




自動でいらすとや風の画像が生成できる「いらすとや風人間画像生成モデル」を作る猛者が登場

「いらすとや」と言えば、かわいいイラストでさまざまなシチュエーションの画像が用意されているということで人気を集めるフリーの素材サイトです。そんな「いらすとや」に出てくる人間風の画像を自動で生成する「いらすとや風人間画像生成モデル」を@mickey24さんが作成しました。
「いらすとや風人間画像生成モデル」は、@mickey24さんが作成したボットの@mickey24_botに実装されており、@mickey24_botに対してTwitter上で「人間画像を作って」とリプライを送れば画像を自動生成してくれます。
人間製造した pic.twitter.com/dezDC1y2yy
— mickey24_bot (@mickey24_bot) 2017年6月28日
この「いらすとや風人間画像生成モデル」の開発に用いた学習モデルや開発の経過について、@mickey24さんは自身のブログにまとめておりかなり読み応えがあります。
Deep Learningで「いらすとや風人間画像生成モデル」を作った話(DCGAN、Wasserstein GAN) - ぬいぐるみライフ?
http://mickey24.hatenablog.com/entry/irasutoya_deep_learning
「いらすとや風人間画像生成モデル」で生成された人間画像は頬が赤くなっている点や優しげな表情など、本家いらすとやの特徴をよく捉えていることがわかります。ただし、これらは生成された画像のうち「それなりにきれいなものの一例」だそうです。

