What kind of work does the browser do before the website is displayed?

A web browser, an application for displaying web pages, is now an indispensable tool for the daily lives of many people. A commentary on how the browser works is published on GitHub.
GitHub-vasanthk / how-web-works: What happens behind the scenes when we type www.google.com in a browser?
In this commentary, for example, the flow 'From entering google.com in the address bar until the Google homepage is displayed' is taken up.
·table of contents
◆ When you enter 'g' on google.com
◆ When you press the enter key
◆ Decrypt URL
◆ Confirm HSTS list
◆ DNS
◆ Open a socket and perform a TLS handshake
◆ HTTP protocol
◆ HTTP server
◆ Server response
◆ Back side of browser
◆ Structure of browser
◆ Rendering engine
◆ About the order of processing
◆ Parsing syntax
◆ DOM tree
◆ Render Tree
◆ Relationship between render tree and DOM tree
◆ Analysis of CSS
◆ Layout
◆ Drawing
◆ Summary
◆ When you enter 'g' on google.com
Press the 'g' key and the browser will launch the autocomplete feature. The algorithm implemented in the browser proposes various candidates and displays them under the address bar. Most of the algorithms are based on history and bookmarks to prioritize them. These candidates will be narrowed down as appropriate as you enter 'google.com'.
◆ When you press the enter key

Pressing the keyboard's 'Enter' key as far as it will close the keyboard electronics. If the keyboard is of mechanical type, the electronic circuit is closed by direct contact between the electrodes, and if it is of the capacitive non-contact type, the circuit is closed simply by bringing the electrodes close. When the circuit is closed, a small amount of current flows in the keyboard circuit, and the keyboard control scans that current to determine which key is pressed. The control system removes noise from the current, converts it into a key code represented by a number, and sends it to the computer via USB or Bluetooth. For example, pressing the Enter key sends '13' to the computer.
・ In the case of USB keyboard
The generated key code is stored in a storage device inside the keyboard called 'endpoint'. The USB controller that controls the USB on the computer reads that endpoint more than 100 times a second. In response to this reading, the key code reaches the USB controller as a serial signal, the signal is decoded by the USB controller, and the keyboard device driver converts it so that the OS can read it. The key code of the key thus pressed reaches the
・ In the case of touch screen keyboard

