




Googleが動画の高密度キャプションを高精度にこなす「Vid2Seq」を発表

Googleの研究部門であるGoogle Researchが、動画に高密度キャプションをつけることが可能な視覚言語モデルの「Vid2Seq」を公開しました。
Vid2Seq: a pretrained visual language model for describing multi-event videos – Google AI Blog
https://ai.googleblog.com/2023/03/vid2seq-pretrained-visual-language.html
動画はエンターテインメント分野だけでなく、教育やコミュニケーションなど、さまざまな分野にまたがり、我々の日常生活の中でますます重要な役割を担いつつあります。ただし、動画の中では異なるタイミングで複数のイベントが発生するため、動画の内容をAIに理解させることは非常に困難です。例えば、犬ぞりを紹介する動画の場合、「犬がそりを引く」という長いイベントと、「犬をそりにつなぐ」という短いイベントが含まれます。
こういった動画の内容をAIに理解させるための研究におけるひとつの手法として採用されているのが、高密度キャプションと呼ばれる手法です。これは数分間の動画の中のすべての事象を時間的に位置づけて説明するというもので、短い動画を一文で説明するシングルキャプションやスタンダードビデオキャプションとは異なるとGoogle Researchは説明しています。
高密度キャプションは、視覚や聴覚に障害を持つ人が動画を視聴できるようにしたり、動画のチャプターを自動で生成したり、大規模データベース内の動画におけるモーメント検索を改善したりと、幅広い用途への利用が期待できます。
しかし、既存の高密度キャプション技術は「高度に専門化したタスク固有のコンポーネントを必要とするため強力な基礎モデルに統合することが困難である」や、「手動でアノテーションされたデータセットのみを用いて学習することが多いため入手が非常に困難であり拡張性のあるソリューションとは言えない」などの、いくつかの問題を抱えているそうです。

