




GitLabで「切りのいい時間」によって引き起こされた不具合と改善されるまでの6つのステップ

By Rawpixel
GitLab.comのエンジニアであるクレイグ・ミスケル氏は、顧客から報告された「gitのリポジトリからpullを行う際に発生したエラー」が、切りのいい時間にとらわれがちな人間性によるものだと判明したことについて、エラーを改善するまでの手順を6つのステップに分けて紹介しています。
6 Lessons we learned when debugging a scaling problem on GitLab.com | GitLab
https://about.gitlab.com/2019/08/27/tyranny-of-the-clock/
ミスケル氏は、GitLab.comの顧客から「Git pullのエラーが断続的に見られる」という報告を受け取りました。報告されたエラーメッセージは以下の通り。
ssh_exchange_identification: connection closed by remote host
fatal: Could not read from remote repositoryこのエラーメッセージは断続的で予測不可能なものであったため、ミスケル氏の所属するチームはエラーをオンデマンドで再現することもグラフやログで何が起こっているかを明確に示すこともできませんでした。同様にSSHクライアントの接続がなくなったという報告もありましたが、それはクライアントか仮想マシンが不安定であるか、ファイアウォールが制御できていないか、ISPの異変、またはアプリケーションの問題であると考えられ、報告されたエラーとは別問題であると考えられました。
最初の手がかりとして、ミスケル氏のチームは、報告されたエラーが1日数回発生していた顧客と連絡を取り、それを足がかりとしました。顧客から関連するパブリックIPアドレスを提供してもらい、フロントエンドのHAproxyノードでパケットキャプチャを行って、すべてのSSHトラフィックよりも小さなデータセットから問題を切り出そうとしました。幸運なことに、顧客はalternate-ssh portを使用しており、確認すべきHAProxyサーバーは2つだけでした。
制約条件下にもかかわらず、約6.5時間あたり約500MBのパケットキャプチャがあり、ミスケル氏のチームはTCP接続が確立された後、クライアントがバージョン文字列識別子を送信した短時間の接続を発見しました。その後、HAProxyはすぐに適切なTCP FINシーケンスで接続を切断しており、接続を切ったのはGitLab.com側であるということが判明しました。
◆1:Wiresharkによる調査
Wiresharkの「Conversations」は、キャプチャ内の各TCP接続の時間、パケット、およびバイトの基本的な内訳が表示され、並べ替えることが可能です。探していたパケット数の少ない接続もConversations viewで簡単に見つけることができます。この機能を使用して他のインスタンスを検索し、最初に見つかったインスタンスは異常値ではないことが確認できました。
