ウェブサイトが表示されるまでにブラウザはどういった仕事を行っているのか?

ウェブページを表示するためのアプリケーションであるウェブブラウザは、今や多くの人が毎日のように利用する生活に欠かせないツールとなっています。そのブラウザがどのような仕組みで成り立っているのかについての解説がGitHubで公開されています。
GitHub - vasanthk/how-web-works: What happens behind the scenes when we type www.google.com in a browser?
https://github.com/vasanthk/how-web-works
この解説では例として「アドレスバーにgoogle.comと入力してからGoogleのホームページが表示されるまで」の流れが取り上げられています。
・目次
◆google.comの「g」を入力した時
◆エンターキーを押した時
◆URLを解読
◆HSTSリストを確認
◆DNS
◆ソケットを開き、TLSハンドシェイクを行う
◆HTTPプロトコル
◆HTTPサーバー
◆サーバーレスポンス
◆ブラウザの裏側
◆ブラウザの構造
◆レンダリングエンジン
◆処理の順番について
◆構文を解析する
◆DOMツリー
◆レンダーツリー
◆レンダーツリーとDOMツリーの関係性
◆CSSの解析
◆レイアウト
◆描画
◆まとめ
◆google.comの「g」を入力した時
「g」キーを押すとブラウザがオートコンプリート機能を立ち上げます。ブラウザに実装されているアルゴリズムが様々な候補を提案し、アドレスバーの下に表示します。ほとんどのアルゴリズムは履歴とブックマークを元に優先順位を決めるようになっているとのこと。これらの候補は「google.com」の入力を進めていくたびにより適切なものに絞り込まれていきます。
◆エンターキーを押した時

キーボードの「Enter」と書かれたキーを最大限に押し込むと、キーボードの電子回路が閉じられます。キーボードがメカニカル方式のものであれば電極どうしが直接くっつくことで電子回路が閉じられ、静電容量無接点方式のものであれば電極が接近するだけで回路が閉じられます。回路が閉じられるとキーボードの回路に少量の電流が流れ、キーボードの制御機構はその電流をスキャンしてどのキーが押されているのかを判別します。制御機構は電流からノイズを取り除いて数字で表されるキーコードに変換し、USBやBluetoothを介してコンピューターに送ります。例えばエンターキーを押すと「13」がコンピューターに送信されます。
・USBキーボードの場合
生成されたキーコードは「endpoint」と呼ばれるキーボード内部の記憶装置に保存されます。コンピューター側でUSBを制御しているUSBコントローラーが毎秒100回以上そのendpointを読み取ります。この読み取りに応じてキーコードがシリアル信号としてUSBコントローラーに到達し、その信号をUSBコントローラーがデコードし、そしてキーボードデバイスドライバーがOSが読めるように変換します。こうして押されたキーのキーコードがOSのハードウェア抽象化レイヤーに到達します。
・タッチスクリーンキーボードの場合

ユーザーが指をスクリーンに乗せるとそこに微量の電流が流れ、その場所の電圧が降下します。スクリーンコントローラーはその電圧降下を検知し、「click」の座標を報告する割り込みを発生させます。するとOSは現在フォーカスされているアプリケーションの当該位置にあるGUI要素にクリックイベントを通知します。つまり今回は仮想キーボードのボタンにクリックイベントが通知され、そして仮想キーボードが「key pressed」というメッセージをOSに送る割り込みを発生させ、その割り込みを受けてOSがブラウザにキーボードイベントを通知するようになっています。
◆URLを解読
URLにはドメインのほかにプロトコルとリソースについての情報が含まれています。例えば「http://google.com/」であれば「http」が「Hyper Text Transfer Protocol」というプロトコルを利用するという意味であり、末尾の「/」はインデックスページを表示するという意味になります。正当なプロトコルやドメイン名が入力されていなかった場合、ブラウザはデフォルトの検索エンジンに入力されたテキストを送信します。
◆HSTSリストを確認
