




Metaがテキストベースのプロンプトに視覚情報ベースで回答するAIエージェントのベンチマーク「OpenEQA」をリリース

現地時間の2024年4月11日、Metaがテキストベースの質問に対してAIエージェントの物理空間の理解度を測定することができるベンチマーク「OpenEQA」をリリースしました。
OpenEQA: From word models to world models
https://ai.meta.com/blog/openeqa-embodied-question-answering-robotics-ar-glasses/
OpenEQA: Embodied Question Answering in the Era of Foundation Models
https://open-eqa.github.io/
Meta AI releases OpenEQA to spur 'embodied intelligence' in artificial agents | VentureBeat
https://venturebeat.com/ai/meta-ai-releases-openeqa-to-spur-embodied-intelligence-in-artificial-agents/
家庭用ロボットやスタイリッシュなスマートグラスの頭脳として機能するAIエージェントは、視覚などの感覚モダリティを活用して周囲を理解し、人々を効果的に支援するために明確な日常言語でコミュニケーションできる必要があります。これは、言語を通じてクエリ可能な、エージェントの外界の内部表現である「世界モデル」を構築するようなものです。この実現は長期的なビジョンであり、気の遠くなるような研究課題であり、Metaは積極的に研究を進めています。
同研究に関する最新の研究結果として、Metaは「Open-Vocabulary Embodied Question Answering(OpenEQA)」と呼ばれるフレームワークを発表しました。OpenEQAはAIエージェントが環境をオープンボキャブラリーの質問で調査することによって、その理解度を測定するという新しいベンチマークです。OpenEQAには家庭やオフィスなど180種類以上の環境データセットと、これらの環境に関する1600種類を超える質問が含まれており、AIがこれらの環境に存在する物体をどの程度正しく認識しているのか、空間的および機能的推論はどの程度可能か、常識などの知識をどの程度持ち合わせているかなどを、徹底的に検証することできます。
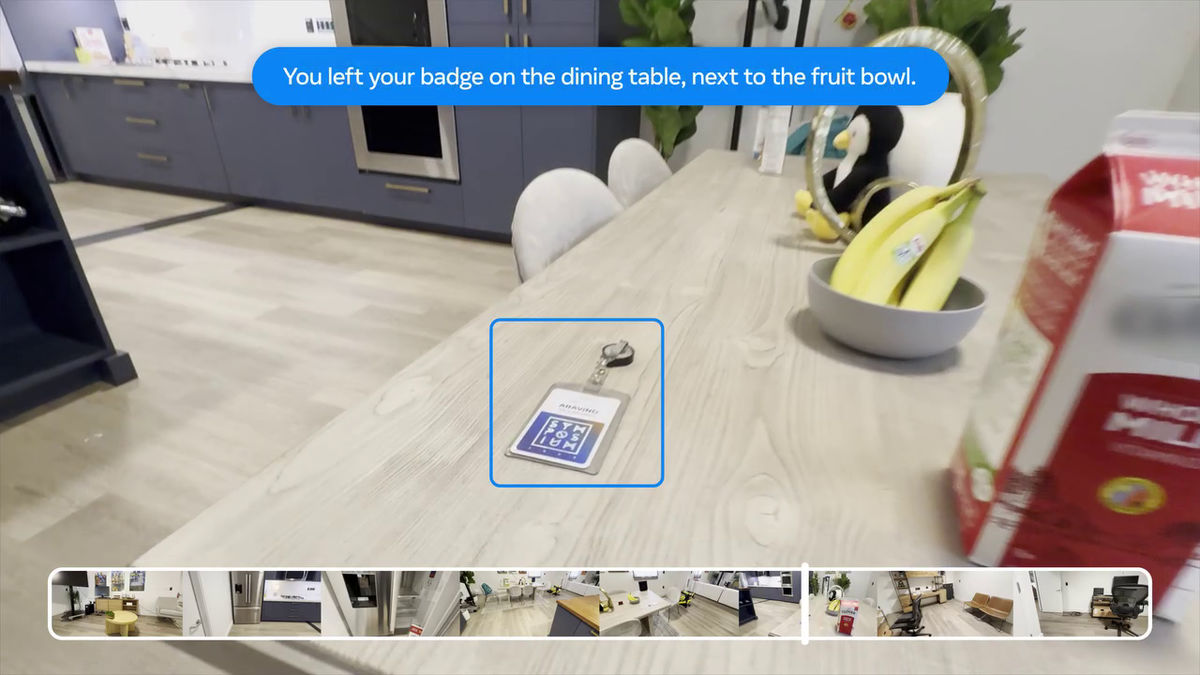
OpenEQAには2つのタスクが含まれています。ひとつは「エピソード記憶EQA」と呼ばれる、身体化されたAIエージェントが過去の経験の回想に基づいて質問に答えるというもの。ある質問に対して、過去の経験(撮影した動画など)から回答を導き出すことができるかを問うタスクです。
例えば「バッジどこに置いたかわかる?」というテキストベースの質問が寄せられた場合。

