An intense person who creates "iris and a wind human model image generation model" that can generate animation and a wind image can appear

"ITSUITOSpeaking of it, it is a free material site gaining popularity by having cute illustrations and images of various situations prepared. Automatically generate a human-like image that appears in such "Irtune"ITSUITO and Wind human image generation model"@ Mickey24Created.
"Inquiry and wind humanoid image generation model" was created by @ mickey24Botof@ Mickey 24 _ botIt is mounted on @ mickey24_bot and if you send a reply "Create a human image" on Twitter it will automatically generate images.
Man madePic.twitter.com/dezDC1y2yy
- mickey 24 _ bot (@ mickey 24 _ bot)June 28, 2017
About the learning model and the progress of development used for developing this "iris and wind humanoid image generation model", @ mickey24 is gathered on his blog and it is quite readable.
A story about making "Irisu and a wind human image generation model" at Deep Learning (DCGAN, Wasserstein GAN) - Stuffed Toy Life?
http://mickey24.hatenablog.com/entry/irasutoya_deep_learning
You can see that the human image generated by "Irisu and Human Human Image Generation Model" captures the characteristics of the original heading and so on, such as the point where the cheeks are red and the gentle expression. However, they are said to be "an example of pretty beautiful things" out of the generated images.

It is said that "Automatic injury and wind human model generation model" which generates animation and wind images is learned using "DCGAN" and "Wasserstein GAN". About 4000 copies of "images with a single person on it and background colors are not so complicated" are selected and used by learning about 15,000 sheets of learning for learning. Also, MacBook Pro released in the latter half of 2016 seems to take too long to learn, using the Google Cloud Platform free frame, it seems that I learned with "Cloud ML Engine CPU × 1 + GPU × 1".
About GAN
First, using "GAN (Generative Adverarial Network)" which is a type of machine learning algorithm, "a discriminator that discriminates between training data and data generated by Generator" and "Generator that outputs data that can trick Discriminator" By learning to compete, we will create a Generator that can eventually generate data similar to training data.
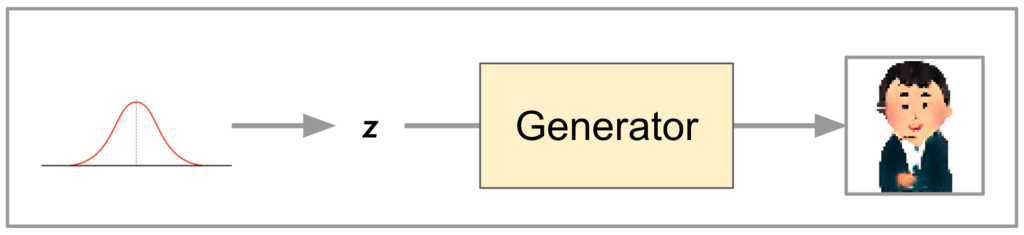
· Generator
The Generator is a "CNN-based model for outputting wind human images" as it can fool discriminators, and outputs one image corresponding to each input vector.
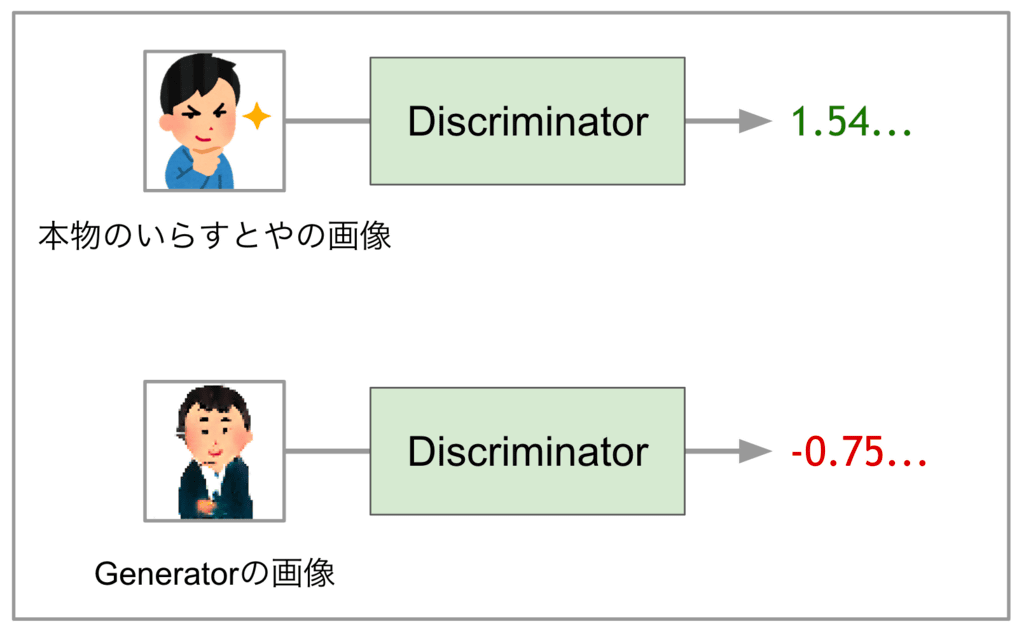
· Discriminator
To the contrary, the Discriminator is a "CNN-based model that can distinguish between real images of animated images and images generated by the Generator", outputs a scalar value, and if the input image is judged as an image of a genuine objective If it is judged that it is a large value, Generator generated image, learn to give small value.
About DCGAN and Wasserstein GAN
"DCGAN (Deep Convolutional GAN)", using GANConvolution neural network(CNN) is learned. Since CNN is used, there are many cases applied to image generation, and it is said that CNN learning by GAN is stabilized in the paper by using ingenuity such as "Batch Normalization" and "LeakyReLU".
And "Wasserstein GAN" is an improvement of the learning method of GAN, it is said that devising discriminator and objective function can alleviate problems such as difficulty of convergence of GAN learning and "mode corruption".
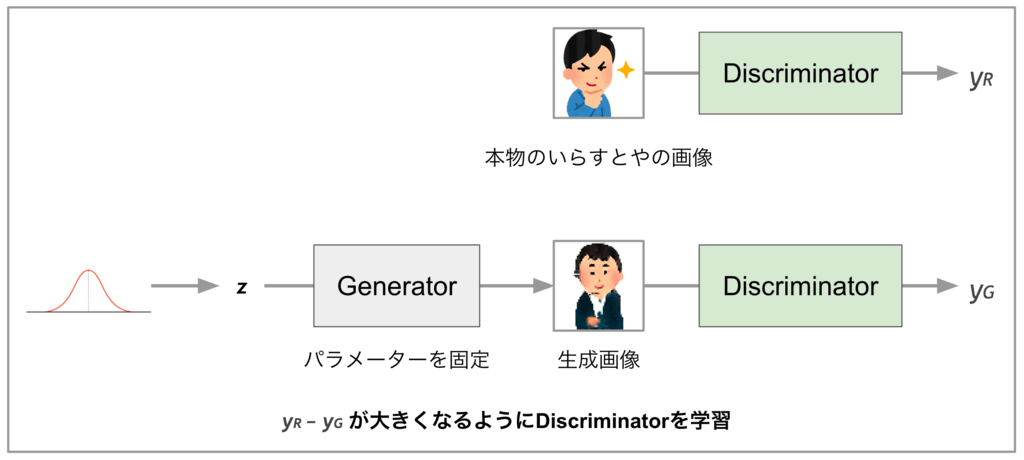
◆ Learning Generator and Discriminator
We will learn alternately between Generator and Discriminator using DCGAN and Wasserstein GAN.
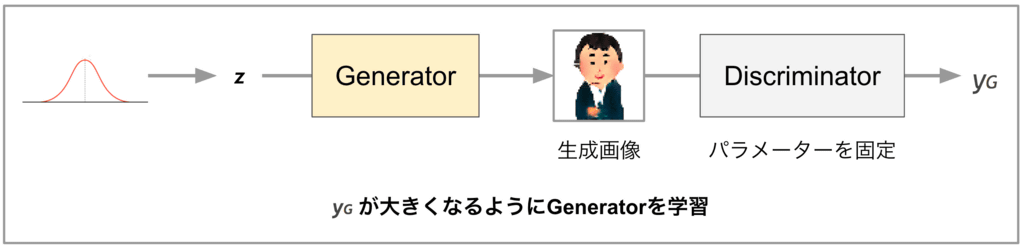
· When learning Generator
In Generator learning, we fix parameters of Discriminator and update Generator parameters so that scalar value (yG) output by Discriminator becomes large value. By continuing learning, Ideally it will be possible to output a realistic image enough to fool Discriminator whatever input vector (z) is given.
· In case of discriminator learning
In learning of Discriminator, we fix fixed parameters of Generator and find scalar value (yR) to be output when genuine inlay or image is given and scalar value (yG) to be output when giving the image generated by Generator . Then update the Discriminator parameters so that the value of "yR - yG" becomes larger. Ideally, no matter how genuine the generic or generous image is outputted by the Generator, the Discriminator seems to be able to distinguish real and counterfeit.
◆ Learning process
The image actually generated during the course of learning is like this.
At first, it seems that a mosaic-like image was output for any input.

