




人間の行動を1回見るだけで学習して次からは違う環境でも同じ行動と結果を再現できるロボットを人工知能研究団体「OpenAI」が公開

人工知能を研究する非営利団体のOpenAIが、人間が一度デモンストレーションするだけで、「行為の目的」を推測して環境が変化してもタスクを遂行できるロボット「Robots that Learn」を発表しています。
Robots that Learn
https://blog.openai.com/robots-that-learn/
Robots that Learnがどうすごいのかは以下のムービーから確認できます。
Robots that Learn - YouTube

生後10分ほどの赤ん坊の目の前で舌を出すと……

赤ん坊はそれをまねして舌を出します。2017年3月に発表されたOne-Shot Imitation Learningは、この行動と同じく「Imitation(模倣)」をカギとしたアルゴリズムで、一度のデモンストレーションでロボットに「何をするのか」を教えることが可能です。

ロボットに行動を教える側の人間が、VRを通して「6ブロックを積み上げて1つのタワーを作る」というタスクを行うと……

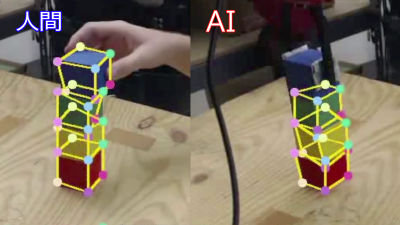
ロボットは一度のデモンストレーションで「6つのブロックを積み上げて1つのタワーを作る」というタスクの目的を理解し、その後、ブロックの置かれる位置が変わってもタスクを遂行することが可能。通常、さまざまな配置の6つのブロックを積み上げて「1つのタワーを作る」という同じ結果を生み出すということは、ロボットにとって非常に困難です。

もちろん、配置を換えてもブロックを積み上げる順序は同じです。
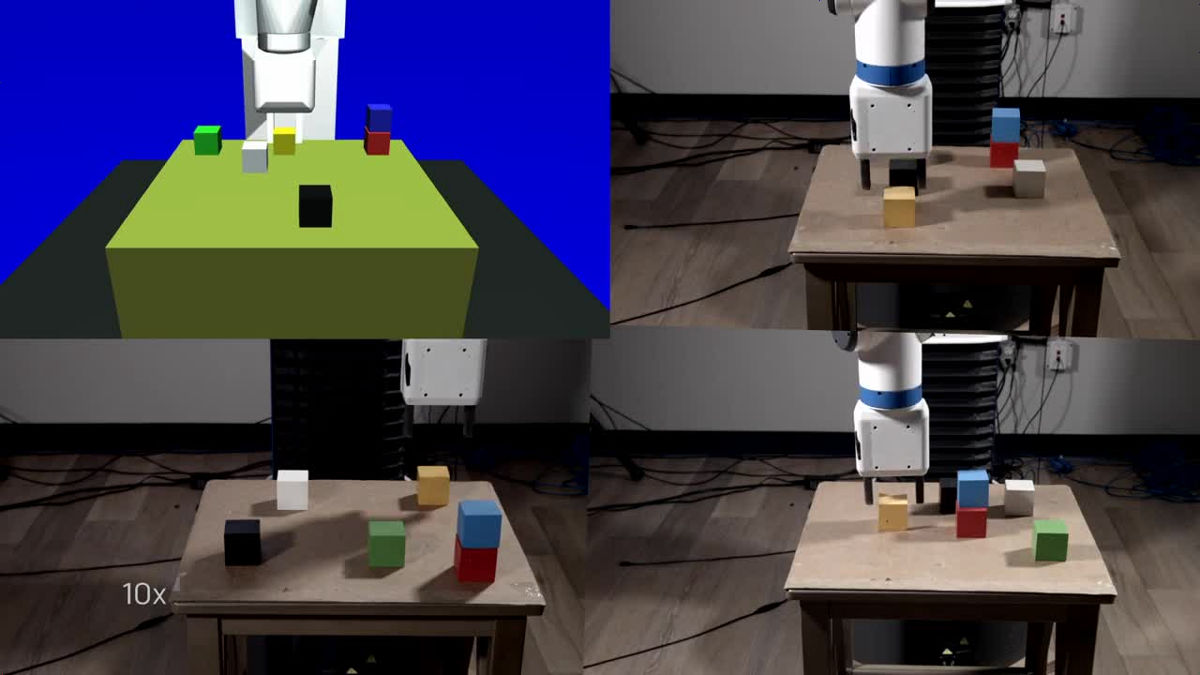
「ブロック2つを積み上げたタワーを計3つ作る」など、タスクの種類を変えたい時は、その都度一度だけデモンストレーションをしてみせればOK。

