




複数の写真から3Dシーンを生成するAIモデル「ArtiFixer」をNVIDIAが発表、写真にない部分も生成処理で補完可能

NVIDIAが複数の写真から3Dシーンを生成できるAIモデル「ArtiFixer」を開発しました。ArtiFixerは動画生成AIのWan 2.1をベースに開発されており、参考画像に含まれていない部分を生成処理で補って高品質な3Dシーンを作り出すことができます。
ArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models
https://research.nvidia.com/labs/sil/projects/artifixer/
nvidia/ArtiFixer · Hugging Face
https://huggingface.co/nvidia/ArtiFixer
3D scene reconstruction works great until the camera never sees part of the scene.
— NVIDIA AI (@NVIDIAAI) June 22, 2026
ArtiFixer from NVIDIA Research is an open autoregressive model that fills in the missing geometry that other methods leave blank.#SIGGRAPH2026 paper, code + demo: https://t.co/D9PX2OzbZf pic.twitter.com/AGQicvVKkW
複数枚の写真をもとに3Dシーンを生成する手法として「3Dガウススプラッティング」という技術の研究が進んでいますが、従来の3Dガウススプラッティングシステムには「シーンの一貫性を保てないことが多い」「写真に写っていない部分の表現が破綻してしまう」という問題が存在しています。ArtiFixerはWan 2.1をベースに開発された約169億パラメーターのAIモデルで、「写真に写っていない部分を生成して挿入する」という仕組みで3Dシーンの高品質化に成功しています。
ArtiFixerの学習は2段階に分かれて実施されており、第1段階では「写真に写っていない部分を生成して挿入する機能を持ったAIモデル」へとトレーニングされ、第2段階では「1つのフレームから数百のフレームを生成する自己回帰モデルへの蒸留」というトレーニングが実施されました。
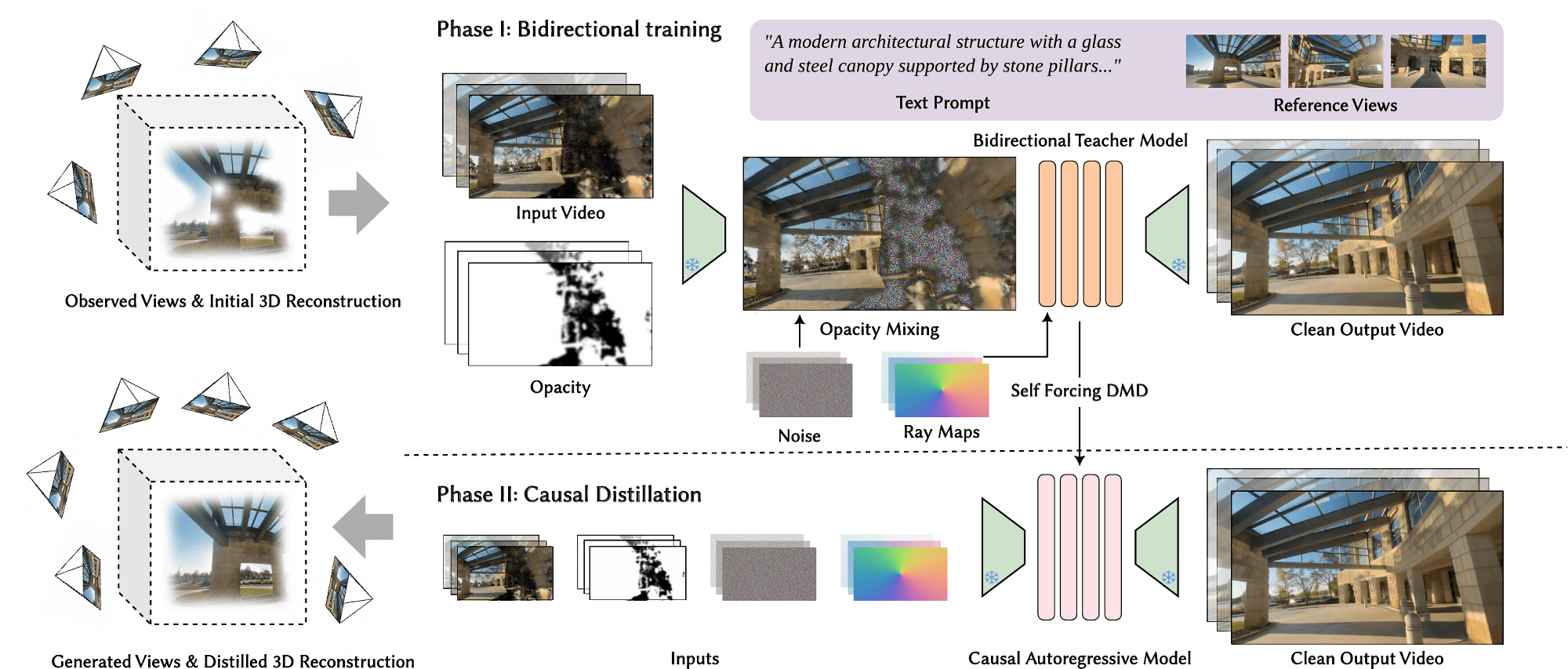
ArtiFixerは以下の3種類が存在しています。
・自己回帰モデルによってビューを生成する「ArtiFixer」
・ArtiFixerの出力を3D表現に蒸留する「ArtiFixer3D」
・ArtiFixer3Dの結果に後処理として自己回帰モデルを適用する「ArtiFixer3D+」
以下の画像は左上が従来手法の「3DGUT」、右上が「ArtiFixer」、左下が「ArtiFixer3D」、右下が「ArtiFixer3D+」で生成した3Dシーンです。ArtiFixerはシャープなシーンを生成可能で、ArtiFixer3Dは一貫性が高いものの少しぼやけるのが特徴。ArtiFixer3D+はシャープかつ一貫性の高いシーンを生成できます。

「3DGUT」「GenFusion」「GSFixer」「ArtiFixer3D+」で生成したシーンの比較画像が以下。ArtiFixer3D+は他の手法と比べて非常に高品質な3Dシーンを生成できます。

オブジェクトが大量にある室内の写真からも高品質な3Dシーンを生成できます。

・関連記事
画像を3D化する「3Dガウススプリッティング」の精度を飛躍的に向上する手法が開発される - GIGAZINE
街全体をスキャンして1億以上の3Dガウス分布からレンダリングした3Dモデルの実例がスゴい - GIGAZINE
リアルタイム動画生成AI「LongLive-2.0」をNVIDIAが公開、FP4量子化を想定した学習により軽量かつ高品質な生成を実現 - GIGAZINE
NVIDIAが高性能画像生成モデル&動画生成モデルを含むフィジカルAI基盤モデル群「Cosmos 3」を公開 - GIGAZINE
高速かつ高精度なオブジェクト検出AIモデル「LocateAnything」をNVIDIAが公開、写真だけでなくアプリUIや文字の検出にも対応 - GIGAZINE
Appleの画像生成AIが大幅強化されて高品質生成や画像編集が可能に - GIGAZINE
Google DeepMindがマルチモーダル生成モデル「Gemini Omni」を発表、自然言語による対話と推論能力による動画生成・編集が可能に - GIGAZINE
・関連コンテンツ








in AI, Posted by log1o_hf
You can read the machine translated English article NVIDIA has announced 'ArtiFixer,' an AI ….