




「AI学習用のデータセット作成を大学や非営利団体に任せることで企業は法的責任から逃げている」という批判

画像生成AIのStable Diffusionが一般に無料公開されたことをきっかけに、画像生成AIの進歩が急激に進んでいます。一方で、AIモデルの学習に使われているデータセットの権利問題を指摘する声もあがっており、一部では法的責任を追及する議論も行われています。インターネットでさまざまな活動を行っている開発者のアンディ・バイオ氏が、「大学や非営利団体の研究者が、大手テクノロジー企業が説明責任から逃避するための隠れ蓑になっている」と批判しています。
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability - Waxy.org
https://waxy.org/2022/09/ai-data-laundering-how-academic-and-nonprofit-researchers-shield-tech-companies-from-accountability/
2022年9月、Metaは動画生成AI「Make A Video」を発表しました。このAIは文字列(プロンプト)を入力するだけで動画を生成するというものでした。
Metaが動画生成AI「Make A Video」発表、空飛ぶスーパードッグや自画像を描くテディベアの動画を公開 - GIGAZINE

Metaは(PDFファイル)論文の中で、「動画生成モデルには『WebVid-10M』と『HD-VILA-100M』という2つのデータセットを使っている」と記していました。そこで、ソフトウェア開発者のサイモン・ウィルソン氏がAIの学習用データセットを検索するオープンソースのツール「Datasette」で2つのデータセットについて調べたところ、「WebVid-10M」に含まれる1070万本以上のビデオクリップすべてにShutterstockの透かしが入っていたとのこと。また、「HD-VILA-100M」はMicrosoftが収集した映像で構成されたデータセットで、そのうち数百万本がYouTubeから収集されたものだったことがわかりました。
Metaは一連のデータセットを「AIへの学習」という研究目的で使っており、商用利用とはしていません。しかし、バイオ氏は「Metaはおそらく将来的な商用利用を想定した上でAIモデルをトレーニングしています。変だと思うでしょう? 実はそうでもないんです。AIを扱う企業が、大学や非営利団体が収集・訓練したデータセットやモデルを商用利用するのは当たり前になっています」と述べています。
例えば、画像生成AIのStable Diffusionは、記事作成時点ではStability AIが開発を主導していますが、もともとはミュンヘン大学ルートヴィヒ・マキシミリアン校(LMU)の機械視覚・学習研究グループの研究からスタートしています。LMUの研究者は、Stability AIがコンピューターを寄付してくれたおかげで開発プロジェクトが進んだと感謝しているそうです。
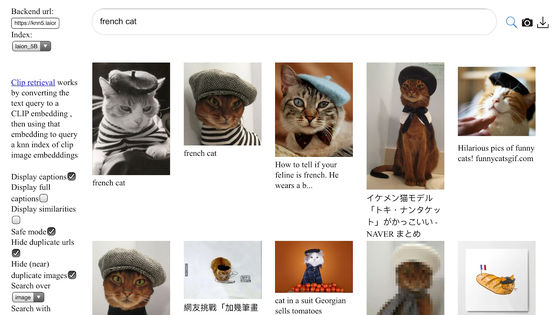
そして、Stable DiffusionやGoogleのImagen、Make A Videoの画像生成モデルの学習に使われたデータセットはいずれもドイツの非営利団体・LAIONが作成したものです。Stability AIはLAIONにも資金提供しています。
Not sure if I mentione but stable diffusion is a model created and released by CompVis at University of Heidelberg.
— Emad (@EMostaque) August 16, 2022
The LAION dataset is created by the German charity of the same name. We support both.
This is outlined in the announcement post.
Has implications for stuff above
バイオ氏は、大学などの研究機関や非営利団体によってデータ収集とモデルの学習が行われている場合、アメリカの著作権法で認められているフェアユースに該当する可能性が高いとみています。しかし、「DreamStudio」のように商業サービスを展開しているStability AIが、大学や非営利団体が作ったデータセットを使ってモデルを学習させ、商用利用可能なオープンソースライセンスの下で画像を生成するのは、一種のデータロンダリングであるとバイオ氏は批判しています。
バイオ氏は、ワシントン大学の研究者が顔認証AIの学習用データセットに写真共有コミュニティサイトのFlickrにあるクリエイティブ・コモンズライセンスの画像を使った件に言及し、データセットの法的責任に触れています。Flickrユーザーだったバイオ氏は帰属表示付きかつ非営利目的で写真をアップロードしていたそうですが、そうしたライセンス規約は無視されたと指摘。ワシントン大学のデータセットは後に廃止されましたが、IBMが作成したデータセットも同様の問題について報じられました。
IBMがユーザーに無断でFlickr上の写真を顔認証技術のために利用しているという指摘 - GIGAZINE
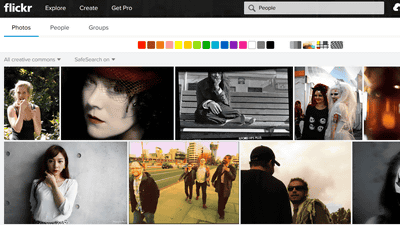
バイオ氏は「データセットの画像すべてで許諾を得ることは大変なコストがかかり、技術の進歩を遅らせるでしょう。しかし無条件に世界にリリースしたものを取り消すことは困難なのです」とコメントしています。
また、バイオ氏は「2022年に入ってAIが急激な進歩を遂げている一方で、AIモデルやデータセットの作成についての倫理観とデータセットへの使用同意・権利帰属・ライセンス表示の欠如などがあらわになっています。実際にこの問題の解決に取り組んでいる人もいますが、私は懐疑的です。AIモデルは一度学習したら、少なくとも今のところ、ほぼそのデータを忘れることはありません」と述べました。
・関連記事
画像生成AIに自分の作品が勝手に使われたかどうかを検索できる「Have I Been Trained?」 - GIGAZINE
超高精度なイラストを生成できると話題の「NovelAI」は本家Stable Diffusionにどんな改善を加えたのか? - GIGAZINE
画像生成AI「Stable Diffusion」でいろいろ特化した使えるモデルデータいろいろまとめ - GIGAZINE
AIの作ったアートに初めて著作権登録が認められる - GIGAZINE
画像生成AIユーザーがAI学習用データセットから「自分の医療記録の写真」を発見してしまう - GIGAZINE
23億枚もの画像で構成された画像生成AI「Stable Diffusion」のデータセットのうち1200万枚がどこから入手した画像かを調査した結果が公開される - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, ネットサービス, ウェブアプリ, Posted by log1i_yk
You can read the machine translated English article Criticism that ``companies are escaping ….