Google releases Gemini 1.5, can process up to 1 million tokens and handle 1 hour of movies and 700,000 words of text

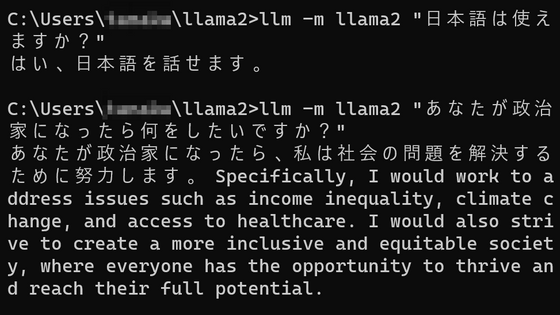
Google has announced ' Gemini 1.5 ' as the next generation model of multimodal AI 'Gemini' that can process text, images, and movies all at once. The upper limit on the number of tokens that can be processed has been increased to 1 million, and it is said that it can provide high quality results with fewer calculations than the previous 1.0 model.
Google Japan Blog: Announcing the next generation model, Gemini 1.5
The previous model, Gemini 1.0, was released on December 6, 2023 as a “multimodal AI with performance exceeding GPT-4.” In the hands-on movie using the top model Gemini 1.0 Ultra, you can see how it responds as if it were a human.
Multimodal AI ``Gemini'' with performance exceeding GPT-4, which can process text, voice, and images simultaneously and have more natural interactions than humans, will be released - GIGAZINE

Then, on February 15, 2024, Google announced 'Gemini 1.5' as the next generation model of Gemini. At the same time as the announcement, the Gemini 1.5 Pro model is now available as a private preview in AI Studio and Vertex AI . 'Gemini 1.5 Pro delivers the same performance as Gemini 1.0 Ultra while reducing the computing resources required to operate,' said Sander, CEO of Google and Alphabet.・Pichai said.
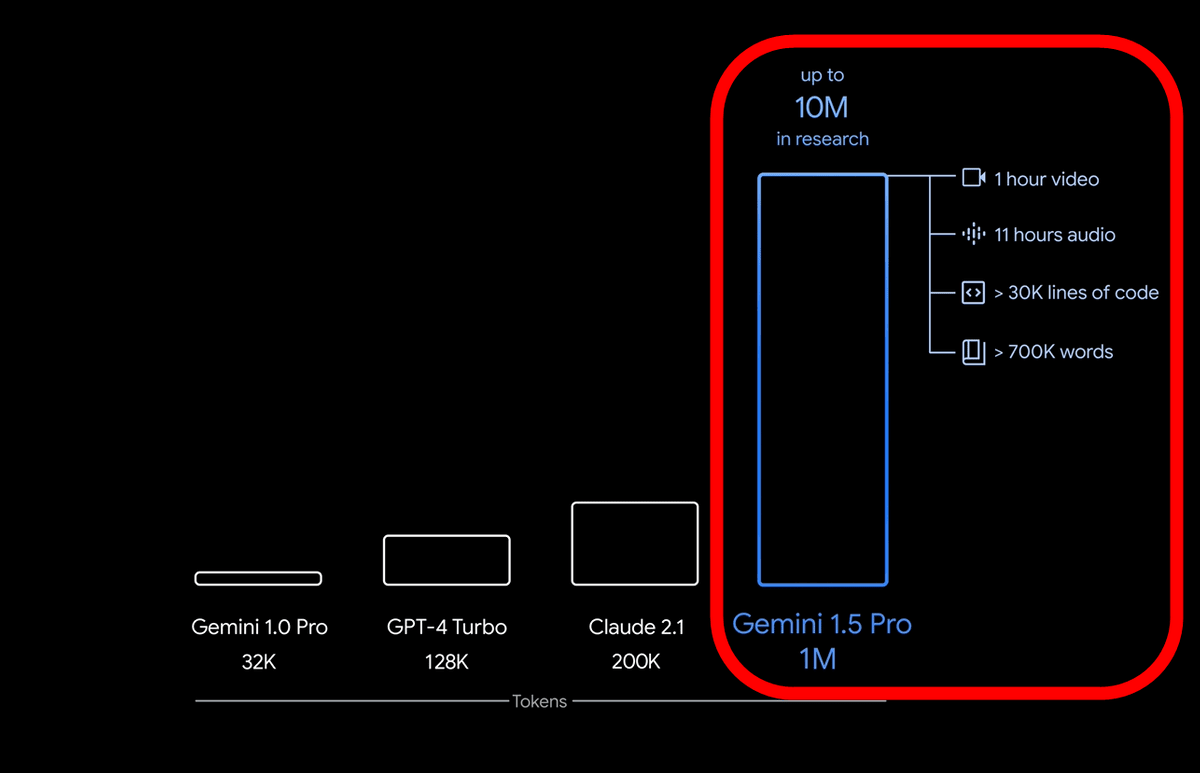
The standard context window for Gemini 1.5 Pro is 128,000 tokens, but some companies and developers selected as early testers can use Gemini 1.5 Pro with support for up to 1 million tokens. . One million tokens is equivalent to ``1 hour of movie,'' ``11 hours of audio,'' ``more than 30,000 lines of code,'' and ``more than 700,000 words of text.'' In addition, at the research stage, we have succeeded in processing up to 10 million tokens.