ミスケル氏のチームは、なぜHAProxyがクライアントへの接続を切断するのかについて、まず時間とTCPポートに基づくパケットキャプチャを調査し、インシデントのうち1つのログエントリを特定しました。これは大きな発見で、そのエントリの詳細で最も興味深かったのは、SDのt_state(終了状態)属性でした
HAProxyドキュメントから:
S: aborted by the server, or the server explicitly refused it
D: the session was in the DATA phase.Dはかなり明確で、TCP接続が適切に確立された後にデータが送信されていたため、パケットキャプチャと一致していました。Sは、HAProxyがRSTまたはICMPエラーメッセージをバックエンドから受信したことを意味します。グリッチや輻輳などのネットワークの問題からアプリケーションレベルの問題まで、あらゆるものが考えられるため、どちらのケースが発生しているかの直接的な手がかりはありませんでした。BigQueryを使用してGitのバックエンドを集約すると、任意の仮想マシンに特定されるエラーではないことが明らかになりました。SDのログはミスケル氏のチームが調べていた問題固有のものではないことが判明しました。
HAProxyとGitサーバー間のトラフィックをキャプチャし、Wiresharkを使用すると、Gitサーバー上のSSHDがTCP3ウェイハンドシェイクの直後に、TCP FIN-ACKとの接続が切断されていることがわかりました。HAProxyはまだ最初のデータパケットを送信しておらず、送信された後すぐにGitサーバーのTCP RSTが応答していました。それがHAProxyがSDとの接続エラーを記録した理由で、SSHは意図的に接続を閉じていることが明らかになりました。RSTは、FIN-ACKの後にパケットを受信するSSHサーバーのアーティファクトであり、ここでは何も意味していません。
BigQueryでSDログを監視し分析していると、時間軸でかなりの量のクラスタリングが進行しており、1分ごとに最初の10秒間にピークがあり、約5〜6秒でピークに達していることが明らかになりました。
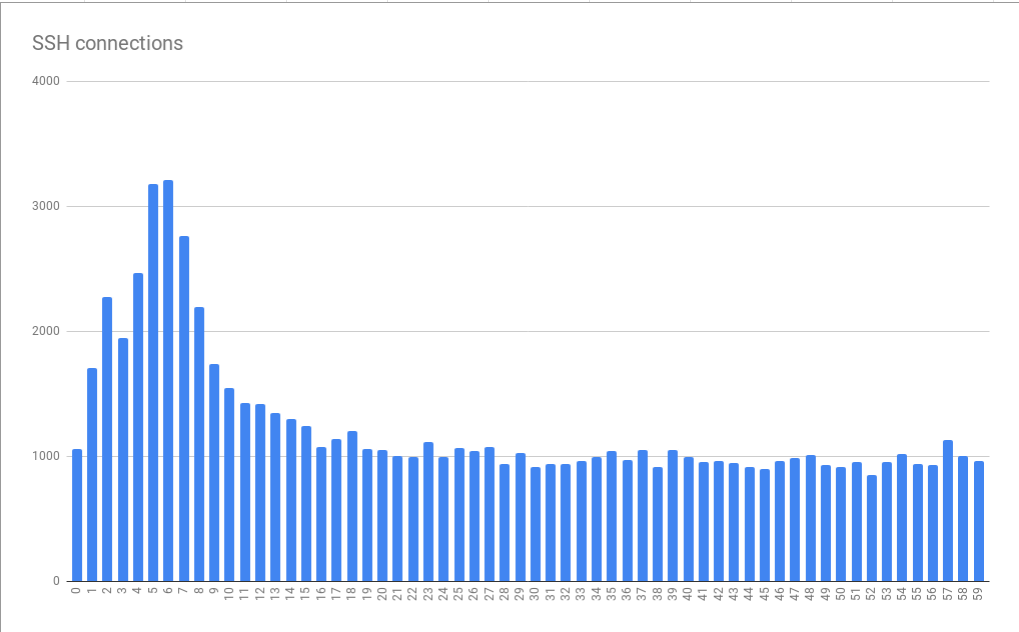
上記のグラフは数時間にわたって照合されたデータから作成されています。グラフのパターンは数分から数時間にわたって一貫しており、1日の特定の時間に悪化することが示唆されています。興味深いことに平均のスパイクはベース負荷の3倍で、スケーリングに問題があるため、仮想マシンに関して「より多くのリソース」を提供してピーク負荷に対応するだけでは、非常にコストがかかる可能性があることを意味していました。これはミスケル氏が「時計の支配」と呼ぶ体系的問題の最初の手がかりとなりました。
人間は切りのいい時間で物事を考えることを好むため、ジョブは1分または1時間の開始時など切りのいい時間で実行されます。GitLab.comからgit fetchを実行する前に準備に数秒かかる場合、接続パターンが1分に数秒増加するため、その時間帯にエラーが増加するということです。
◆2:多くの人がNTPなどを介して時刻を適切に設定している
多くの人がNTPなどを介して時刻を適切に設定していなければ、このエラーは明確には現れなかっただろうとミスケル氏は述べています。ではSSHが接続を切断した原因は何でしょうか?
