機械学習やビッグデータを扱うデータサイエンティストの年収や使用言語などを赤裸々にするデータ
By Carlos Muza
企業や研究者がデータを投稿し、世界中のアナリストやデータサイエンティストが予測モデリングや分析手法を競い合う、というプラットフォームの「Kaggle」が、2017年時点での機械学習やデータサイエンスに携わる人々がどのようなツールを使っているのかや、どれくらいの給料を得ているのかを如実に示すデータを公開しています。
The State of ML and Data Science 2017 | Kaggle
https://www.kaggle.com/surveys/2017
Kaggleが自サイトに登録するユーザーに向けて、データサイエンスと機械学習の利用状況を正確に把握するための調査を行いました。調査では1万6000件を超える回答を得られたそうで、世界中のデータサイエンティストやアナリスト、機械学習を用いるデベロッパーなどから、赤裸々な情報を入手しています。
まずはデータサイエンスに関わる人々の年齢層をチェック。以下のグラフが回答者の年齢をグラフで示したもので、中央値は「30歳」となっています。全体の中央値は30歳となっているのものの、この数字は国ごとに大きく異なっており、例えばインドのデータサイエンティストのは25歳で、オーストラリアは34歳と9歳も差があります。なお、日本の場合は中央値が33歳でした。
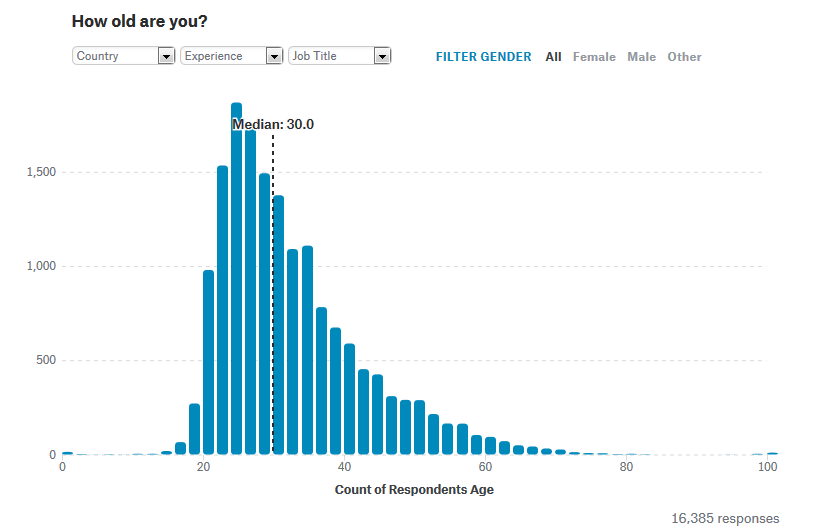
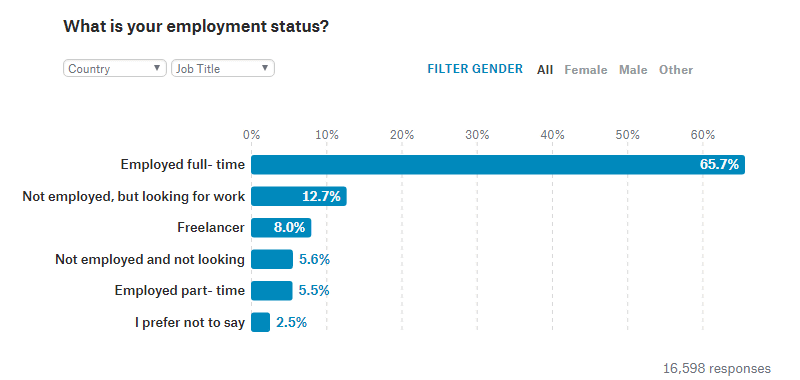
続いて、回答者がどのような雇用形態で働いているかについてのデータ。全体の65.7%が正社員として働いています。職探し中と回答したのが12.7%、フリーランスで働いているのが8%、仕事をしておらず職探しもしていないといのが5.6%、パートタイムとして働いているのが5.5%となっています。
次は「何という名前の職業についているのか?」という質問への回答。最も多いのはデータサイエンティスト(24.4%)で、全体の4分の1がデータサイエンティストとして働いているということになります。続いて、ソフトウェアデベロッパー/エンジニアが12.3%、データアナリストが11.3%、科学者/研究者が9.2%、機械学習エンジニアが5.9%と続いています。

以下のグラフは回答者の年間収入をグラフにしたもの。回答してくれたのは3771人で、中央値は5万5441ドル(約630万円)という結果に。アメリカでは各職種のうち、平均すると最も高額な給料をもらっているのは「機械学習エンジニア」でした。
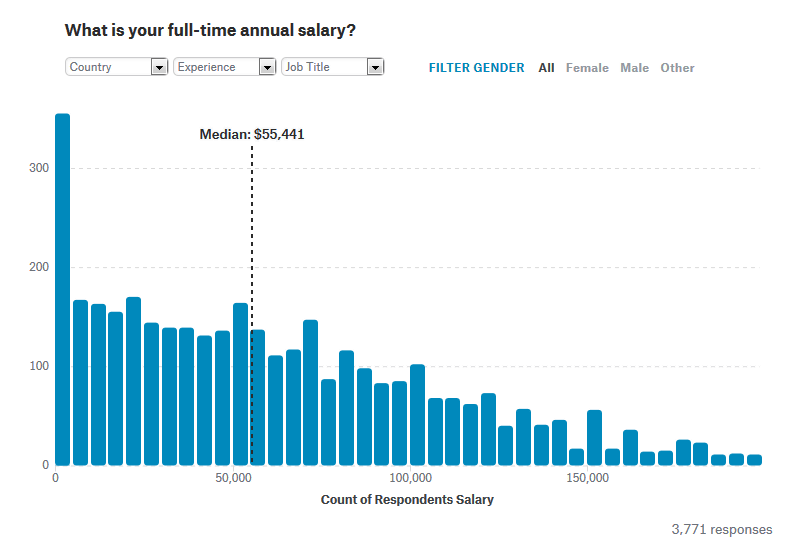
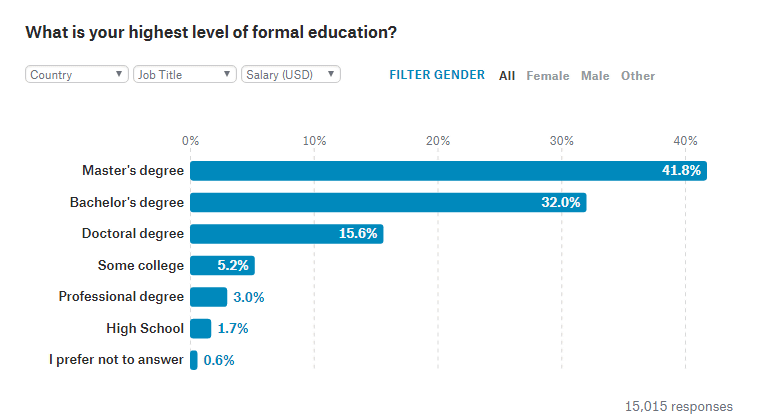