ブラウザには「preloaded HSTS (HTTP Strict Transport Security)」というリストがハードコードされており、アクセスしようとしているドメインがこのリストに登録されていれば必ずHTTPSで接続を行うようになっています。このリストを使用せずともHTTPS通信を強制することは可能ですが、リストを使用しなかった場合は初回の接続がHTTPで行われることになるため、ダウングレード攻撃などのリスクを背負うことになります。このリストはGoogleが管理していますが、Google ChromeのほかにもFirefoxやSafari、Internet Explorer、Edgeなど主要なブラウザで利用されています。リストへの登録は以下のサイトから誰でも行うことができます。
HSTS Preload List Submission
https://hstspreload.org/
◆DNS
コンピューター同士がインターネットを介して通信する場合には、接続相手のIPアドレスを知っておく必要があります。入力されたドメイン名を元に目的のIPアドレスを知るためのツールがDNSです。このフェーズは以下の順に進んでいきます。
・ブラウザキャッシュ
最初にブラウザは自身のキャッシュを確認し、以前接続した時の情報が残っていればそれを利用します。OSはブラウザにキャッシュの有効期限を表すTTL
という数値を伝えないため、ブラウザキャッシュは元のTTLにかかわらず20分から30分ほど残ります。
・OSキャッシュ
ブラウザキャッシュが残っていなければブラウザはシステムコールを呼び出し、OSにDNSの検索を依頼します。例えばWindowsであれば「gethostbyname」というシステムコールが呼び出されます。OS自体もDNSのキャッシュを保持しているため、ここでキャッシュが残っていればその値がブラウザに伝えられます。
・ルーターキャッシュ
OSキャッシュにも残っていなければ次はルーターにDNSリクエストが送信されます。一般的には、ルーターも独自のキャッシュを持っています。
・ISP DNSキャッシュ
次はISPのDNSサーバーにリクエストを送ります。このサーバーもキャッシュを持っています。
・再帰探索
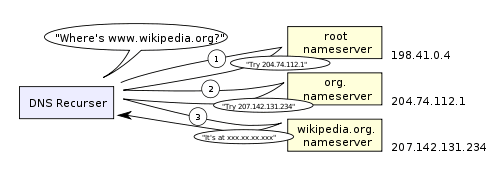
ISPのDNSサーバーは、送られてきたリクエストに対応するキャッシュがなければ再帰探索を開始します。再帰探索とはルートネームサーバー、「.com」のトップレベルネームサーバー、Googleのネームサーバーと順にDNS情報をリクエストしていく方法のことです。なお、通常は「.com」のネームサーバー情報をキャッシュするためルートネームサーバーへの問い合わせは不要です。
下図は「www.wikipedia.org」を例に再帰探索の様子を表したもの。まずルートネームサーバーに「org」のネームサーバー情報を問い合わせ、その返答を元に次は「org」のネームサーバーに「wikipedia.org」のネームサーバー情報を問い合わせ、そして最後に「wikipedia.org」のネームサーバーに「www.wikipedia.org」の情報を問い合わせています。
◆ソケットを開き、TLSハンドシェイクを行う
接続先サーバーのIPアドレスが判明したら、次はポート番号の指定を確認します。ポート番号の指定がない場合、HTTPは80番、HTTPSは443番ポートが利用されます。そしてシステムライブラリのsocket関数を呼び出してTCPソケットストリームを要求します。そしてこの接続はいきなりデータを送信し始めるのではなく、最初に暗号化方式や共通鍵を定めるためのハンドシェイクという処理を行います。
1. クライアントコンピューターはTLSのバージョン情報、利用できる暗号化アルゴリズムと圧縮方法のリストとともにClientHelloと呼ばれるメッセージをサーバーに送信します。
2. サーバーはTLSのバージョン情報、利用する暗号化アルゴリズムと圧縮方法、認証局によって署名されたサーバーの公開証明書とともにServerHelloと呼ばれるメッセージを返信します。証明書には公開鍵がついており、共通鍵を生成するまでの間、クライアントはその公開鍵を利用して残りのハンドシェイクを暗号化します。
3. クライアントはサーバーの証明書を検証し、検証に成功すれば擬似ランダムな文字列を生成してサーバーの公開鍵で暗号化し、サーバーへ送信します。
4. サーバーは送られてきた文字列を復号します。こうしてクライアントとサーバーで共通の文字列が得られたわけですが、サーバー・クライアントともにこの文字列を元に共通鍵を生成します。