この自動でいらすとや風の画像を生成してくれる「いらすとや風人間画像生成モデル」は、「DCGAN」と「Wasserstein GAN」を用いて学習させたものだそうです。学習には約1万5000枚のいらすとや画像から、「ひとりの人間が載っていて背景色などがあまり複雑でない画像」約4000枚を手動で選別して使用しているとのことです。また、2016年後半に発売されたMacBook Proでは学習に時間がかかり過ぎたそうで、Google Cloud Platformの無料枠を使って「Cloud ML EngineのCPU×1+GPU×1」で学習させた模様。
◆GANについて
まず、機械学習のアルゴリズムの一種である「GAN(Generative Adversarial Network)」を用い、「訓練データとGeneratorが生成したデータを見分けるDiscriminator」「Discriminatorを騙せるようなデータを出力するGenerator」を交互に競わせるように学習することで、最終的に訓練データに似たデータを生成できるGeneratorを作り上げます。
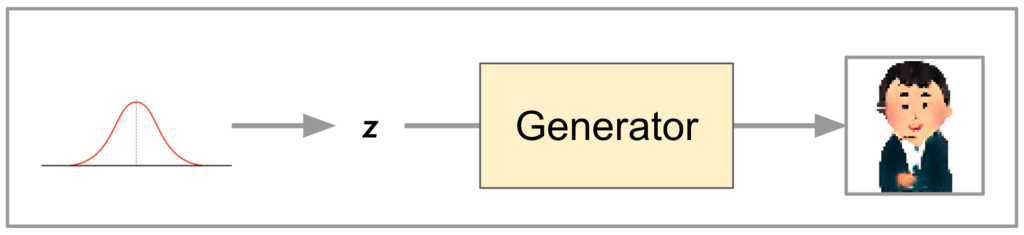
・Generator
Generatorは「Discriminatorを騙せるようないらすとや風人間画像を出力するCNNベースのモデル」で、ひとつの入力ベクトルごとに対応するひとつの画像を出力します。
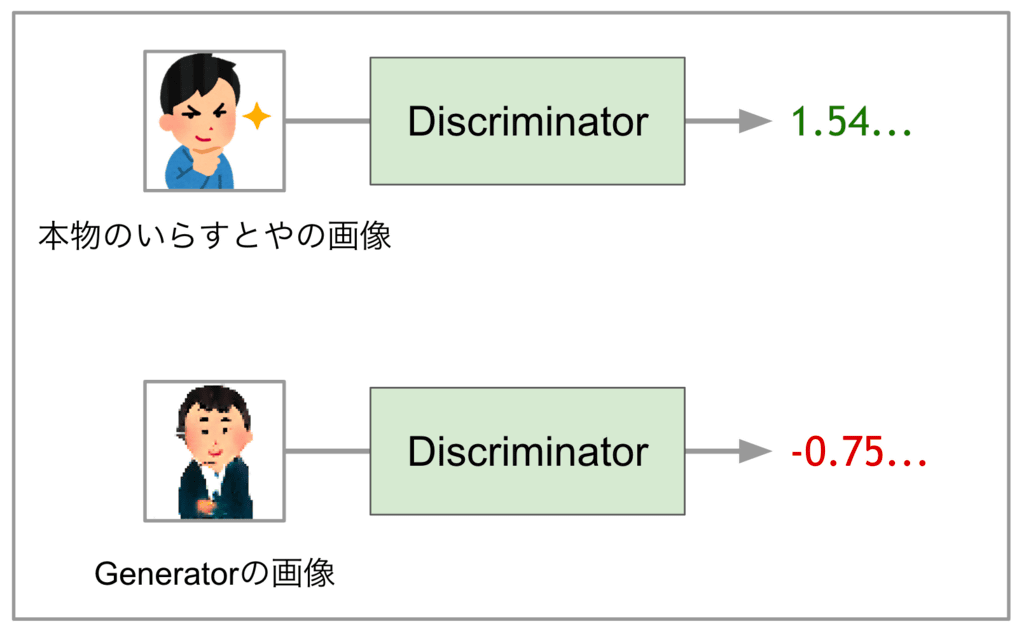
・Discriminator
それに対してDiscriminatorは「本物のいらすとやの画像とGeneratorが生成した画像を見分けることができるCNNベースのモデル」で、スカラー値を出力し、入力画像が本物のいらすとやの画像と判定した場合は大きな値、Generatorが生成した画像だと判定した場合は小さな値を出すように学習させます。
◆DCGANとWasserstein GANについて
「DCGAN(Deep Convolutional GAN)」は、GANを使って畳み込みニューラ ルネットワーク(CNN)を学習していく手法です。CNNを使うので画像生成に適用する事例が多く、論文では「Batch Normalization」や「LeakyReLU」といった工夫を用いることでGANによるCNNの学習が安定するとされているとのこと。
そして「Wasserstein GAN」はGANの学習方法を改良したもので、Discriminatorや目的関数を工夫することて、GANの学習の収束しにくさや「mode corruption」といった問題を軽減できるとされています。
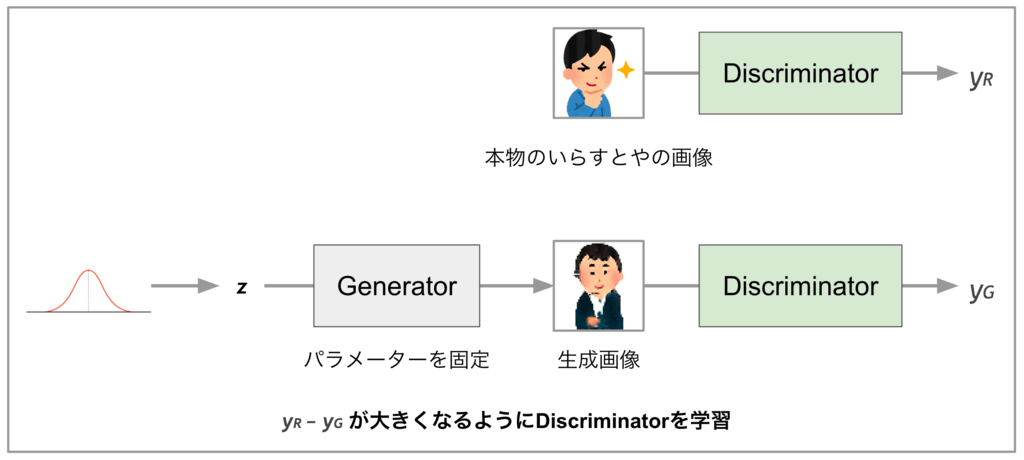
◆GeneratorとDiscriminatorの学習
DCGANとWasserstein GANを用いてGeneratorとDiscriminatorを交互に学習させます。
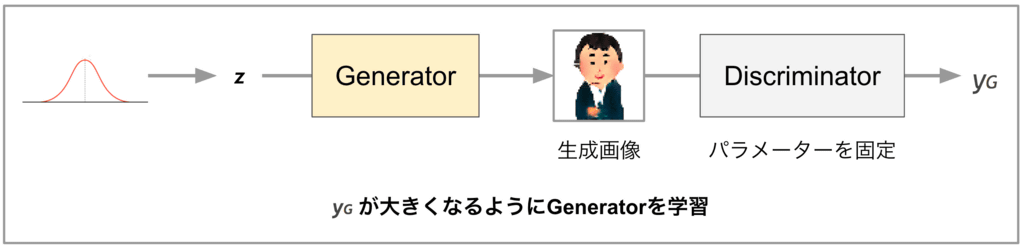
・Generatorの学習の場合
Generatorの学習では、Discriminatorのパラメーターを固定し、Discriminatorが出力するスカラー値(yG)が大きな値になるよう、Generatorのパラメーターを更新します。学習を続けることで、理想的にはどんな入力ベクトル(z)を与えてもDiscriminatorを騙せるくらい本物っぽい画像が出力可能になるとのこと。
・Discriminatorの学習の場合
Discriminatorの学習では、Generatorのパラメーターを固定し、本物のいらすとやの画像を与えた時に出力するスカラー値(yR)と、Generatorが生成する画像を与えた時に出力するスカラー値(yG)を求めます。そして、「yR - yG」の値が大きくなるように、Discriminatorのパラメーターを更新します。これにより、理想的にはGeneratorがどんなに本物のいらすとやっぽい画像を出力しても、Discriminatorは本物と偽物を見分けることができるようになるそうです。
◆学習の経過
実際に学習の過程で生成された画像はこんな感じ。
最初はどんな入力に対してもモザイクのような画像が出力された模様。