回答者の中で最も多いのは修士号を取得しているユーザー。ただし、給料が最も高い15万ドル(約1700万円)以上の回答者には、博士号取得者が多いようです。
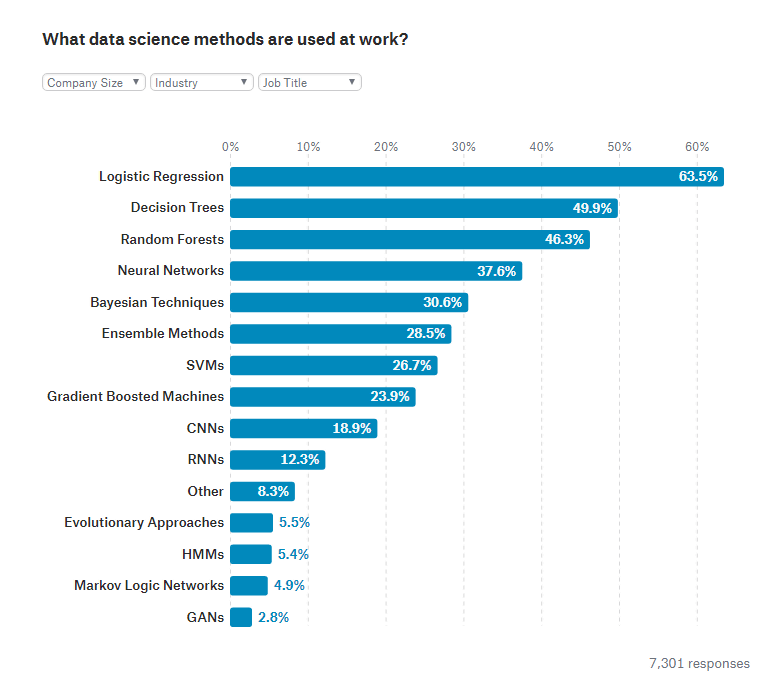
データサイエンスにおいてどのような手法を用いているかを質問したところ、「ロジスティック回帰」を用いているという回答が63.5%、「決定木」が49.9%、「ランダムフォレスト」が46.3%、「ニューラルネットワーク」が37.6%。最も多くの人々が使っているロジスティック回帰は、ニューラルネットワークの使用が一般的となっている軍事・セキュリティ分野以外では、ほぼ全ての産業および職種で使用されているそうです。
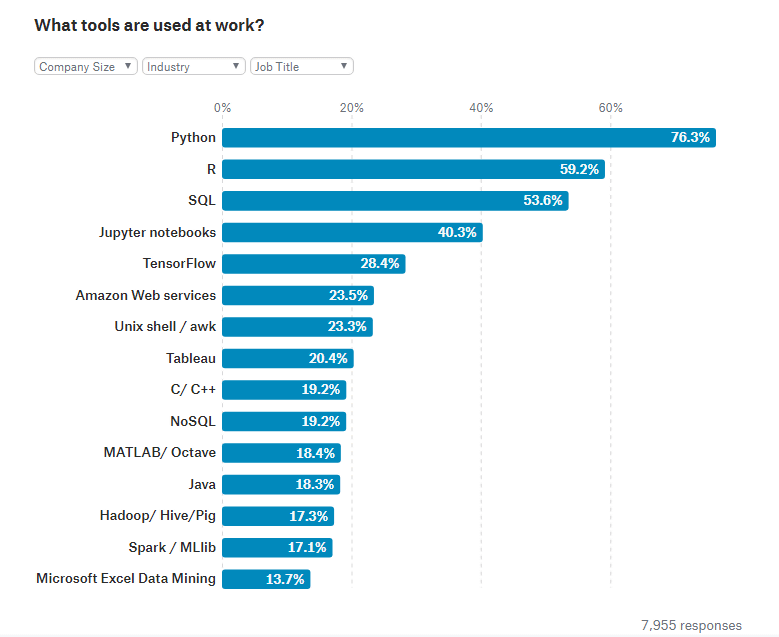
調査によると、最も一般的に使用されているプログラミング言語は「Python」で、なんと76.3%が使用していると回答。ただし、統計家にしぼると「R言語」を使用している割合が90.8%にまで伸びます。
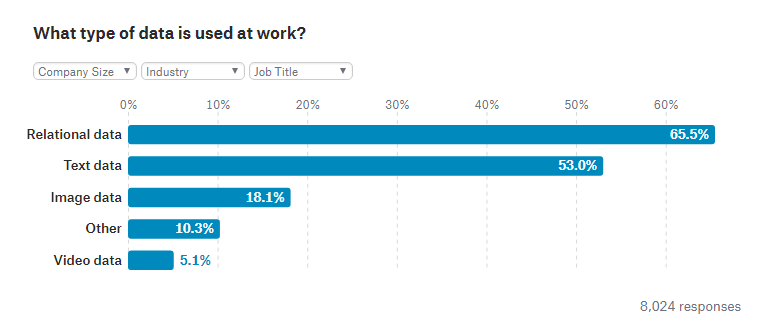
さらに、仕事で使用されているデータの種類としては、「関係データ(リレーショナルデータ)」が65.5%、「テキストデータ」が53.0%、「画像データ」が18.1%、「ムービーデータ」が5.1%、その他が10.3%。リレーショナルデータは、テキストデータが多く使用される学究的環境や軍事・セキュリティ分野以外では、どの分野でも最も多く使用されるデータの種類となっています。