5. クライアントがこれまでの通信をハッシュ化し、共通鍵で暗号化してFinishedメッセージとしてサーバーに送信します。
6. サーバー側でも同様に通信をハッシュ化し、クライアントから送られてきたハッシュと一致することを確認します。一致すればFinishedメッセージをクライアントに送り返します。
これでハンドシェイクは完了し、これ以降は共通鍵で暗号化されたアプリケーションデータを送信していきます。
◆HTTPプロトコル
HTTPリクエストメッセージは以下のような文字列から成り立っています。
GET http://www.google.com/ HTTP/1.1 Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...] User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip, deflate Connection: Keep-Alive Host: google.com Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]
リクエストにはいくつかの種類がありますが、そのうち「GET」というメソッドを利用したリクエストであることが1行目に明記され、続いてリクエストするURLである「http://www.google.com/」が表記されています。2行目、4行目の「Accept」「Accept-Encoding」ヘッダーではレスポンスとして受け入れ可能な形式が表され、3行目の「User-Agent」ヘッダーにブラウザの識別子が記載されています。5行目の「Connection: Keep-Alive」はTCPコネクションを次のリクエストのために維持してほしいという意思を表しており、6行目ではCookieが送信されています。最後の行はヘッダーが終わったことを意味する空行が入ります。
サーバーはリクエストに答えてレスポンスを返します。レスポンスには応答コードが含まれており、例えばリクエストが成功した際には200 OKという応答コードが送信されます。レスポンスは応答コード、応答ヘッダーと続いて空行が挿入され、その空行の後ろにHTMLコンテンツ本体が搭載されます。
ブラウザは受け取ったHTMLを解析し、画像やCSSファイルなどそのページで参照される全てのリソースに対して同様のプロセスを繰り返します。別のドメインへの参照が含まれていた場合はDNSの項目から再び同じ手順を行います。
◆HTTPサーバー
HTTPD(HTTP Daemon)サーバーアプリケーションは、サーバーサイドでリクエストおよびレスポンスを取り扱うためのツールです。LinuxではApacheやnginx、WindowsであればIISが有名です。
HTTPDがリクエストを受け取ると、そのリクエストから「メソッド」「ドメイン名」「リクエストパス」を抽出し、ドメイン名に対応したバーチャルホストが存在するかを確認します。ブラウザのアドレスバーにURLを入力した場合はメソッドが「GET」になり、そして今回の場合ドメイン名はgoogle.comでリクエストパスは「/」となります。
google.comというホストでGETリクエストを処理できることを確認したら、続いてサーバーはその処理を行う権限があるかを確認します。そして今回のリクエストパス「/」に対応するインデックスファイルを取得します。そして必要に応じてASP.NETやPHP、Rubyといったリクエストハンドラを利用してインデックスファイルをHTMLに変換し、クライアントに送り返します。
◆サーバーレスポンス
サーバーレスポンスは以下のような形式になっています。
HTTP/1.1 200 OK Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Sat, 01 Jan 2000 00:00:00 GMT P3P: CP="DSP LAW" Pragma: no-cache Content-Encoding: gzip Content-Type: text/html; charset=utf-8 X-Cnection: close Transfer-Encoding: chunked Date: Fri, 12 Feb 2010 09:05:55 GMT 2b3 ��������T�n�@����[...]