そこでGoogle Researchが開発したのが「Vid2Seq」です。Vid2Seqは言語モデルを特別な時間トークンで補強し、同じ出力シーケンスでイベントの境界とテキストのキャプションをシームレスに予測することを可能にします。
Vid2Seqは、高密度キャプションをシーケンス2シーケンスの問題として定式化し、特別な時間トークンを使用して、モデルがテキストの意味情報と動画内の各テキストの根拠となる時間的ローカリゼーション情報の両方を含むトークンをシームレスに理解し、生成できるようにするというモデル。
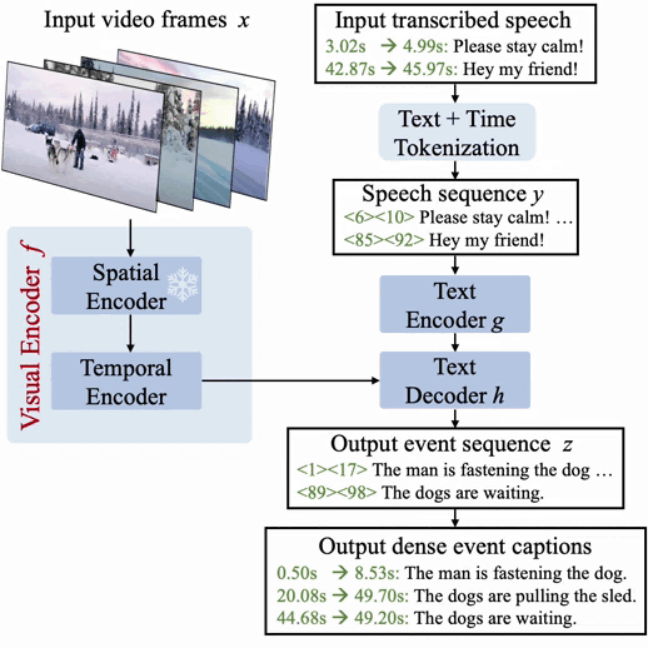
研究チームはVid2Seqを事前学習させるために、ラベルなしのナレーション付き動画を活用。文字起こしされた音声の文末を疑似的なイベント境界として再定義し、文字起こしされた文章を疑似的なイベントキャプションとして使用します。数百万本のナレーション付き動画で事前学習されたVid2Seqは、YouCook2、ViTT、ActivityNet Captionsなどの高密度キャプションベンチマークにおいて高いスコアを記録しているそうです。また、Vid2Seqは数ショットの高密度キャプション設定、動画段落キャプションタスク、標準ビデオキャプションタスクにうまく一般化することができます。
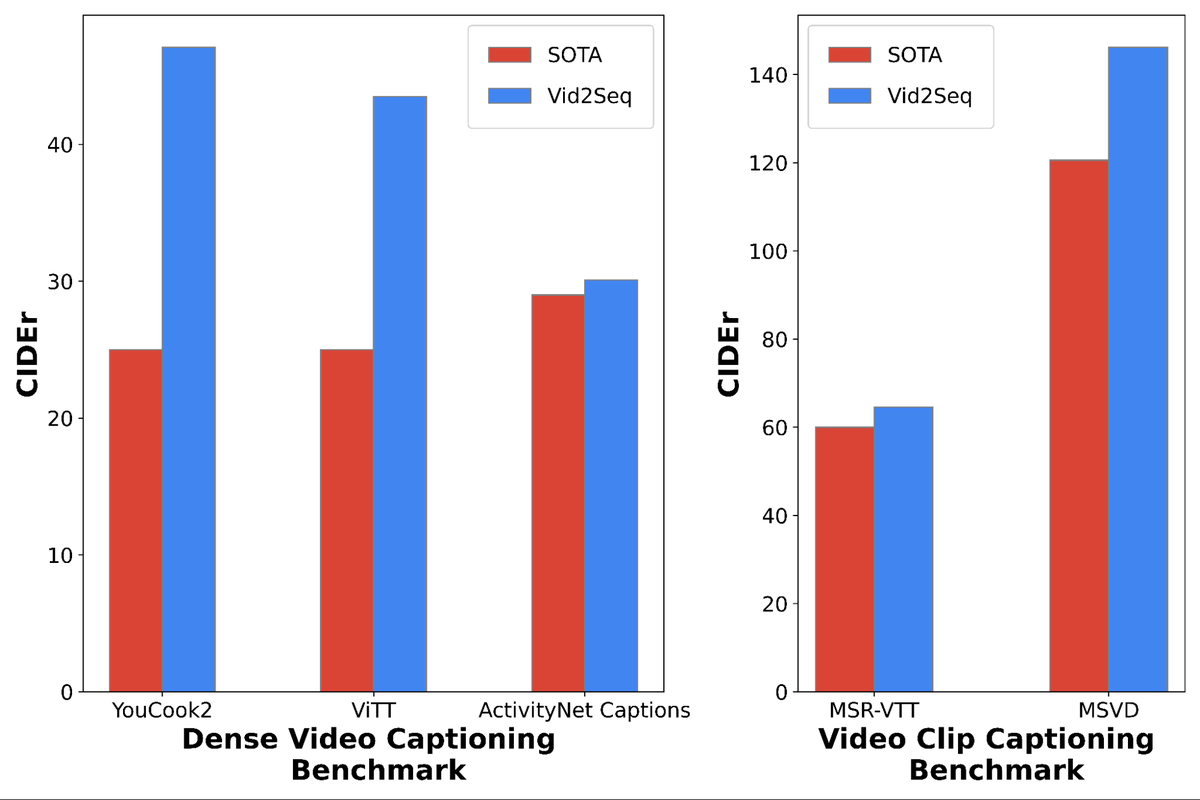
左は高密度キャプションベンチマークであるYouCook2、ViTT、ActivityNet Captionsの3つでVid2SeqとSOTA(現時点での最先端レベルの性能)のスコア(縦軸)を比較したグラフで、右は動画キャプションベンチマークのMSR-VTTとMSVDにおけるVid2SeqとSOTAのスコアを比較したグラフ。どのベンチマークにおいてもVid2Seqは業界最先端の基準を上回るスコアをたたき出しています。
Vid2Seqによる高密度キャプションの事例が以下。動画の1~9秒に「男性が犬をそりにつないでいる」、20~50秒に「犬がそりを引いている」、45秒と49秒に「犬が待機している」といった具合に、シーン別に異なるキャプションをつけることができます。

Vid2SeqのコードはGitHub上で公開されています。
scenic/scenic/projects/vid2seq at main · google-research/scenic · GitHub
https://github.com/google-research/scenic/tree/main/scenic/projects/vid2seq
なお、Vid2Seqは2023年6月に開催予定のCVPR 2023で詳細が発表される予定です。
・関連記事
Twitterが動画に自動で字幕を付ける機能を発表 - GIGAZINE
Microsoftが「人間以上の精度で画像に説明文を追加するAI」をWordやOutlookなどの改善に使用 - GIGAZINE
Microsoftがテキストから本物と見間違うレベルの架空のイメージを自動生成する新AI技術「AttnGAN」を開発 - GIGAZINE
MicrosoftのOfficeツールにAIが画像を自動で認識して説明文を作成する新機能を追加 - GIGAZINE
Googleが画像の説明文章を自動生成する技術を開発 - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by logu_ii
You can read the machine translated English article Google announces ``Vid2Seq'' tha….