ミスケル氏のチームがSSHDの資料を調べたところ、事前認証済み状態にできる接続の最大数を制御するMaxStartupsが見つかりました。最初の10秒のピークで、インターネット上で予定されたジョブか接続制限を超えていたようです。MaxStartupsには、最低水準点(接続のドロップを開始する数)、最低水準点を超える接続に対してランダムに低下する接続の割合、およびすべての新しい接続がドロップされる絶対最大値の3つの数値があります。デフォルトの値は10:30:100であり、この時点での設定は100:30:200であったため、過去に明らかに接続を増やした形跡が見つかりました。
面倒なことに、サーバー上のopensshのバージョン7.2でMaxStartupsが侵害されていることを確認する唯一の方法は、デバッグレベルのログを有効にすることでした。これは全データを流しっぱなしにすることになるため、1台のサーバーでのみ短時間オンにしました。その結果、数分以内にMaxStartupsが侵害され、接続が早期に切断されたことが明らかになりました。
OpenSSH 7.6(Ubuntu 18.04に付属しているバージョン)では、MaxStartupsのログが適切なものであることがわかりました。それを確認するには冗長なログを取得する必要がありました
◆3:デフォルトレベルでのログの記録
問題の原因がわかったところで、ミスケル氏のチームはどのように対処すべきかを検討しました。MaxStartupsを増やすことはできても費用はいくらかかるのか、メモリは少量でもダウンストリームへの悪影響はないかなどの問題があり、推測の域を出なかったので、MaxStartupsの値を150:30:300に上げて(50%増加)テストを行いました。結果、大きな改善効果があり、CPU負荷の増加など目に見えるマイナス効果はありませんでした。
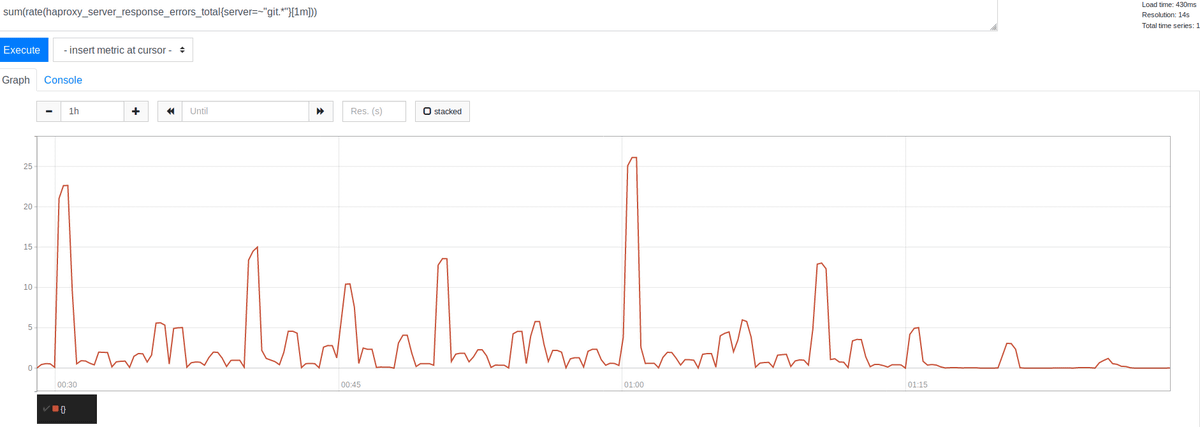
01:15以降の大幅な減少に注目すると、エラーの大部分を明らかに除去することができました。興味深いことに、これらは時間の先頭、30分ごと、15分ごと、10分ごとに、切りのいい時間にクラスタ化されています。時間の頭に最大のピークが見られ、妥当と思われる結果となりました。多くの人は、ジョブを1時間ごとに実行するようにスケジュールすることから、この結果はスケジュールされたジョブがスパイクを引き起こすという理論を裏付けする証拠であり、数値的制限によるエラーが発生していたことを示しています。
MaxStartupsの増加による明らかな悪影響はなく、SSHサーバーのCPU使用率はほぼ同じままで、著しい負荷の増加も発生しませんでした。ビジー状態でも接続の中断は引き起こされず、有望な手段であると考えられました。
ミスケル氏のチームは単にMaxStartupsを高くするだけでなく、他にも改善できることがないか模索しました。SSHサーバーの前にあるHAProxyレイヤーに焦点を当て、HAProxyのフロントエンドリスナー用に設けられた「レート制限セッション」オプションを検討しました。設定されると、フロントエンドがバックエンドに通信する1秒あたりの新しいTCP接続を制限し、TCPソケットに追加の着信接続を残します。ミリ秒ごとに測定される着信率が制限を超えると、新しい接続は遅延するというもので、TCPクライアント(この場合はSSH)はTCP接続が確立される前に遅延を確認するので、ミスケル氏は全体のレートが制限を超えて過度に高いスパイクが発生しない限り問題ないと考えました。