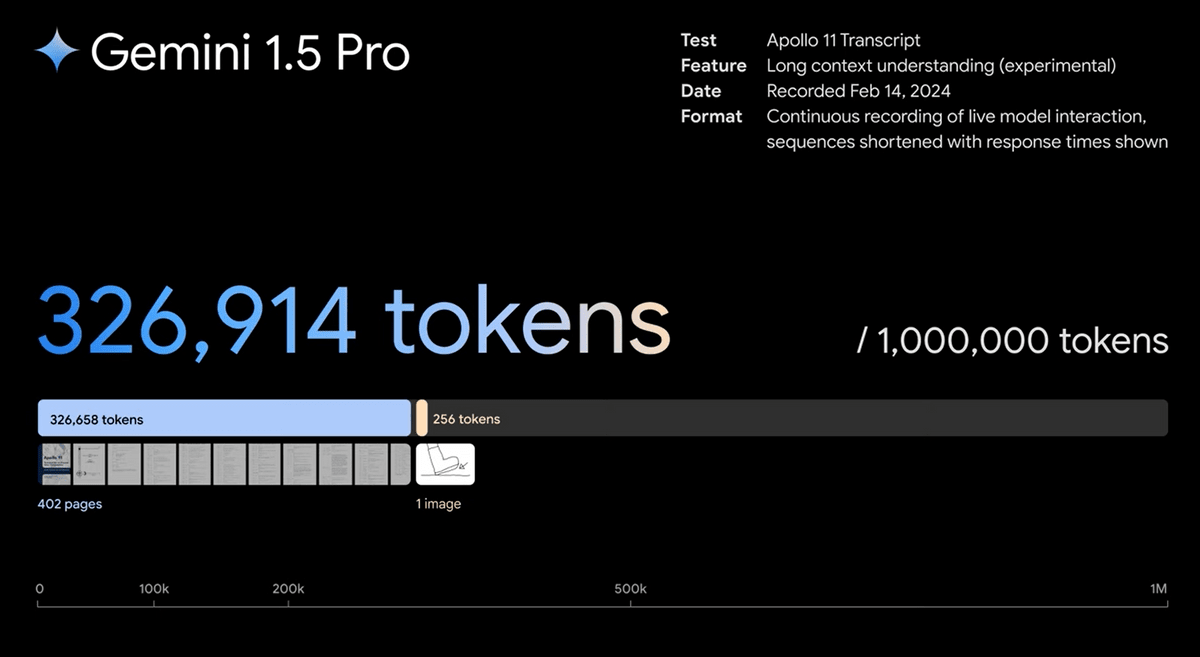
Several demo movies have been uploaded to YouTube that actually prove the power of Gemini 1.5 Pro. The first one is about reading the 402-page record of
Reasoning across a 402-page transcript | Gemini 1.5 Pro Demo - YouTube
The record on page 402 is about 330,000 tokens.