レスポンスの空行の下は文字化けしてしまっていますが、これは7行目にあるようにgzipで圧縮されているためです。ブラウザがデータを展開すると「<!DOCTYPE html[...]」というHTML文章になります。そして8行目で「Content-Type」が「text/html」だと宣言しておくことで、ブラウザがこのファイルをダウンロードするのではなくhtmlとして解釈し、ページを表示してくれます。
◆ブラウザの裏側
ブラウザはHTMLやCSS、JavaScriptを読み込むとその構文を解釈し、レンダリング処理を行っていきます。レンダリング処理は「DOMツリーを構築」→「レンダーツリーを構築」→「レンダーツリーをレイアウト」→「レンダーツリーを描画」という順番で行われます。
◆ブラウザの構造
ブラウザは下図のように、いくつかのパーツに分解できます。

1. ユーザーインターフェース(UI)
アドレスバーや戻る・進むボタン、ブックマークメニューなどを担当します。
2. ブラウザエンジン
UIとレンダリングエンジンのやりとりを仲介します。
3. レンダリングエンジン
HTMLやCSSを解釈し、コンテンツを画面に表示するためのエンジンです。
4. ネットワーク
HTTPリクエストのようなネットワーク部分を担当します。プラットフォームごとに実装が異なっているとのこと。
5. UIバックエンド
ドロップダウンリストやウィンドウのような基礎的なパーツを描画する部分で、ネットワークと同様にプラットフォーム間の差異を吸収しており、異なるプラットフォームでも汎用的に利用できるインターフェースを提供しているとのこと。
6. JavaScriptエンジン
JavaScriptの構文を解釈し、実行するエンジンです。
7. データストレージ
cookieのようなローカルデータの保存を担当しています。
◆レンダリングエンジン
レンダリングエンジンは、HTMLやXML、画像ファイルなどのコンテンツとCSSやXSLなどのフォーマット情報を受け取り、フォーマットされたコンテンツを画面に表示するソフトウェアです。ChromeやOperaではBlink、SafariはBlinkの元となったWebkit、FirefoxではGeckoというレンダリングエンジンが利用されています。
◆処理の順番について
レンダリングエンジンはドキュメントの内容を通常8KBずつネットワーク層から読み込みます。読み込んだHTMLドキュメントを解析してトークン化を行い、DOMノードに変換し、「DOMツリー」と呼ばれるツリーに配置します。
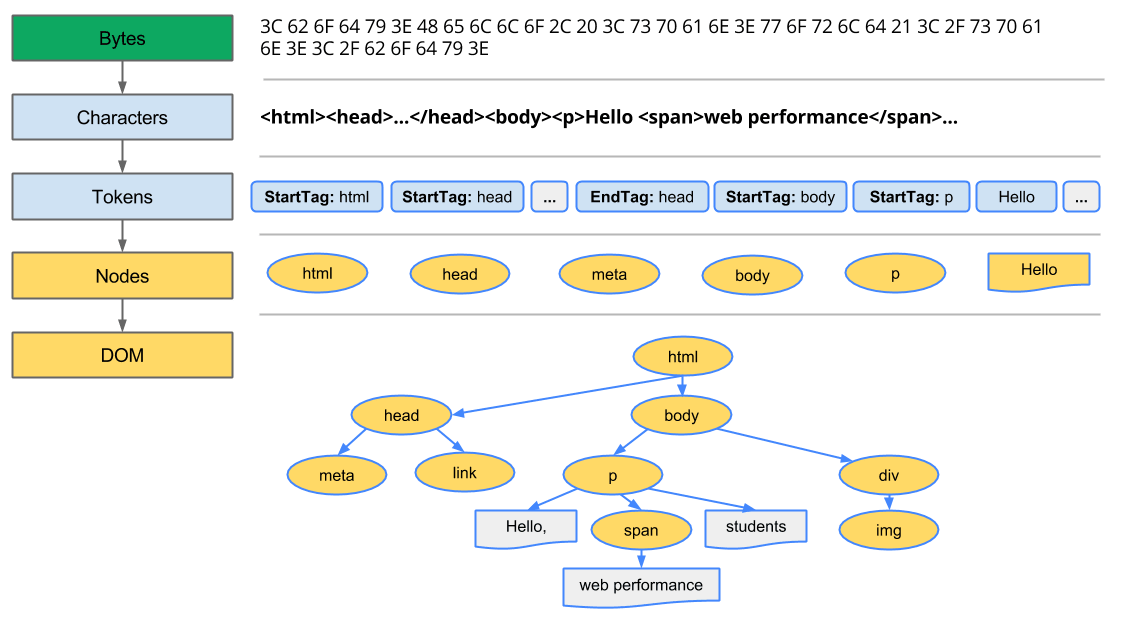
また、レンダリングエンジンは外部のCSSファイルやstyle要素を読み込み、コンテンツツリーの情報と併せて「レンダーツリー」と呼ばれるまた別のツリーを構築します。レンダーツリーではそれぞれの要素は色や寸法などの情報をもった長方形として保存されています。
