An easy-to-understand illustration of 'What is a convolutional neural network?'

I've seen more and more terms like AI, machine learning, and neural networks, but it's hard to understand what they really are.
What Are Convolutional Neural Networks?
https://serokell.io/blog/introduction-to-convolutional-neural-networks
CNN is one of the neural networks and has an inseparable relationship with tasks related to image recognition and computer vision. In addition to image classification tasks such as MRI diagnosis and land classification for agriculture ...

It is also used in smartphones and familiar object detection.
Before understanding CNN, it is necessary to first understand the mechanism of neural networks. Neural networks are written in English as 'Neural Network' and are composed of

Neurons are usually organized in layers. The same applies to the nodes of a neural network. For example, in the case of a feedforward neural network (FNN), the information input from the 'input layer' goes through multiple 'intermediate layers' to the 'output layer' in a single direction. The signal is transmitted to.
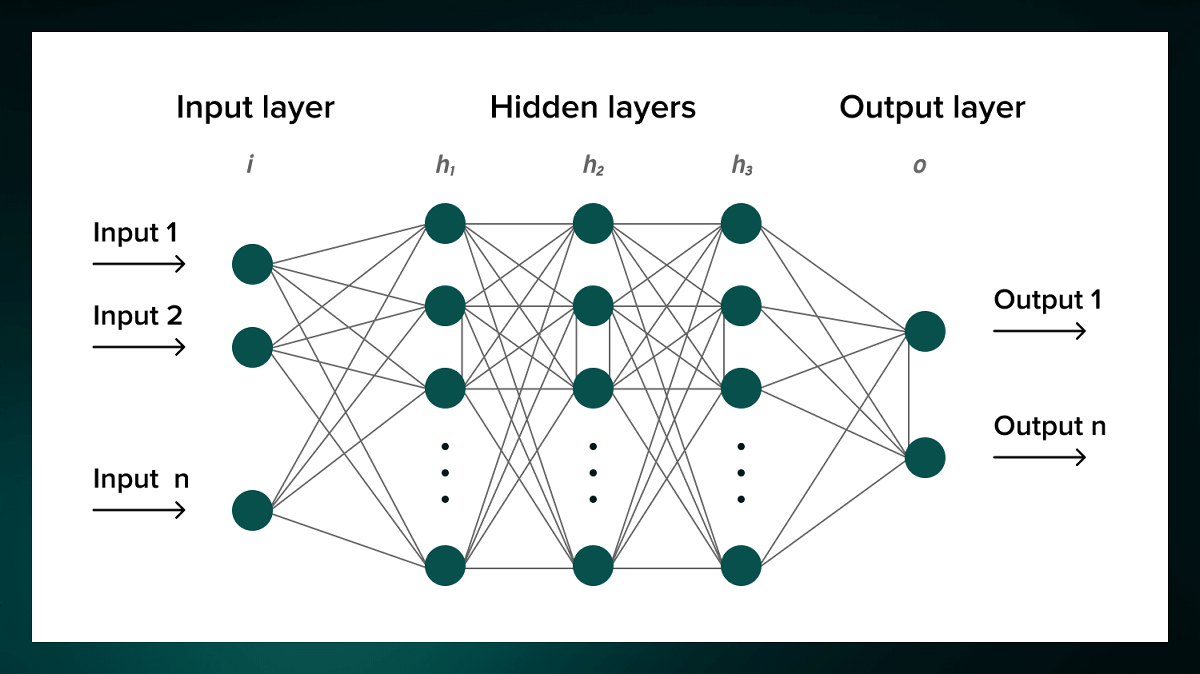
All nodes in the system are connected to the nodes of the previous and subsequent layers, receive information from the previous layer, do some processing on that information, and then send the information to the next layer. ..
At this time, 'weight' is assigned to all connections. In the figure below, the node at the top of the middle tier receives the information '0.8' and '0.2', which is multiplied by the factor '0.73'. The numbers that are multiplied when information is received from different nodes in this way are called 'weights'.
