要ありません。
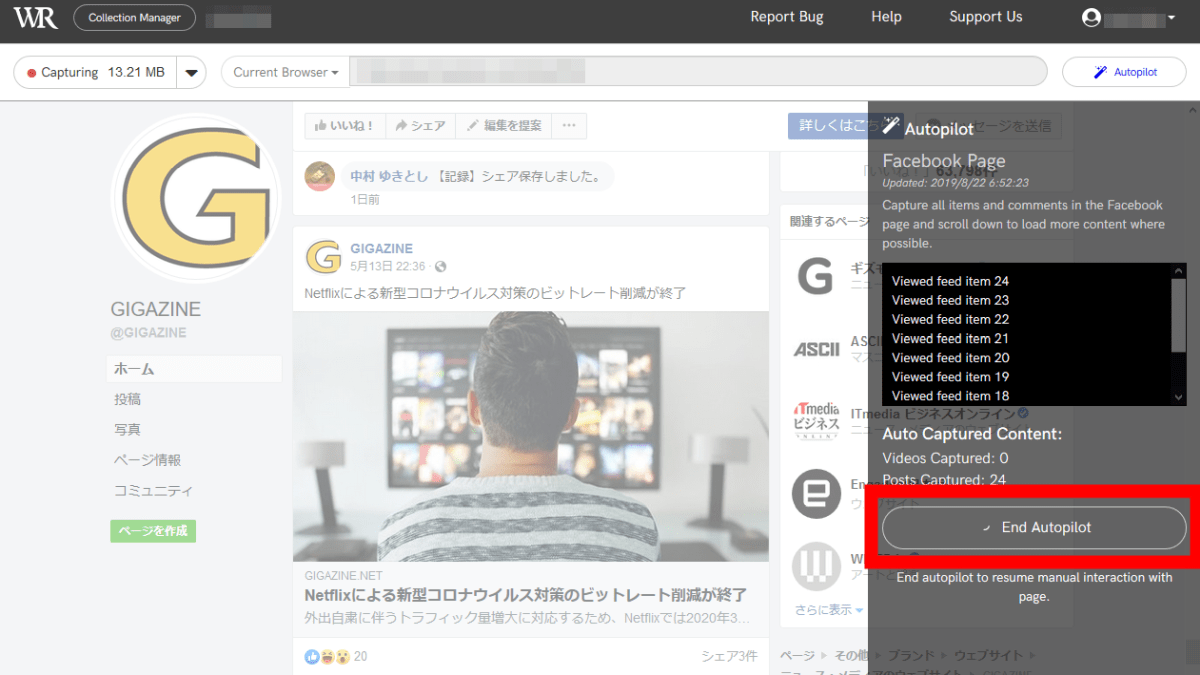
Autopilotを停止したい場合は「End Autopilot」をクリックします。
今度はYouTubeでムービーをキャプチャしようとしましたが、何も表示されませんでした。
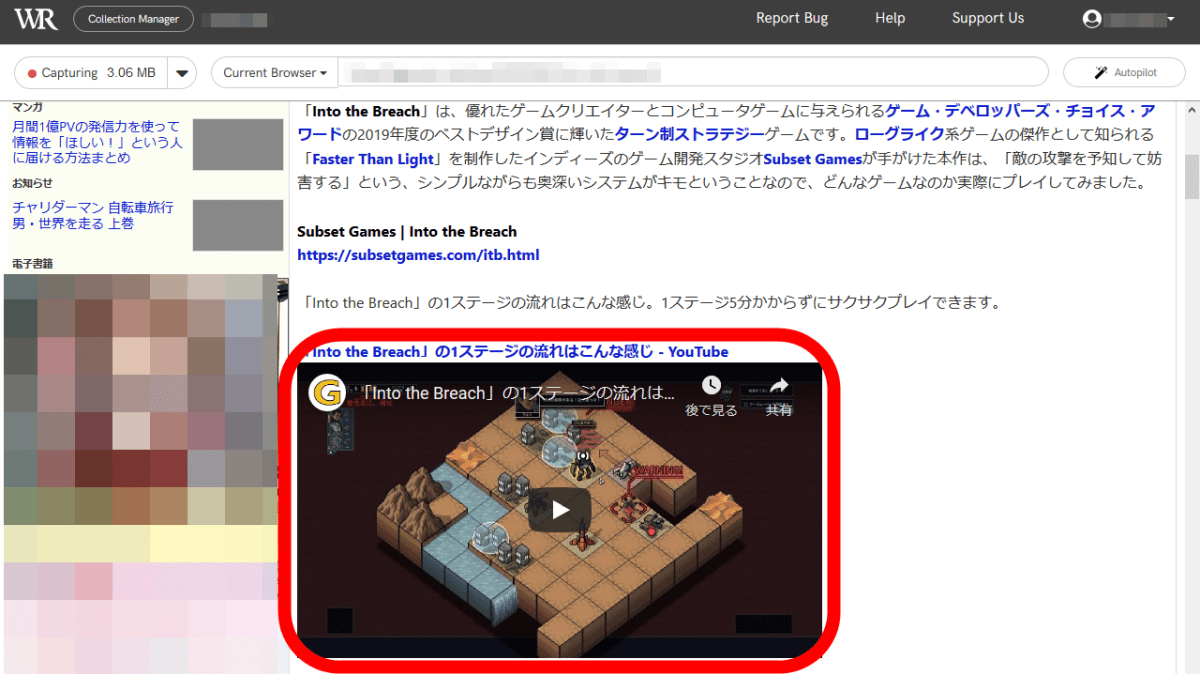
ウェブサイトに埋め込まれたYouTubeのムービーは正しく表示されていました。
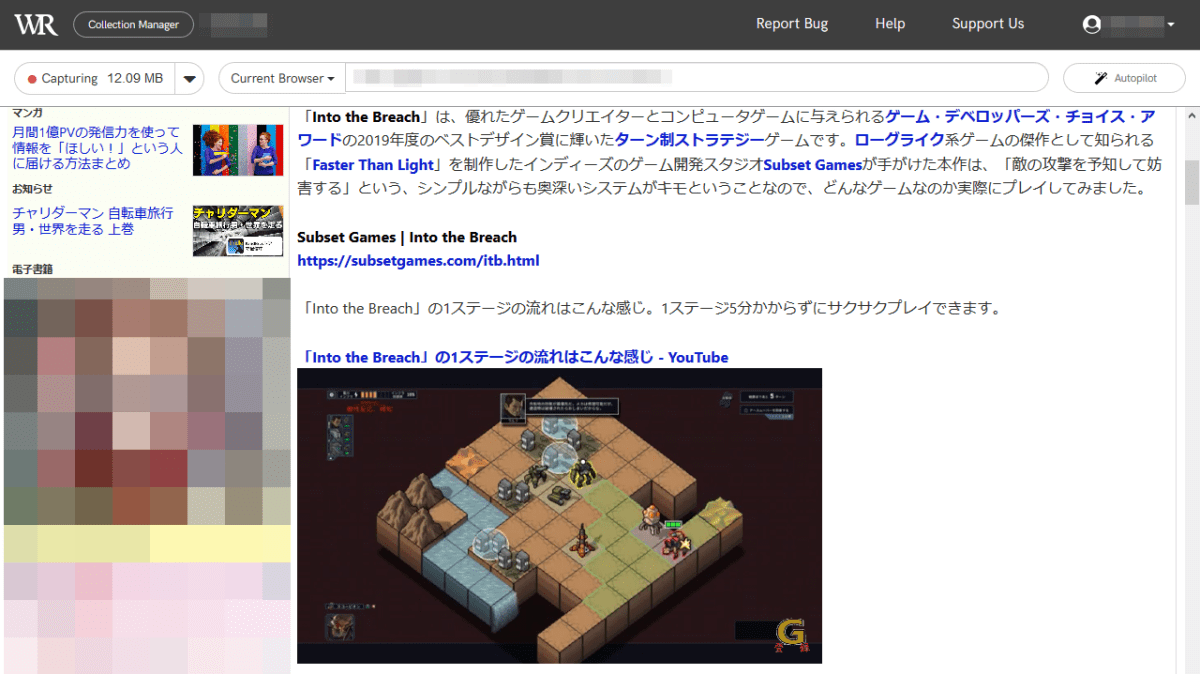
再生も行うことができましたが、キャプチャしたデータ容量が増えていないのでキャプチャできていない可能性が高そうです。
なお、Webrecorderではキャプチャ中にリモートのブラウザに切り替えることが可能。赤枠部分をクリックしてブラウザを選択すると……