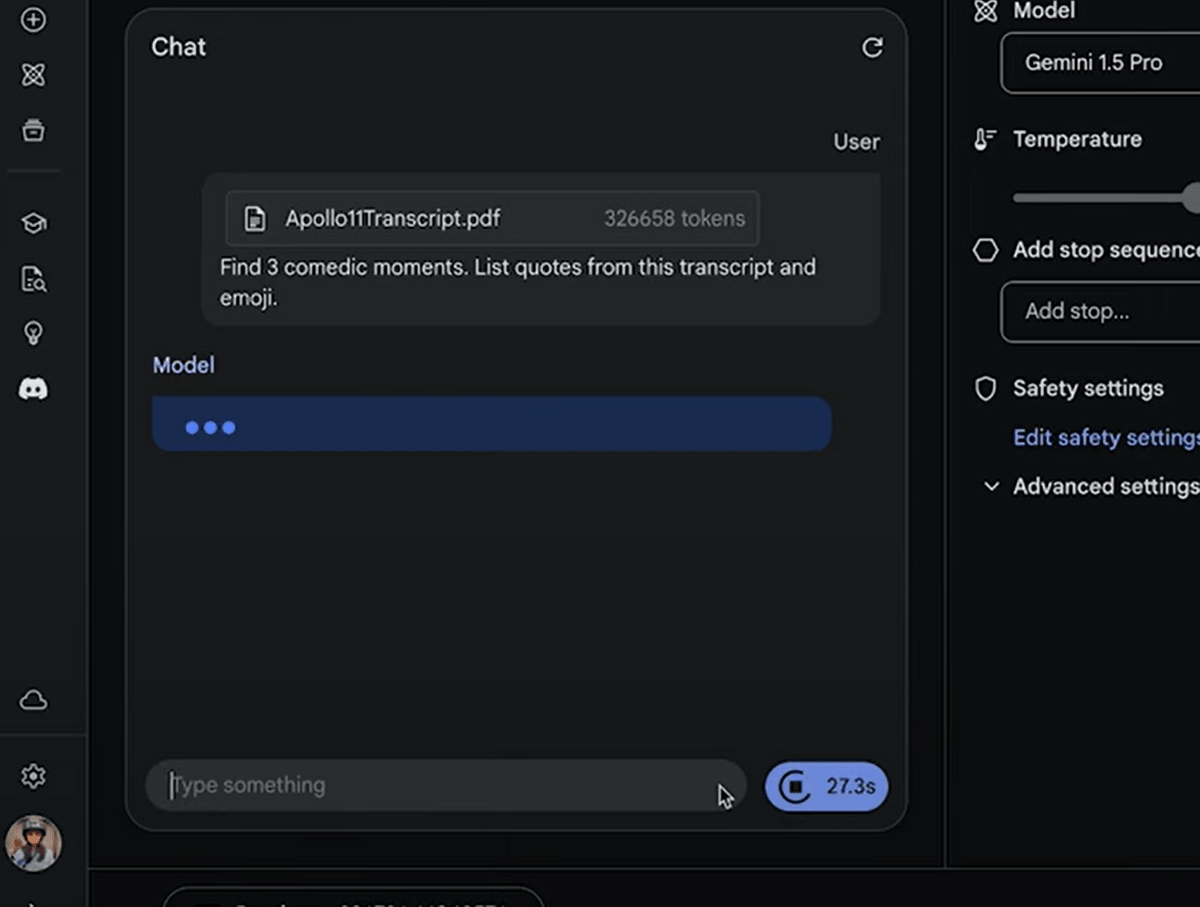
Upload the PDF file and enter the prompt, ``Find 3 funny moments, quote them, and add emojis.''
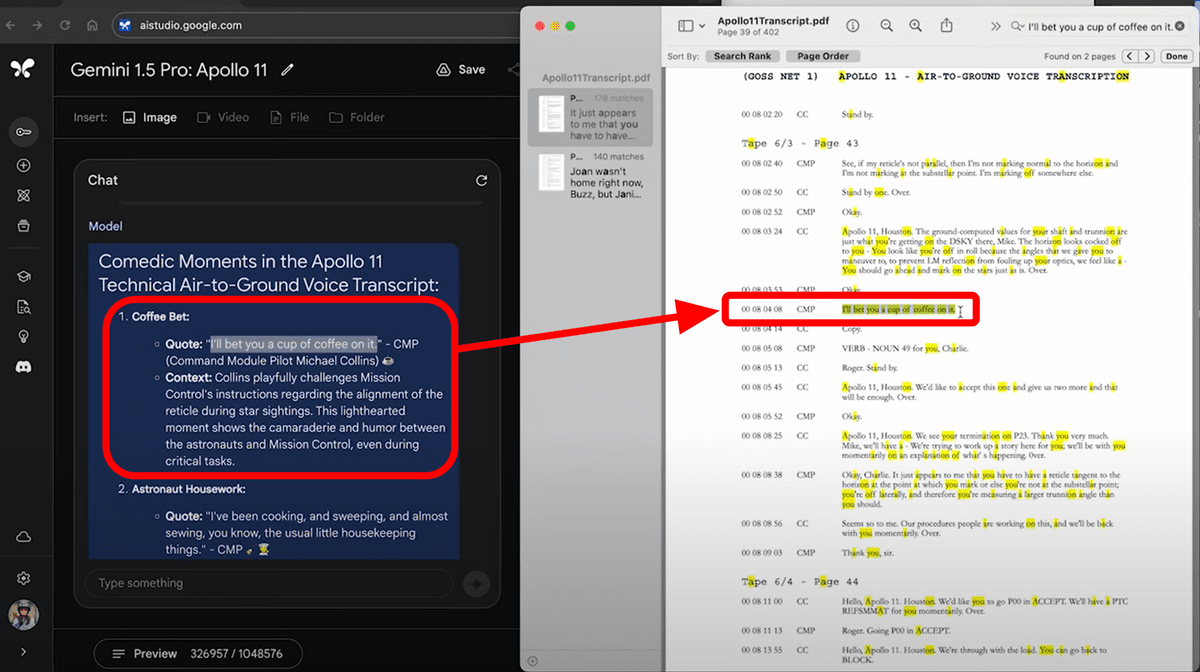
I was able to properly extract the 'jocular exchange' part.
