Google announces ``Vid2Seq'' that handles high-density captions of videos with high accuracy

Google Research, Google's research division, has released ' Vid2Seq ', a visual language model that can add high-density captions to videos.
Vid2Seq: a pretrained visual language model for describing multi-event videos – Google AI Blog
Videos are playing an increasingly important role in our daily lives, not only in the entertainment field, but across various fields such as education and communication. However, since multiple events occur at different times in a video, it is extremely difficult to make AI understand the content of the video. For example, a video showcasing dog sledding might include a longer event 'Dog pulls the sled' and a shorter event 'Tie the dog to the sled.'
One method used in research to make AI understand the content of such videos is a method called high-density captioning . Google Research explains that this is a temporal description of all events in a few minutes of video, and is different from single captions and standard video captions that describe short videos in one sentence.
High-density captions have a wide range of uses, from making videos accessible to people with visual and hearing impairments, automatically generating video chapters, and improving moment searches for videos in large databases. can be expected to use
However, existing dense captioning techniques 'require highly specialized, task-specific components that are difficult to integrate into a strong underlying model,' and 'use only manually annotated datasets.' It is very difficult to obtain and cannot be said to be an extensible solution because it is often learned by learning.”

Therefore, Google Research developed 'Vid2Seq'. Vid2Seq augments
Vid2Seq formulates dense captioning as a sequence-2-sequence problem and uses special temporal tokens to ensure that the model contains both the semantic information of the text and the underlying temporal localization information for each text in the video. A model that allows seamless understanding and generation of
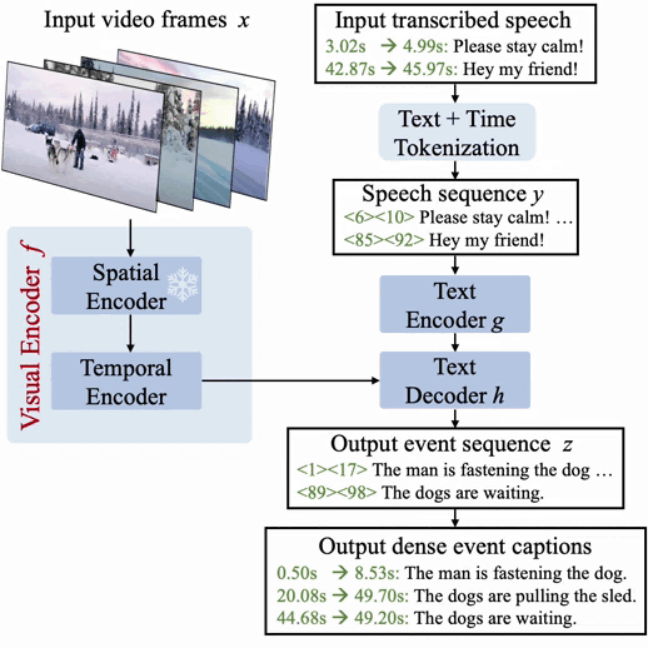
The research team used
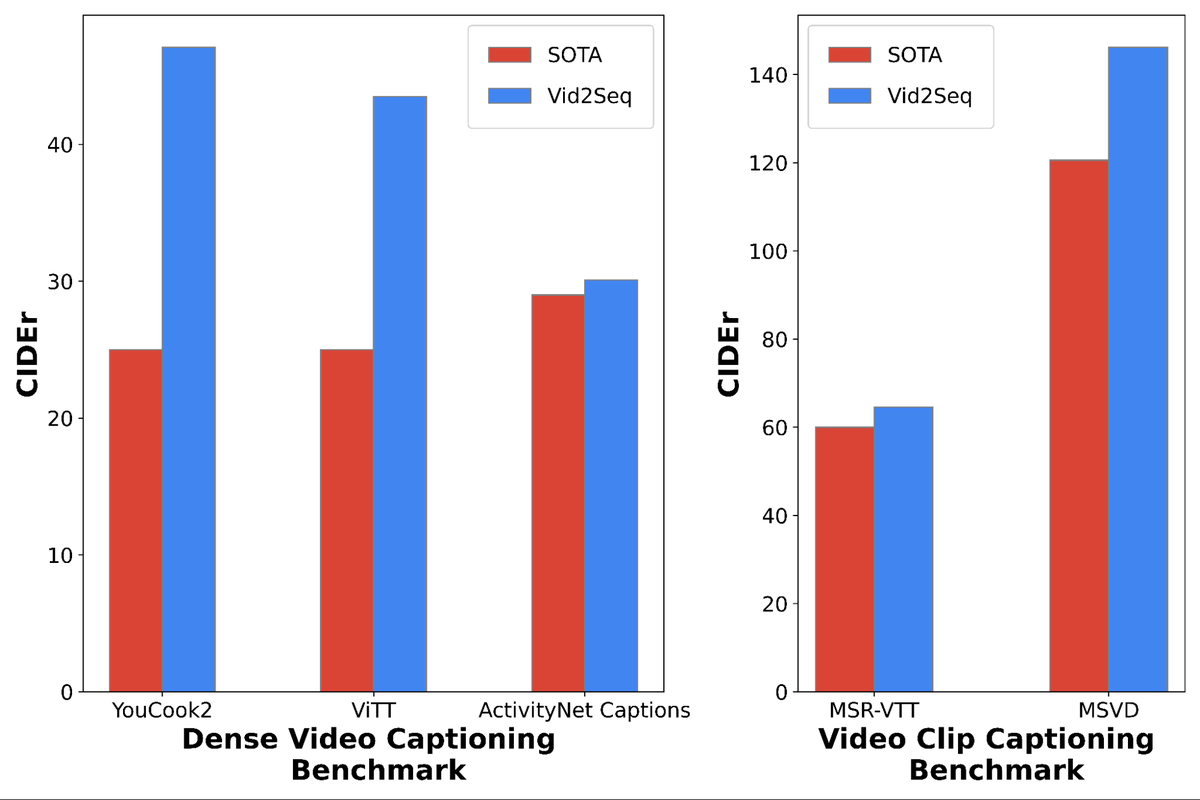
The graph on the left compares the scores (vertical axis) of Vid2Seq and SOTA (current state-of-the-art performance) for three high-density caption benchmarks, YouCook2, ViTT, and ActivityNet Captions, and the right is the video caption benchmark MSR . -Graph comparing Vid2Seq and SOTA scores on VTT and MSVD . Vid2Seq outperforms industry-leading standards on every benchmark.
Below is an example of high-density captioning with Vid2Seq. ``A man is leading a dog to a sled'' in seconds 1-9 of the video, ``A dog is pulling a sled'' in seconds 20-50, and ``A dog is waiting'' in seconds 45 and 49. can have different captions for different scenes. 
The code of Vid2Seq is published on GitHub.
scenic/scenic/projects/vid2seq at main google-research/scenic GitHub
https://github.com/google-research/scenic/tree/main/scenic/projects/vid2seq
Details of Vid2Seq will be announced at CVPR 2023 , which is scheduled to be held in June 2023.
Related Posts:








in Software, Posted by logu_ii