過去に記録した動画から、質問の答えを導き出すことができるかを検証します。
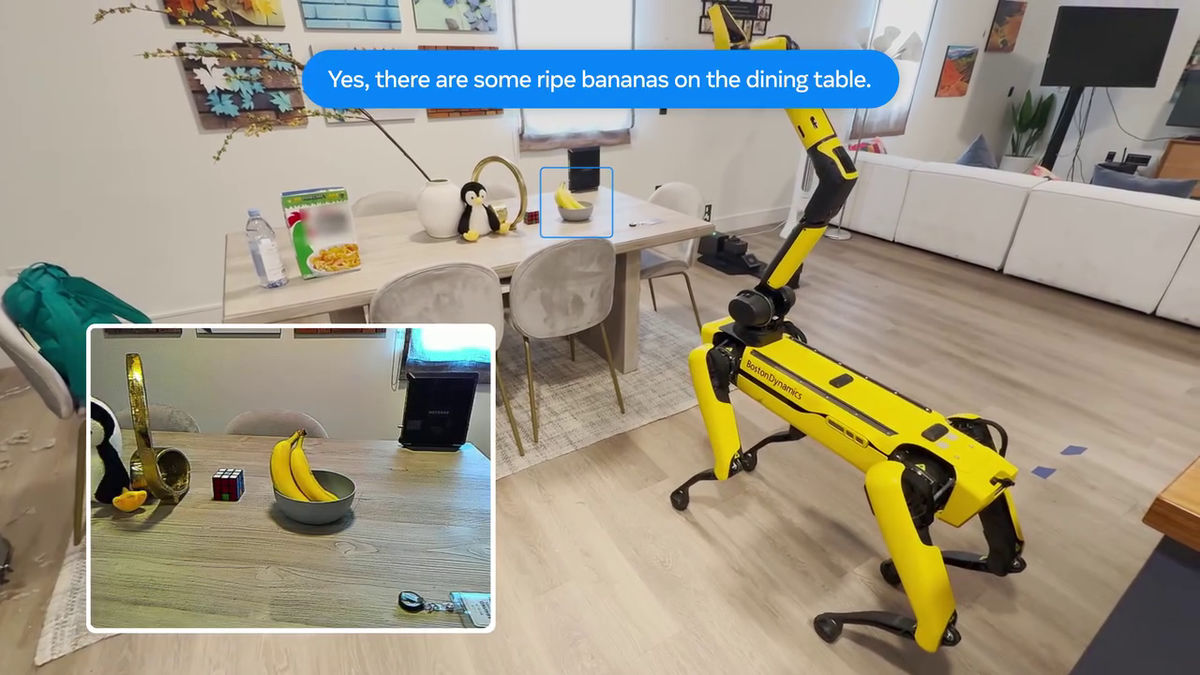
もうひとつが「アクティブEQA」と呼ばれる、必要な情報を収集するためにAIエージェントが環境内でアクションを実行して質問に答えるというタスクです。
例えば「家にフルーツ何かある?」というテキストベースの質問の場合。

