




GoogleのAI部門でトップだったエンジニアが示す機械学習システムアーキテクチャの進むべき姿とは?

日進月歩で技術が進む機械学習とそれに基づく人工知能(AI)の世界は、常に新しい技術が登場し続ける場です。かつてGoogleのAI部門でチーフを務め、「Google Brain」のトップだったジェフ・ディーン氏が、今後の機械学習を見定める上で重要なポイントを語っています。
Google AI Chief Jeff Dean’s ML System Architecture Blueprint
https://medium.com/syncedreview/google-ai-chief-jeff-deans-ml-system-architecture-blueprint-a358e53c68a5
2018年1月、ディーン氏は論文「A New Golden Age in Computer Architecture: Empowering the Machine-Learning Revolution」を、チューリング賞受賞者でコンピューターアーキテクト(設計者)のデイビッド・パターソン氏と共同で発表しました。この論文では、機械学習の専門家とコンピューターアーキテクトが機械学習の可能性を実現するために必要なコンピューティングシステムを協力して設計することが奨励されています。

ディーン氏はまた、2018年7月に北京で開催された「Tsinghua-Google AIシンポジウム」で、研究者が学習させたいと考えているモデルのトレンドについての講演を行いました。
Dean氏は、論文アーカイブサイト「arXiv」にアーカイブされる機械学習関連の論文件数の増加カーブが、1975年にコンピューターチップの成長予測を示した「ムーアの法則」の上昇カーブを既に超えていることを指摘していました。