次に問題となったのは、使用する番号です。27個のSSHバックエンドと18個のHAproxyフロントエンド(16個のメイン、2個のalt-ssh)があり、レート制限のためにフロントエンドが相互に調整されないため複雑になります。また、新しいSSHセッションが認証を通過するまでにかかる時間を考慮する必要があります。MaxStartupsを150と仮定すると、認証フェーズに2秒かかった場合、各バックエンドに毎秒75個の新しいセッションしか送信できませんでした。この問題に関するメモには数学の派生があり、レート制限の計算に必要な4つの数があることを除いて、ここでは詳しく言及しません。4つの数とは、両方のサーバータイプのカウント、MaxStartupsの値、T、SSHセッションが認証に要する時間です。Tは重要ですが、推定しかできませんでした。今のところ2秒で到達し、フロントエンドあたりのレート制限が約112.5になり、110に切り捨てられました。
この変更では、エラー率に目に見える影響は得られず、ミスケル氏はかなり苦しみました。ログ、最終的にはHAProxyメトリックの調査に戻り、レート制限が指定した数に制限されるよう機能していること、記録的に接続が送信されていた割合が高いことを確認しましたが、測定可能な数値に十分に近づいていませんでした。HAproxyによって記録されたバックエンドを抜粋すると、奇妙な点が示されていました。1時間の初めに、バックエンド接続がすべてのSSHサーバーに均等に分散されておらず、抜粋したサンプル時間では1秒で30から121まで変化しており、負荷分散のバランスが取れていませんでした。設定を確認したところ、特定のクライアントIPアドレスが常に同じバックエンドに接続するようにbalance sourceを使用していることがわかりました。そこで最小の接続数でバックエンドに新しい着信接続を配布する、負荷分散アルゴリズムleastconnに変更を試みました。これは、SSH(Git)フリートのCPU使用率の結果です。
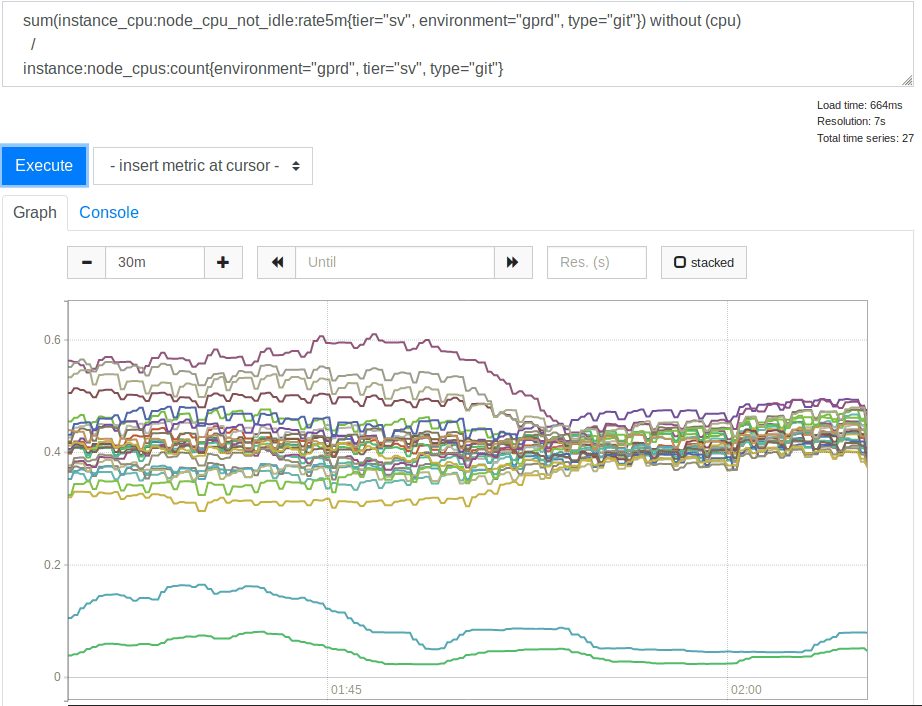
leastconnを使用するのは良いアイデアでした。使用率の低い2行はカナリアサーバーなので無視して、変更前のその他のスプレッドは2:1(30%から60%)であったため、バックエンドの一部は、ソースIPハッシュの影響で他のバックエンドよりもはるかに負荷が高い状態でした。
◆4:デフォルト設定を変更する場合は、コメントを残すか、理由に関するドキュメント/問題へのリンクを記入するべき
透明性はGitLabのコアバリューの1つであるとミスケル氏は述べています。leastconnをオンにするとエラー率を減らすことができたので、この方法を採用しようと考えました。実験の一環でレート制限を100に下げたところ、エラー率がさらに減少し、Tの初期推定が間違っていた可能性が示唆されました。Tの初期推定は小さすぎてレート制限が高くなりすぎてしまい、100/sでさえ低いと感じられたので、ミスケル氏はそれ以上落とすつもりはありませんでした。運用上の理由から、残念ながら上記2つの変更は単なる実験となり、balance sourceおよびレート制限100にロールバックする必要がありました。leastconnが不十分なため、レート制限を快適な限り低くし、MaxStartupsを増やしてみました。最初に200、次に250に増やしました。結果、エラーはほとんどなくなり、悪影響は発生しませんでした。
◆5:MaxStartupsは、デフォルトよりもはるかに高くしてもパフォーマンスへの影響はほとんどない
MaxStartupsは、必要に応じて引くことができる強力なレバーであるとミスケル氏は述べています。Tの推定、SSHセッションを確立して認証する時間について、200でMaxStartupsは十分ではなく、250で十分であることがわかっているため、方程式をリバースエンジニアリングすると、Tはおそらく2.7〜3.4秒であると計算できます。もう一度ログを確認したところ、t_stateがSDでb_read(クライアントが読み取ったバイト数)が0である場合、特定の障害が引き起こされることを発見しました。1日に約2,600万から2,800万のSSH接続が処理され。問題が最悪の場合、接続の約1.5%がドロップされたことを発見しました。
