




紙を使って直感的に利用できるAIインターフェース「Feels Like Paper!」
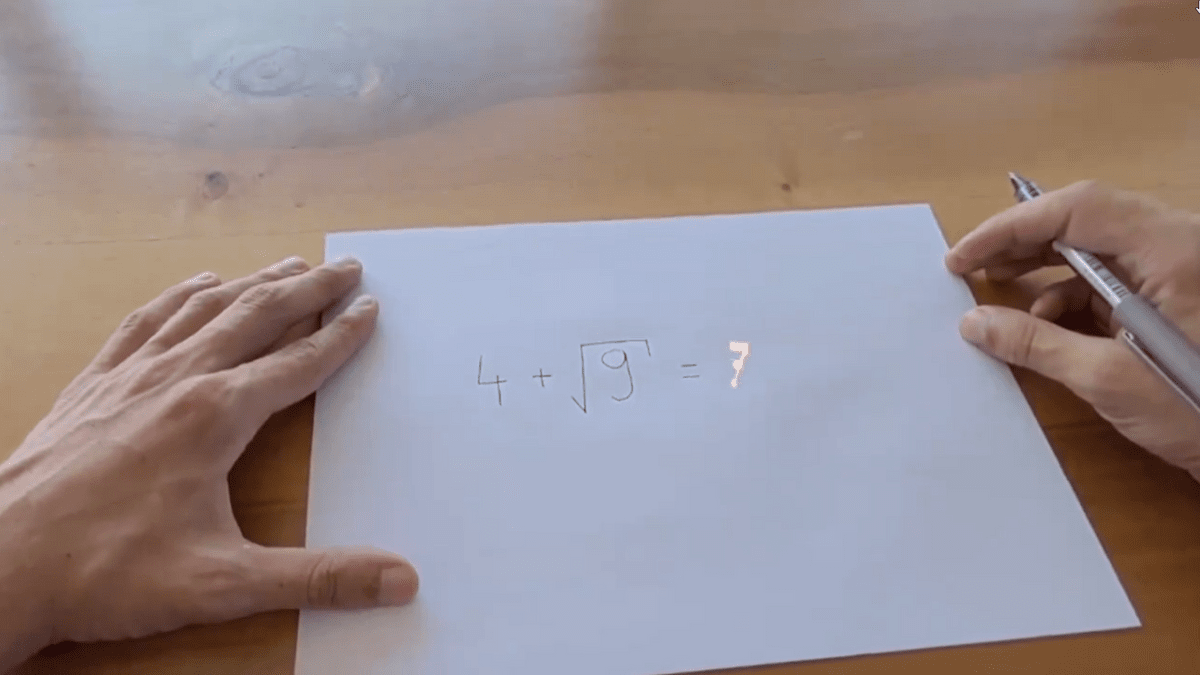
紙はコンピューターと異なり、本を読むことや、簡単なメモや落書きを残すことに長けているとされています。そんな紙の上に直接手書きすることでAIがさまざまな変換を行ってくれる「Feels like Paper!」をデザイナーのルーカス・モロー氏が開発しました。
"Feels Like Paper!" · Interfacing Artificial Intelligence through Paper
https://lukasmoro.com/paper
「Feels like Paper!」は「Maths & Questions」「Mark & Comment」「Draw & Dream」という3つのプロトタイプからなるシリーズです。
◆Maths & Questions
Maths & Questionsは、MR(複合現実)ヘッドセットを装着した状態で紙面にユーザーが数式を書くと、計算結果を示してくれるというアプリケーションです。仕組みとしては、ユーザーが紙面に書いた数式をAppleのVision Framework APIを用いたラッパーで、自動で等号や疑問符を光学的に認識し、読み取った数式を大規模言語モデルに送信することで計算結果を算出しています。
Apple's Math Notes feature, but on real paper.
— Lukas Moro (@lukas_moro) August 30, 2024
Could camera access on mixed reality headsets in combination with OCR & LLMs lead to a renaissance of physical paper as a productivity tool? pic.twitter.com/z9vlx2UGN1
疑似的に表示されるすべての文字は、事前にモロー氏がコンピューター上で手書きしたもので、モロー氏は「まるで友好的な幽霊によって書かれるようなアニメーションが数字や文字ごとに表示されます」と述べています。
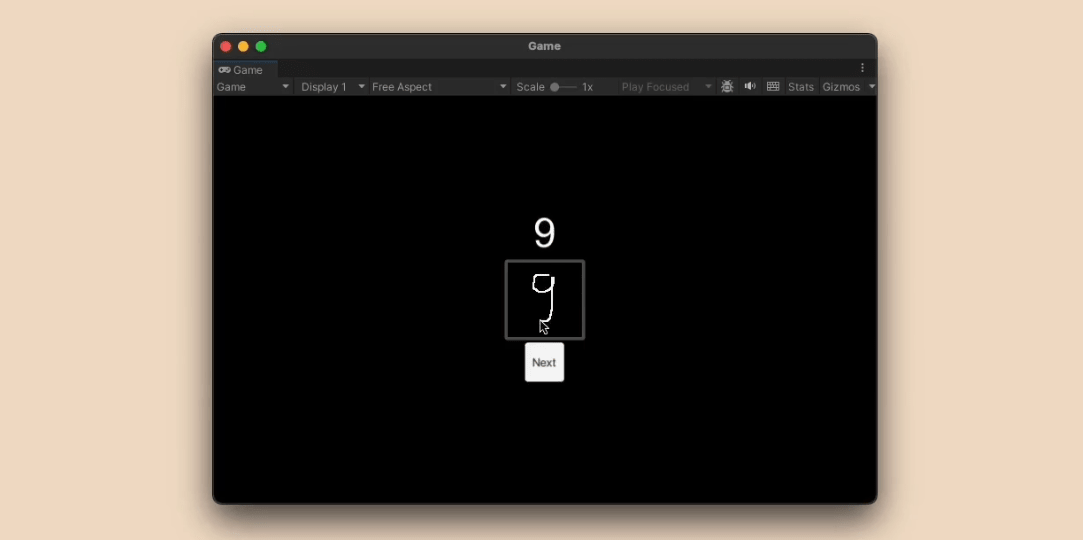
◆Mark & Comment
ユーザーが紙に書かれた文章をマーカーで強調すると、リアルタイムでコンピューター上の同じ文章もハイライト表示されるというのが「Mark & Comment」です。
Another prototype about interfacing artificial intelligence through paper with Quest 3. Highlight and comment text on physical paper, it synchronises the highlights and spoken comments with a digital version automatically. https://t.co/DsYI170AFD pic.twitter.com/LlptksaP64
— Lukas Moro (@lukas_moro) September 23, 2024
また、小指で紙を押さえながら言葉を発すると、自動的に音声が録音され、文字起こしAIのWhisperに入力されます。文字起こしされたコメントは自動的にハイライトの上に表示されるとのこと。

