What is image recognition by "capsule network (CapsNet)" in deep learning?

BySplitShire
Deep learningFor image recognition inConvolution neural network(CNN) is commonly used for learning. However, in image recognition by CNN, although it can recognize eyes, nose, mouth parts when recognizing a person's face, it is not good at recognizing the exact positional relationship between them. I am a researcher at Google in November 2017Jeffrey HintonHe said that he overcame the shortcomings of CNNCapsule network"(CapsNet) announced. What is CapsNet,O'ReillyIt is becoming clear that you can read the article of.
Introducing capsule networks - O'Reilly Media
https://www.oreilly.com/ideas/introducing-capsule-networks
In image recognition, "convolution neural network" (CNN) is mainstream, many methods such as "Classification + Localization", "Object Detection", "semantic segmentation", "instance segmentation" etc. have been made in order to overcome disadvantages .
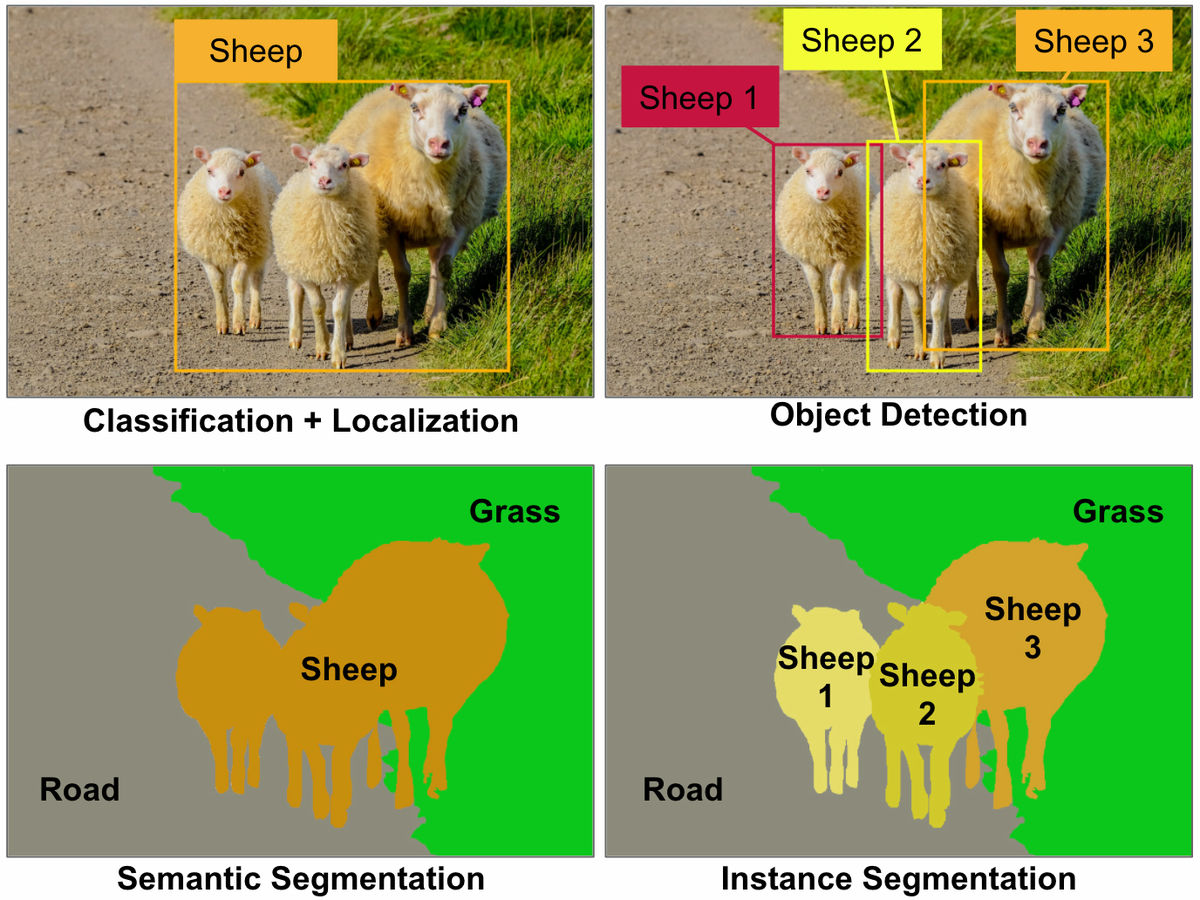
However, in order to successfully perform image recognition with the method using CNN, it is necessary to learn a huge number of images, there are cases where there are many objects in the image and it can not be handled as crowded, and pooling processing It is said that there are various kinds of barriers, such as losing the relationship between the features in the image. Therefore, the neural network architecture "capsule network (CapsNet)" was developed to compensate for the drawbacks of CNN, and it is said that it has the possibility to have a big impact on image recognition using deep learning. CapsNet may not be able to recognize some objects when there are many objects in the image, but it seems that other problems are almost clearable.
