




Googleが画像の説明文章を自動生成する技術を開発

人間は写真を見てそれがどういった場面なのかを説明することができますが、これはコンピューターにとっては非常に難しいことです。しかし、Googleの研究者は機械学習システムを用いて一度写真を見れば自動でその状況を説明するようなキャプションを生成できる、というまるで人間のような能力を持ったシステムの開発に成功しています。
Research Blog: A picture is worth a thousand (coherent) words: building a natural description of images
http://googleresearch.blogspot.jp/2014/11/a-picture-is-worth-thousand-coherent.html
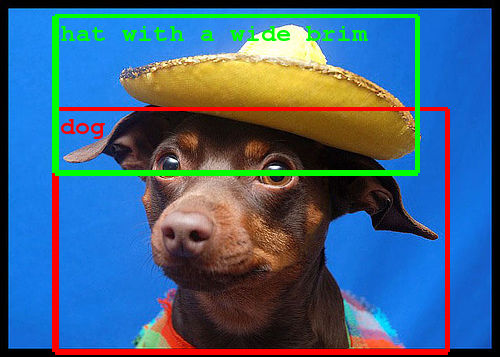
近年の研究では、物体の検出や分類、ラベル付けなどの技術が大幅に向上しています。しかし、人間のように複雑な状況を簡潔に説明するには、深い表現の幅と多種多様な物体を正確に認識し、それを自然な言葉で表す必要があります。
人の目の代わりに画像を認識して、物体を認識したり位置決め・分類・計測・検査などを行うようなシステムのことをマシンビジョンと言い、これは「機械の目」を作るための研究分野とも言われます。そんなマシンビジョンの最先端技術と、複雑な状況も適切に説明できる自然言語処理システムが合体すれば、素晴らしいシステムになるはず。
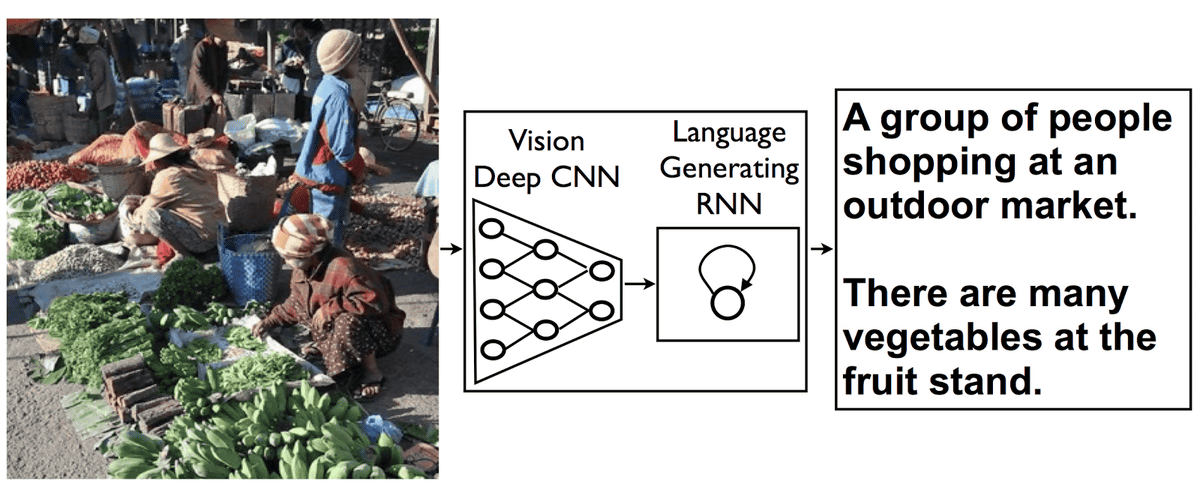
このアイデアを実現するために必要不可欠となるのが、人間の脳の機能を計算機上でシミュレートしようというニューラルネットワークの派生であるRecurrent neural network(RNN)です。このRNNを駆使して画像のイメージから文章や語句を生成し、写真にキャプションをつけます。
まず始めに「深層畳み込みニューラルネットワーク(CNN)」を用いた画像認識アルゴリズムで写真に映っている状況を解析させます。通常のCNNを使った画像認識アルゴリズムの場合、CNNの最終層では、写真の中の物体が何なのかをおおよその見込みで決めるための作業が行われるそうです。しかし、Googleの作成したシステムではこの最終層を削除し、代わりに言語生成のためのRNNを加えることで、大量に生成された画像に関する情報がRNNに供給されることになる、とのこと。そうすることで、既存の画像認識アルゴリズムが生成したデータを言語生成のためのRNNに上手く活用できるようになるわけです。
さらに、このシステムに直接さまざまな画像を認識させてキャプションを生成させることで、システムは機械学習により、より精度の高いキャプションを付けられるようになっていきます。Googleの研究チームではいくつものオープンデータベースの画像を処理させまくることで、キャプションの質を向上させることにも成功しています。
実際にGoogleのシステムが写真を解析して付けたキャプションは以下の通り。
・成功例
「A person riding a motorcycle on a dirt road.(泥道でオートバイに乗る人)」

「A group of young people playing a game of frisbee.(フリスビーで遊ぶ若者の集団」

「A herd of elephants walking across a dry grass field.(乾いた草原を歩く象の群れ)」

・小さなミスがあるキャプション
「Two dogs play in the grass.(芝生の上で遊ぶ2匹の犬)」:実際には3匹

「A close up of a cat laying on a couch.(ソファーの上で寝ているネコのアップ写真)」:アップではありません

・状況自体は正解に近いが単語単位で間違いがある
「A skateboarder does a trick on a ramp.(スケートボーダーがランプ上でトリックを決めている)」:ランプ上でトリックを決めているのはBMXのライダー

「A red motorcycle parked on the side of the road.(道路脇に駐車された赤いオートバイ)」:オートバイの色はピンクで、駐車しているのは駐車場

・失敗例
「A dog is jumping to catch a frisbee.(犬がジャンプしてフリスビーをキャッチしている)」:犬はジャンプしておらず、フリスビーもくわえていない

「A refrigerator filled with lots of food and drinks.(冷蔵庫の中は食べ物や飲み物でいっぱい)」:全くの別物

驚くべき画像認識システムと自然言語処理システムの合わせ技であるこのシステムは、将来的には視覚障害のある人が映像を見るのに役立ったり、インターネットの回線速度が遅い場所では写真よりも先にテキストで状況説明を送ることで画像を補完したり、さらにはGoogle画像検索の検索精度を向上させることにも大いに役立つと見られています。
・関連記事
Google Glassで目の前の人を自動で顔認識しリアルタイムに情報が見える「NameTag」 - GIGAZINE
Googleが3Dカメラとセンサーで人間レベルの空間認識能力を備えたスマホのプロトタイプを発表 - GIGAZINE
自動運転を実現するGoogleの自動運転車の外界認識センサーはこんなにある - GIGAZINE
ターミネーターのような高度な画像認識が機械で可能になるのか? - GIGAZINE
・関連コンテンツ








in メモ, Posted by logu_ii
You can read the machine translated English article Google develops technology to automatica….