なお、Mark & Commentの処理ではOpenCVによる光学式文字認識パイプラインを用いて文字コードの列に変換した後に、「強調表示されたテキストが表示された場合は、テキストのみで回答してください。それ以外の場合は空の回答を返します」というプロンプトをGPT-4oに転送します。この結果、強調表示されたテキストだけを認識してデジタル上でハイライトを付けることが可能になります。

◆Draw & Dream
「Draw & Dream」は、紙の上に絵を描く様子をリアルタイムで別の映像に変換するというアプリケーション。仕組みとしては、ユーザーが紙に描いた絵が自動的に画像生成AIのStreamDiffusionに入力され、プロンプトに沿った画像を生成します。この生成画像のビデオフィードをUnityアプリケーションを通じてリアルタイムでレンダリングしているとのこと。
Real-time image diffusion as a muse while painting on physical paper. Prototype using StreamDiffusion and Quest 3. https://t.co/zbnIywxsTc pic.twitter.com/2EqJf0GXAs
— Lukas Moro (@lukas_moro) October 18, 2024
モロー氏によると、描画した画像をStreamDiffusionにフィードするために、Python上に画像処理パイプラインを実装したとのこと。また、OpenCVを導入して紙の4辺を検出し、画像をStreamDiffusionに入力しているそうです。さらに、連続するフレーム間で特徴を一致させる「Brute-Force matcher」や画像を常に鳥瞰(ちょうかん)で見ることができるホモグラフィなどを用いることで、手やペン、ブラシで紙が部分的に隠れてしまっても適切に入力することが可能です。

これらのプロトタイプについて、モロー氏は「これら3つのアプローチは、人間とAIとの関係の枠組みが異なります。『Maths & Questions』は私たち自身の知性を補完するためのAIとの統合または『融合』を提案するもので、『Mark & Comment』はAIの機能を活用して世界を理解するアシスタントとして使用するもの、『Draw & Dream』は生成AIがただのツールではなく、自分の作品を制作するのを助けたり、創作意欲をさらに刺激するインタラクションを与えたりするものです」と述べています。
・関連記事
手書きのメモの写真からペンの動きを抽出するモデル「InkSight」をGoogleが開発 - GIGAZINE
GPT-4oはどのように画像をエンコードしてトークンに分解しているのか? - GIGAZINE
文章だけでなく視覚的なコンテンツも理解してIQクイズに答えられるAI「Kosmos-1」をMicrosoftが発表、汎用人工知能の開発に前進 - GIGAZINE
画面上の文字列をOCRで読み取り翻訳できる翻訳支援ツール「PCOT」 - GIGAZINE
無料&ブラウザ上でPDF・JPEG・PNG・GIFファイルからOCRによるテキスト抽出ができる「OCR PDFs and images directly in your browser」 - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article 'Feels Like Paper!': An intuitive AI int….