




ディープラーニングにおける「カプセルネットワーク(CapsNet)」による画像認識とは?

By SplitShire
ディープラーニングにおける画像認識には畳み込みニューラルネットワーク(CNN)を使った学習が一般的とされています。しかし、CNNによる画像認識では、人の顔を認識するときに目や鼻、口のパーツは認識できるものの、これらの正確な位置関係を認識することは得意ではありません。2017年11月にGoogleの研究員であるジェフリー・ヒントン氏が、CNNの欠点を克服したという「カプセルネットワーク」(CapsNet)を発表しました。CapsNetがどのようなものか、オライリーの記事を読むとよくわかるようになっています。
Introducing capsule networks - O'Reilly Media
https://www.oreilly.com/ideas/introducing-capsule-networks
画像認識においては「畳み込みニューラルネットワーク」(CNN)が主流で、欠点を克服するために、「Classification + Localization」「Object Detection」「セマンティックセグメンテーション」「インスタンスセグメンテーション」などの手法がたくさん作られてきました。
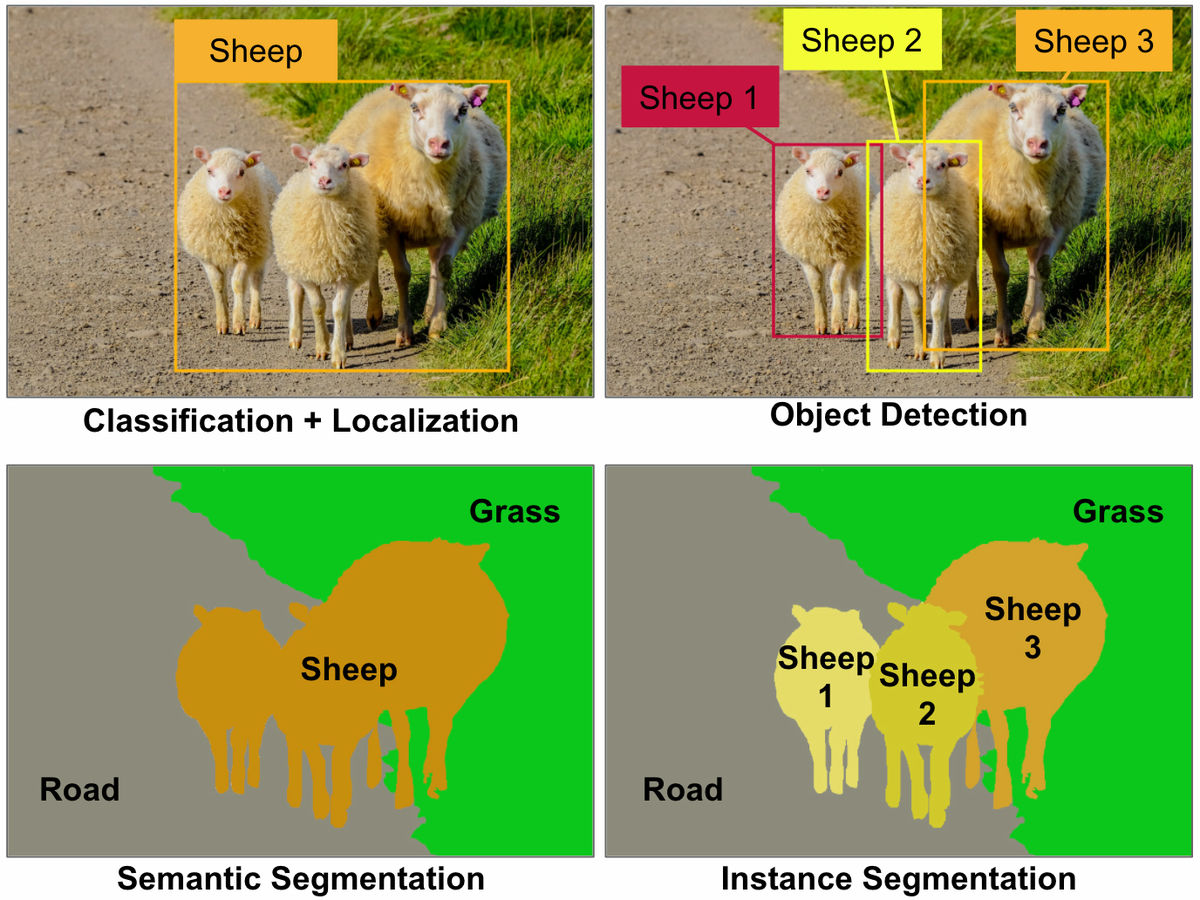
しかし、CNNを使った手法でうまく画像認識を行うには膨大な数の画像を学習させる必要があったり、画像内にオブジェクトがたくさんあって混雑していると扱えないことがあったり、プーリング処理を施すことで、画像内にある特徴同士の関係性が失われてしまったりなど、いろいろと障壁があるとのこと。そこでCNNの欠点を補うために開発されたのがニューラルネットワークアーキテクチャ「カプセルネットワーク(CapsNet)」であり、ディープラーニングを使った画像認識に大きなインパクトを与える可能性を秘めているとされます。