Free capture software 'Web recorder' can capture the contents viewed in the browser 'as is'
Many people have saved their
Webrecorder | Homepage
https://webrecorder.io/
Release Webrecorder Desktop 2.0.1 · webrecorder / webrecorder-desktop · GitHub
https://github.com/webrecorder/webrecorder-desktop/releases/tag/v2.0.1
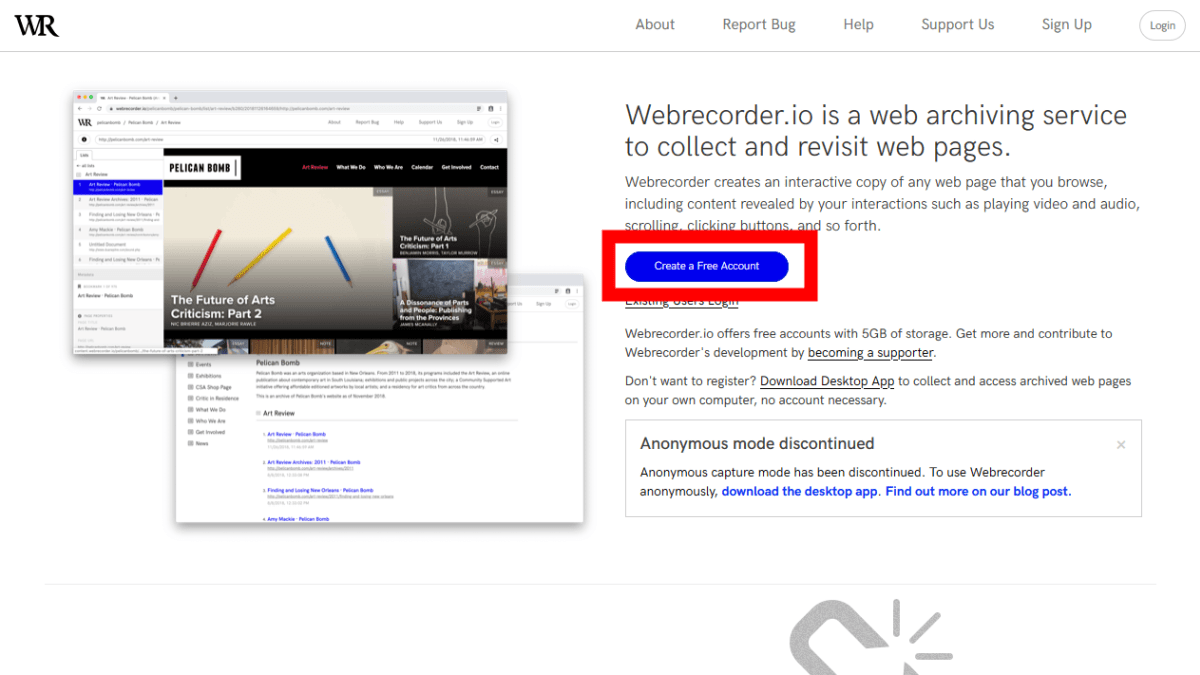
Webrecorder has cloud version and desktop version. The cloud version registers an account and saves the content of the website in the cloud, whereas the desktop version saves the content locally without an account. I can use the cloud version this time because the content can be saved locally even in the cloud version later. Visit the website of Webrecorder and click 'Create a Free Account'.
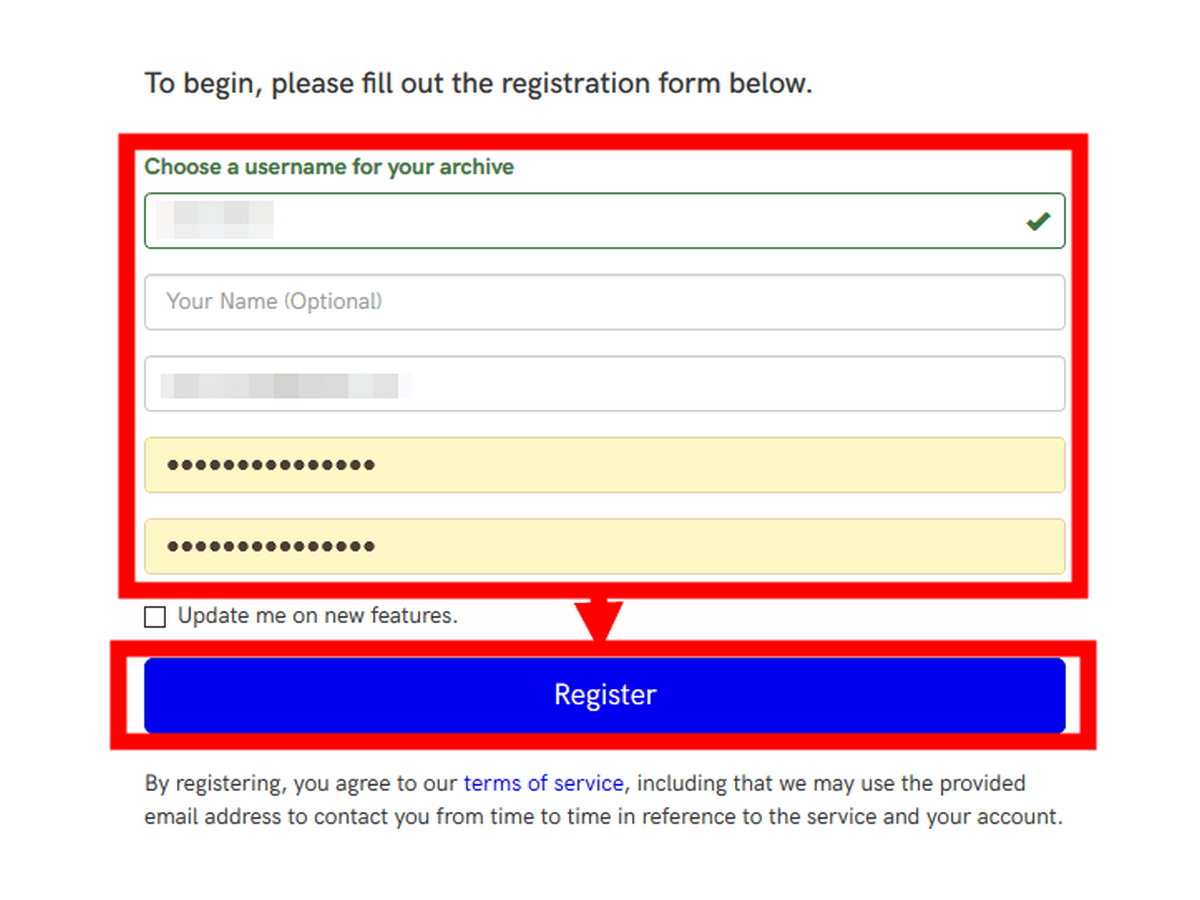
Enter your user name, email address and password and click Register.