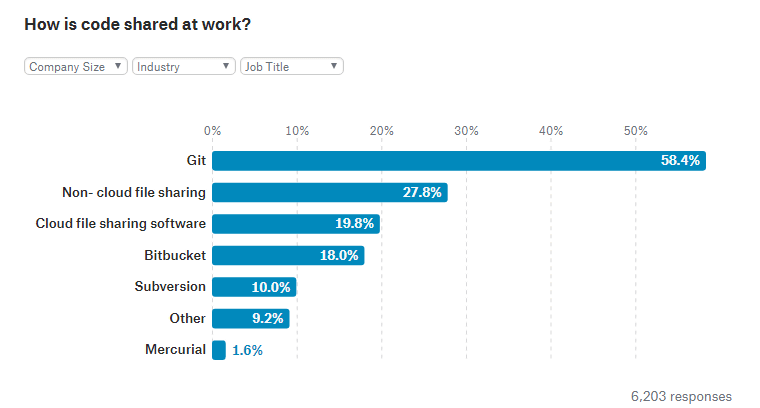
仕事でどうやってコードを共有しているかについては、58.4%ものユーザーがGitを利用していると回答しました。
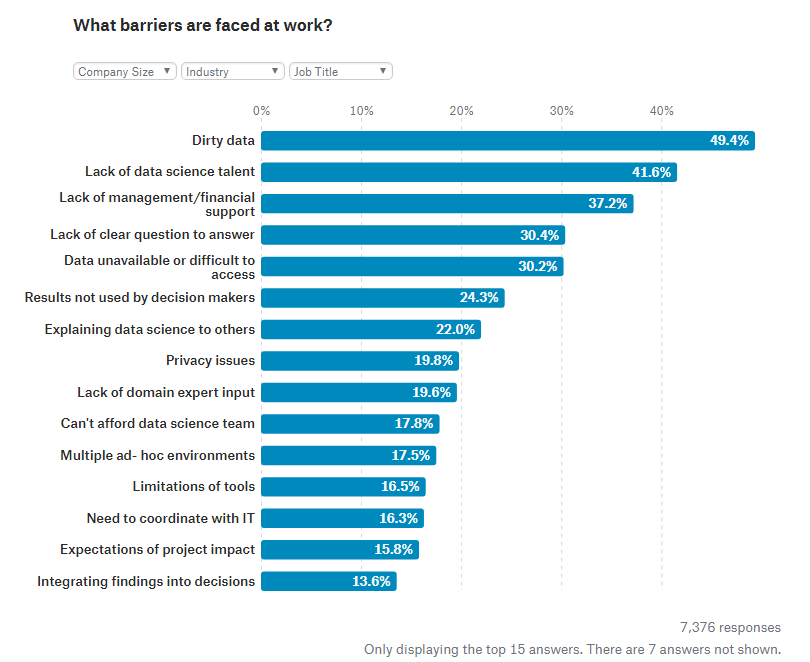
仕事における障害を聞いたところ、49.4%と約半数もの人が間違った情報を含む「Dirty data」と回答。Kaggleによると、「Dirty data」はデータサイエンス分野で働く人々にとって最も一般的な問題のひとつだそうです。なお、その他には「データサイエンス分野の人材不足」や「管理や財政面でのサポート不足」なども挙げられています。
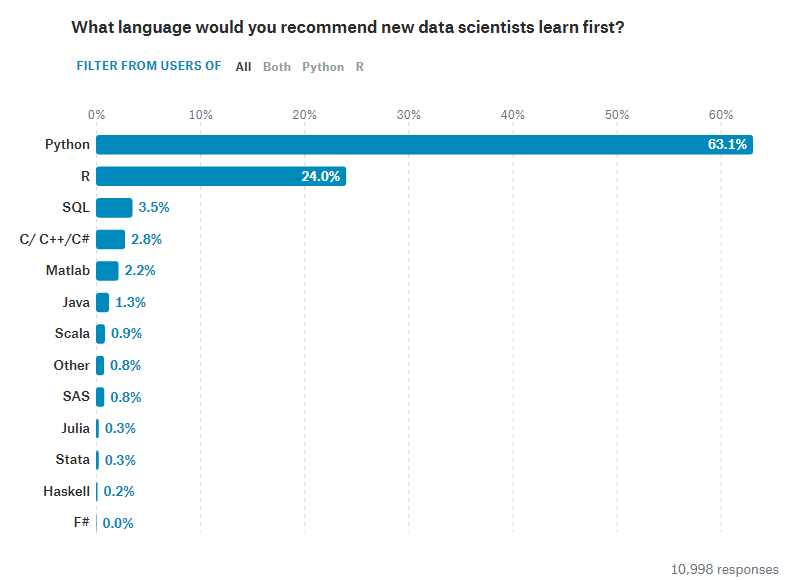
これからデータサイエンス分野に足を踏み入れる、という人にオススメする「最初に勉強すべきもの」は「Python」。
どのようなプラットフォームを用いてデータサイエンスについて学習しているのかを質問したところ、「Employed in Field(現場で雇用されている人)」と「Entering Field(これからデータサイエンス分野に入ってくる人)」の両方が、Kaggleで勉強していると回答。その他には、オンラインコースやブログ、YouTubeのムービーなどさまざまな勉強方法が挙げられています。