ディーン氏とパターソン氏は論文の中で、Googleが開発した機械学習向けプロセッサ・Tensor Processing Unitの第一世代である「TPU v1」と第二世代の「TPU v2」の例を挙げながらハードウェア設計を分析します。両者は、機械学習ハードウェアとしての競争力を維持するためには、少なくとも2年間の設計と3年間の導入期間からなる5年の時間軸で状況を見極める必要性を説いています。
ディーン氏は、この5年という時間軸における機械学習ハードウェア設計について、以下の6つのポイントを挙げています。
◆1:トレーニング(強化)
機械学習ワークフローで最も重要な2つのフェーズは、「推論(inference)」または「予測(prediction)」と呼ばれる生産フェーズと、「強化(training)」または「学習(learning)」と呼ばれる開発フェーズであるとのこと。
Googleは2015年にTPU v1を、2017年にTPU v2を、そして2018年にはTPU3.0を発表しました。ディーン氏は、TPU v2を16台連結させることでGoogleの検索ランキングモデルの学習スピードを14.2倍に、画像モデルのトレーニング速度を9.8倍向上させるなどの実績を挙げてきました。TPU v2は、本来は64台を連結させることで所定の性能を発揮するシステム構成となっていますが、ディーン氏はその4分の1の構成で高速化を実現したことになります。
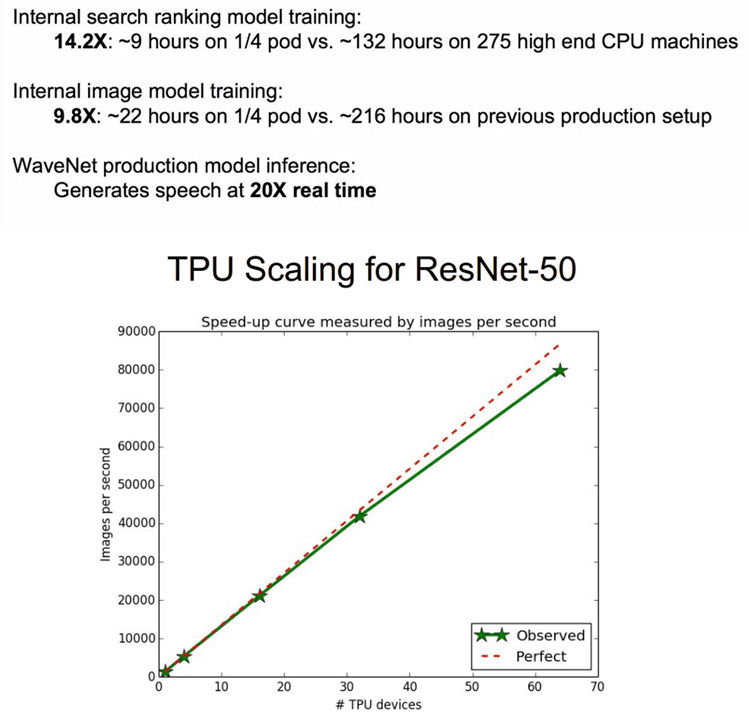
TPUは非常に高価なハードウェアではありますが、GoogleはTFRC(TensorFlow Research Cloud)プログラムの一環として、機械学習の研究を進めるために取り組みを行っているトップレベルの科学者に1000台のTPUデバイスを無料で提供しています。
◆2:バッチサイズ
機械学習を進める上で重要な設定「ハイパーパラーメーター」の1つが「バッチサイズ」です。これは訓練に用いるデータを小さなバッチ(ミニバッチ)に分けて処理を行うもので、そのサイズ設定が機械学習のスピードや効率に大きく影響します。
2018年時点で用いられているGPUは、32以上のミニバッチサイズで効率的に動作するようになっているとのこと。しかし、Facebook AI Research(FAIR)が発表した論文「[1706.02677] Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour」では、画像を学習する視覚認識モデルは「8192」および「32768」というミニバッチサイズで効果的に訓練されることが示されています。このような大規模なトレーニングはFAIRのモデルには適しているものの、普遍的な解決策とは捉えられていないのが現状であるとのことです。
◆3:スパーシティ(疎性)と埋め込み
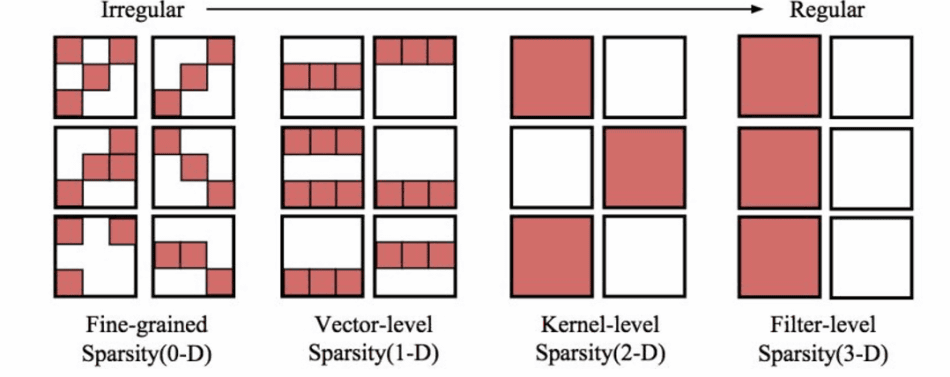
「スパーシティ」または「疎性」は、ニューラルネットワークが持つニューロンのうち一部だけが発火(反応)するというものです。スパーシティにはさまざまな形式があり、うまく利用することでデータの0と小さな値をスキップして機械学習の複雑さを軽減することができるようになります。一般的に研究者は大規模なデータセットに対してますます巨大なモデルサイズを必要とするものですが、「より大きなモデル、しかし疎性的にアクティベートされた状態」が重要であると説いています。
その例の1つが、Google BrainのMixed of Expert(MoE)モデルです。このモデルでは、ネットワーク構成の一部として学習された「Expert」パネルのサブセットを参照して、望ましい疎性のレベルを実現します。
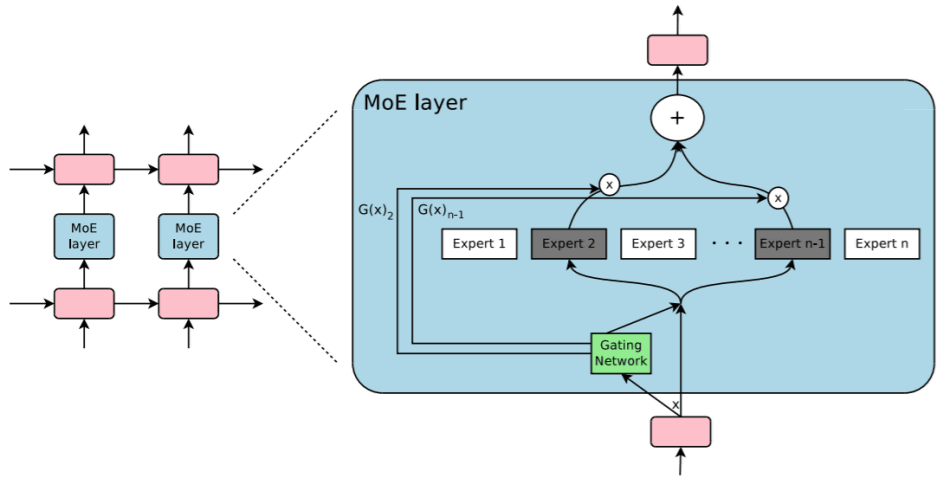
その結果、MoEモデルは、以前のアプローチよりも少ないFLOP数でより高い精度の学習を行います。Googleが持つ英語からフランス語の翻訳データセットでは、MoEモデルは、時間でわずか6分の1の訓練を受けた後、Google翻訳の頭脳であるGNMT(Google Neural Machine Translation)モデルよりも1.01倍高いBilingual Evaluation Understudyスコアを記録しました。

