An artificial intelligence research organization "OpenAI" publishes a robot that learns by seeing only human behavior once and then can reproduce the same behavior and result in different environments

OpenAI, a nonprofit organization that studies artificial intelligence, is a robot that can perform tasks even if human beings only demonstrate once "guess the purpose of action" and change the environmentRobots that Learn"Has been announced.
Robots that Learn
https://blog.openai.com/robots-that-learn/
You can see how great Robots that Learn is from the following movie.
Robots that Learn - YouTube
Take your tongue in front of a baby's eyes about 10 minutes after birth ... ....

The baby imitates it and puts out his tongue. It was announced in March 2017One-Shot Imitation LearningAs with this behavior, it is an algorithm with "Imitation" as the key, it is possible to teach the robot "what to do" with a demonstration at a time.

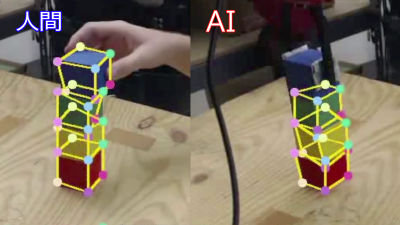
When a person teaching behavior to the robot performs a task of "building up 6 towers by building 6 towers" through VR ... ...

The robot can understand the purpose of the task "build a single tower by stacking six blocks" with one demonstration and then perform the task even if the position where the block is placed changes. Generally it is very difficult for a robot to stack the six blocks of various arrangements together to create the same result of "making one tower".

Of course, even if you change the placement, the order of building blocks is the same.
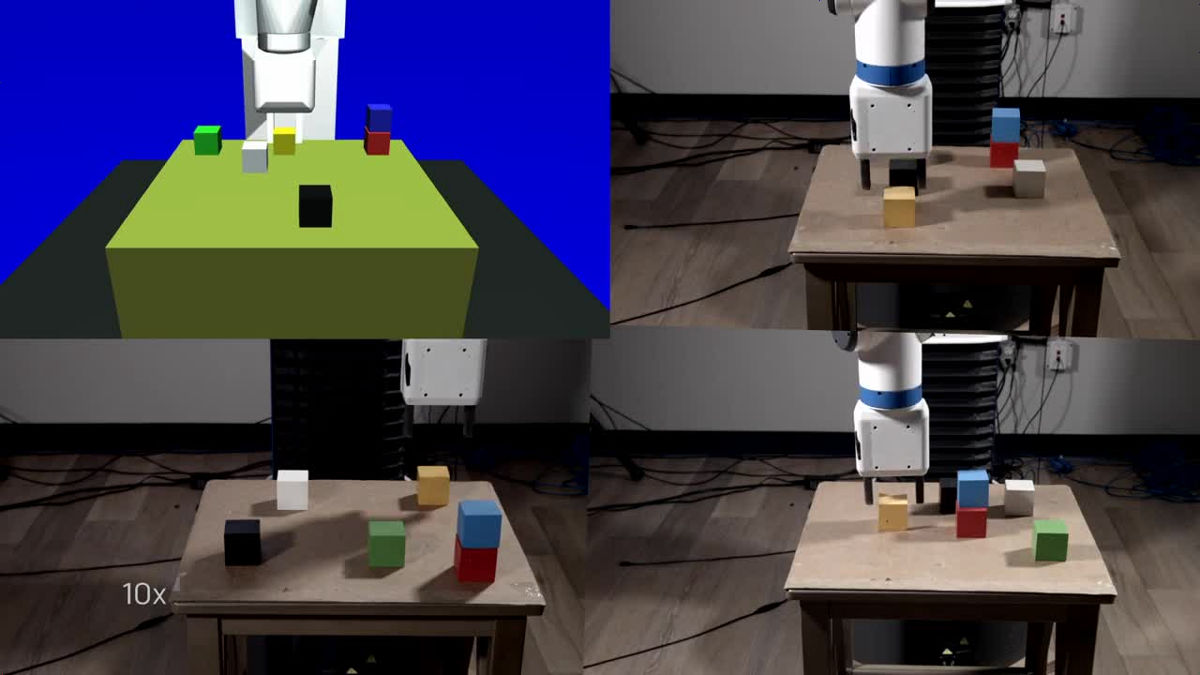
If you want to change the type of task, such as "make 3 towers with 2 blocks stacked together", you can demonstrate once each time OK.

