




GoogleがAIで治療薬開発を改善する「TxGemma」をオープンモデルでリリース、誰でも利用可能に

Googleが、新しい治療薬の開発を助けるためのAI「TxGemma」をリリースしました。有望なターゲットの特定から臨床試験の結果の予測までを行えて理由を解説することも可能とのこと。オープンモデルのため誰でも利用可能となっています。
Introducing TxGemma: Open models to improve therapeutics development - Google Developers Blog
https://developers.googleblog.com/en/introducing-txgemma-open-models-improving-therapeutics-development/

新しい治療薬の開発において、候補となる薬ができてもその後の臨床試験で90%程度が脱落し、試験を突破して医薬品と認められる割合は10%程度です。候補薬の開発も含めると新薬の開発成功率はさらに下がり、新薬1つを開発するのに数十億ドル(数千億円)の費用と10年以上の年月が必要になることも多々あります。
開発中の医薬品の90%は臨床試験を突破できない - GIGAZINE
今回登場したTxGemmaはGoogle DeepMindが開発したGemma 2をベースに新薬開発に役立つよう特別にトレーニングしたモデルで、治療物質の特性を理解して有望なターゲットの特定や臨床試験の結果の予測を行えるとのこと。「研究室から臨床現場までの時間とコストを削減できる可能性がある」とGoogleは述べています。
Googleがオープンソースのビジュアル言語モデル「PaliGemma」を公開&Llama 3と同等性能の大規模言語モデル「Gemma 2」を発表 - GIGAZINE
TxGemmaは700万個の例を使用してGemma 2をファインチューニングしたモデルで、「予測」モデルと「会話」モデルに分かれています。予測モデルはパラメーター数が20億の2Bモデル、90億の9Bモデル、270億の27Bモデルが同時にリリースされ、以下のようなTherapeutics Data Commonsから抽出されたタスクに特化しているとのこと。
・分類
「この分子は血液脳関門を通過するか?」などのタスク
・回帰分析
薬物の結合親和性の予測などのタスク
・生成
反応の生成物から反応物のセットを生成するタスク
会話モデルはパラメータ数が90億の9Bモデルと270億の27Bモデルがリリースされました。会話モデルは推論の説明や質問への回答、複数ターンに渡る議論などのトレーニングを受けており、例えば研究者は「特定の分子が有毒であると予測した理由は何か?」などの質問に分子構造を基にした説明を受けることが可能です。