◆4:量子化と蒸留
「量子化」は、費用対効果の高い機械学習推論において有用であることが既に証明されています。また、既に訓練されたAIの入力と出力をそのまま新しくシンプルなAIに学習させる蒸留も、効率を高める上でおろそかにできないものであるという認識が広まっています。
◆5:「ソフトメモリ」を持つネットワーク
論文の中でディーン氏とパターソン氏は、いくつかのディープラーニング技術がメモリアクセス(記憶へのアクセス)に似た機能を提供できることを示しています。たとえば、「attention mechanism(注意メカニズム)」はデータ処理の長いシーケンスの間に、ソースの中で選択された部分に注意を向けることによって、機械翻訳における機械学習パフォーマンスを改善するために活用されると考えられています。
従来の「ハードメモリ」とは異なり、「ソフトメモリ」は情報量の多いコンテンツ選択のために、用意されたすべてのエントリに対して加重平均を計算します。しかし、これは複雑な処理であり、ソフトメモリモデルの効率的に、または疎性を持つ状態で実装することに関する研究は未だ存在していません。
◆6:「学習したことから学習する」
ほとんどの大規模な機械学習アーキテクチャとそのモデル設計は、依然として人間の専門家が持つ経験則と直感に依存しています。機械学習が学習したことから学習する「Learning to Learning(L2L)」は、人間の専門家による意志決定を伴わない自動機械学習を可能にするモデルという意味で革命的なものです。このアプローチは、機械学習の専門家が不足する問題に対処するために使用されています。
自動化された機械学習の場合、Google Brainチームは「強化学習(Reinforcement Learning)」を用います。これは2017年に発表された論文「Neural Architecture Search with Reinforcement Learning」で提案されている手法です。「正確性」を報酬信号として使用することにより、このモデルは時間の経過とともに自己改善することを学ぶことができます。論文では、新しいネットワークアーキテクチャの発見のために「CIFAR-10データセット」を、そして強化学習を有する新規のメモリセルの組成について「Penn Treebankデータセット」を適用することで、ともに従来の最先端の方法に匹敵する結果を達成しました。


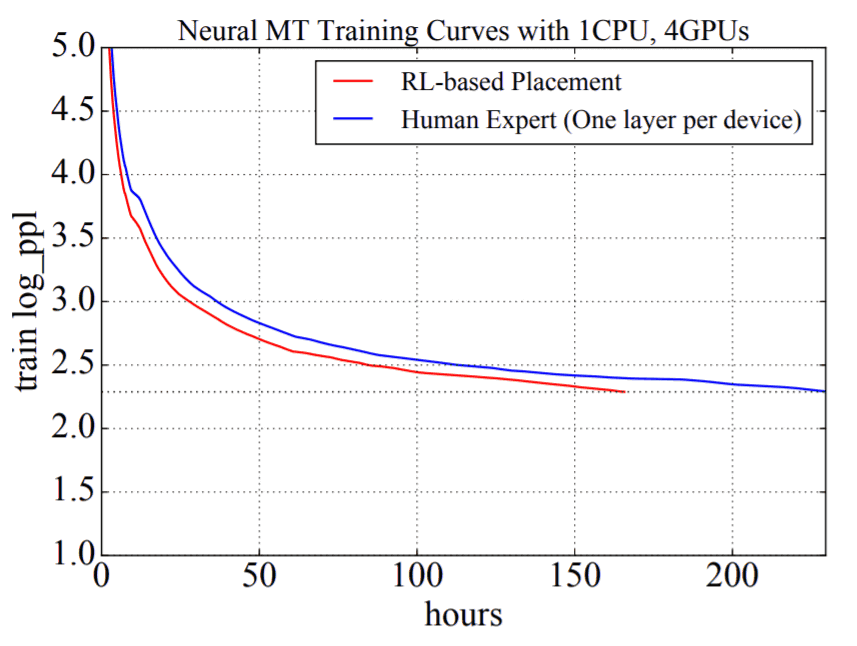
メタ学習において強化学習を応用する他の例には、最適な経路の検出、活性化関数の選択、学習最適化のアップデート基準などが含まれます。Neural Machine Translation(NMT)モデルのトレーニングテストでは、強化学習ベースのプレースメントが人間の直感と矛盾していたにもかかわらず、専門的なプレースメントよりも学習スピードが約65時間速く、27.8%のトレーニング時間のスピードアップを達成しました。
◆将来の見通し
シンポジウムの最後にディーン氏は、将来の見通しについて以下のようなアイデアを提示しています。
1.大規模なモデルだが、疎的に活性化するもの
2.多くのタスクを解決するための単一のモデル
3.大規模なモデルを通して動的に経路を学習し、成長するもの
4.機械学習スーパーコンピューティングに特化したハードウェア
5.ハードウェアへの効率的なマッピングが可能な機械学習
・関連記事
コンピューターが人間を超える「AI」「ディープラーニング」「機械学習」とは何かについて解説する「Machine Learning 101」 - GIGAZINE
AIを開発するGoogle Brainチームが2017年の機械学習研究の成果を振り返る「Looking Back on 2017」パート1を公開 - GIGAZINE
AI(人工知能)に対するありがちな「誤解」とそれに対する回答まとめ - GIGAZINE
より高い品質の翻訳を実現するGoogleの「Transformer」がRNNやCNNをしのぐレベルに - GIGAZINE
自己学習する「人間のような」次世代人工知能を開発するカギとなるものは? - GIGAZINE
・関連コンテンツ








in ハードウェア, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article What is the appearance of the machine le….