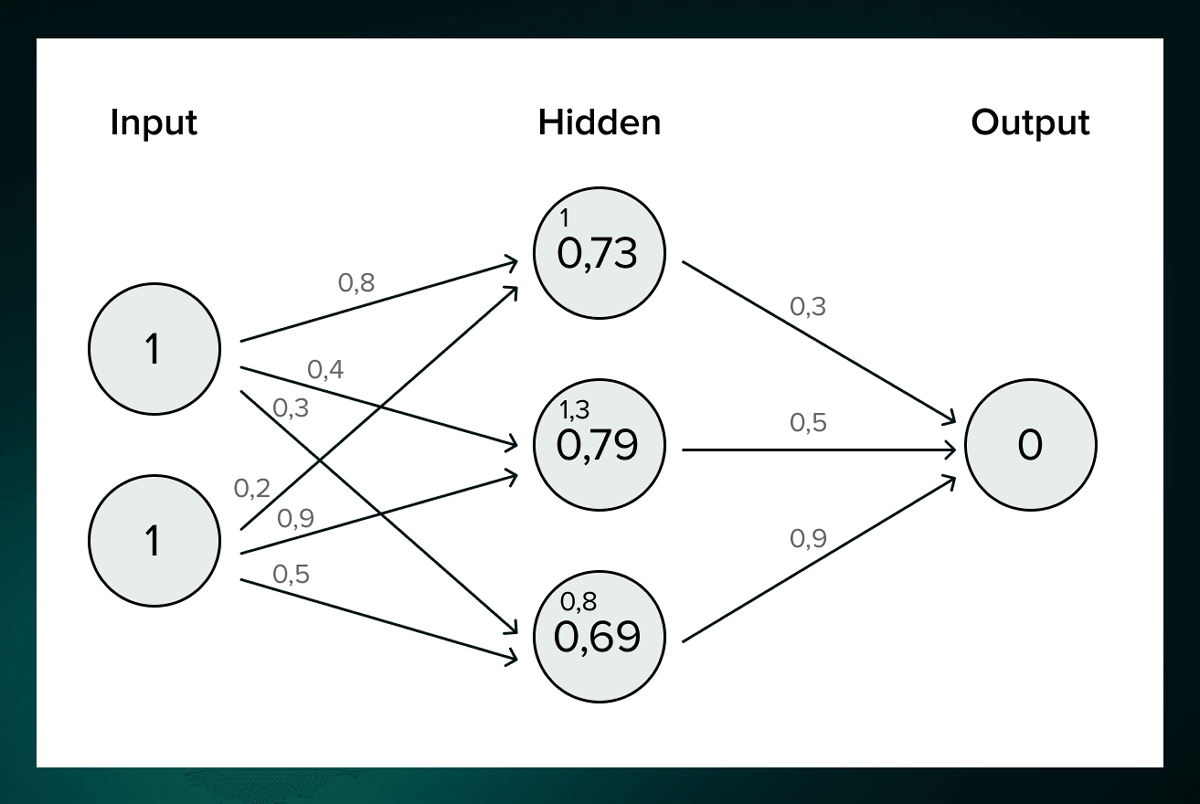
Normally, a node has multiple input values, and there is also a weight for each input value.