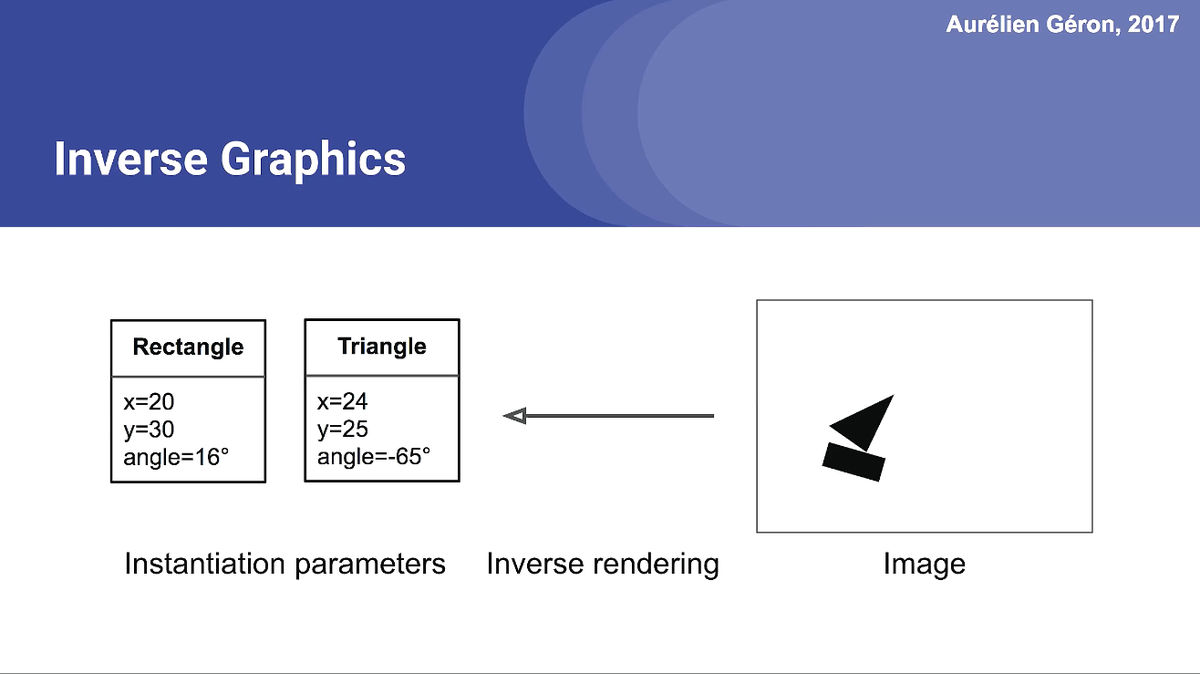
CapsNet says that it is easy to understand if you imagine putting object information out of an image, just like you would see it with your eyes.