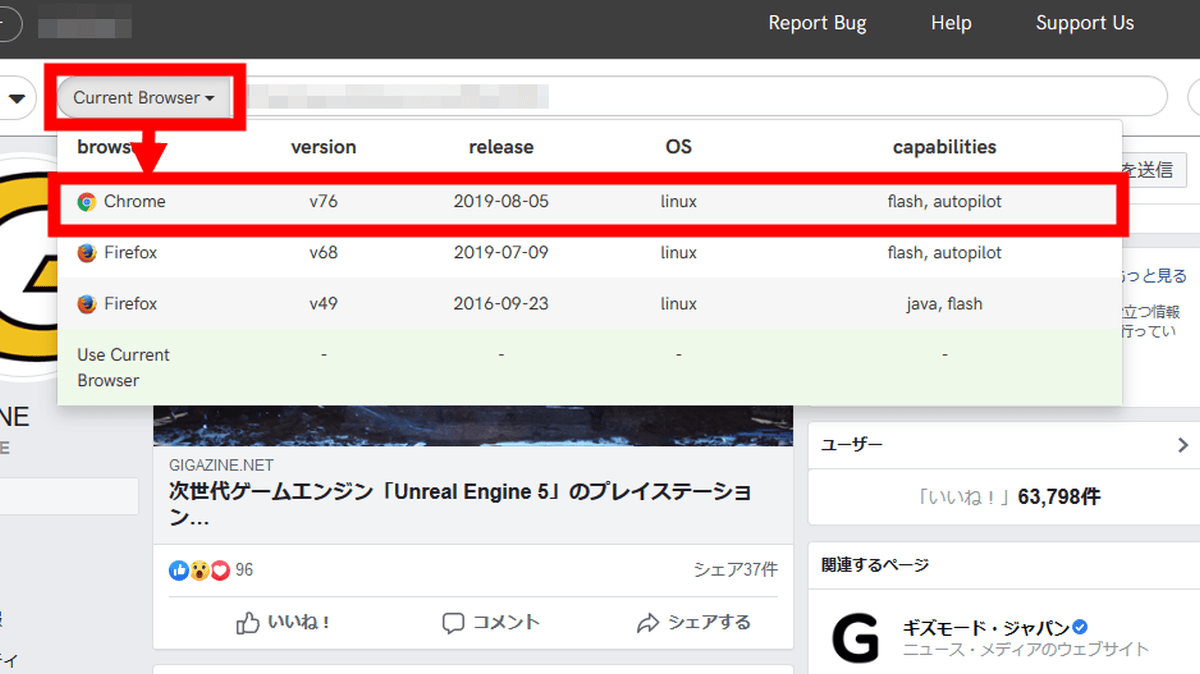
リモートのブラウザが起動し、そのブラウザ内でウェブサイトをキャプチャすることができます。動作は若干重いですが、自分が利用しているブラウザに対応していないウェブサイトをキャプチャしたい場合は便利に使えそうです。
キャプチャを終了には赤枠部分をクリック。
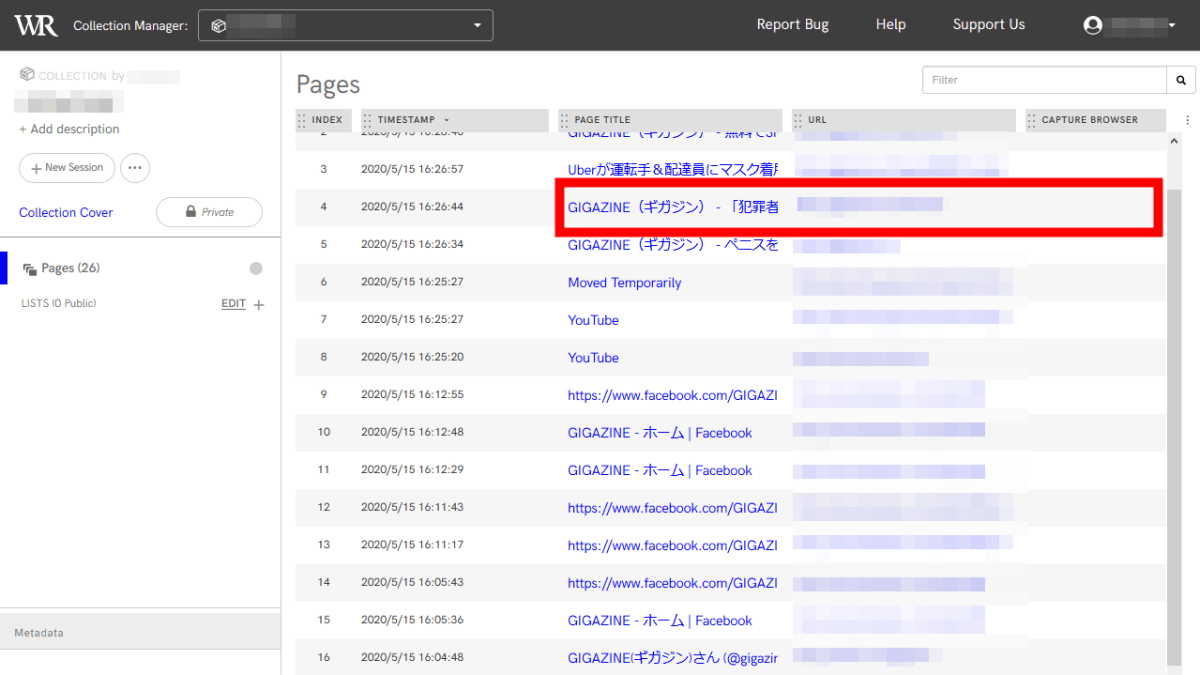
キャプチャしたウェブサイトの一覧が表示されました。一覧に表示されているURLをクリックすると……
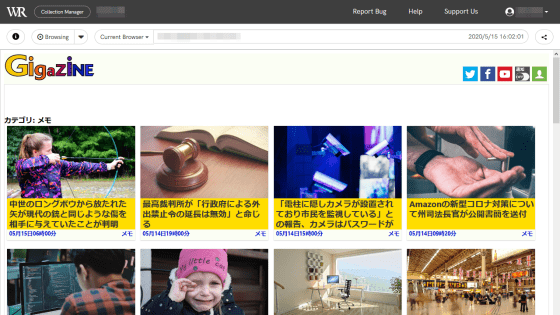
キャプチャしたウェブサイトがそのまま表示されました。