レンダーツリーが構築されると続いてレイアウトを行い、それぞれのノードが表示されるべき画面上の位置を計算します。
そして最後にUIバックエンド層を用いてレンダーツリーの内容を描画します。少しでも早くページを表示するために、全ての手順は同時進行していきます。この一連の流れを図にすると以下のようになります。
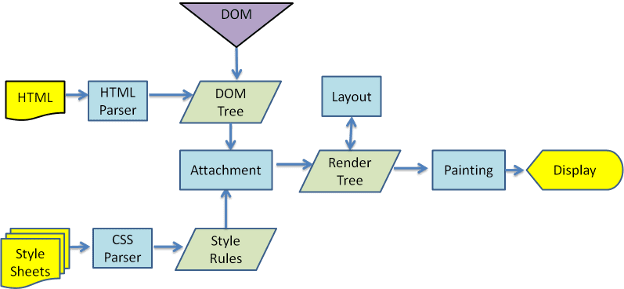
◆構文を解析する
ドキュメントをより扱いやすい形式の構造体に変換することをパースと呼びます。HTML文章の文法は文脈自由文法と呼ばれるものの1つで、決定論的な構文ルールが用いられており曖昧なところがありません。パースは字句解析と構文解析の2つのフェーズでとらえることができ、字句解析は入力を有効な構成要素のトークンに分割するプロセスで、構文解析は言語の構文ルールにあてはめるプロセスです。
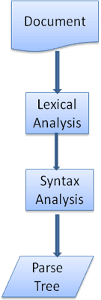
パースを行う際、レキサーがドキュメントの字句解析を行い、ドキュメントをトークンに変換していきます。HTMLトークンは開始タグや終了タグ、属性名や属性の値などで成り立っています。パーサーはレキサーから受け取ったトークンが構文を形成しているかを調べ、構文が成立しなければ成立するまでトークンを要求していきます。

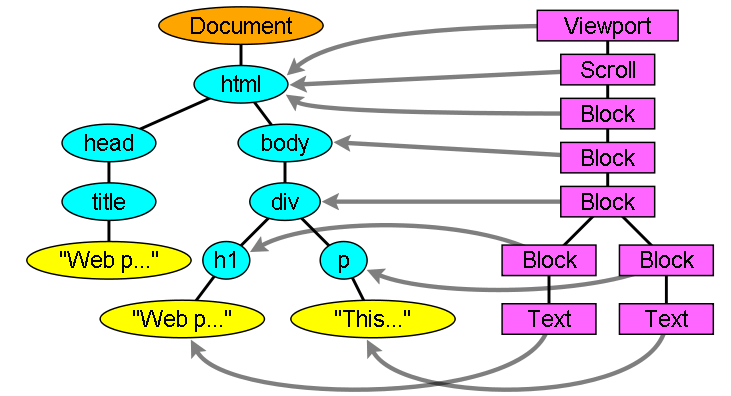
◆DOMツリー
DOMはドキュメント・オブジェクト・モデルの略称で、DOMツリーはHTMLの要素をツリーで表したものです。例えば下記のようなHTMLドキュメントであれば……

下図のようなDOMツリーに変換されます。

◆レンダーツリー
DOMツリーの構築と同時に、ブラウザはレンダーツリーと呼ばれるまた別のツリーを構築します。このツリーは描画すべき要素を表示順に並べたツリーであり、それぞれのノードは自分自身とその子のレイアウト方法・描画方法の情報を保持しています。
◆レンダーツリーとDOMツリーの関係性
レンダーツリーの要素はDOMツリーの要素と対応していますが、必ず1対1で対応しているわけではなく、「head」要素などの描画されない要素はレンダーツリーには含まれていません。また、フロートや絶対位置が指定されている要素はDOMノードの時の位置から移動し、実際に表示されるフレームにマッピングされます。
◆CSSの解析
ブラウザはCSSのセレクターを右から左へと読み、照合を行います。照合では、1つの要素ごとに全てのルールを走査し、セレクターとマッチするかどうかを確かめます。複数のルールで競合が発生する場合、「要素のstyle属性」「IDセレクタの数が多いルール」「クラスセレクタ・属性セレクタ・擬似クラスの数が多いルール」「要素名や擬似要素の数が多いルール」の順に優先されます。
◆レイアウト
レンダーツリーの要素を、ページのどの位置にどの大きさで表示するのかを決定するプロセスをレイアウトと呼びます。HTMLはフローベースのレイアウトモデルを使用しており、基本的には後ろの要素が前の要素に影響を与えないようになっているため、ドキュメントの上から下へと順にレイアウトしていくことが可能となっています。