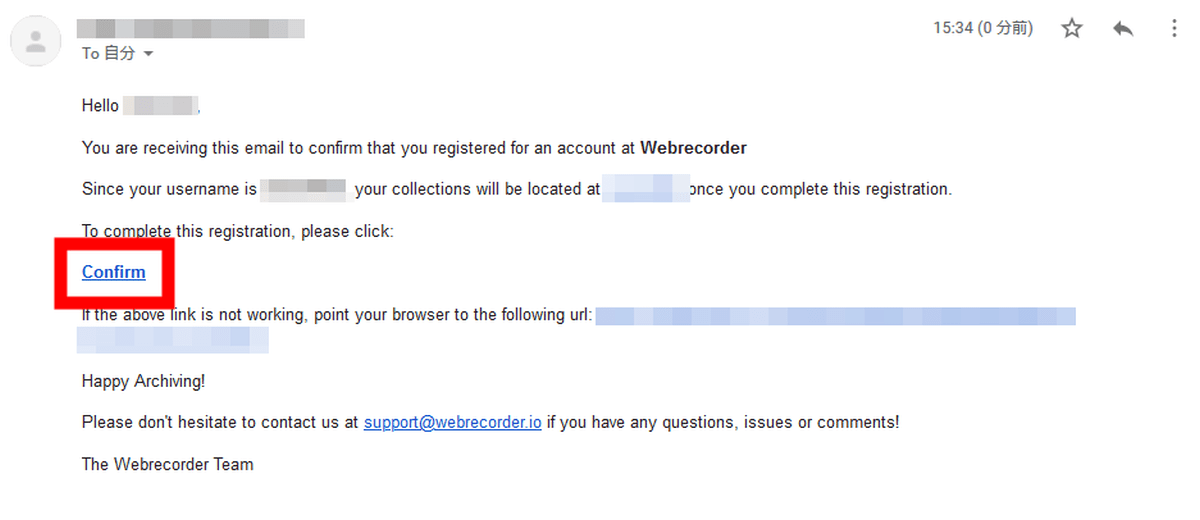
A confirmation email will be sent to the registered email address, so click 'Confirm'.
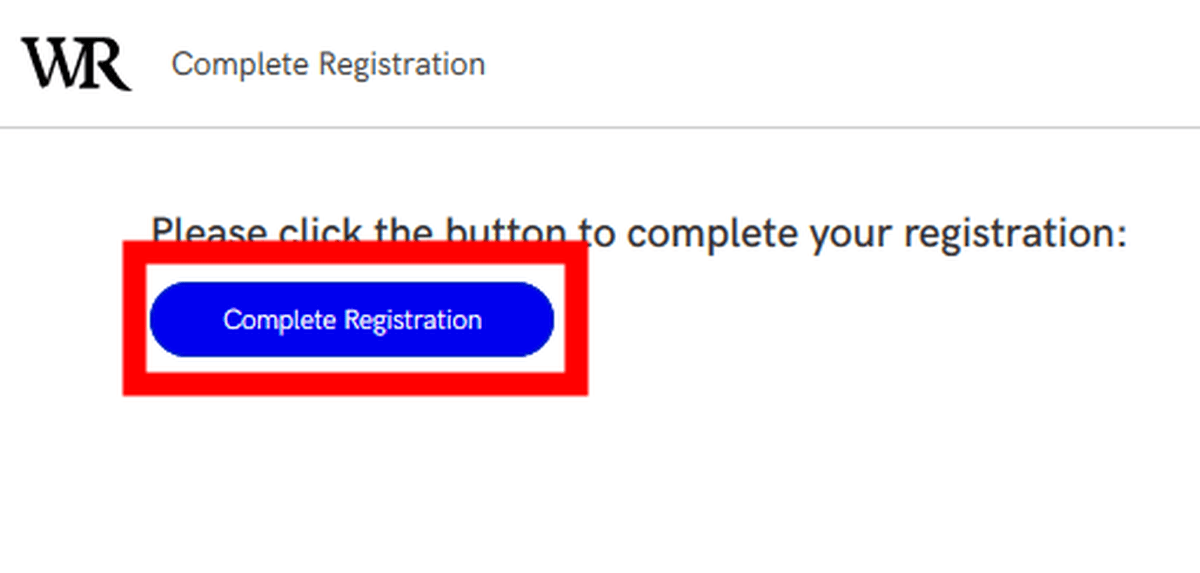
Click 'Complete Registration' to complete the registration.
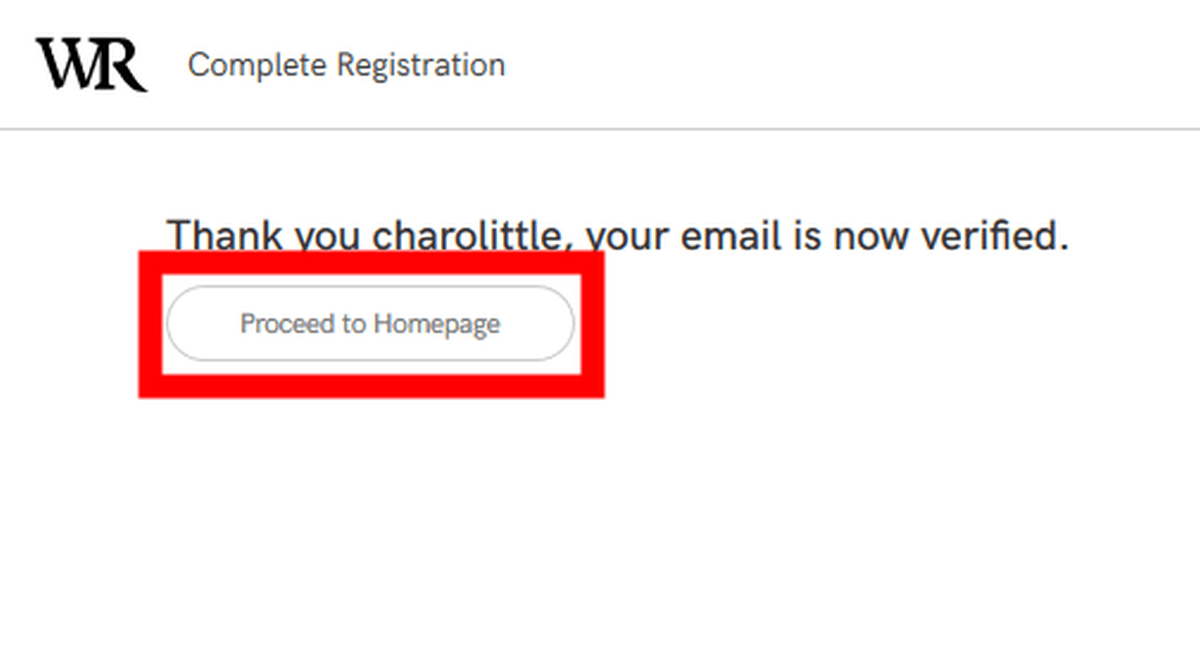
A message indicating that registration is complete is displayed. Click 'Proceed to Home page' to go to the home page.