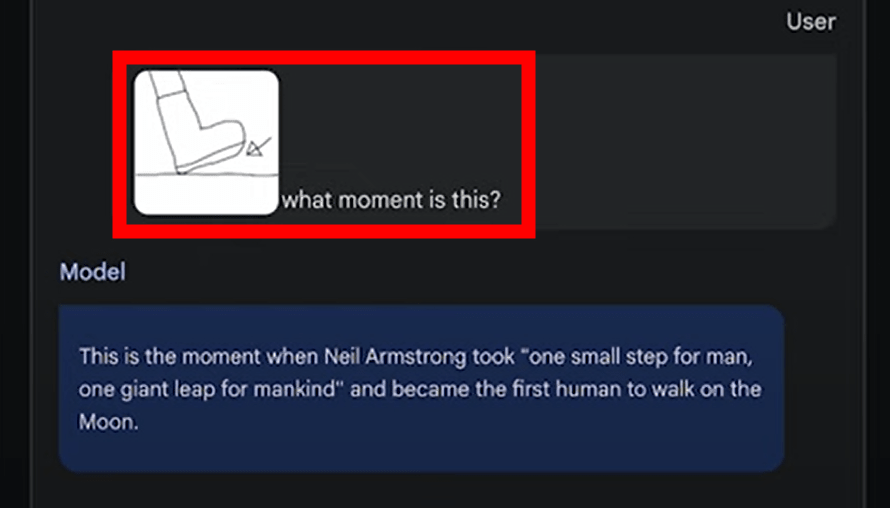
When I prepared an image of taking a step and asked, ``What kind of moment is this?'' Gemini 1.5 Pro answered, ``The moment when humans first walked on the moon.''
