




ウェブサイトの情報を自動で取得する「ウェブスクレイピング」をJavaScriptで行う方法

ウェブサイトの情報を自動で取得するウェブスクレイピングは、情報収集をプログラムに任せて時間の節約ができるほか、毎回同じ操作を正確に行えるのでヒューマンエラーの防止にも役立ちます。そんなウェブスクレイピングをJavaScriptで行う方法について、エンジニアのPavel Prokudin氏がサンプルコードを用いて解説しています。
Web scraping with JS | Analog Forest
https://qoob.cc/web-scraping/
ウェブスクレイピングのツール群としては、プログラミング言語にPython 3、HTMLの取得にRequestsライブラリ、HTMLの解析にBeautiful Soupがよく用いられます。しかし、このツール群によるスクレイピング手法は数年前から変化がないことに加え、JavaScriptエンジニアにとっては利用コストが高いとProkudinは指摘。これからJavaScriptでウェブスクレイピングをしたい人のためのドキュメントを整備したいとProkudin氏は語っています。
◆データを事前確認する
まずはウェブスクレイピングを行う前に「ウェブスクレイピングが必要かどうか」を確認しておくべきだとProkudin氏はアドバイスしています。最近のウェブアプリケーションはHTMLにデータを直接記述するのではなく、構造化されたデータを動的に生成していることが多いため、そもそもウェブスクレイピングをせずともデータを取得できてしまうことが多いとのこと。
◆データを取得する
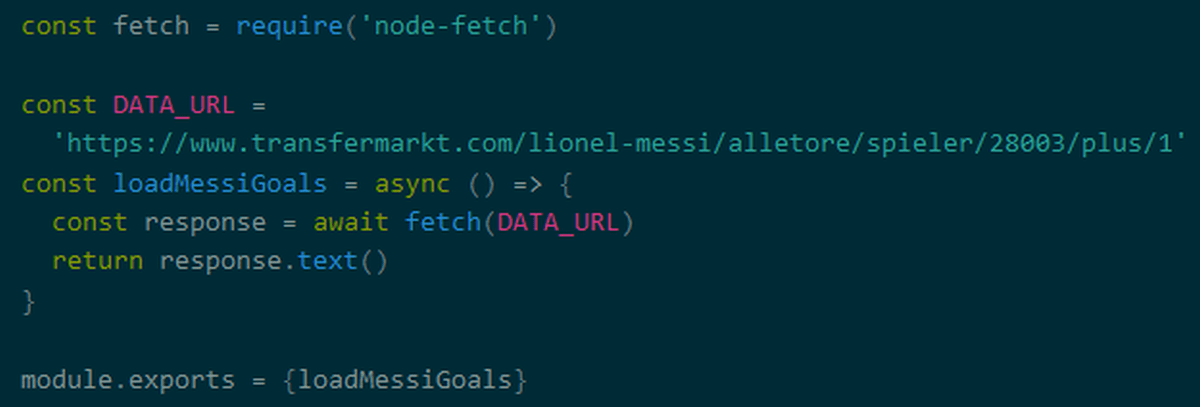
ウェブスクレイピングが必要な場合は、まずウェブサイトからHTMLデータそのものを取得します。Node.jsのHTTPS標準モジュールをそのまま利用することも可能ですが、Prokudin氏は非同期処理に対応しているnode-fetchを推奨。以下のコードではサッカーの試合結果などの情報を提供しているウェブサイト「
Transfermarkt」からリオネル・メッシ選手に関するページのHTMLを取得しています。
◆データを解析する
取得したHTMLを解析するツールにはcheerioやjsdomなどがあり、Prokudin氏はサンプルコードでjsdomを使用しています。まずは取得したHTMLをプログラムで扱えるようにするため、ドキュメントオブジェクトモデル(DOM)を作成。

作成したDOMから取得したい情報が存在している部分のCSSセレクターを指定して、NodeListオブジェクトを生成。その後Array.from()メソッドを使ってNodeListオブジェクトをArrayオブジェクトに変換します。これで欲しい情報を扱いやすい配列の形で取得することができました。