過去に撮影した動画ではなく、家の中を動き回って動画を撮影し、フルーツがないかを探します。

そして、フルーツの有無を回答。その精度を検証します。
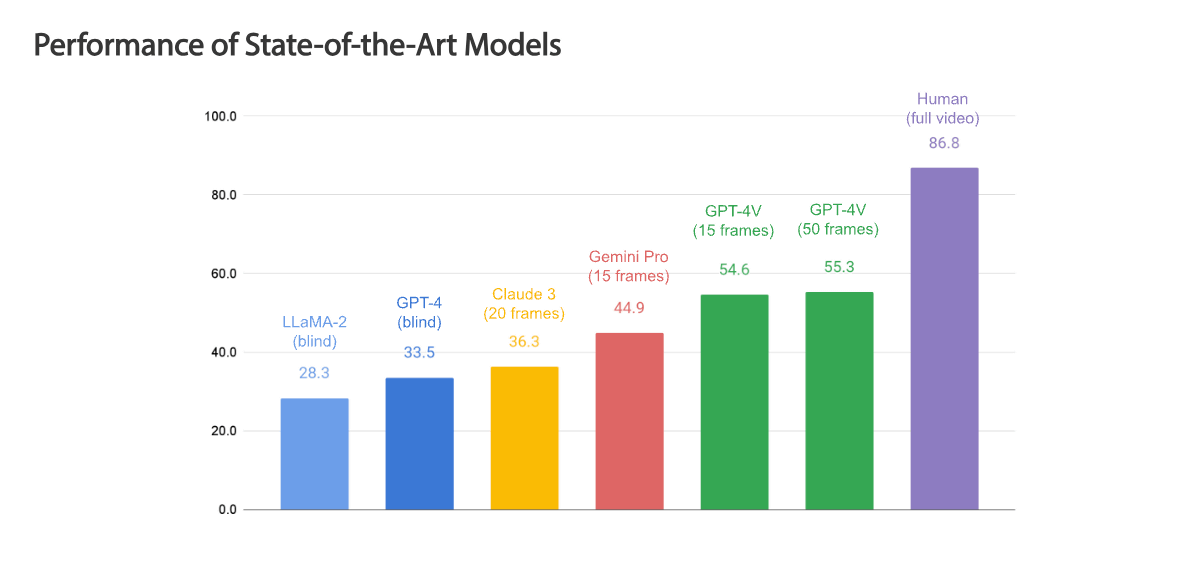
OpenEQAを用い、最先端の画像とテキストを複合して扱うことのできるAIモデル(VLM)のベンチマークテストを実施したところ、最もパフォーマンスが高いモデルは「GPT-4V」で、その精度は「55.35%」であったと報告しています。一方、人間の場合は精度が「86.89%」と非常に高く、依然としてAIと人間のパフォーマンスには大きな開きがあることがわかります。
特に興味深いのは、空間理解を必要とする質問では、最高レベルのVLMであってもほぼ「目隠し状態」であるという点です。VLMであるにもかかわらずパフォーマンスがテキストのみのAIモデルとそれほど変わらないという結果が出ています。これは、視覚情報を利用するモデルが視覚情報から実質的な恩恵を受けていないことを示しているとMetaは指摘。例えば、「私はリビングルームのソファに座ってテレビを見ています。私の真後ろにある部屋はどれですか?」と質問すると、AIモデルは空間の理解をもたらすはずの視覚的なエピソード記憶の恩恵を受けずに、基本的にランダムにさまざまな部屋を推測するそうです。そのため、「知覚と推論の両面でAIモデルにさらなる改善が必要であることを示唆している」とMetaは指摘しました。
OpenEQAは語彙を自由にできる挑戦的な質問と、自然言語で回答する機能を組み合わせています。これにより、環境を深く理解していることを示す簡単なベンチマークが得られ、既存の基礎モデルに大きな課題をもたらすことが可能です。Metaは「OpenEQAが、AIが見ている世界を理解し、コミュニケーションできるようにするためのさらなる研究の動機となることを願っています」と記しました。
・関連記事
Metaが自社開発のAIチップ「MTIA」第2世代を発表、前世代の3倍の性能を実現しデータセンターにも導入済み - GIGAZINE
MetaのAIでアジア人が一時生成不可に、「アジア人と白人のカップル」を出力できない問題で - GIGAZINE
Metaの画像生成AIは「アジア人男性と白人女性のカップル」をイメージできないという報告 - GIGAZINE
MetaがAI強化のため「訴えられてもいいから著作権で保護された作品をかき集めよう」と議論していたとの報道 - GIGAZINE
Metaは「動画エコシステム」のための巨大AIモデル構築を進めている - GIGAZINE
Metaが2024年後半に独自設計のAIプロセッサ「Artemis」を自社データセンターに導入することが明らかに - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article Meta releases OpenEQA, a benchmark for A….