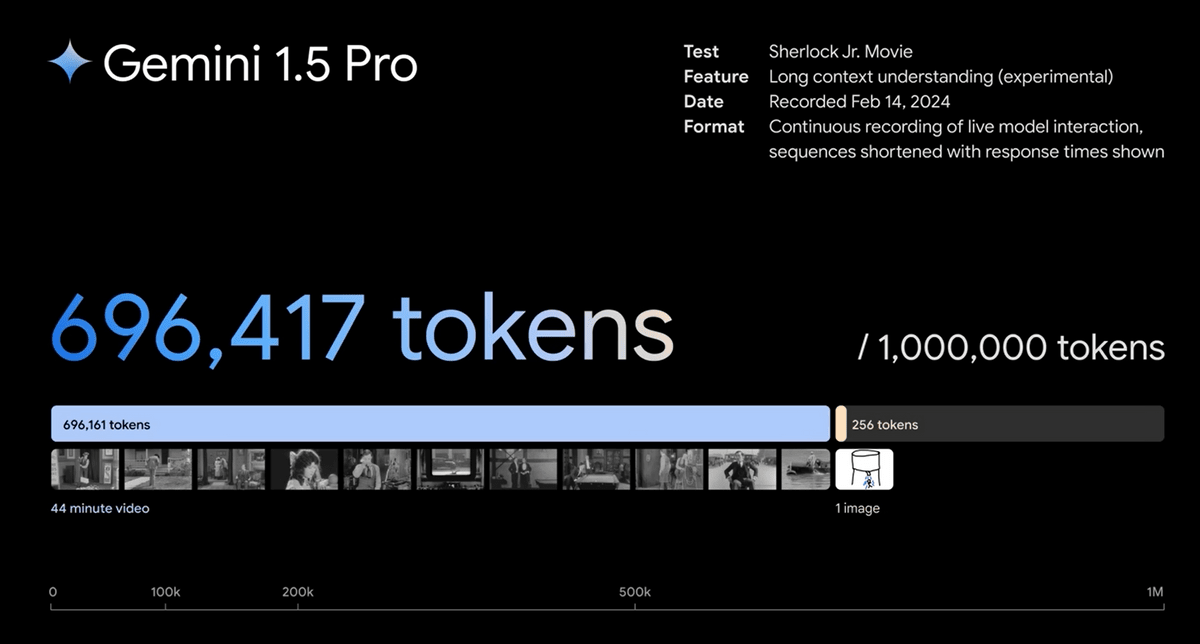
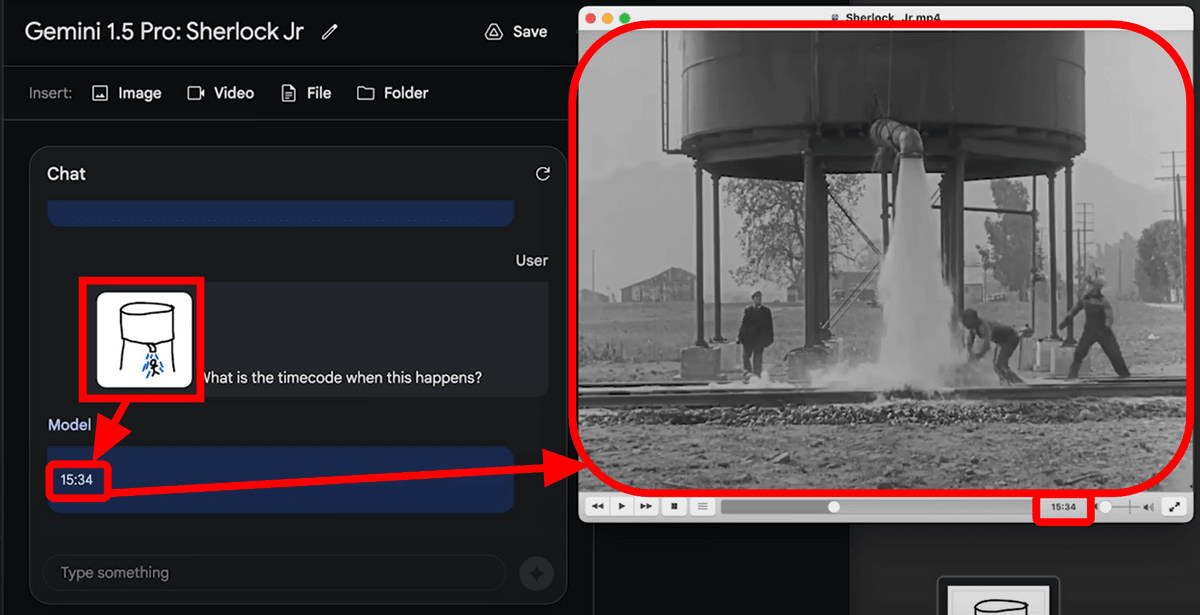
The second example is to interpret a 44-minute movie.
A 44-minute movie costs about 700,000 tokens.