CapsNetも画像内にたくさんオブジェクトがある場合は一部認識できないことがありますが、これ以外の問題点はほぼクリアできているようです。
CapsNetは目で見るときと同じように、イメージからオブジェクトの情報を出すことをイメージするとわかりやすいとのことです。
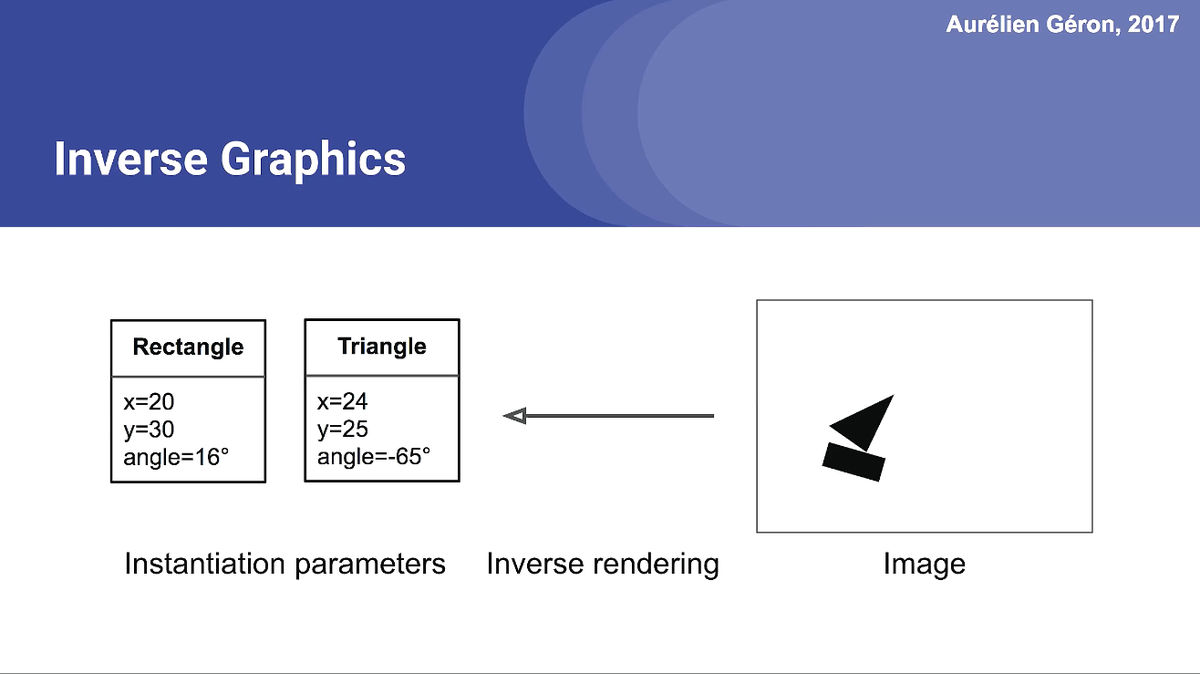
CapsNetの「カプセル」とは、オブジェクトの情報を意味していて、どんな形でどの位置に存在するのかを示すものです。赤枠内に50個のカプセルがあり、実際にオブジェクトが存在している位置のカプセルが大きくなります。このカプセルのことを「Primary Capsule Layer」と呼びます。
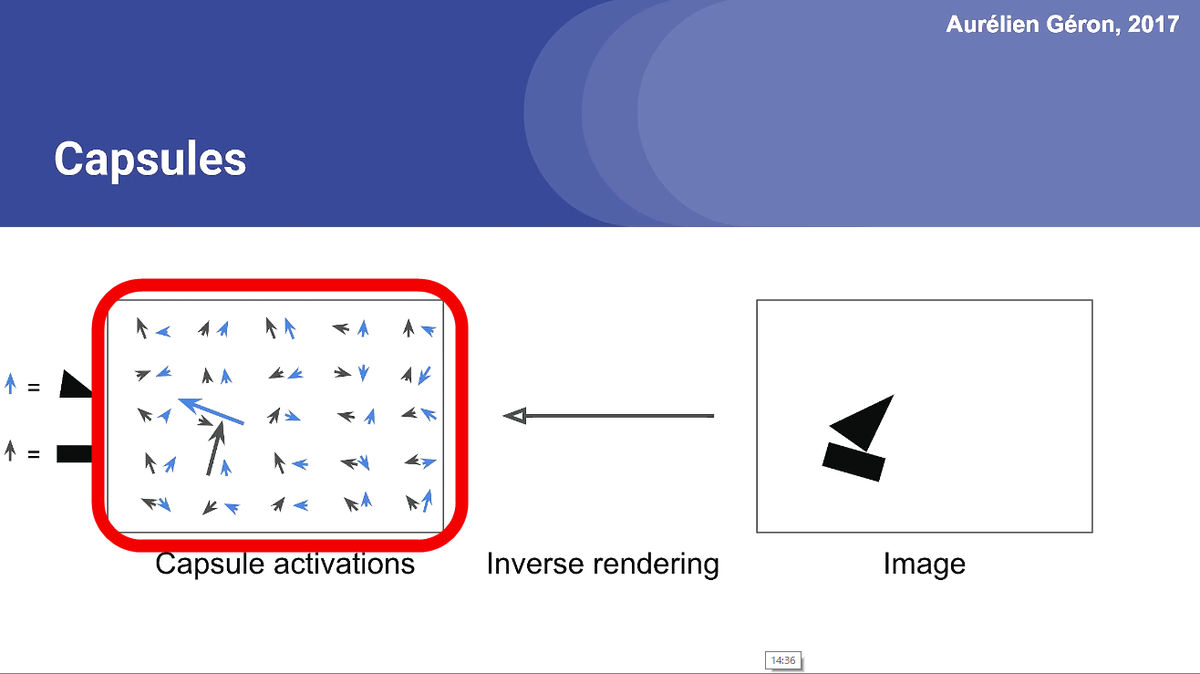
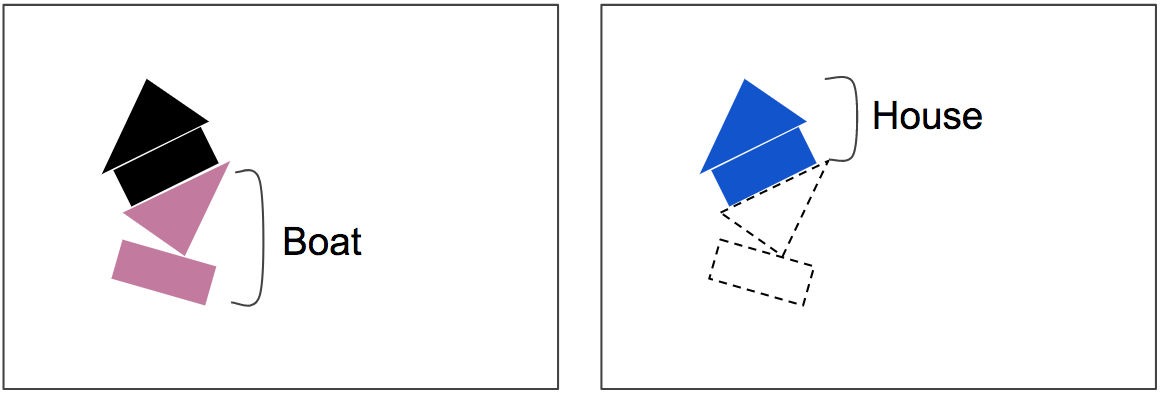