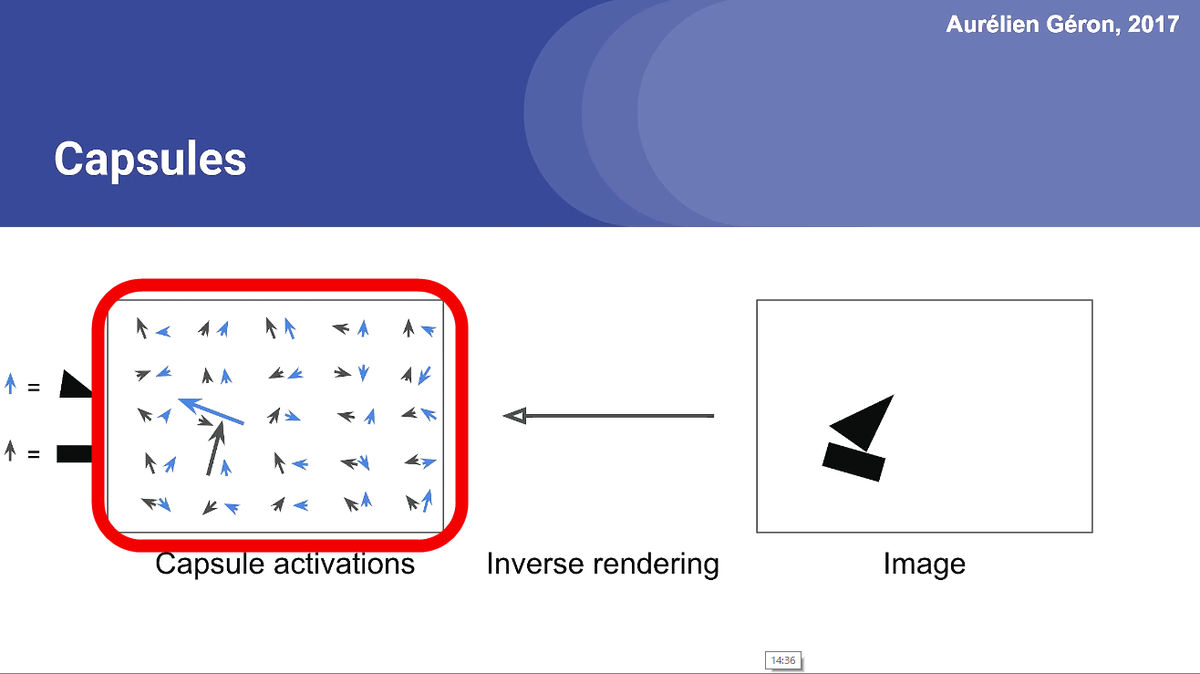
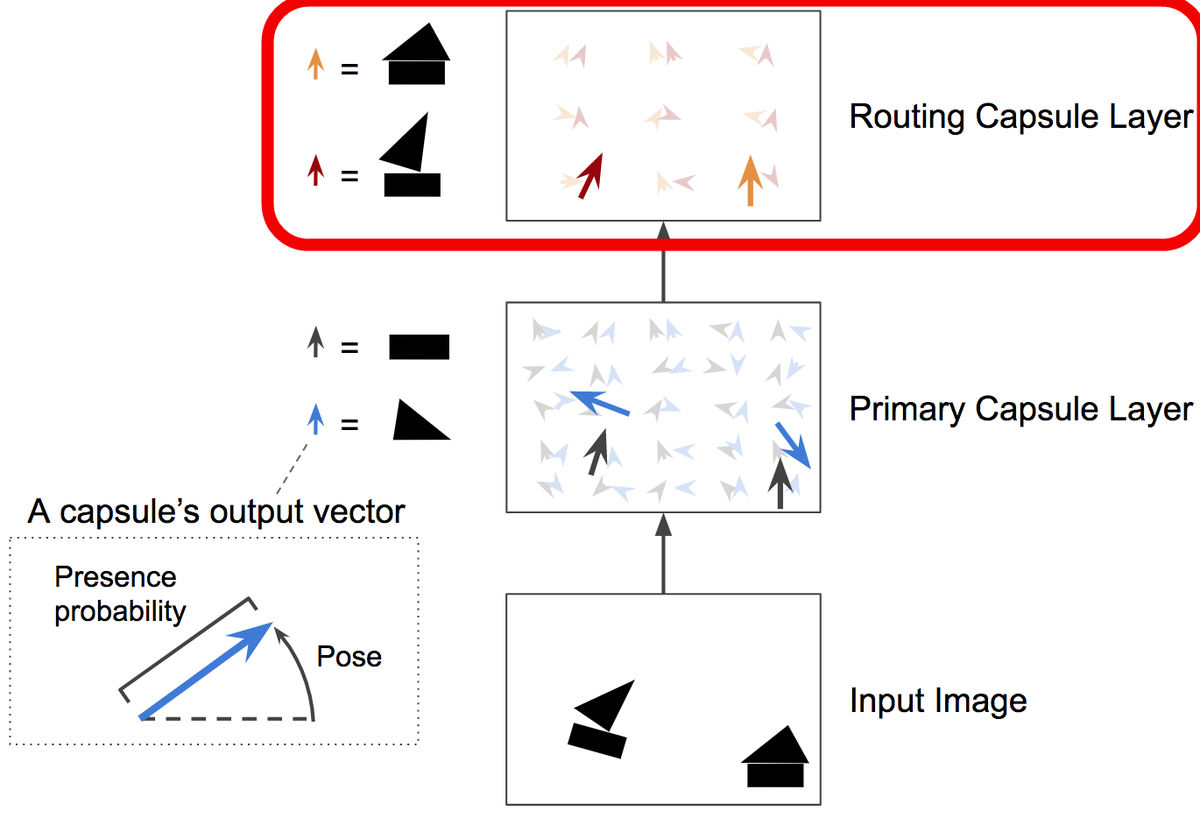
CapsNet's "capsule" means information about an object, and it shows what shape and position it is in. There are 50 capsules in the red frame, and the capsule at the position where the object actually exists increases. This capsule is called "Primary Capsule Layer".