The web recorder home page is displayed.
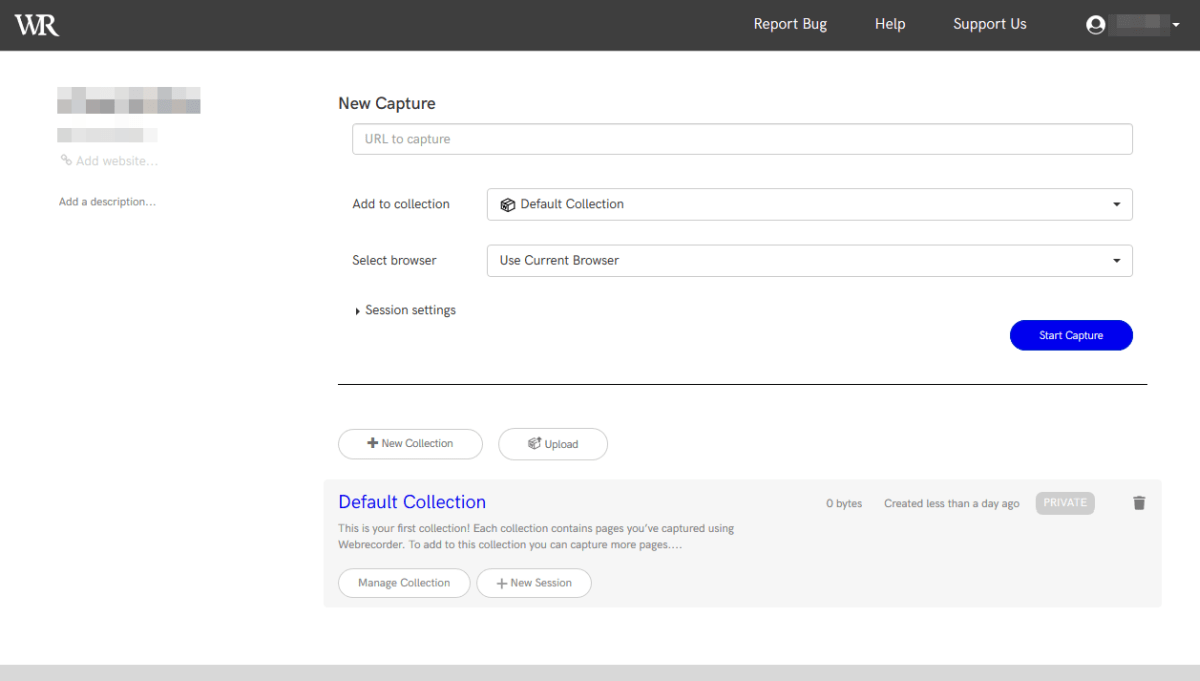
Enter the URL of the website you want to capture.

'Add to Collection' allows you to name and organize a set of capture results.
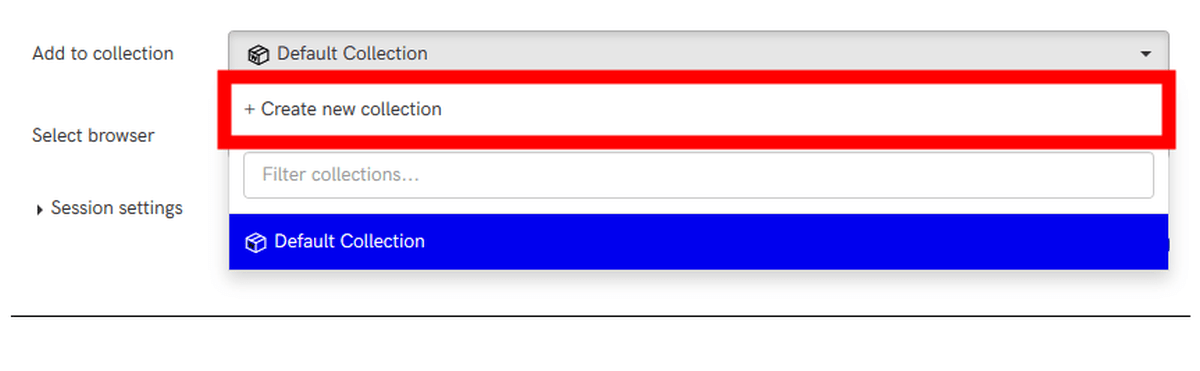
Enter a name in 'Collection Name' and click 'Create'. If you check 'Make public (visible to all)?', The captured content will be saved so that anyone can view it.
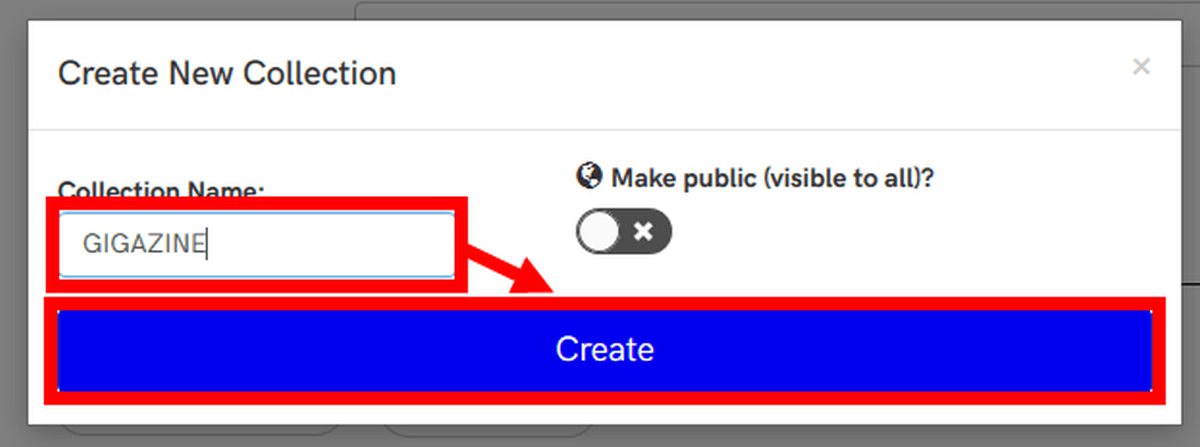
In 'Select browser', you can select the browser to use for capture. In addition to your current browser, you can also remotely use certain versions of Chrome and Firefox. Select 'Use Current Browser' because you want to capture with the browser you are using.