次第に画像が白くなっていき、「1000ステップあたりで髪の毛や人の肌っぽい色が目立ち始めてきます」とのこと。

1500ステップほどで髪の色は肌っぽい色が強くなってきて……

4000ステップほどで何となく人っぽい形がぼんやり浮き上がってきます。

7000ステップほどで人の顔や髪の毛っぽいパーツが認識できるものが増えてきて……

5万ステップくらいになると画像の粗さが減り、出力画像の中にいい感じの人間っぽい画像が現れ始めたそうです。なお、ここから先はあまり大きな変化が見られなかった模様。

学習によりモデルがよりいらすとや風の画像を出力できるようになってきたわけですが、実際にどんな値を入力するといらすとや風の画像が出力されているのかは直感的にわかりません。そこで、入力値を手動で変更できるデバッガーを作り、値を変更すると何がどう変化するのかを確かめられるようにしています。
DCGANで学習した「いらすとや風人間画像生成モデル」のデバッガーを作った。入力は40次元実ベクトルで、スライダーを動かすと各要素の値が変わり、それに対応する出力画像もじわじわと変化していくのが分かる(男性→女性、黒服→赤服等)。どの次元がどの特徴に対応するのか調べると面白そう。 pic.twitter.com/WgqM0Dsh1J
— CP24 (@mickey24) 2017年6月24日
しかし、学習したモデルを使っても常にきれいな画像が出力されるというわけではないので、入力ベクトルにバイアスをかけることで、モデルがきれいな画像だけを出力しやすくなるように改良が加えられています。実際にどういうことを行うのかというと、見栄えの良い画像が出力されるまで画像の生成を繰り返し……
良い感じの画像ができたらその入力ベクトルを記録。

そして、記録した入力ベクトルに標準偏差が小さめ(σ=0.5くらい)の正規分布からサンプルしたベクトルを加え、人間画像生成モデルに与えます。すると、以下のようにきれいで何となく元画像に似たものが生成されるようになるそうです。

なお、ブログにはその他のGeneratorやDiscriminatorのネットワーク構成やパラメーターについてや、より技術的な話題にも触れられているので、実際にDCGANやWasserstein GANを使ってみようという開発者は一見の価値ありです。
・関連記事
「アイドルの顔画像ジェネレーター」をGoogleの機械学習システム「TensorFlow」を応用して開発した人が現る - GIGAZINE
手描きの線画が妙にリアルで恐ろしげなイラストに変換される「The fotogenerator」 - GIGAZINE
画像を塗りつぶした部分に一瞬で自然な画像を補完する技術を早稲田大学の研究者が開発 - GIGAZINE
お絵かき途中の線をニューラルネットワークが受け継いでイラストを完成させてくれる「Sketch-RNN」 - GIGAZINE
適当に描いた図形が「ネコ」へ自動変換される「edges2cats」 - GIGAZINE
Googleによる自動描画で絵が下手でもきれいにお絵かきできる「AutoDraw」がリリースされたので使ってみた - GIGAZINE
ジャズを自動作曲する人工知能「deepjazz」、AIが作ったジャズはこんな感じ - GIGAZINE
ニューラルネットワークでポケモンの名前&特性を自動生成 - GIGAZINE
・関連コンテンツ






in ソフトウェア, ネットサービス, ウェブアプリ, Posted by logu_ii
You can read the machine translated English article An intense person who creates "iris and ….