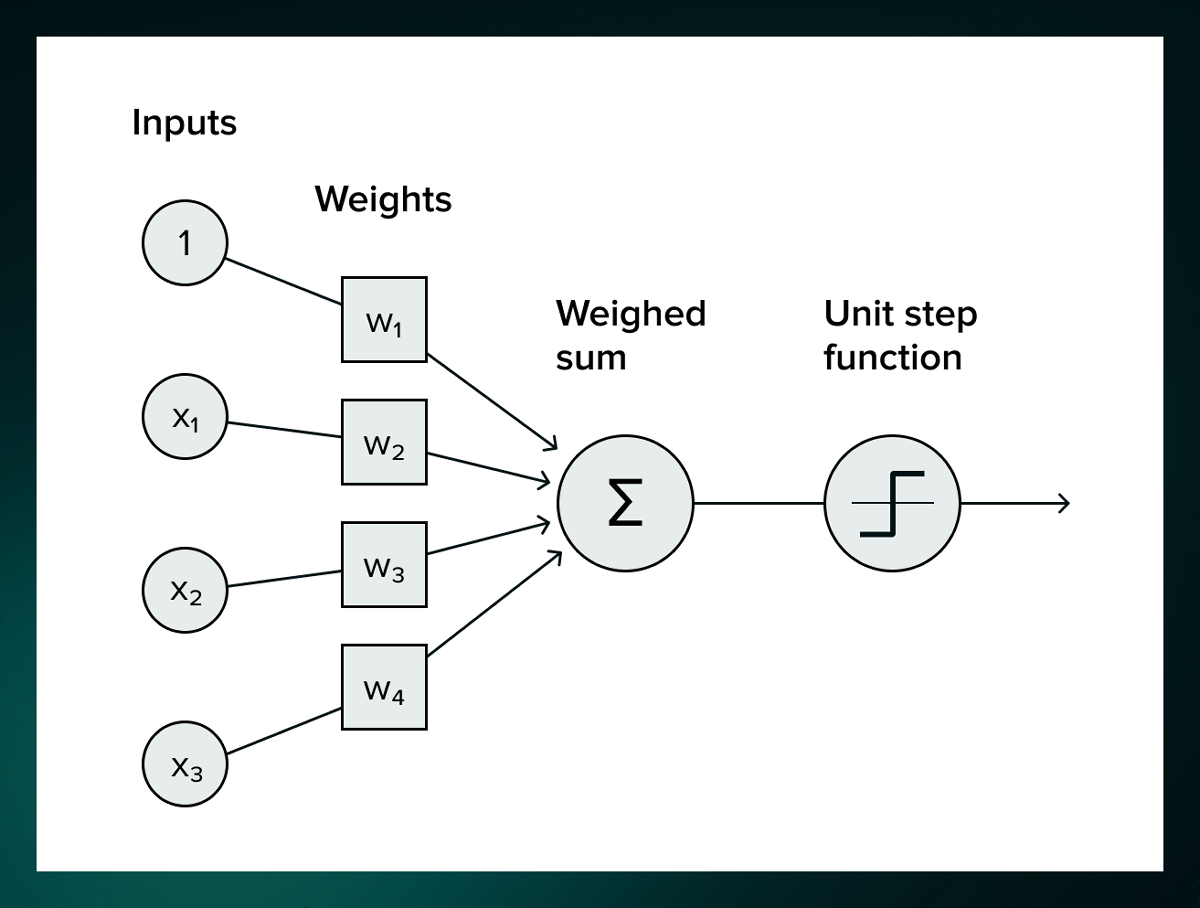
In addition, whether or not to pass the input to the next layer is also decided by each node, and there are cases where only the value of the node that exceeds the threshold value is passed to the next layer. When the neural network is trained for the first time, all weights and thresholds are randomly assigned, but then the weights and thresholds are adjusted so that 'the same output will be obtained when training data with the same label is input'. increase. This is called
Normal neural networks cannot process very large data. For example, computer vision training uses a dataset called 'CIFAR,' which contains images with 32 x 32 pixels and three color channels. In other words, in this case, the neural network weights 32 x 32 x 3 = 3072. However, when the image becomes 300 x 300 pixels, it will be weighted as much as 270,000, which not only requires enormous computational power for training, but also only stores the data set due to the large number of parameters, resulting in overfitting. It tends to be.
On the other hand, CNN reduces the calculation load by using the mathematical concept and convolution of 'combining multiple pieces of information'. The figure below shows the convolution process, and features are extracted from the left figure (Input) consisting of 5 x 5 squares using the right figure (Filter / kernel) of 3 x 3 squares. Extracting features in this way is the convolutional process in CNN.