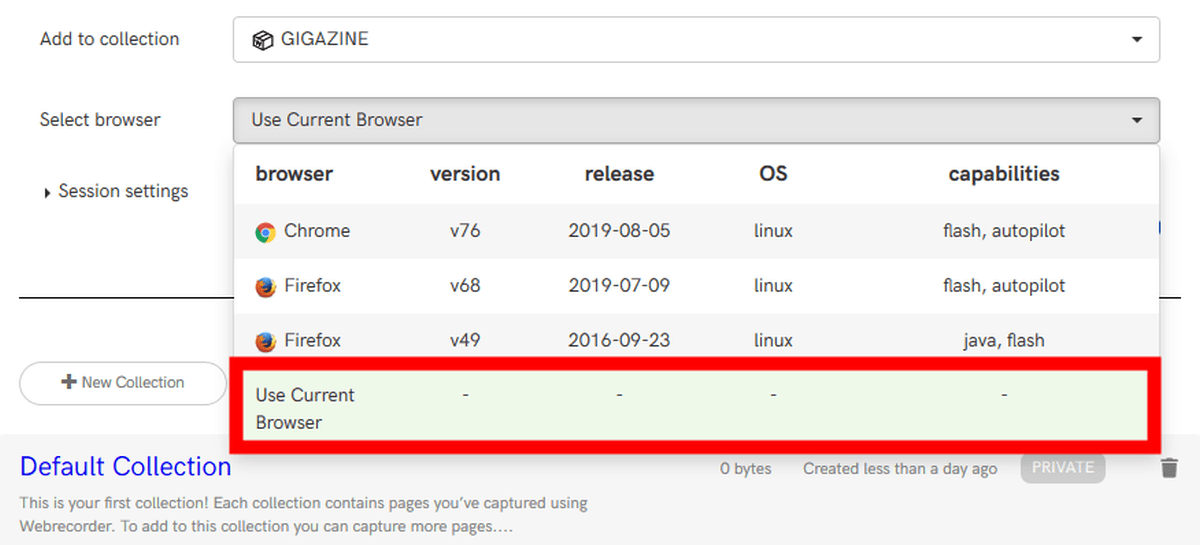
Click “Start Capture” when the settings are complete.
The website you want to capture is displayed.
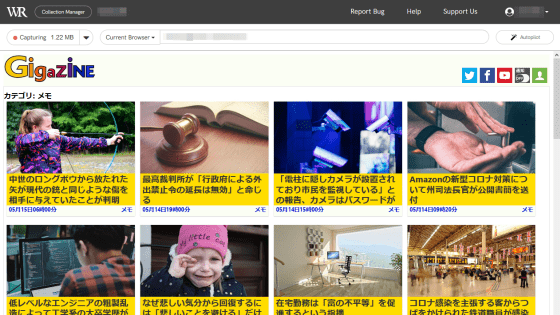
The amount of captured data is displayed in the upper left.
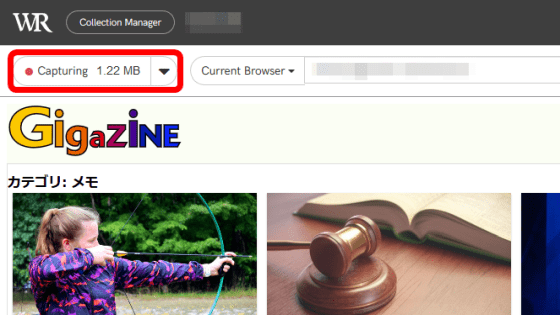
As you scroll through the screen, the new content loaded will be captured by Webrecorder, increasing the amount of data captured. In addition, in the cloud version of Webrecorder, the data capacity that can be saved in the cloud for free is up to 5 GB.
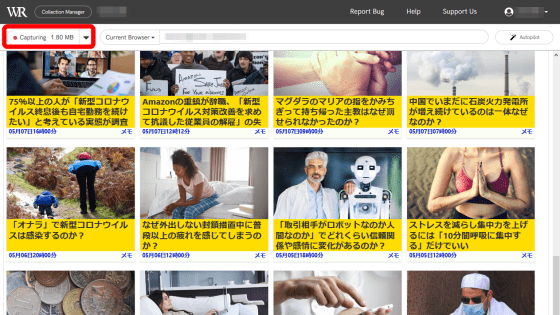
Open the page you want to capture and keep saving content.
