




全ベンチマークでGPT-4oを上回る世界トップのオープンソース大規模言語モデル「Reflection 70B」が登場、Llama 3.1 70B Instructをベースにリフレクションチューニングを施す

大規模言語モデル(LLM)が自分の間違いを修正できるように開発されたトレーニング手法の「リフレクションチューニング」を用いてトレーニングされたオープンソースのLLM「Reflection 70B」が発表されました。
HyperWrite debuts Reflection 70B, most powerful open source LLM | VentureBeat
https://venturebeat.com/ai/meet-the-new-most-powerful-open-source-ai-model-in-the-world-hyperwrites-reflection-70b/

New Open Source AI Model Can Check Itself and Avoid Hallucinations | Inc.com
https://www.inc.com/kit-eaton/new-open-source-ai-model-can-check-itself-avoid-hallucinations.html
Startup aims to open source the world's most capable AI model
https://the-decoder.com/startup-aims-to-open-source-the-worlds-most-capable-ai-model/
Reflection 70Bは、AIパーソナルアシスタントのHyperWriteを開発するOthersideAIのCEOであるMatt Shumer氏が、AI企業のGlaive AIと共同で構築した新しいAIモデルです。
I'm excited to announce Reflection 70B, the world’s top open-source model.
— Matt Shumer (@mattshumer_) September 5, 2024
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
405B coming next week - we expect it to be the best model in the world.
Built w/ @GlaiveAI.
Read on ⬇️: pic.twitter.com/kZPW1plJuo
Claude 3.5 SonnetやGPT-4o、Gemini、Llama 3.1 405BといったLLMと性能を比較したところ、マルチモーダルな言語理解力を測定するベンチマークのMMLU、数学的問題解決能力を測定するベンチマークのMATH、指示追従能力を評価するベンチマークのIFEval、数学能力を評価するベンチマークのGSM8KにおいてReflection 70Bはトップの成績を納めています。さらに、高度な推論能力を評価するベンチマークのGPQAや、プログラム合成能力を評価するベンチマークのHumanEvalも実施されており、これらすべてでGPT-4oを上回るパフォーマンスを示したそうです。このベンチマーク結果を受け、Reflection 70Bは「世界トップのオープンソースLLM」であることがアピールされています。
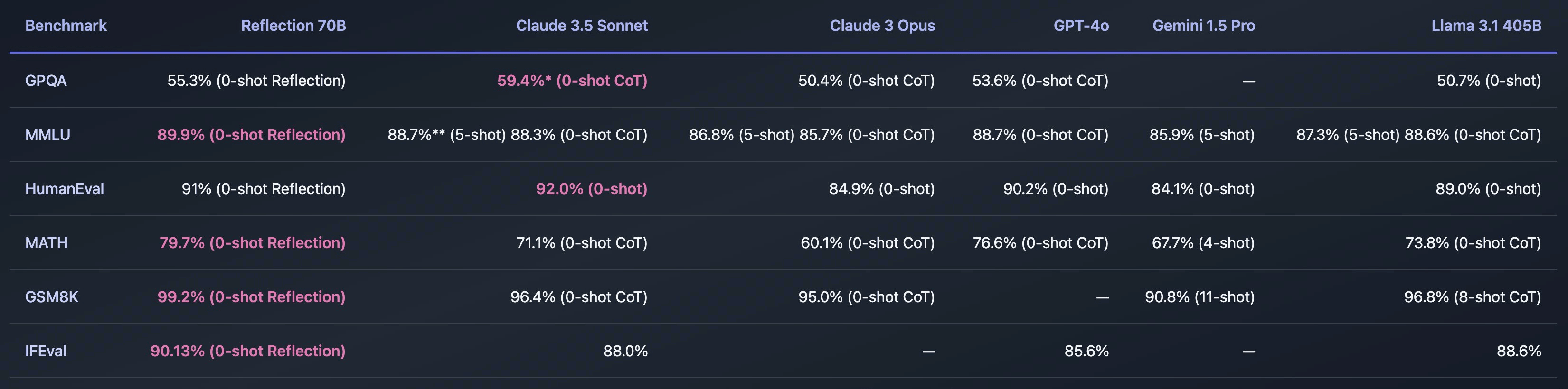
Reflection 70BはMetaのオープンソースLLMであるLlama 3.1 70B Instructをベースとしており、他のLlamaモデルと同じコード・パイプラインを利用しながら、リフレクションチューニングと呼ばれる「LLMに間違いを認識させ、回答を確定する前に自身で修正させる手法」を取り入れたものです。Reflection 70Bでは推論とエラー修正のための新しい特殊トークンを導入しており、これによりユーザーがより構造化された方法でモデルと対話することが容易になっています。推論中、Reflection 70Bは特殊タグ内に推論を出力するため、間違いが検出された場合はリアルタイムでこれを修正することができるそうです。
また、Reflection 70Bは「計画」フェーズと回答生成段階を分離することで、Chain-of-Thoughtアプローチの有効性を取り入れつつ出力がエンドユーザーにとってシンプルで簡潔なものになる模様。
Additionally, we separate planning into a separate step, improving CoT potency and keeping the outputs simple and concise for end users. pic.twitter.com/CECu7evmve
— Matt Shumer (@mattshumer_) 2024年9月5日
また、Reflection 70Bはデータ汚染がないかをチェックするためにLMSysのLLM Decontaminatorを使用しています。
Reflection 70Bは以下から利用可能です。
mattshumer/Reflection-Llama-3.1-70B · Hugging Face
https://huggingface.co/mattshumer/Reflection-Llama-3.1-70B

Reflection 70Bのデモ版がウェブサイト上で公開されていますが、トラフィックが集中しており記事作成時点ではページが一時的にダウンしており利用できませんでした。
Shumer氏によるとReflection 70Bよりもパラメーター数の大きなReflection 405Bもリリース予定であり、Reflection 70BはHyperWriteに統合される予定でもあるそうです。
なお、Reflection 70BはGlaive AIが作成したデータセットを用いてトレーニングされています。Glaive AIはAI開発における最大のボトルネックのひとつである「高品質でタスク固有のデータの可用性の解決」に重点を置いた企業で、特定のニーズに合った合成データセットを作成することで、企業がAIモデルを迅速かつ低コストで微調整できるようにサポートしています。
・関連記事
なぜ大規模言語モデル(LLM)はだまされやすいのか? - GIGAZINE
AIの仕組みであるLLMの「ブラックボックス」の内部を見てどのニューラルネットワークが特定の概念を呼び起こすかを知る試みをAnthropicが解説 - GIGAZINE
大規模言語モデルが回答できない質問はどういうものなのか? - GIGAZINE
Microsoftが独自の大規模言語モデル「MAI-1」を開発中との報道、Google・OpenAI・AnthropicのAIモデルと競合可能なレベルとも - GIGAZINE
Hugging FaceのAIモデルをテストする「Open LLM Leaderboard v2」で中国Qwenのモデルがトップに - GIGAZINE
スパコン「富岳」で学習した日本語特化大規模言語モデル「Fugaku-LLM」が公開される - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article The world's top open source large-sc….