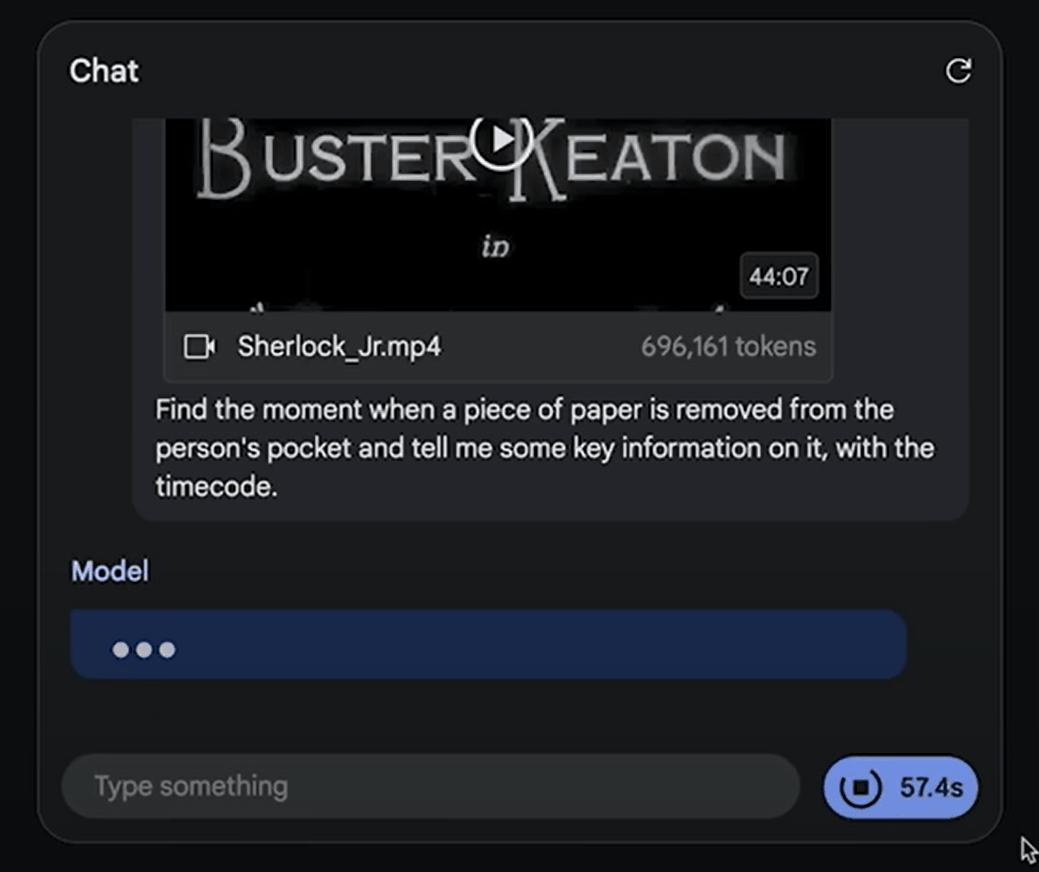
Give the movie to Gemini 1.5 Pro and ask it to ``find the moment when you take out a piece of paper from someone's pocket and tell me the time and context.''
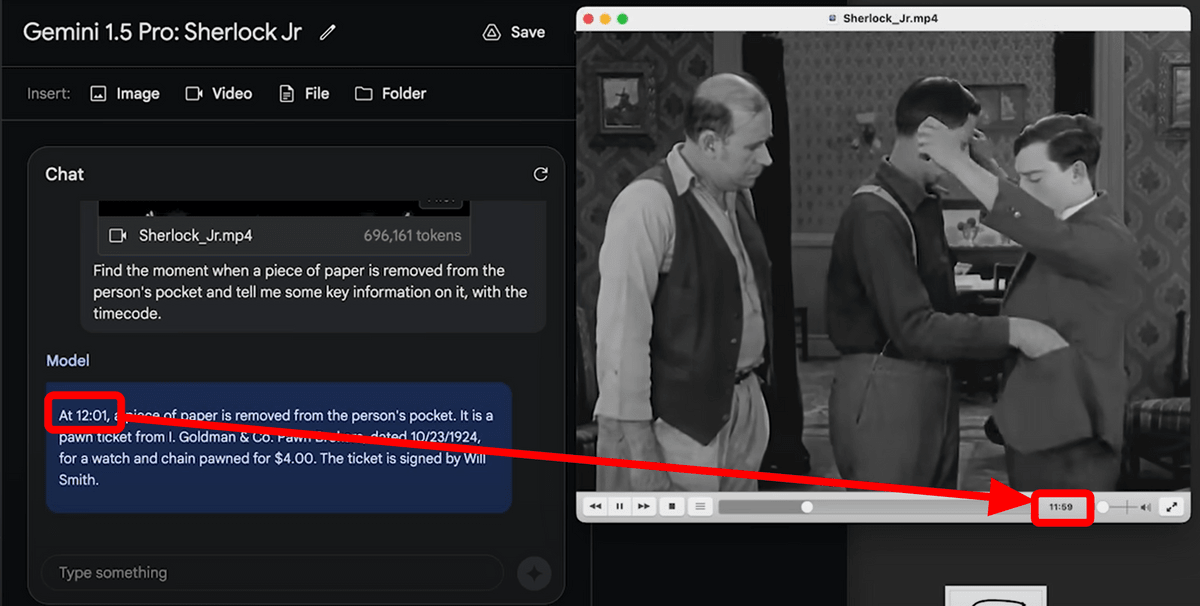
Then, Gemini 1.5 Pro not only accurately conveyed the time when the event occurred, but also outputted information such as the date, person, and paper content in the movie.