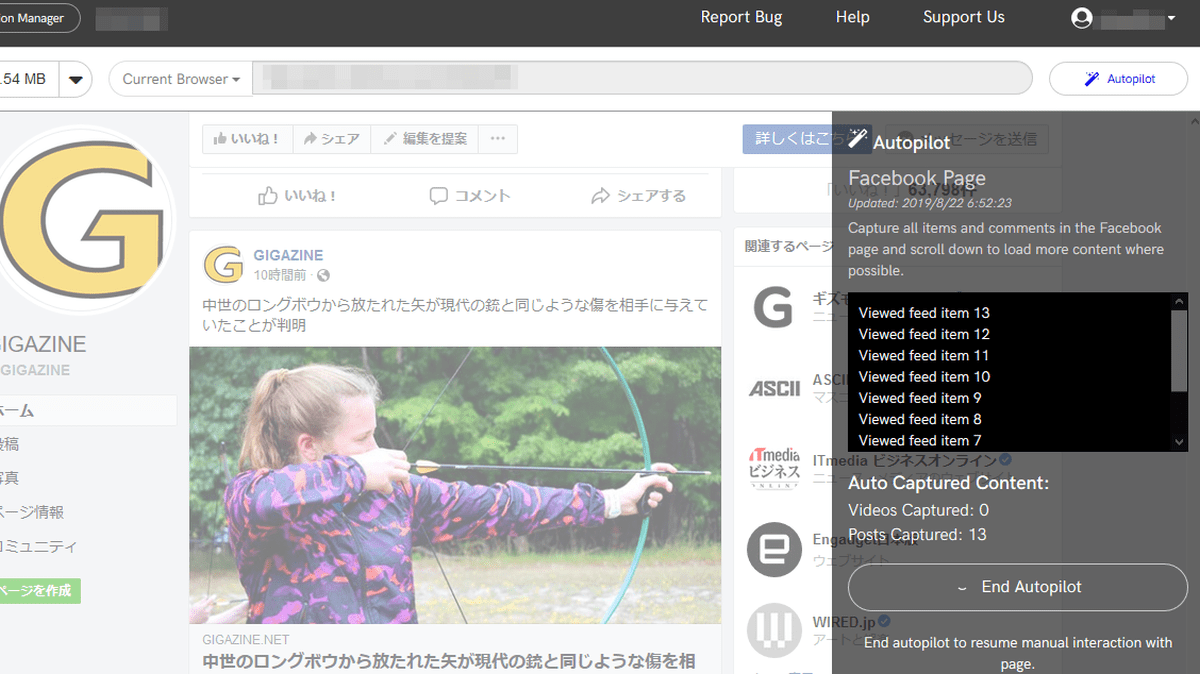
Since Webrecorder captures websites not by page but by action on the browser, it is possible to save across different websites. Let's try opening Facebook.
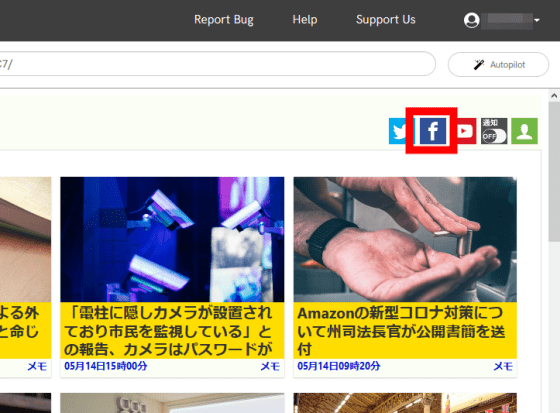
The Facebook screen was displayed in another tab. The captured content on the page of Facebook is saved together with the captured content of the page you were browsing so far, and you can browse it collectively later.

On some websites such as Twitter, Instagram, and Facebook, a button of 'Autopilot' that automatically operates the browser screen and captures appears. To use Autopilot, click the button and click 'Start Autopilot'.
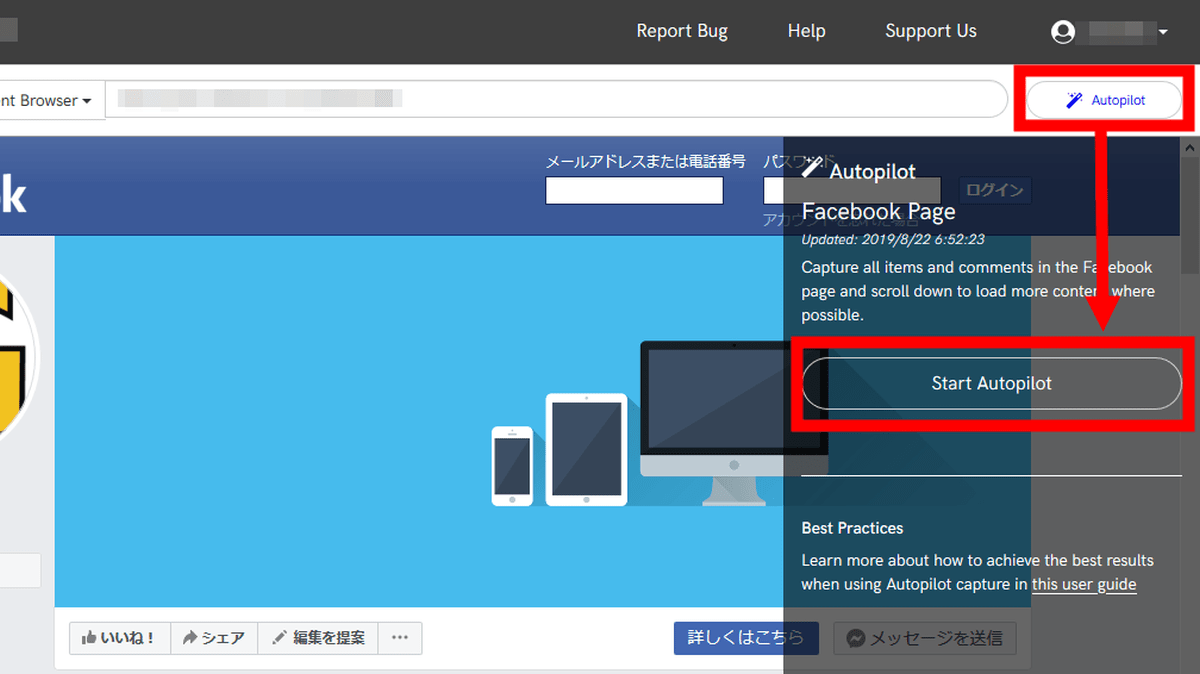
Click to automatically scroll the screen and start loading and capturing the page.