When the user places a finger on the screen, a small amount of current flows there, and the voltage at that place drops. The screen controller detects the voltage drop and generates an
◆ Decrypt URL
In addition to the domain, the URL contains information about protocols and resources . For example, 'http://google.com/' means that 'http' uses a protocol called ' Hyper Text Transfer Protocol ', and '/' at the end means that an index page is displayed. . If you do not enter a valid protocol or domain name, the browser sends the text entered into the default search engine.
◆ Confirm HSTS list
The browser has a hard-coded 'preloaded HSTS (HTTP Strict Transport Security)' list. If the domain you are trying to access is registered in this list, the connection is always made via HTTPS. Although it is possible to force HTTPS communication without using this list, if you do not use the list, the initial connection will be made over HTTP, and you will bear the risk of downgrading attacks etc. You This list is maintained by Google, but is used by Google Chrome as well as major browsers such as Firefox, Safari, Internet Explorer and Edge. Anyone can register to the list from the following site.
HSTS Preload List Submission
https://hstspreload.org/
◆ DNS
If computers communicate with each other via the Internet, you need to know the IP address of the other party. DNS is a tool to know the target IP address based on the entered domain name. This phase proceeds in the following order:
・ Browser cache
First, the browser checks its cache and uses information from previous connections, if any information remains. OS is TTL indicating browser cache expiration date
The browser cache will remain for about 20 to 30 minutes regardless of the original TTL, because it does not convey that number.
・ OS cache
If there is no browser cache, the browser calls a system call and requests the OS to search DNS. For example, on Windows, the system call 'gethostbyname' is called. The operating system itself also holds a DNS cache, so if the cache remains there, its value will be communicated to the browser.
・ Router cache
If it does not remain in the OS cache, a DNS request is sent to the router next. In general, routers also have their own cache.
・ ISP DNS cache
Next we will send a request to the DNS server of the ISP. This server also has a cache.
・ Recursive search
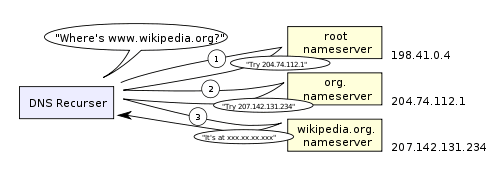
The ISP's DNS server will start a recursive search if there is no cache for the incoming request. Recursive search is a method of requesting DNS information in order of root name server, top-level name server of '.com', and name server of Google. In addition, it is usually unnecessary to query the root name server because it caches '.com' name server information.
The figure below shows the state of recursive search with 'www.wikipedia.org' as an example. First, ask the root name server for name server information of 'org', and based on the response, next ask the name server of 'org' for name server information of 'wikipedia.org', and finally, 'wikipedia.org' I am asking the name server for information on 'www.wikipedia.org'.
◆ Open a socket and perform a TLS handshake
Once you have found the IP address of the destination server, check the port number specification next. If no port number is specified, HTTP 80 and HTTPS 443 will be used. Then call the system library socket function to request a TCP socket stream. And this connection does not start to send data suddenly, but performs processing called handshake to define encryption method and common key first.
1. The client computer sends a message called ClientHello to the server along with a list of TLS version information, a list of available encryption algorithms and compression methods.
2. The server TLS version information, the encryption algorithm and the compression method to be used, the certificate authority sends back a message called ServerHello together with the public certificate of the signed server by. The certificate has a public key, and the client uses the public key to encrypt the remaining handshake until the common key is generated.
3. The client validates the server's certificate, and if successful, generates a pseudo-random string, encrypts it with the server's public key, and sends it to the server.
4. The server decrypts the string sent. In this way, a common string was obtained between the client and the server, but both the server and the client generate a common key based on this string.
5. The client hashes the previous communication, encrypts it with the common key, and sends it to the server as a Finished message.
6. Hash the communication as well on the server side and make sure that it matches the hash sent from the client. If it matches, it sends a Finished message back to the client.
The handshake is now complete and we will continue to send application data encrypted with the common key.
◆ HTTP protocol
The HTTP request message consists of the following strings:
[code] GET http://www.google.com/ HTTP / 1.1
Accept: application / x-ms-application, image / jpeg, application / xaml + xml, [...]
User-Agent: Mozilla / 4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW 64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: google.com
Cookie: datr = 1265876274-[...]; locale = en_US; lsd = WW [...]; c_user = 2101 [...]
[/ code]
There are several types of requests, but it is clearly stated in the first line that the request uses the 'GET' method, and the URL to be requested subsequently is 'http://www.google.com/ 'Is written. The 'Accept' and 'Accept-Encoding' headers on the second and fourth lines indicate the acceptable format for the response, and the browser identifier is described in the 'User-Agent' header on the third line. The fifth line 'Connection: Keep-Alive' represents the intention to keep the TCP connection for the next request, while the sixth line sends a cookie. The last line contains an empty line, which means that the header is over.
The server responds to the request and returns a response. The response contains a response code, eg a 200 OK response code will be sent if the request is successful. The response is inserted with the response code, the response header and a blank line followed by the HTML content body behind the blank line.
The browser parses the received HTML and repeats the same process for all resources referenced in the page, such as images and CSS files. If the reference to another domain is included, perform the same procedure again from the item of DNS.
◆ HTTP server
HTTPD (HTTP Daemon) server application is a tool to handle request and response on the server side. Apache and nginx for Linux and IIS for Windows are famous.
When HTTPD receives a request, it extracts 'method' 'domain name' 'request path' from the request, and checks if there is a virtual host corresponding to the domain name. If you enter a URL in the browser's address bar, the method is 'GET', and in this case the domain name is google.com and the request path is '/'.
After confirming that the host google.com can handle the GET request, the server then checks if it has permission to do so. And get index file corresponding to this request path '/'. Then, if necessary, index files are converted to HTML using request handlers such as ASP.NET, PHP and Ruby, and sent back to the client.
◆ Server response
The server response has the following format:
[code] HTTP / 1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check = 0,
pre-check = 0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP = 'DSP LAW'
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text / html; charset = utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3
T n @ [...]
[/ code]
The blank line of the response is garbled, because it is compressed with gzip as shown in the seventh line. When the browser expands the data, it will be the HTML sentence '<! DOCTYPE html [...]'. And by declaring that 'Content-Type' is 'text / html' in the eighth line, the browser interprets this file as html instead of downloading it, and the page is displayed.
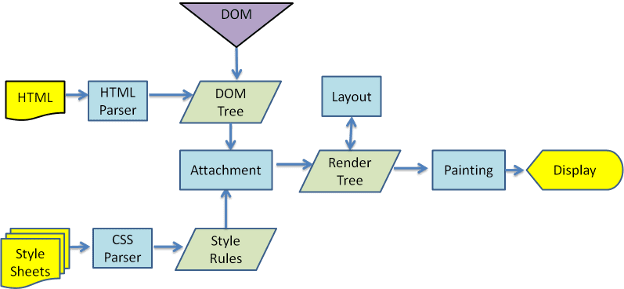
◆ Back side of browser
When the browser reads HTML, CSS, JavaScript, it interprets the syntax and performs rendering processing. The rendering process is performed in the order of 'Build DOM Tree'-> 'Build Render Tree'-> 'Layout Render Tree'-'Draw Render Tree'.
◆ Structure of browser
The browser can be disassembled into several parts as shown below.