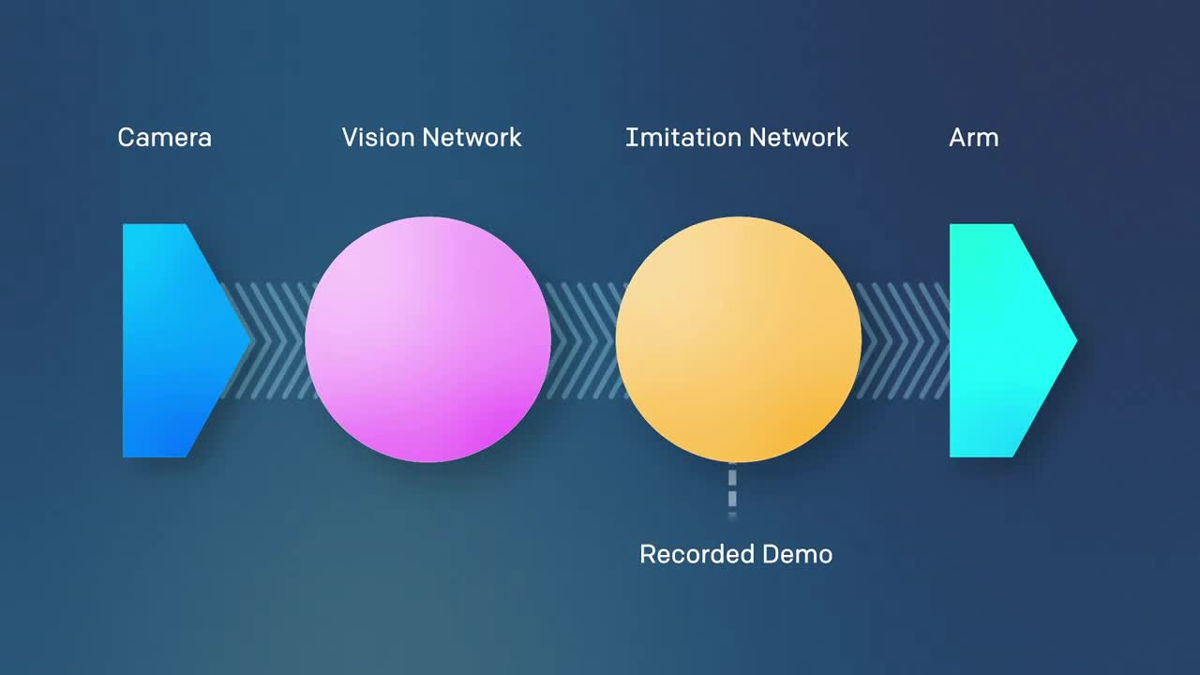
The mechanism is as follows. As the robot is equipped with a camera, the robot first recognizes the environment using the camera, and then performs the task with the arm.
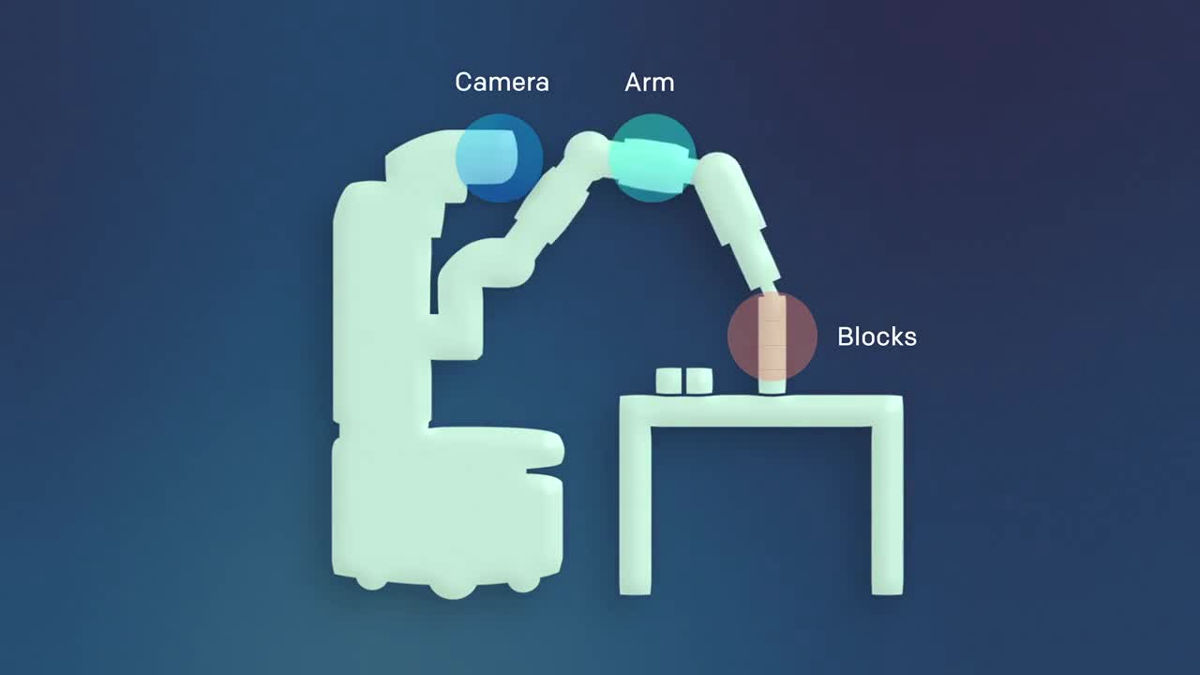
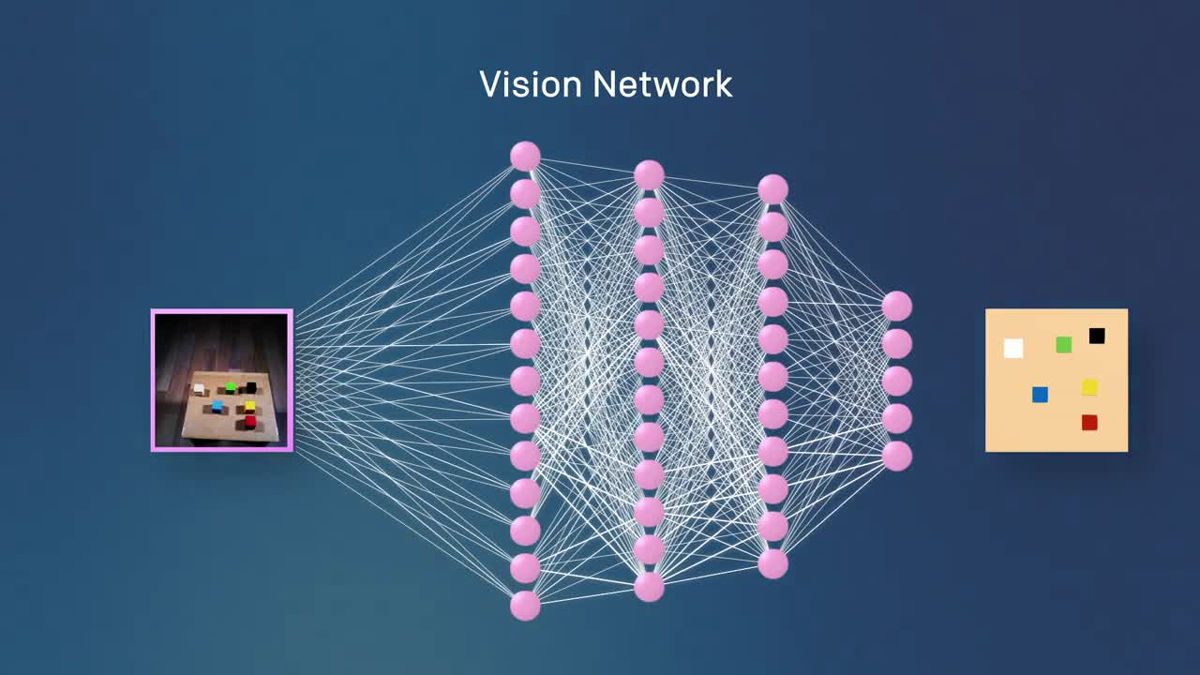
Two robots are installed, "Vision Network" and "Imitation Network", and images captured by the camera are processed by the Vision Network.
The Vision Network has been learned using hundreds of thousands of images that have changed conditions such as lighting, texture, and objects in advance, from which it determines the type, placement and state of the object placed in the real environment .