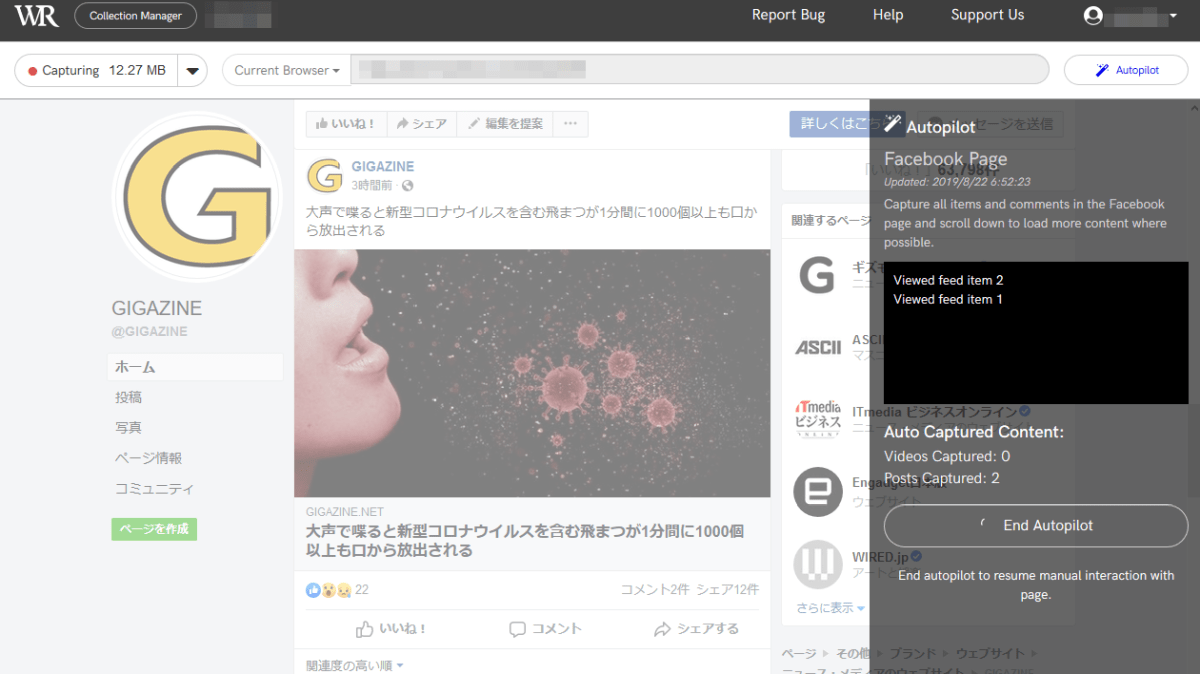
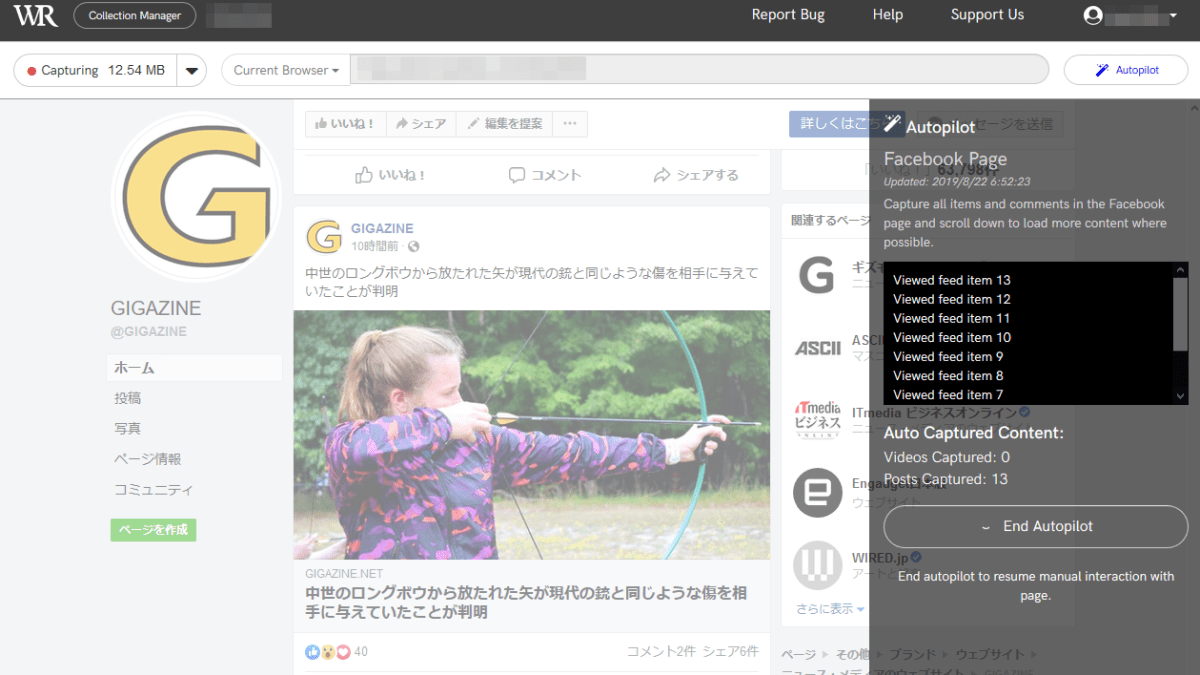
Since it is automatically captured one after another, no user operation is required.
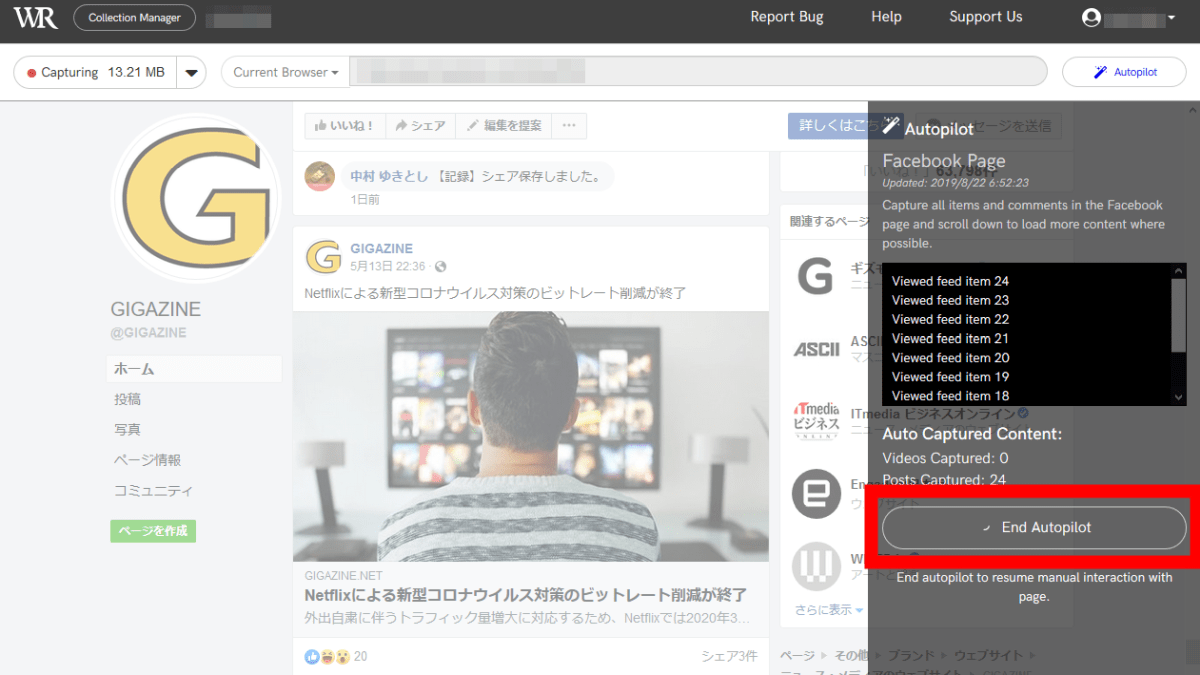
If you want to stop Autopilot, click 'End Autopilot'.