三角形と長方形の物体の向きは、カプセル内のそれぞれ2つのベクトルで表されています。つまり、この大きな矢印の位置に長方形と三角形が存在し、同じ向きに図形を配置することで、ボートのような形になるというわけです。
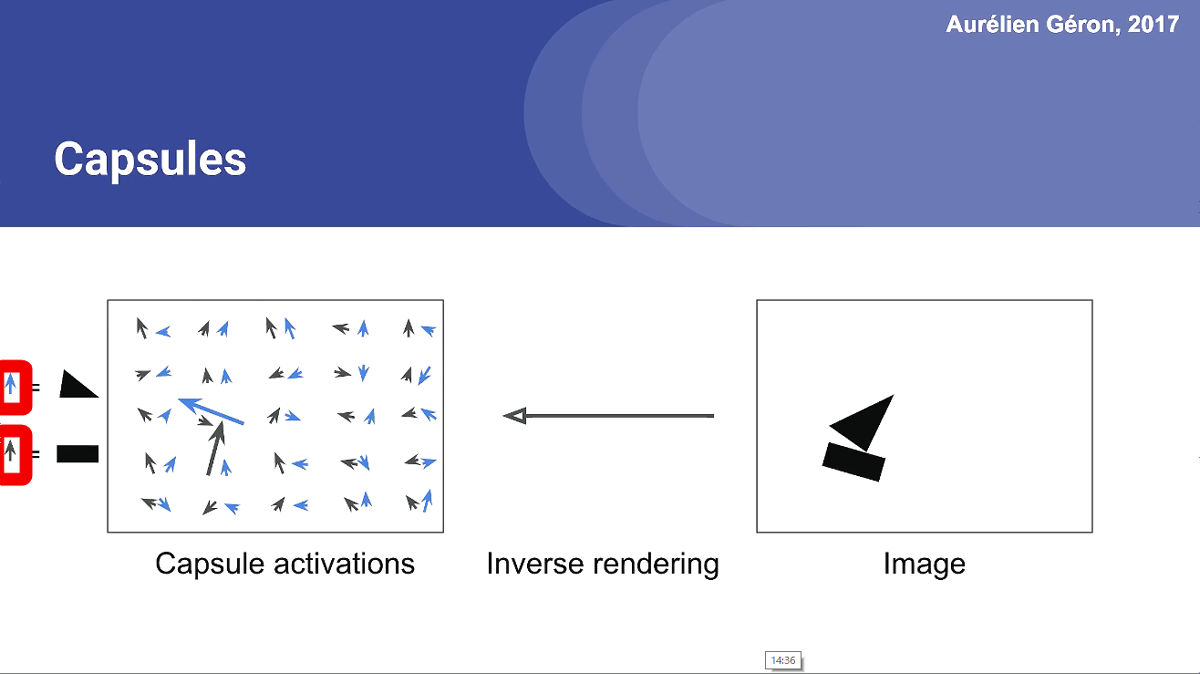
さらに長方形と三角形のカプセルの関係に着目し、複数のカプセルを組み合わせ、複雑なオブジェクトを検出する上位層の「Routing Capsule Layer」もあります。ここでは、三角形と長方形を組み合わせた「ボート」と「家」の画像を認識させる例で考えてみます。
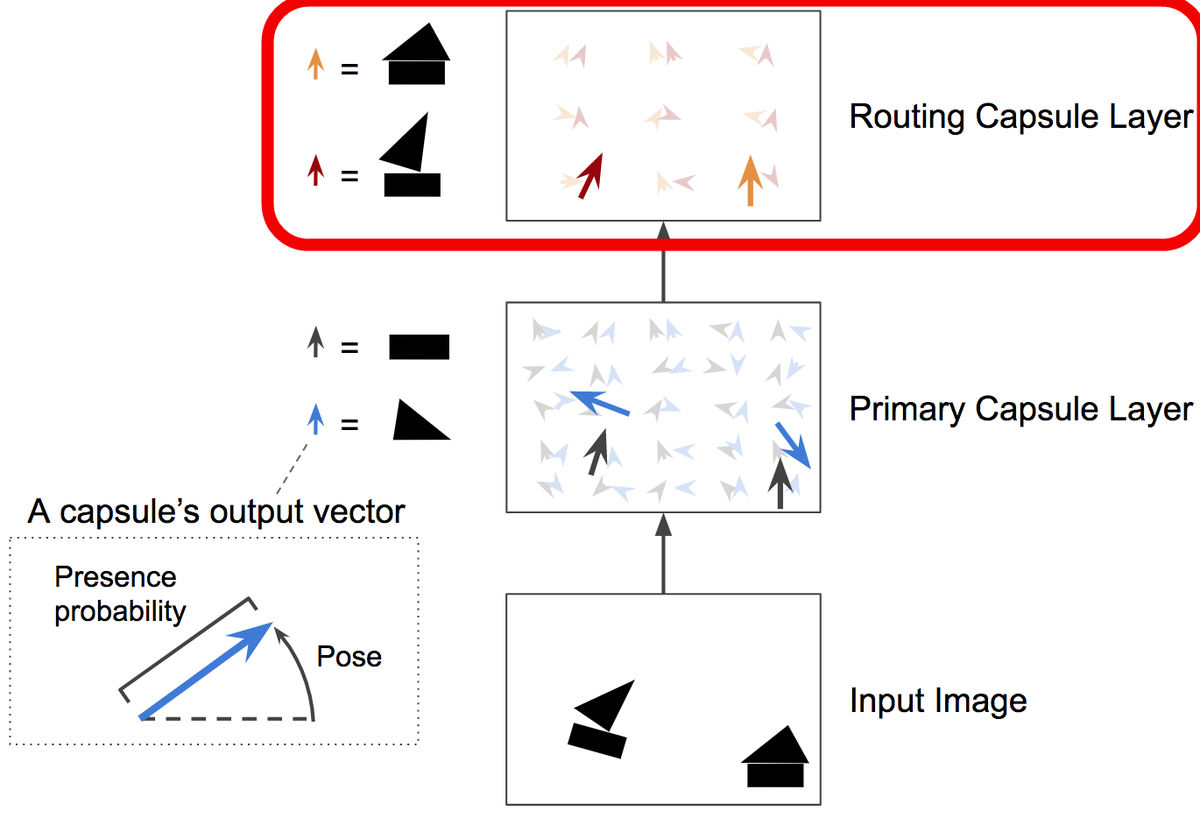
「Routing Capsule Layer」では「Routing by Agreement」と呼ばれる少し変わったアルゴリズムを使っています。この例であれば、長方形と三角形を組み合わせた図形は、家もしくはボートのいずれかになりますが、長方形と三角形がわずかに右に回転した状態をベースに図形を作ってみると、下の画像のようにボートになる確率が高くなるので……