仕組みは以下の通り。ロボットにはカメラが搭載されているので、まずカメラを使ってロボットは環境を認識し、その後、アームでタスクを遂行します。
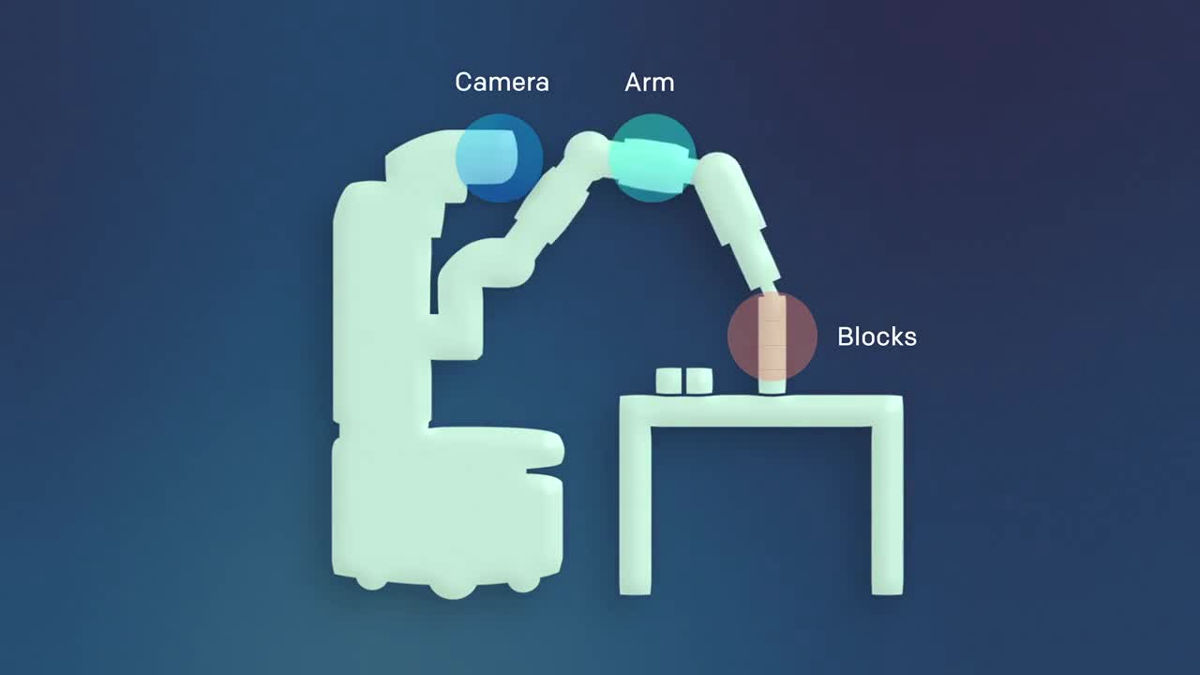
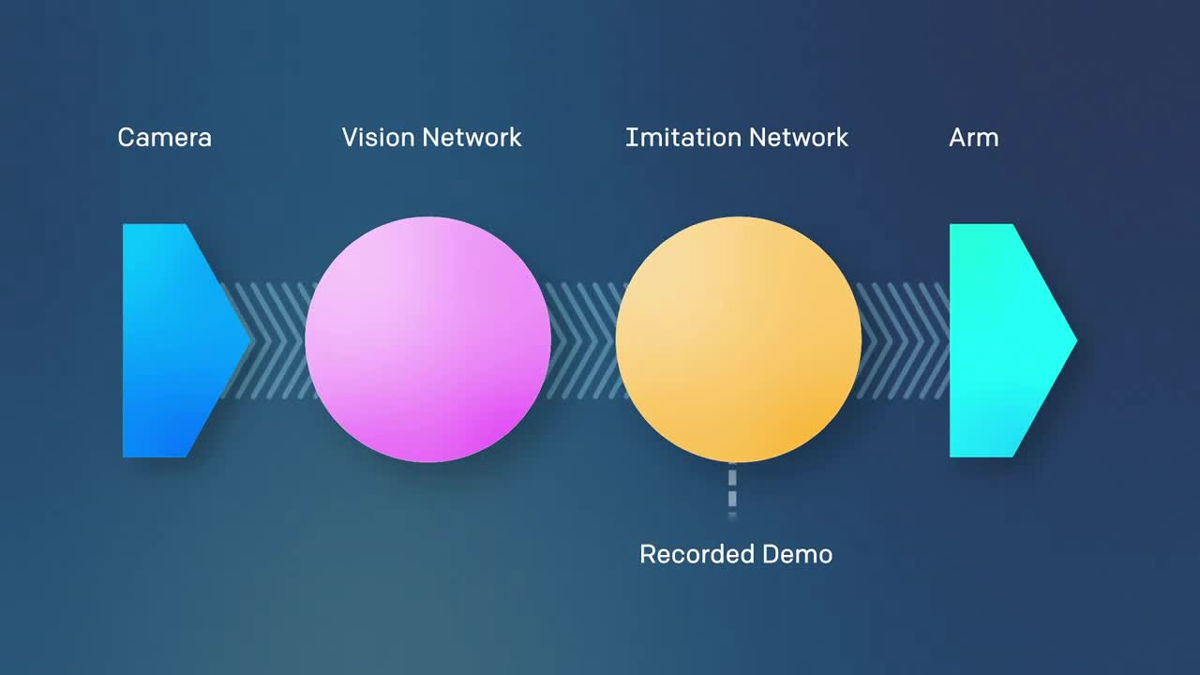
ロボットには「Vision Network」と「Imitation Network」の2つが搭載されており、まず、カメラで撮影された映像はVision Networkで処理されます。