This time I tried to capture the movie on YouTube, but nothing was displayed.
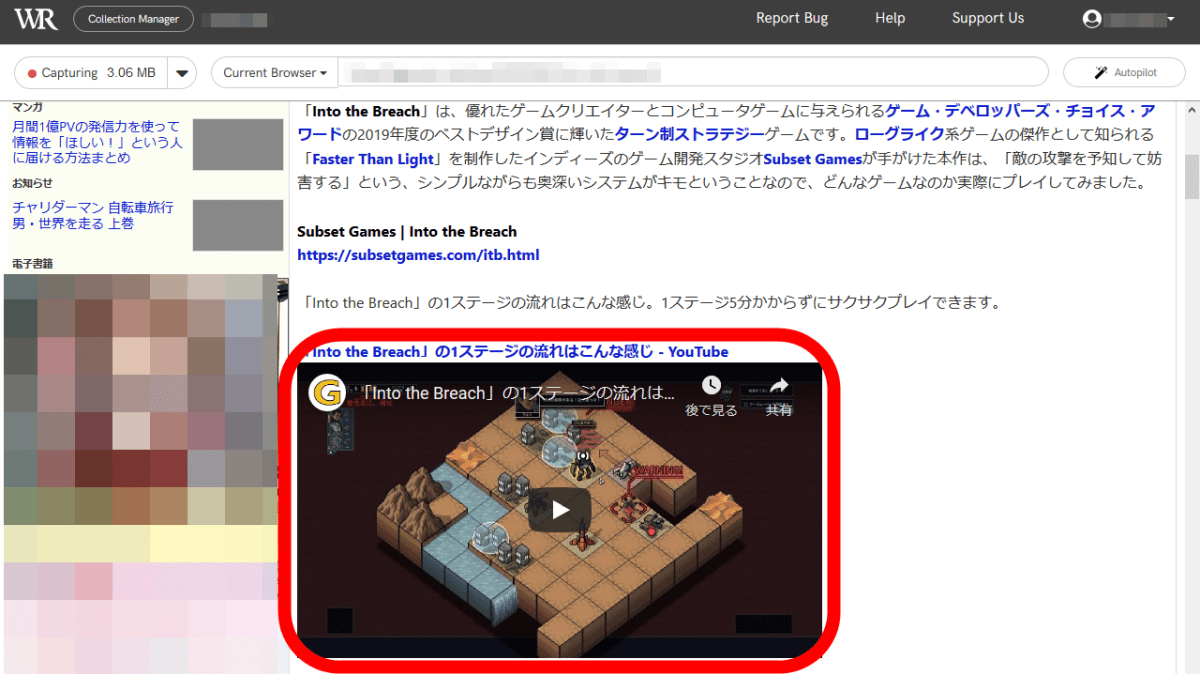
The YouTube movie embedded in the website was displayed correctly.
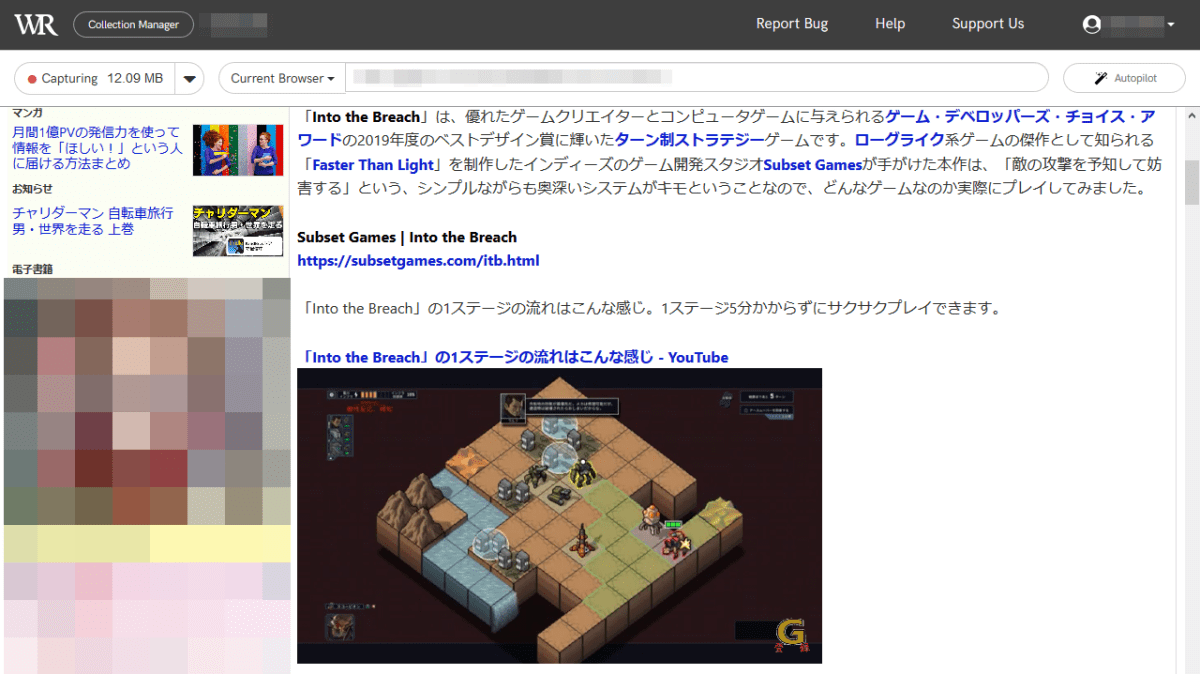
I was able to play it, but it seems likely that I could not capture because the amount of captured data has not increased.
In addition, Webrecorder can switch to a remote browser during capture. If you click on the red frame and select a browser ...