1. User interface (UI)
In charge of address bar, back and forward buttons, bookmark menu, etc.
2. Browser engine
It mediates the interaction between UI and rendering engine.
3. Rendering engine
It is an engine for interpreting HTML and CSS and displaying content on the screen.
4. Network
Responsible for network parts like HTTP requests. The implementation is different for each platform.
5. UI back end
In drawing basic parts such as drop-down lists and windows, it absorbs differences between platforms as well as networks, and provides an interface that can be used universally on different platforms.
6. JavaScript engine
An engine that interprets and executes JavaScript syntax.
7. Data storage
I am responsible for storing local data like cookies.
◆ Rendering engine
The rendering engine is software that receives content such as HTML, XML, and image files, and format information such as CSS and XSL, and displays the formatted content on the screen. In Chrome and Opera, Blink is a rendering engine called Blink, Safari is a Webkit that was the source of Blink, and Firefox is a rendering engine called Gecko.
◆ About the order of processing
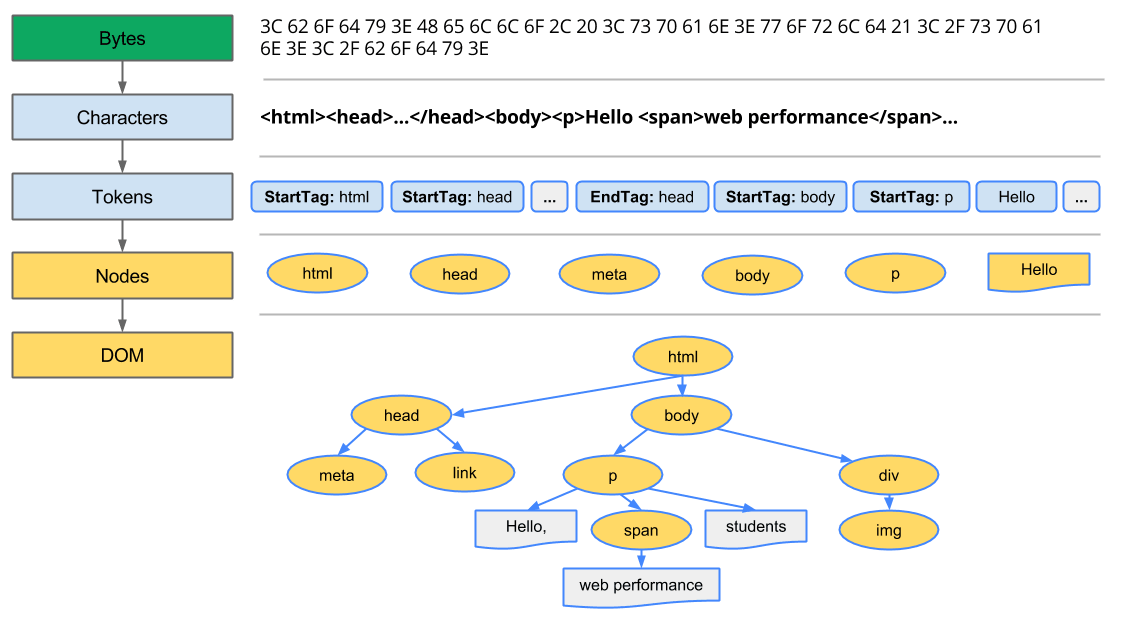
The rendering engine reads the document content from the network layer, usually 8 KB each. Parse and tokenize the imported HTML document, convert it into DOM nodes, and place it in a tree called 'DOM tree'.
In addition, the rendering engine reads external CSS files and style elements, and builds another tree called 'render tree' together with the information of the content tree. In the render tree, each element is stored as a rectangle with information such as color and dimensions.
Once the render tree has been built, we will layout it and calculate the position on the screen where each node should be displayed.
And finally, render the contents of the render tree using the UI back end layer. In order to display the page as soon as possible, all the steps will be in progress simultaneously. The flow of this series is as follows.
◆ Parsing syntax
Converting a document into a more manageable format is called parsing. HTML sentence grammar is one of the so-called
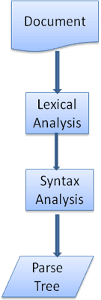
When parsing, the Lexar performs lexical analysis of the document and converts the document into tokens. HTML tokens consist of start tag, end tag, attribute name and value of attribute. The parser checks if the token received from the lexer forms a syntax, and if the syntax does not hold, it requests the token until it holds.