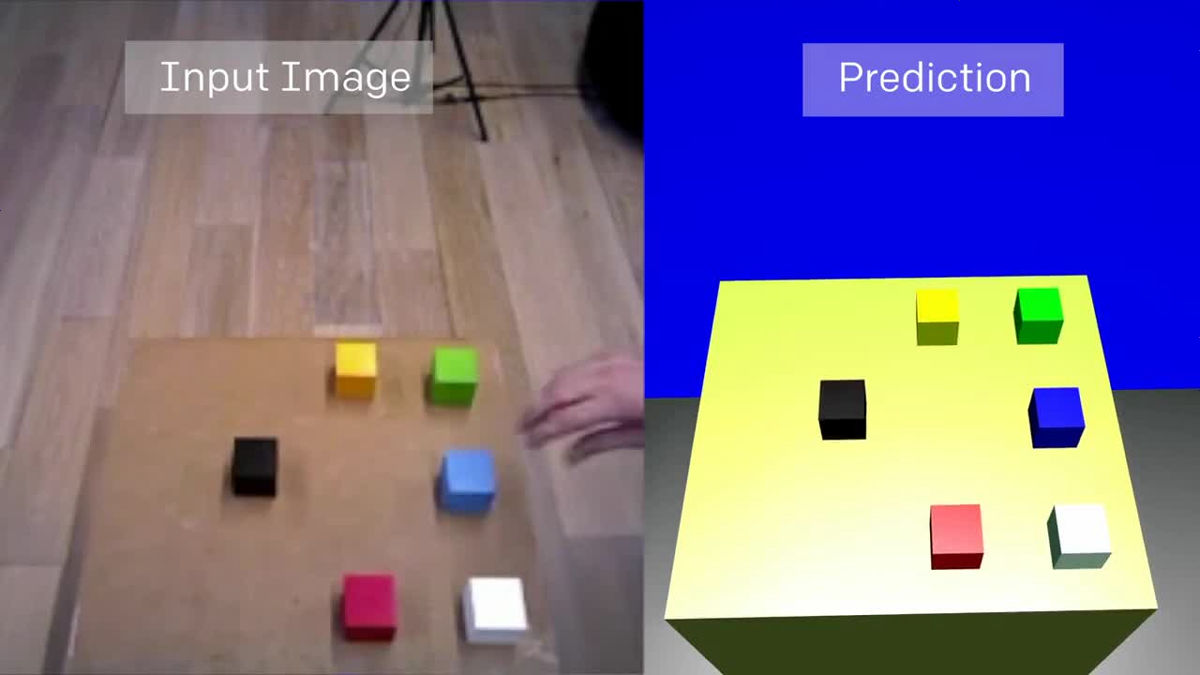
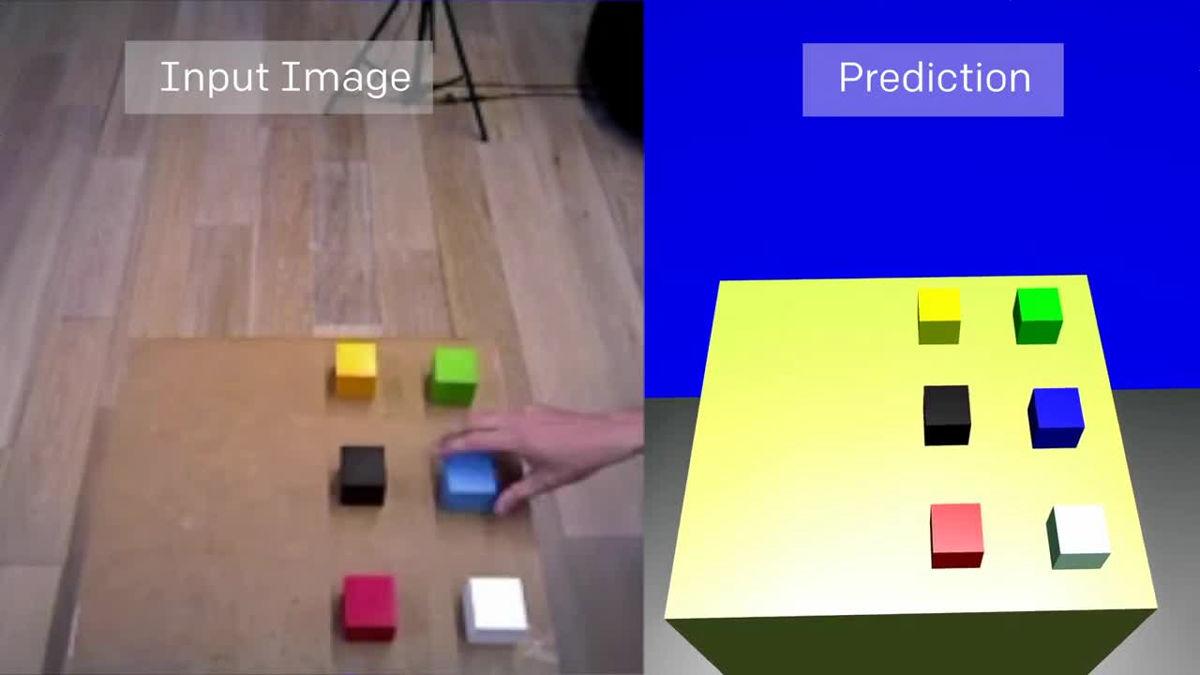
At this time, what is used for Vision Network learning is not an actual image, but animation data as follows.