TxGemmaを使用して新薬を開発する際のイメージ動画がXにポストされています。
Introducing 🥁🥁TxGemma!
— Omar Sanseviero (@osanseviero) 2025年3月25日
🧪LLM for multiple therapeutic tasks for drug development
🤏2B, 9B, and 27B
🤗Fine-tunable with transformers
🤖Agentic-Tx for agentic systems
Blog: https://t.co/nTqoWgmgoF
Models: https://t.co/dlcvuYdH6j pic.twitter.com/OOaAZrBhds
まず、TxGemmaが候補を絞り込みます。
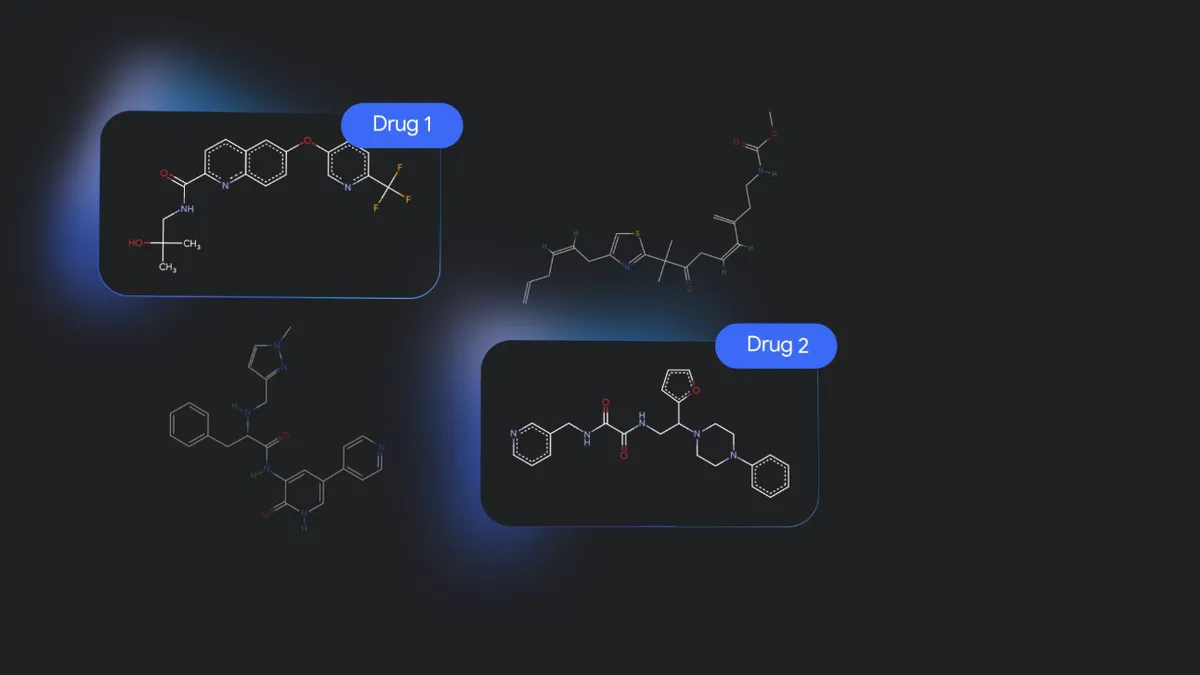
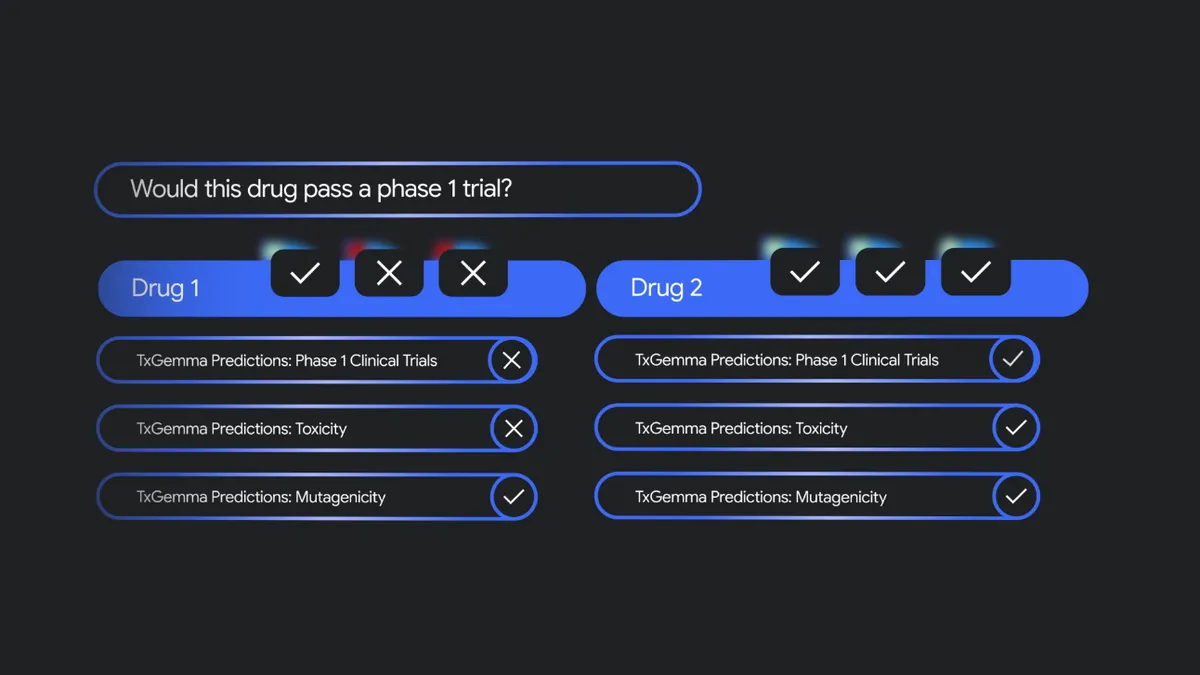
そして「遺伝子への影響はあるか?」「毒性を持つか?」「フェーズ1臨床試験を突破できるか?」などの質問でさらに候補を絞っていき、どの薬の開発を進めるかを効率的に決めることができるというわけです。
TxGemmaはオープンモデルでリリースされているため、誰でもHugging Faceからモデルをダウンロードして利用可能なほか、追加でファインチューニングを行って独自の治療データやタスクに適応させることが可能です。ファインチューニングのやり方についても参考用のColabノートブックが用意されているので気になる人は確認してみて下さい。
・関連記事
「薬の値段が高いのは製薬会社の研究開発費を回収するためではない」という主張 - GIGAZINE
ワクチン接種や抗生物質の服用が認知症リスクの低下と関連しているという研究結果 - GIGAZINE
統合失調症に対する数十年ぶりの新薬をFDAが承認 - GIGAZINE
臨床試験で100%の有効性を示した新たなHIV予防薬「レナカパビル」とは? - GIGAZINE
AIで人間の寿命を10年延ばす治療法を研究するスタートアップ「レトロ・バイオサイエンス」がOpenAI等から10億ドルの資金を調達 - GIGAZINE
・関連コンテンツ






in ソフトウェア, サイエンス, Posted by log1d_ts
You can read the machine translated English article Google releases 'TxGemma' to improve dru….