The image gradually turns white, "Hair and human skinish color will start to stand out in 1000 steps."

In 1500 steps, the color of the hair is getting stronger with a skinish color ......

A somewhat human-like shape emerges vaguely in about 4000 steps.

More than 7000 steps can recognize human faces and hairy parts ... ...

The image roughness decreases when it is about 50 thousand steps, and it seems that a human-like image appears to be good in the output image. Moreover, it seems that there was not much change seen from here.

Learning has made it easier for models to output images of wind and wind, but I do not intuitively understand what kind of values actually entered and what the wind images are outputting. Therefore, we create a debugger that can manually change the input value, and change the value so that we can see what will change.
I have created a debugger "Irutu and a human-like image generation model" learned with DCGAN. The input is a 40 dimensional real vector. As you move the slider, the value of each element changes, and the corresponding output image also changes gradually (male → female, black clothes → red clothes etc.). It seems interesting to find out which dimensions correspond to which features.Pic.twitter.com/WgqM0Dsh1J
- CP 24 (@ mickey 24)June 24, 2017
However, since a beautiful image is not always outputted even when using the learned model, improvements have been made so that the model can easily output only beautiful images by applying bias to the input vector. What we actually do is repeat generation of images until a good-looking image is output ......
When you get a good feeling image record its input vector.

Then, add the sampled vector from the normal distribution with small standard deviation (σ = 0.5) to the recorded input vector and give it to the human image generation model. Then, it seems to be something like the following, which is somewhat similar to the original image.

Incidentally,blogIt is touched on other network configurations and parameters of Generator and Discriminator, and more technical topics, so the developer who actually wants to use DCGAN or Wasserstein GAN is worth a look.
Related Posts:







in Software, Web Service, Web Application, Posted by logu_ii