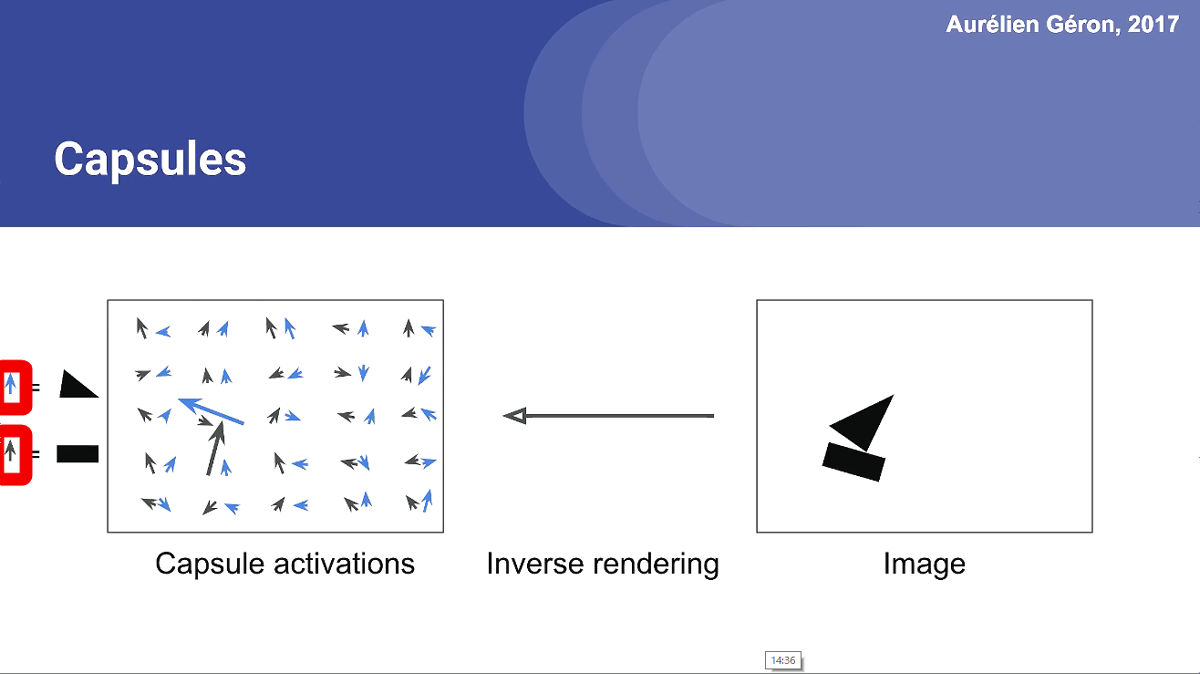
The orientation of triangular and rectangular objects is represented by two vectors each in the capsule. In other words, rectangles and triangles exist at the position of this large arrow, and by arranging figures in the same direction, it becomes like a boat.
Furthermore, paying attention to the relationship between rectangular and triangular capsules, there is also a "Routing Capsule Layer" in the upper layer that combines multiple capsules and detects complex objects. In this example, let's consider an example of recognizing images of "boat" and "house" which are a combination of a triangle and a rectangle.
In "Routing Capsule Layer" we use a slightly strange algorithm called "Routing by Agreement". In this example, the shape of a combination of a rectangle and a triangle will be either a house or a boat, but when figures are made based on the state that the rectangle and the triangle rotate slightly to the right slightly, the lower image As the probability of becoming a boat increases like ... ....