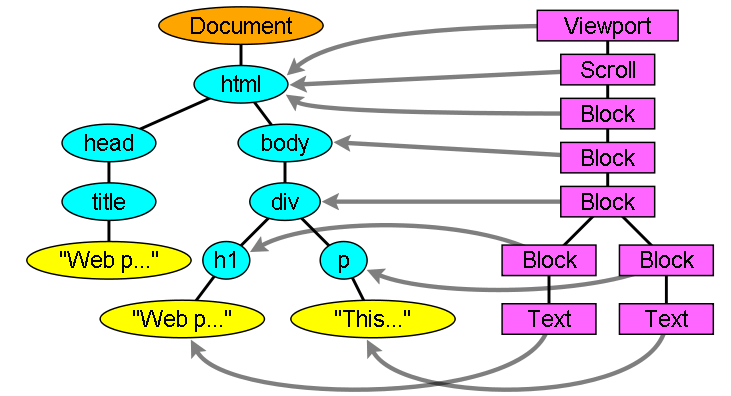
◆ DOM tree
DOM is an abbreviation of Document Object Model, and DOM tree is a tree representation of HTML elements. For example, in the following HTML document ...

It is converted to a DOM tree as shown below.

◆ Render Tree
At the same time as building the DOM tree, the browser builds another tree called the render tree. This tree is a tree in which the elements to be drawn are arranged in display order, and each node holds information on how to lay out and draw itself and its children.
◆ Relationship between render tree and DOM tree
The elements of the render tree correspond to the elements of the DOM tree, but they do not necessarily correspond one-to-one, and non-drawn elements such as the 'head' element are not included in the render tree. Also, elements with floats or absolute positions are moved from the position of the DOM node and mapped to the frame actually displayed.
◆ Analysis of CSS
The browser reads CSS selectors from right to left and performs matching. Matching involves scanning all rules one element at a time to see if they match the selector. When conflicts occur in multiple rules, 'element style attribute' 'rule with a large number of ID selectors' 'rule with a large number of class selectors / attribute selectors / pseudo-classes' 'There are many element names and pseudo-elements The rule is prioritized in order.
◆ Layout
The process of determining at what position on the page and in what size the elements of the render tree will appear is called a layout. HTML uses a flow-based layout model, and basically the elements behind it do not affect the elements before, so the layout can be in order from top to bottom of the document It is possible.
Layout is a recursive process that recursively processes the frame hierarchy from the root node corresponding to the '<html>' element of the HTML document to its children. The flow is summarized as follows.
1. Parent node determines its own width
2. Determine the position of the child node relative to the parent node
3. Repeat 1 and 2 as needed, and if you can determine the height of the child node, go to the next step
4. Determine parent node height based on child node height and margin information
5. Mark the parent node as 'layout complete'
◆ Drawing
Drawing is a phase that displays the content on the screen based on the result of the render tree and layout. If one element is changed, redrawing the entire tree will slow down the page display, so only relevant parts can be processed. For example, WebKit saves the current display area as a bitmap, draws the difference from the changed one, and draws only the difference.
If you want to change the color of an element, you only need to redraw that element, but if you change the position of the element, layout and drawing processing will be performed not only to the element but also to elements that are children or siblings. . Major changes, such as changing the font size of the 'html' element, will invalidate the cache and cause the entire tree to be re-layout and re-draw.
◆ Summary
It is a browser that is normally used casually, but the reverse side is built with a very large and complicated mechanism. If you check
With the advent of technologies such as 'PWA' that can use websites like native apps, the technology is getting more and more advanced, and the browser is becoming oligopolistic, such as Microsoft giving up maintaining its own engine . The situation is already clear, but as a user, it is appreciated that the browser we use every day will become increasingly useful.
Related Posts:







in Software, Posted by log1d_ts