レイアウトは再帰的な処理となっており、HTMLドキュメントの「<html>」要素に対応するルートノードからその子へとフレーム階層を再帰的に処理していきます。流れをまとめると以下のようになります。
1. 親ノードが自身の幅を決定
2. 親ノードに対して子ノードの位置を決定
3. 必要に応じて1と2を繰り返し、子ノードの高さを決定できれば次のステップへ
4. 子ノードの高さと余白の情報を元に親ノードの高さを決定
5. 親ノードに「レイアウト完了」マークを付ける
◆描画
描画は、レンダーツリーとレイアウトの結果を元に画面にコンテンツを表示するフェーズです。一要素が変更された場合にツリー全てを再描画しているとページの表示が遅くなってしまうため、関係する部分のみを処理できるようになっています。例えばWebKitは今の表示領域をビットマップで保存し、変更後のものと差分をとってその差分だけを描画するようになっています。
要素の色を変更する場合であればその要素だけを再描画すれば済みますが、要素の位置を変更した場合はその要素だけでなく子や兄弟となる要素までレイアウト・描画処理が行われます。「html」要素のフォントサイズを変えるなどの大きな変更ではキャッシュが無効化され、ツリー全体の再レイアウト・再描画が行われます。
◆まとめ
普段何気なく利用しているブラウザですが、その裏側は非常に大きく複雑な仕組みで成り立っています。Google Chromeの元となっているオープンソースプロジェクトである「chromium」のリポジトリを確認すると、2008年に登場して以来80万回近くのアップデートが行われてきたことが分かります。また、その巨大さは貢献した開発者の数が数えられずに「無限」と表記されているほど。
ウェブサイトをネイティブアプリのように利用できる技術「PWA」が登場したりするなどますます高度化が進んでいっており、Microsoftが自社製エンジンの維持を諦めるなどブラウザの寡占化が進んでしまうのもうなずける状況となっていますが、ユーザーとしては毎日使うブラウザがますます便利になっていくのはありがたいものです。
・関連記事
ウェブブラウザの「about:」機能はどのようにして誕生したのか? - GIGAZINE
今や最も使用されているブラウザ「Chrome」は誕生からの10年でどれほど速くなったのか - GIGAZINE
Webページをアプリとして利用できる「デスクトップPWA」などが含まれるGoogle Chrome 70安定版がリリース - GIGAZINE
Webの生みの親バーナーズ=リーは中央集権化しているWebの現状を憂いている - GIGAZINE
「Googleは長年にわたってパートナーだったFirefoxを妨害してきた」とMozilla元幹部が主張 - GIGAZINE
・関連コンテンツ