Vision Networkは事前にライティング・テクスチャー・オブジェクトなどの条件を変えた何十万という画像を使って学習させられており、そこから現実の環境に置かれたオブジェクトの種類や配置や状態を判断します。
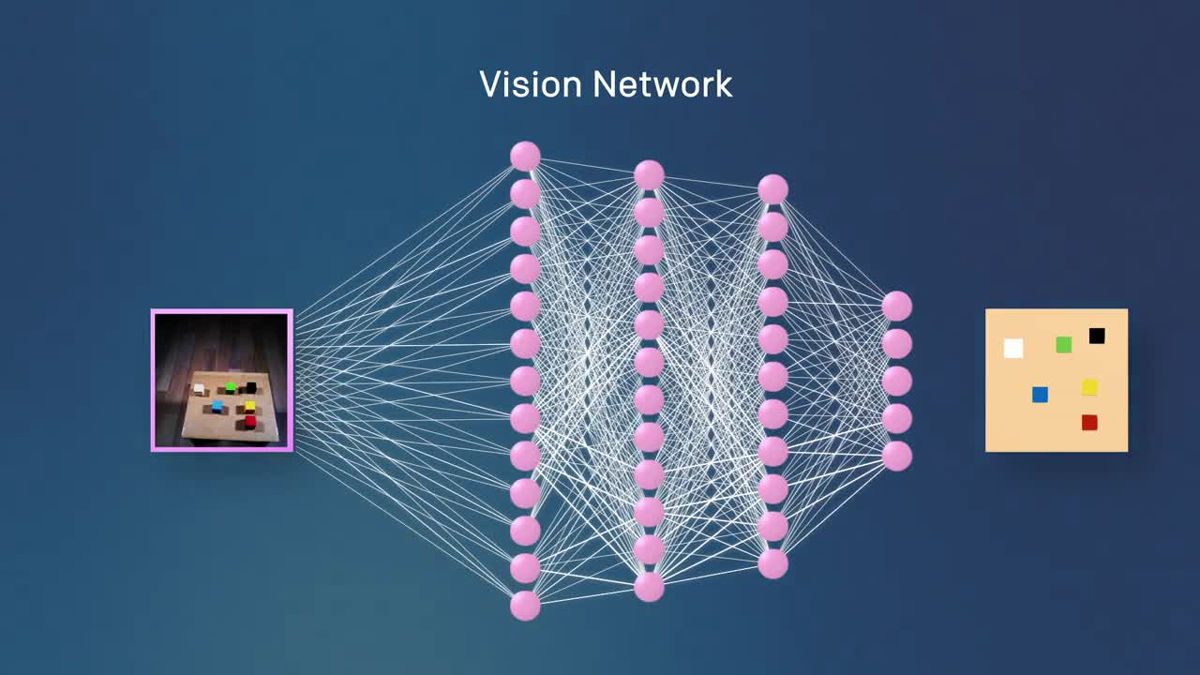
このとき、Vision Networkの学習に使われているのは実際の画像ではなく、以下のようなアニメーション・データとのこと。