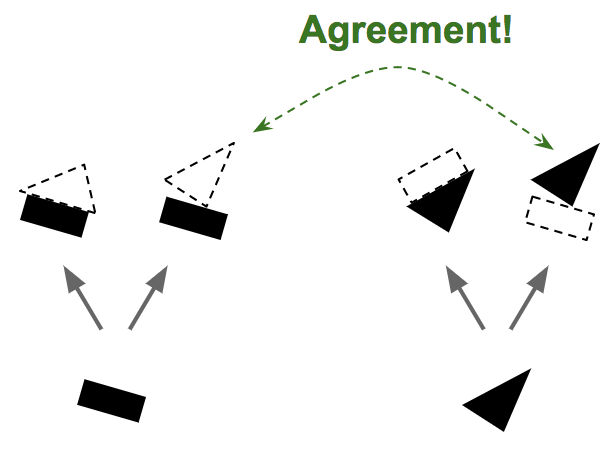
In this positional relationship, it is interpreted that the relationship between the rectangle and the triangle tends to be in the form of a boat, and in the case of the boat shape in the "Routing Capsule Layer", a strong arrow is drawn and the priority in the image recognition becomes high .
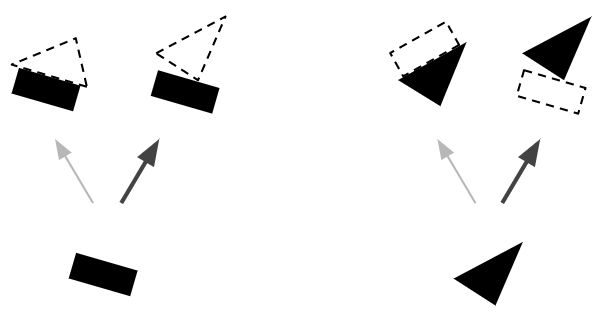
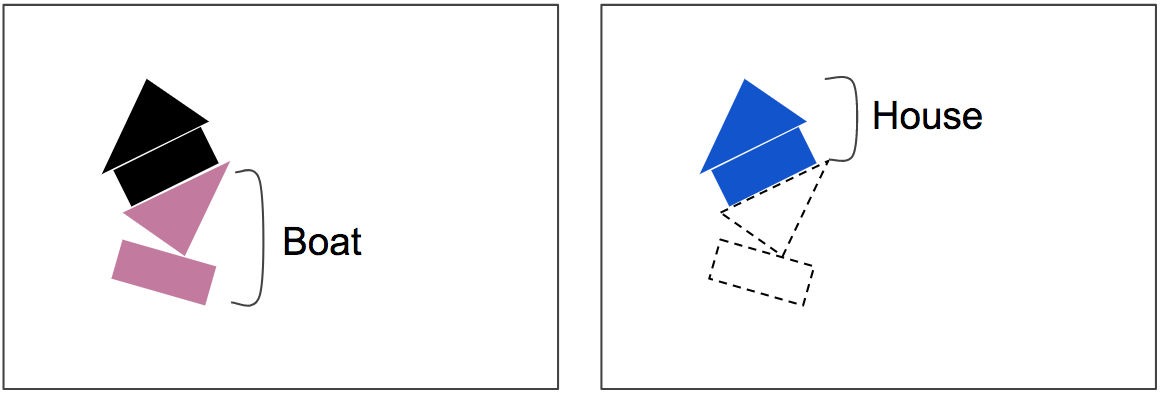
In other words, when reading the following images with CapsNet ......

If you recognize the middle rectangle and the opposite triangle as a house, you can not explain the top triangle and the bottom rectangle ... ...
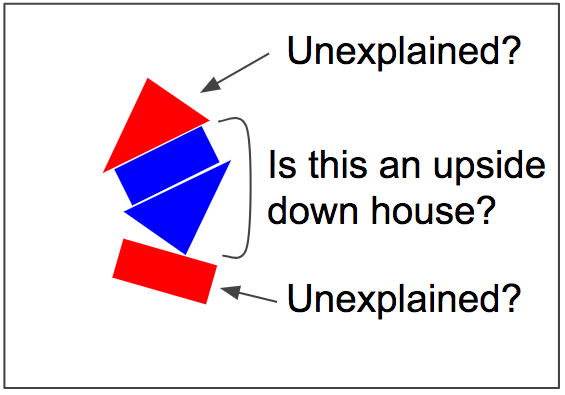
Because of the "Routing by Agreement" earlier, there is a strong correlation that it becomes a boat from the angle of the bottom rectangle, so the lower two figures are easier to recognize the boat and the upper two figures are the house.
Related Posts:





in Software, Posted by darkhorse_log