After learning, the robot will be able to detect changes in its placement even if you randomly change the position of the colorful box on the desk. Even if it is a form that I have never seen through a camera.
After that, the Imitation Network inherits the data of Vision Network.
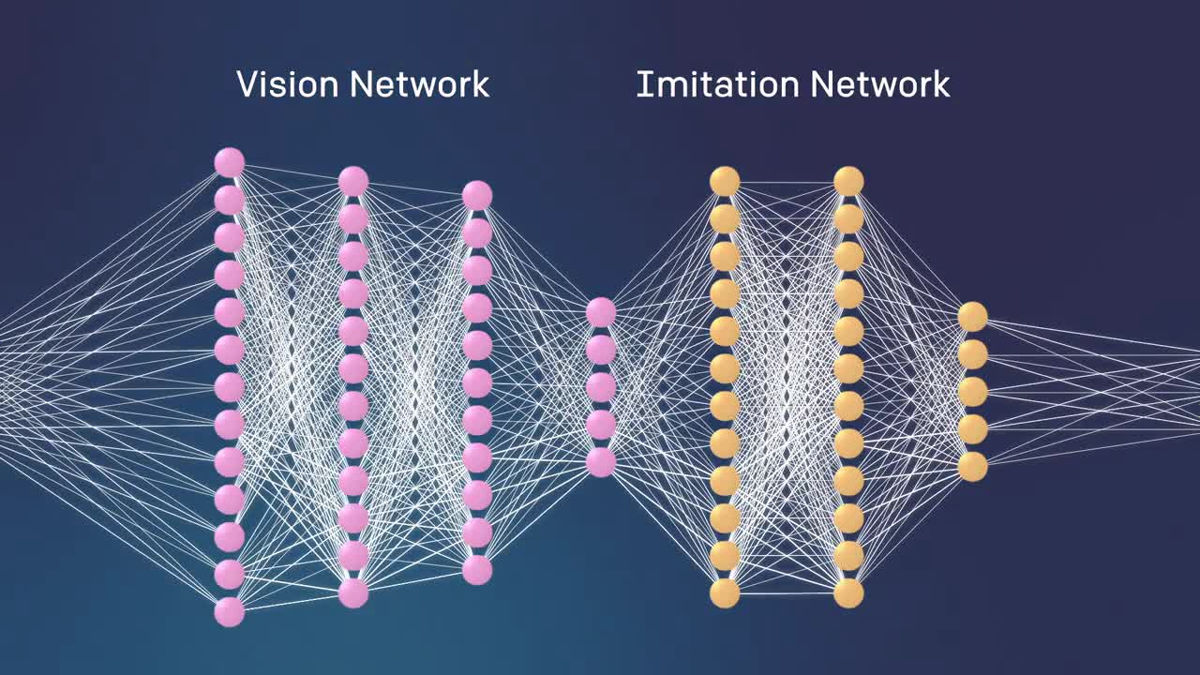
The Imitation Network processes information on what is being done in the demonstration and guesses what the purpose of the task is. Since "purpose" is guessed rather than merely imitating the movement, even if the position of the block is different, the task can be completed.

Related Posts: