画像認識モデルの「盲点」を克服するための奇妙な画像ばかり集めたデータセット「ObjectNet」をMITとIBMの研究チームが公開

人工知能(AI)を用いた画像認識モデルは、写真や映像の中に映り込む物体を正確に識別することを目的としたもので、自動運転車の外界認識機能などさまざまなものに応用されています。例えば自動運転車の場合、画像認識モデルの物体認識精度は自動運転車の安全性に直結してくるため、モデルの学習に使用するデータセットは非常に重要な役割を担うこととなります。そこで、マサチューセッツ工科大学(MIT)とIBMの研究者チームは、多種多様な物体を含んだ画像認識モデル向けのデータセット「ObjectNet」を作成しています。
This object-recognition dataset stumped the world’s best computer vision models | MIT News
https://news.mit.edu/2019/object-recognition-dataset-stumped-worlds-best-computer-vision-models-1210
画像認識モデル向けのデータセットである「ObjectNet」は、画像認識モデルの学習に使用するトレーニングセットを含まず、モデルの精度を検証するためのテストセットのみで構成されています。収録画像のテストセット数は、AIブームを引き起こしたクラウドソースのデータセットImageNetと同じ5万枚です。
ObjectNet
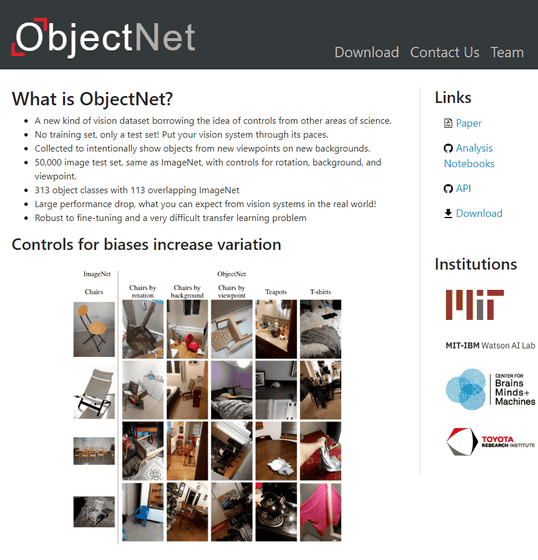
ImageNetはFlickrなどの写真共有サービス経由で収集された画像が収録されたデータセットですが、ObjectNetはフリーランスの写真家などに有料で依頼して撮影してもらった写真データをまとめたデータセットとなっています。物体をわざと横向きに傾けたり、普通は撮影しないような奇妙なアングルから撮影したり、わざと散らかった部屋の中で撮影したりすることで、画像認識が難しくなるような画像を集めているというわけ。
ImageNet(左)の場合、イスの写真は以下のようなわかりやすいものしか収録されていません。それに対してObjectNet(右)の場合、乱雑な部屋の中にイスが置かれていたり、イスの裏面が写された写真だったり、人間でも判断が難しいような写真が収録されています。

画像認識モデルはデータセットを用いてディープラーニングで画像認識精度を上げていきます。しかし、ImageNetのような膨大なデータセットでも、その中に含まれている画像は上記の例のように「イスの裏面」や「倒れたイス」などの画像が存在しないという盲点が存在するとのこと。そのため、ImageNetのような従来型のデータセットで学習した画像認識モデルでは、「イスの裏面」や「倒れたイス」のようなイレギュラーなケースに遭遇した場合、画像を正確に認識できません。
また、ObjectNetはその他のデータセットとは異なり、トレーニングセットが含まれていません。ほとんどのデータセットはモデルを学習するためのトレーニングセットと精度検証のためのテストセットが別々に用意されていますが、2つは類似性が高いため正確な精度検証ができないケースがあるとのこと。
実際に、主要な画像認識モデルでImageNetとObjectNetに収録された画像の認識テストを行ったところ、ImageNetの収録画像は最高97%の精度で正しく認識することに成功しましたが、ObjectNetの収録画像の場合はその精度が50~55%程度にまで低下したそうです。これは物体の裏面などを画像認識モデルが正確に認識できていないことの現れで、ObjectNetの開発に携わったIBMの研究者であるダン・ガットフレウンド氏は、「最新の画像認識モデルのアーキテクチャには物体の裏面や奇抜なアングルを認識するという概念が組み込まれていないことを表しています」と記しています。
研究を行った一人であるMITコンピューター科学・人工知能研究所(CSAIL)とCBMMで働く研究科学者のボリス・カッツ氏は、画像認識モデルについて「より優れ、よりスマートなアルゴリズムが必要です」と語っています。なお、ObjectNetについては2019年12月8日から14日までの期間開催されている、ニューラル情報処理システムに関する会議NeurlPSの中で、その成果を発表するとのことです。
NeurIPS | 2019
CSAILとCBMMで研究者として働くアンドレイ・バルブ氏は、「アルゴリズムが現実の世界でどれだけうまく機能するかを知りたい場合は、偏りがなく、これまで見たことのないような画像で画像認識モデルをテストする必要があります」と語り、ObjectNetは画像認識モデルを作成するためではなく検証するために作られたデータセットであると説明しています。
ObjectNet用の画像データはAmazon Mechanical Turkを利用して収集されたため、アメリカ国内のみならず世界中の国々で撮影された写真が収録されています。そのため、同じバナナの写真でも黄色のものもあれば緑色のものもあるなど、さまざまなバリエーションが含まれることとなっています。
・関連記事
「監視カメラの画像認識をだます服」をハッカー兼ファッションデザイナーが発表 - GIGAZINE
画像認識システムの落とし穴となる「ExifのOrientation属性」とは? - GIGAZINE
ニューラルネットワークを用いた画像認識は簡単にだますことができることを示すムービー - GIGAZINE
Googleが人間以上の能力を持つ画像認識AI「PlaNet」を開発していることが明らかに - GIGAZINE
自動運転を実現するGoogleの自動運転車の外界認識センサーはこんなにある - GIGAZINE
・関連コンテンツ