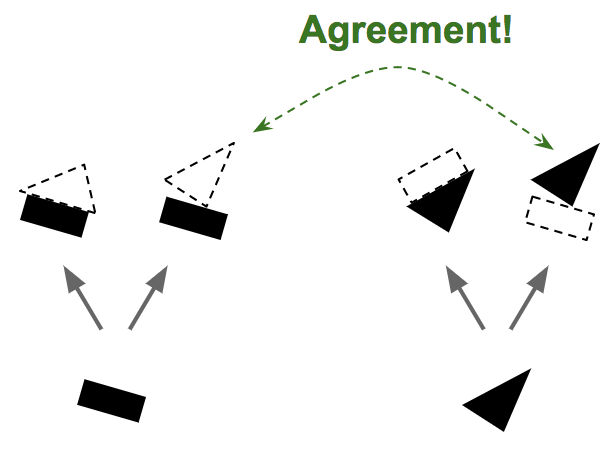
この位置関係であれば、長方形と三角形の関係はボートの形になりやすいと解釈し、「Routing Capsule Layer」ではボートの形のときは強い矢印を描き、画像認識時の優先度が高くなります。
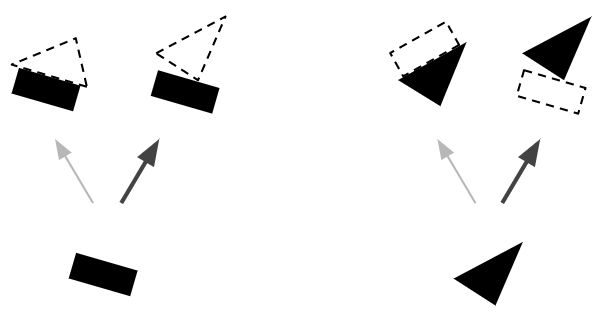
つまり以下の画像をCapsNetで読み込んだ時……

真ん中の長方形と逆向きの三角形を家と認識してしまうと、一番上の三角形と、一番下の長方形の説明ができなくなりますが……
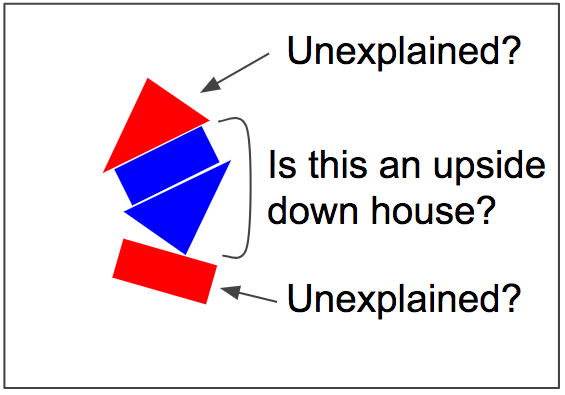
先ほどの「Routing by Agreement」により、一番下の長方形の角度からボートになるという強い相関があるため、下側2つの図形がボート、上側2つの図形が家と認識されやすくなるというわけです。
・関連記事
ディープラーニングを用いてAIに「皮肉」を理解させるという研究 - GIGAZINE
AIを実現する「ニューラルネットワーク」を自動的に構築することが可能なAIが出現 - GIGAZINE
人間の脳を解明するための国際プロジェクト「ヒューマン・ブレイン・プロジェクト」を支える大規模コンピューター環境「SpiNNaker」システムの実態に迫る - GIGAZINE
Googleが段ボールで自作できる画像認識AI「Vision Kit」を発表 - GIGAZINE
機械学習やビッグデータを扱うデータサイエンティストの年収や使用言語などを赤裸々にするデータ - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article What is image recognition by "capsule ne….