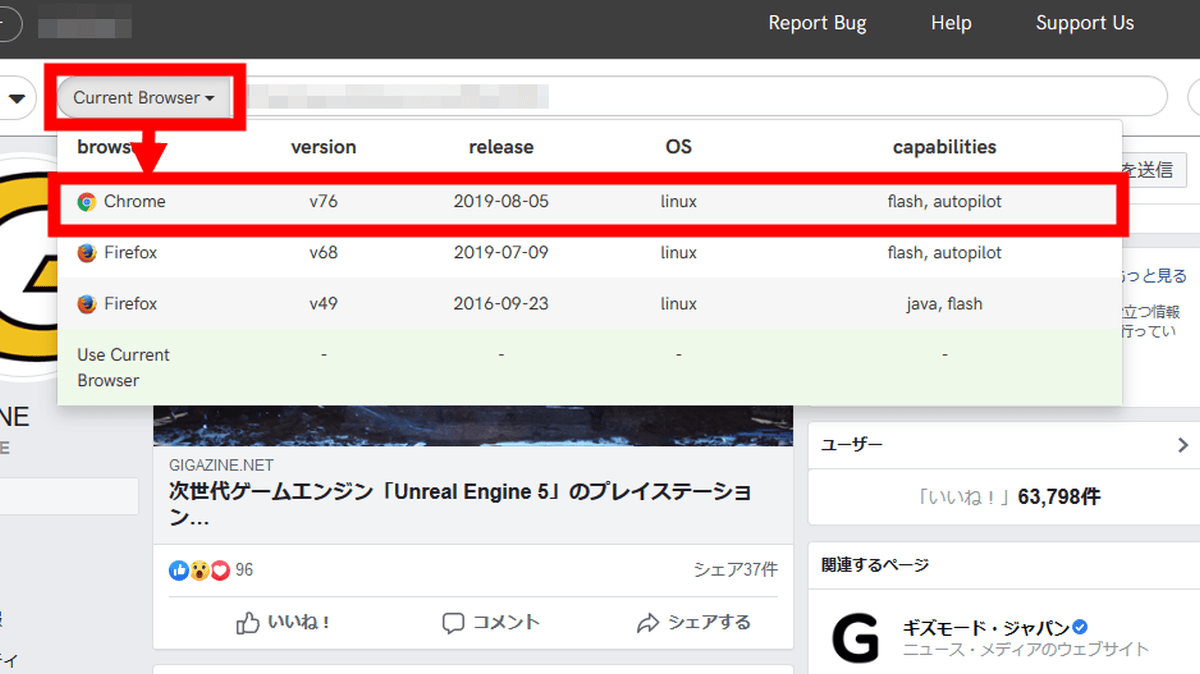
A remote browser will launch and you can capture the website within that browser. The operation is a little heavy, but it seems to be useful if you want to capture a website that does not support the browser you are using.
Click the red frame to finish the capture.
A list of websites that were captured was displayed. Click the URL displayed in the list ……
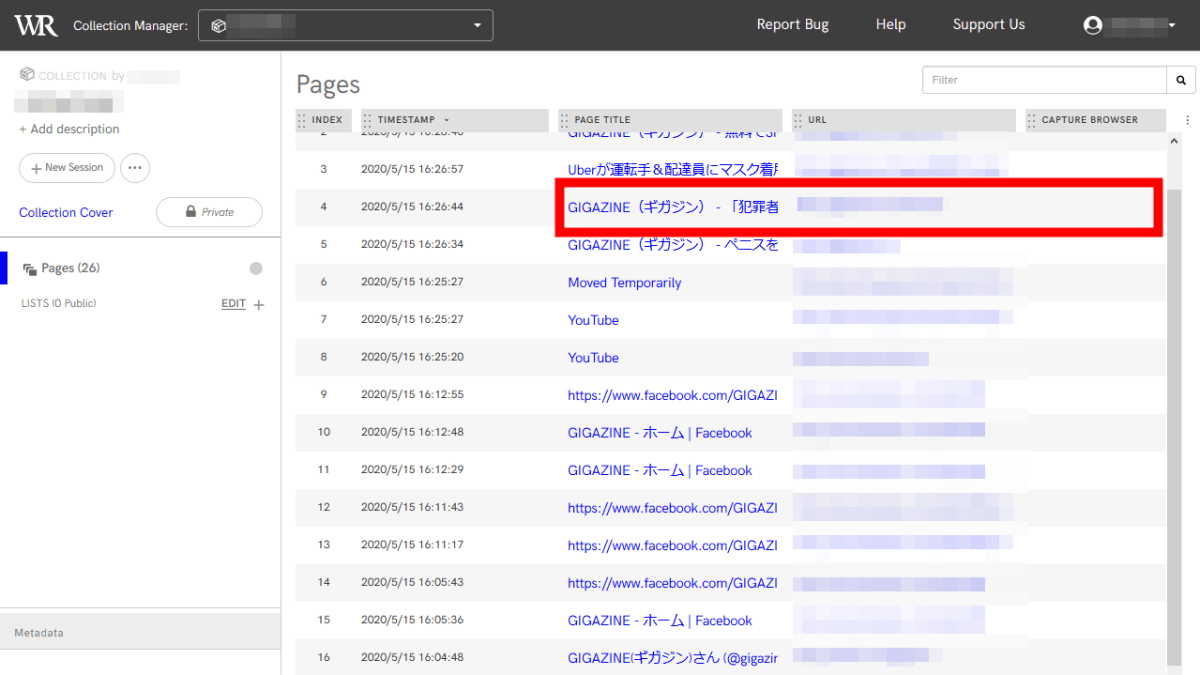
The captured website is displayed as it is.
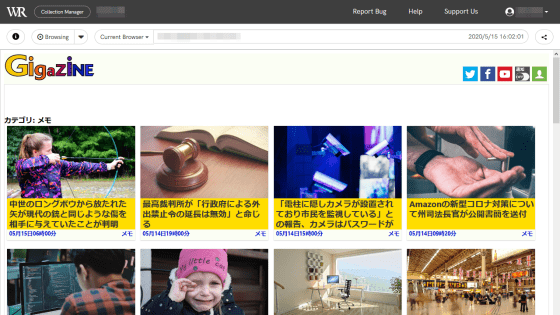
If you visit a page that you haven't captured, you'll obviously get an error.
When I checked the page where I tried to capture the YouTube embedded movie, I was able to play the YouTube movie as well. However, since I was able to play the part that was not playing at the time of capture, it seems that the embedded movie is simply loaded from YouTube.
You can upload, download, or delete the capture result by clicking the red frame on the capture result screen.

When I tried to download it, a file with the extension 'warc' was downloaded.
The downloaded file can be viewed by installing 'Webrecorder Player'.
GitHub-webrecorder / webrecorder-player: Webrecorder Player for Desktop (OSX / Windows / Linux). (Built with Electron + Webrecorder)
https://github.com/webrecorder/webrecorder-player
Related Posts:


in Software, Web Service, Review, Posted by darkhorse_log