◆データを処理する
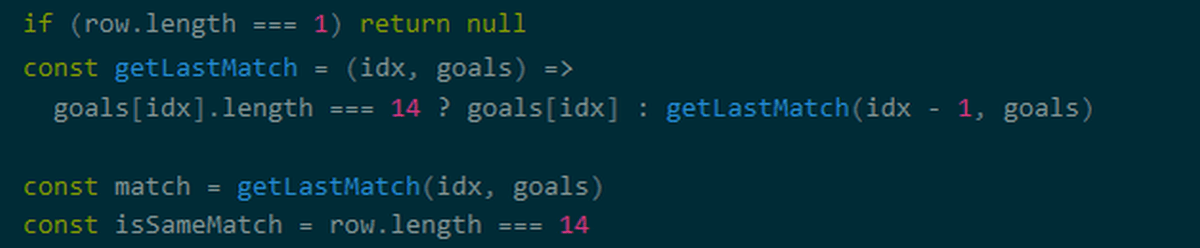
取得した配列には不要な情報が含まれているため、必要な情報のみ残すように処理を行うとのこと。Prokudin氏のサンプルコードでは、配列内の行の長さを取得して、データの形状を調べています。今回のサンプルコードで取得した配列は、長さが1、5、14、15の4種類の長さの行を持っています。

行の長さに応じて処理を加えていきます。長さが15の行は先頭から5番目までの値と、6番目以降の値に分離。

そのほかにもProkudin氏のコードでは、長さが1の行は除外するといった処理が行われています。
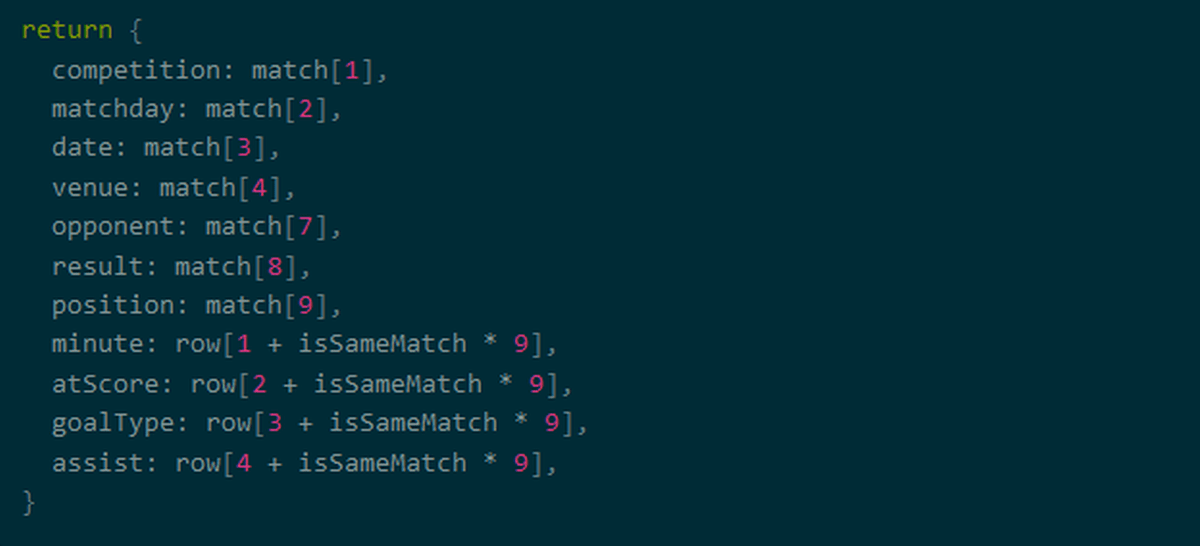
最後に配列の値をマッピングすれば、データの処理は完了。
◆データを保存する
あとは処理したデータを保存すればOK。これでPythonを使わずにウェブスクレイピングすることができます。

Prokudin氏がチュートリアルに用いた全サンプルコードはCodeSandboxに公開されています。
・関連記事
ウェブサイトからデータを自動で収集する「スクレイピング」を実行する方法と注意点 - GIGAZINE
インターネットに公開された情報は「法律による保護の対象ではない」と裁判所が認める - GIGAZINE
住みたい物件のURLを貼り付けるだけで家賃・初期費用・2年間トータル費用などの比較表が作れる「家探しのための Suumo スクレイピング用スプレッドシート」 - GIGAZINE
1996年から850億ものウェブサイトを保存している「Wayback Machine」 - GIGAZINE
画像をブックマークできるSNS「Pinterest」がGoogle画像検索の表示ランキングを故意に上げていると判明 - GIGAZINE
・関連コンテンツ




in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article How to perform 'web scraping' to automat….