◆6:できるだけ早く実際のエラー率を測定する
問題の範囲を認識していた場合は、解決を優先した可能性がありますが、識別特性を知ることに依存していました。プラス面としては、MaxStartupsとレート制限に達した後、エラー率は0.001%、つまり1日に数千まで低下しました。優れた改善効果でしたが、それでもミスケル氏が思っていたよりもエラー率は高くなっていました。他の運用上の問題のブロックを解除した後、最小接続の変更を正式に展開することができ、エラーは完全に排除されました。
SSH認証フェーズには、おそらく最大3.4秒の時間がかかっています。GitLabはAuthorizedKeysCommandを使用して、データベースでSSHキーを直接検索することができます。これは、多数のユーザーが接続している場合の迅速な操作に重要で、そうでない場合、SSHDは非常に大きなauthorized_keysファイルを順番に読み取ってユーザーの公開キーを検索する必要があり、うまく拡張できません。内部HTTP APIを呼び出すRubyでルックアップを実装します。エンジニアリングフェローであるスタン・フー氏は、Git/SSHサーバー上のUnicornインスタンスが多くのキューを認識することを特定しました。
これは、約3秒間の事前認証段階に大きく貢献する可能性があるため、さらに調査を続ける必要があります。これらのノードでUnicorn(またはpuma)ワーカーの数を増やすことができるため、SSHで使用可能なワーカーが常に存在していますが、この方法にはリスクがあるため、適切な測定を行う必要があります。解決に向けて作業は続行されますが、コアユーザーの問題が軽減されたことにより処理速度は遅くなりました。最終的にMaxStartupsを削減する可能性もありますが、マイナスの影響がないため、ほとんど必要ありません。また、問題が発生していることを示すHAProxyログが表示された場合も警告を行う必要があり、その場合、MaxStartupsをさらに増やす必要があります。リソースに制約がある場合は、Git/SSHノードを追加する必要があります。
◆結論
複雑なシステムには複雑な相互作用があり、多くの場合、さまざまなボトルネックを制御するために使用できる複数のレバーがあります。多くの場合はトレードオフが存在するため、使用可能なツールを知ることは良いことであり、仮定と推定は危険で、結果的には認証にかかる時間が短い測定値を取得しようとしたので、T推定値はより良くなりました。
最大の教訓は、多数の人が24時間体制でジョブをスケジュールすると、GitLabのような中央サービスプロバイダーにとって非常に興味深いスケーリングの問題につながるということで、もしあなたがそのうちの1人である場合は、開始時に30秒のランダムスリープを行うことを検討するか、1時間の間にランダムな時間を選択してランダムスリープに入れ、「時計の支配」と戦うことをおすすめするとミスケル氏は述べています。
・関連記事
超一流プログラマーはどういう働き方をしているのか? - GIGAZINE
全社員がリモート勤務でも成功できたスタートアップの戦略とは? - GIGAZINE
プログラマーが知っておくべき「PC内部の通信速度」 - GIGAZINE
命に関わるコードを書く時の10個のルール - GIGAZINE
大規模な分散システムを構築する際に押さえておくべき概念 - GIGAZINE
社員全員が世界各地でリモートで働く「GitLab」はなぜ創業2年で160人まで規模を拡大できたのか? - GIGAZINE
・関連コンテンツ






in ソフトウェア, ネットサービス, Posted by darkhorse_log
You can read the machine translated English article 6 steps to improve with GitLab caused by….