キャプチャしていないページにアクセスすると、当然ですがエラーが表示されます。
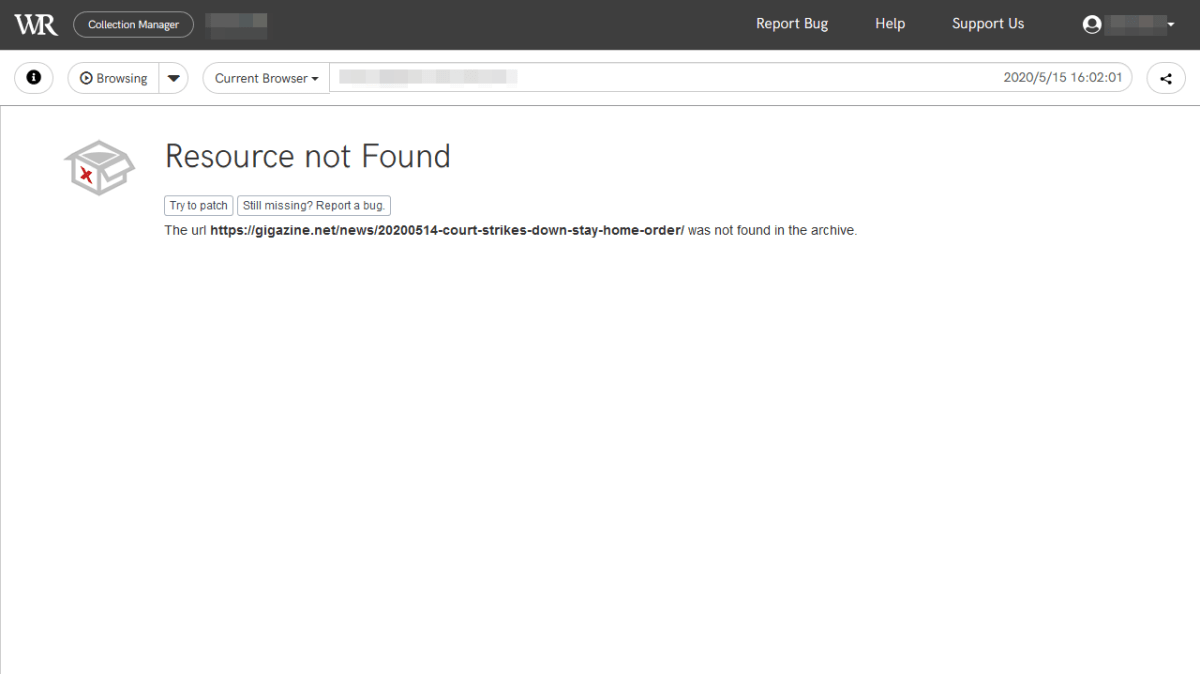
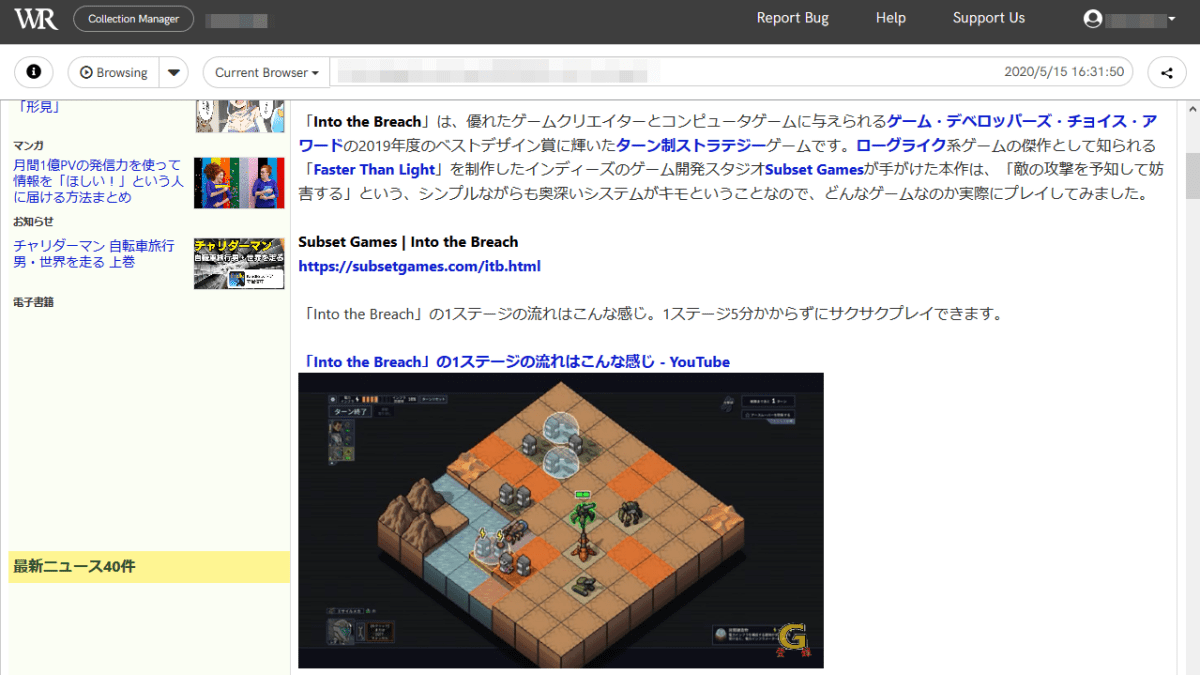
YouTubeの埋め込みムービーのキャプチャを試みたページを確認すると、YouTubeのムービーも再生することができました。しかし、キャプチャ時に再生していない部分も再生できてしまったので、単純に埋め込みムービーをYouTubeからロードしているだけのようです。
キャプチャ結果の画面で赤枠部分をクリックすると、キャプチャ結果のアップロードやダウンロード、削除を行うことができます。

試しにダウンロードを実行すると、拡張子が「warc」のファイルがダウンロードされました。
ダウンロードしたファイルは、「Webrecorder Player」をインストールすると閲覧することができます。
GitHub - webrecorder/webrecorder-player: Webrecorder Player for Desktop (OSX/Windows/Linux). (Built with Electron + Webrecorder)
https://github.com/webrecorder/webrecorder-player
・関連記事
無料でSNSなどの複数アカウントに1つのブラウザで同時ログインできる拡張機能「SessionBox」 - GIGAZINE
無料で世界各地からのサイト表示速度を測定してくれる「Fast or Slow」レビュー - GIGAZINE
無料でスマホからウェブサイトを作れるアプリ「Airsite」を使ってみた - GIGAZINE
インターネット上のあらゆる情報を記録・保存する「インターネット・アーカイブ」はどのように運営されているのか? - GIGAZINE
新型コロナウイルスの影響で「インターネット・アーカイブ」の通信量が秒間60ギガビットに到達、月間通信量は20ペタバイト以上 - GIGAZINE
・関連コンテンツ
in ソフトウェア, ネットサービス, レビュー, Posted by darkhorse_log
You can read the machine translated English article Free capture software 'Web recorder' can….