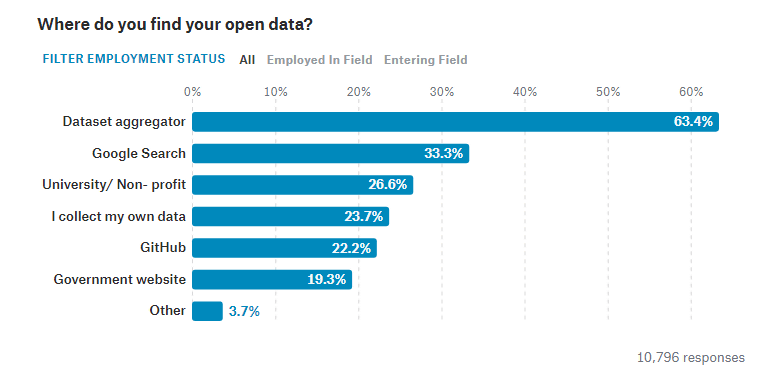
データサイエンスの勉強や実際の業務で使用するオープンデータをどこで見つけてきたかという質問には、Kaggleのような「データセットアグリゲーター」を使用するという人が最も多い63.4%となっており、その他は「Google Search」が33.3%、「大学」が26.6%、「自分で収集する」が23.7%、「GitHub」が22.2%、「政府のウェブサイト」が19.3%、その他が3.7%です。
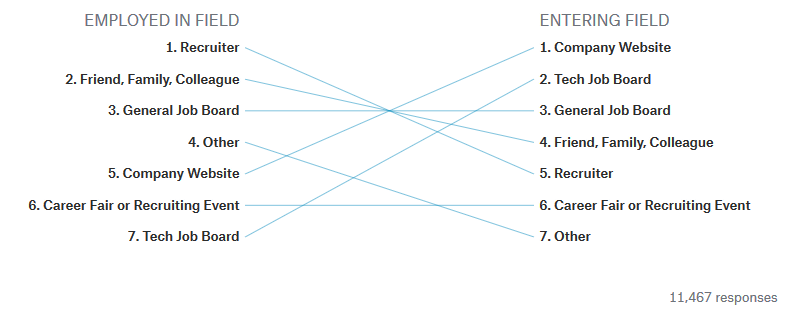
さらに、どうやって仕事を探したもしくは探しているかという質問に対しては、既に働いているユーザーはリクルーターを使用した人が多く、現在探し中である人は企業サイトを見て探していると回答しています。
・関連記事
初心者向け「機械学習とディープラーニングの違い」をシンプルに解説 - GIGAZINE
機械学習でGIGAZINEの関連記事を自動生成するサーバーを作ってみました - GIGAZINE
ビッグデータ解析・機械学習・人工知能の発展に伴って「パレートの法則(80:20の法則)」が進化している - GIGAZINE
人工知能・データサイエンス・暗号化などMicrosoftの研究者が予測する16の未来とは? - GIGAZINE
・関連コンテンツ