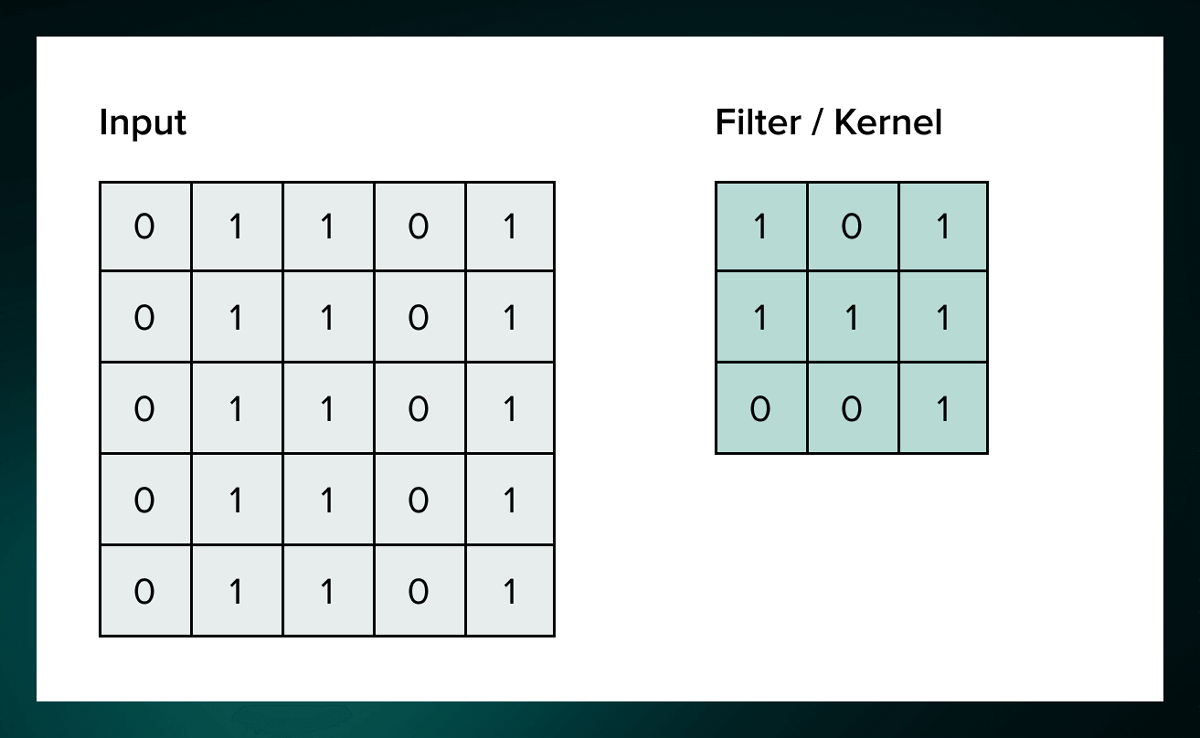
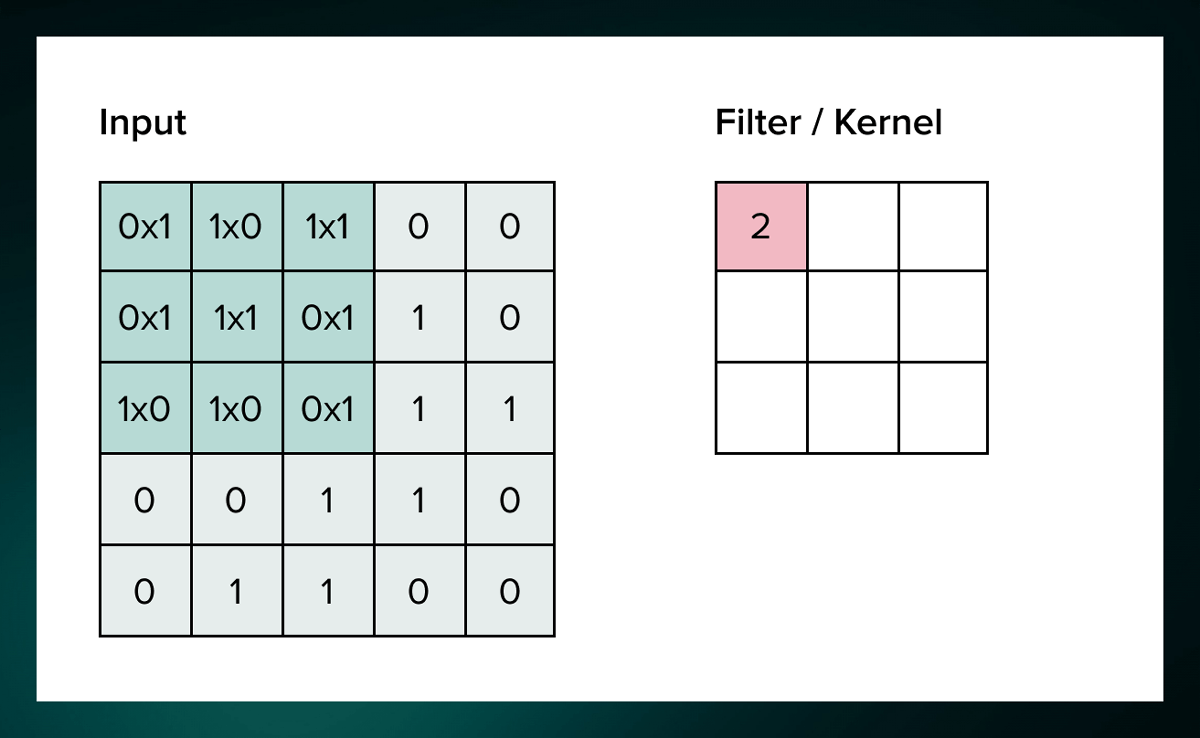
A filter called the kernel is used to extract features. In the figure below, the features of the 9 squares painted in dark green in the left figure are extracted by the filter, and the pink part marked '2' in the right figure is written out. Then, the work of 'the characteristics of 3x3 squares out of 5x5 squares are expressed as 1 square' is repeatedly executed for other squares while sliding the filter.
CNN's architecture basically consists of three layers: a convolution layer, a pooling layer, and a fully connected layer. The convolution layer recognizes the feature in the pixel by the above processing, the pooling layer abstracts the extracted feature, and the fully connected layer uses this feature for prediction.