We are also able to respond to questions such as ``When did this occur?'' based on handwritten images.
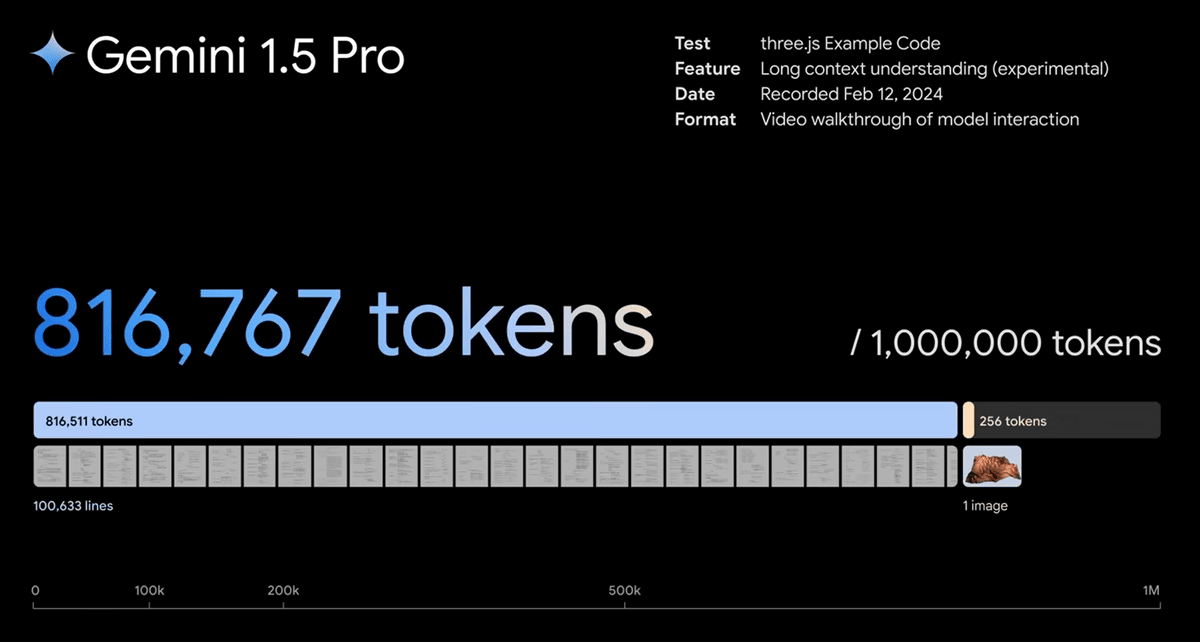
The final part involves reading over 100,000 lines of code.
The number of tokens is approximately 820,000. Three.js sample code is used.
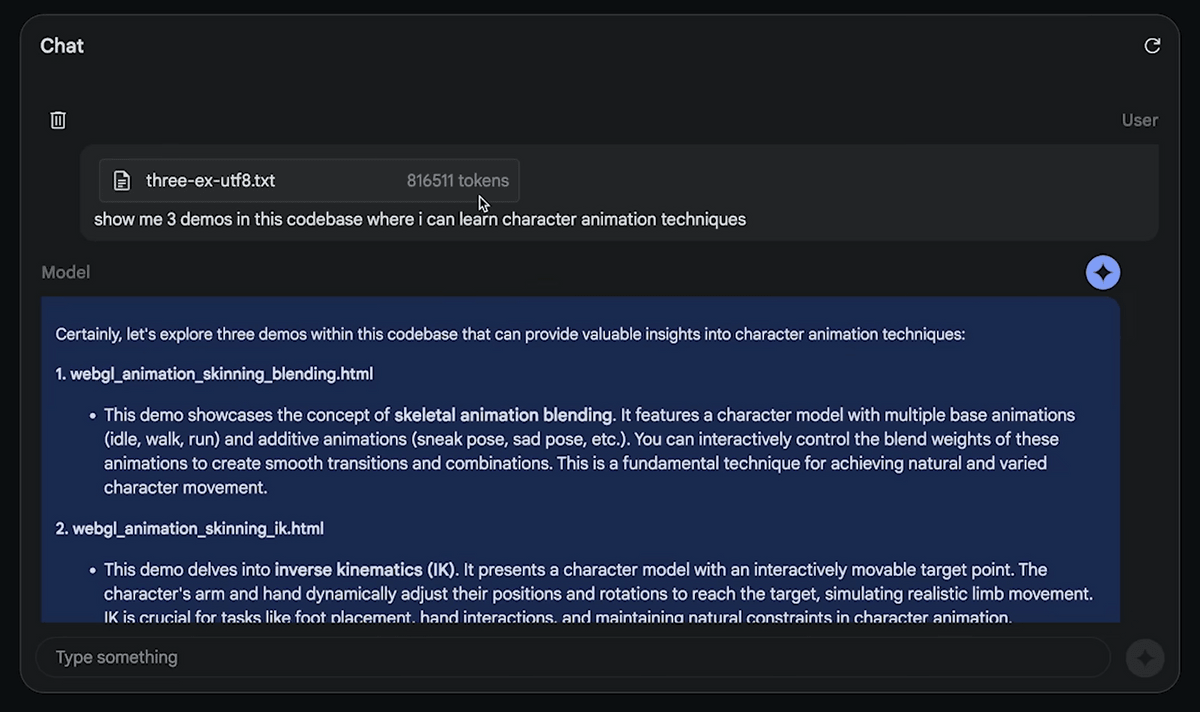
If you ask them, ``Show me three demos included in the code that will teach you about techniques for animating characters,'' they will introduce the demos with explanations.
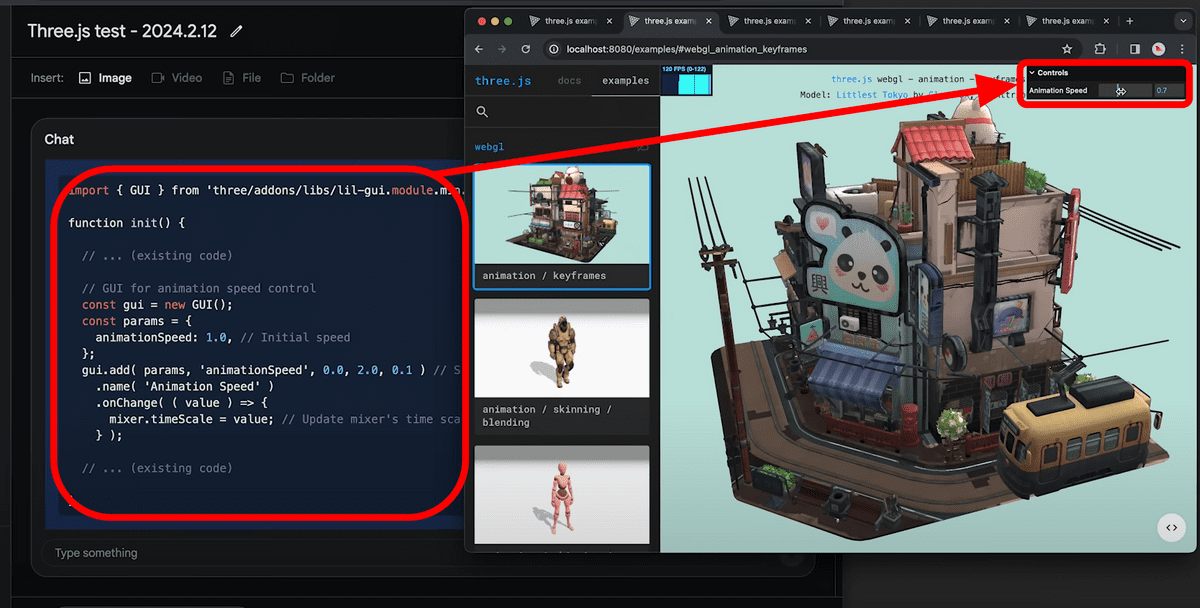
You can also request code changes via text. When I asked ``Please add a slider to adjust the animation speed,'' it generated the appropriate code.
Developers interested in using Gemini 1.5 Pro can sign up for the AI Studio waiting list, and businesses are asked to contact Vertex AI 's account team.
Google plans to make Gemini 1.5 Pro publicly available with a 128,000-token context window as soon as the model is ready for wide release, with plans to scale up to 1 million tokens as the model improves. says.
Related Posts:





in Software, Web Service, Posted by log1d_ts