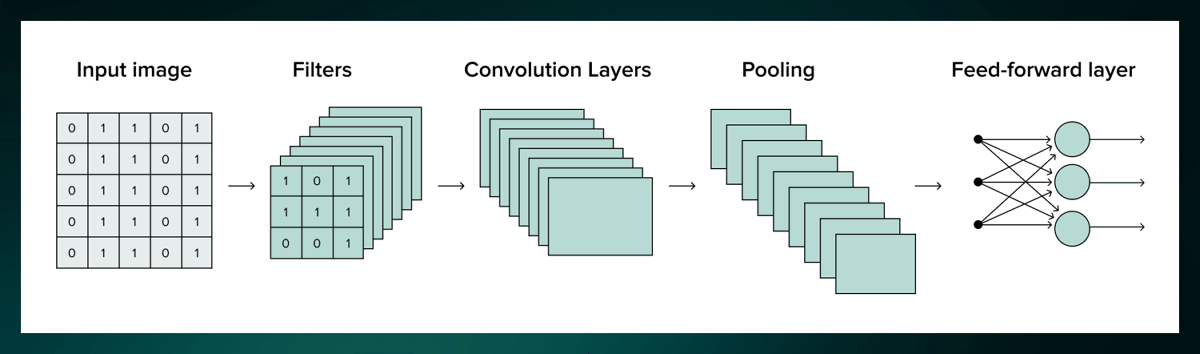
Performing a convolution produces a large amount of data, which makes training neural networks difficult. Therefore, it is necessary to compress the data in the pooling layer.
CNNs have the advantage of being more computationally efficient than regular neural networks and more accurate than non-convolutional neural networks. On the other hand, it also has the disadvantage of being susceptible to 'hostile attacks' that trick the input data into producing incorrect output. This could allow criminals to trick CNN-based facial recognition systems into passing through security systems. It is also said that a large amount of training data needs to be collected and preprocessed, which hinders the spread of technology.
Related Posts:






in Science, Posted by darkhorse_log