学習が終わると、机の上にあるカラフルなボックスの位置をランダムに変更しても、ロボットはその配置の変化を検知できるようになります。例え、それがカメラを通して一度も見たことがない形であってもです。
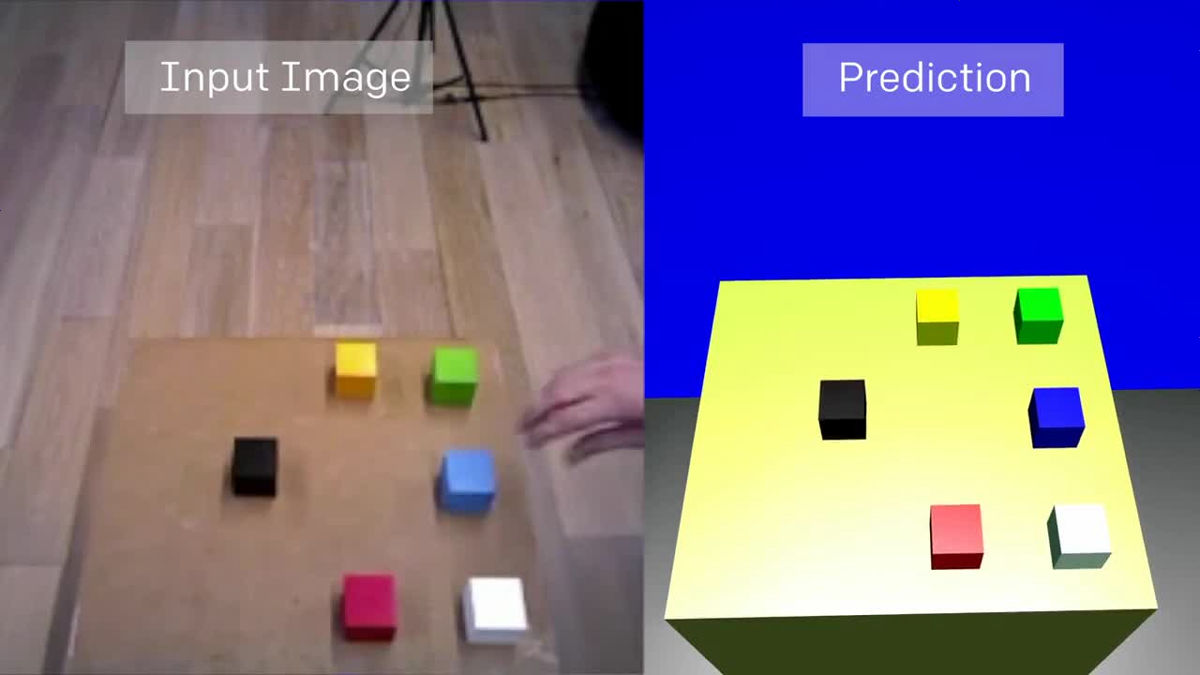
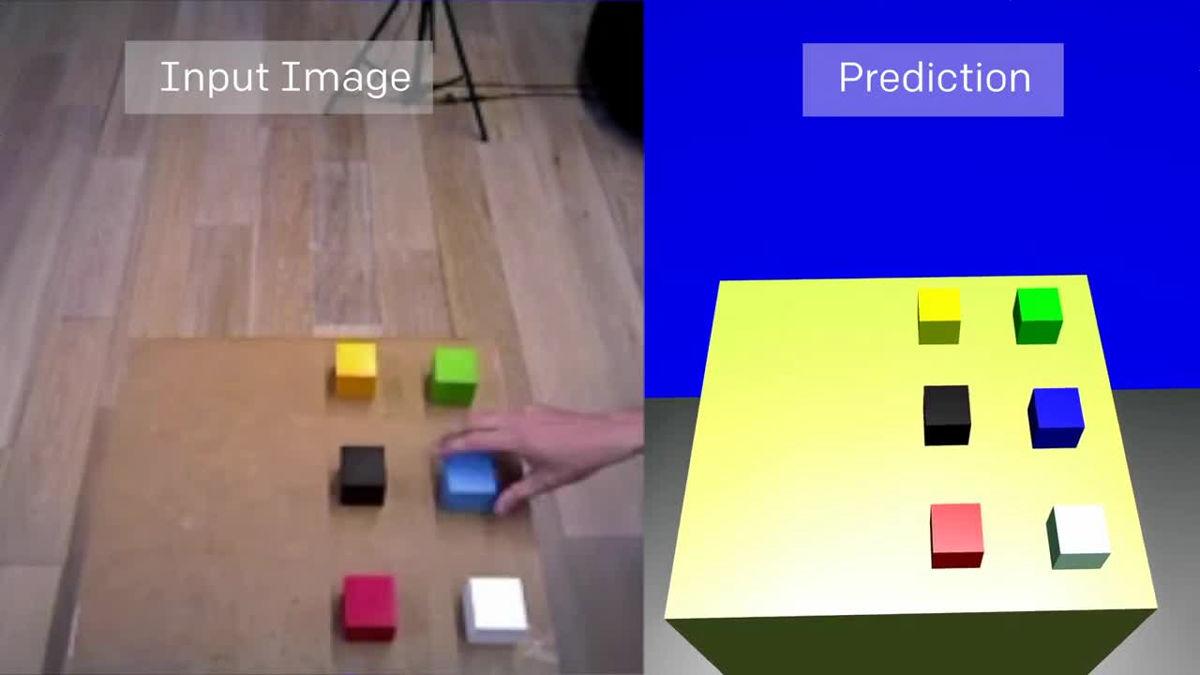
その後、Vision NetworkのデータをImitation Networkが引き継ぎます。
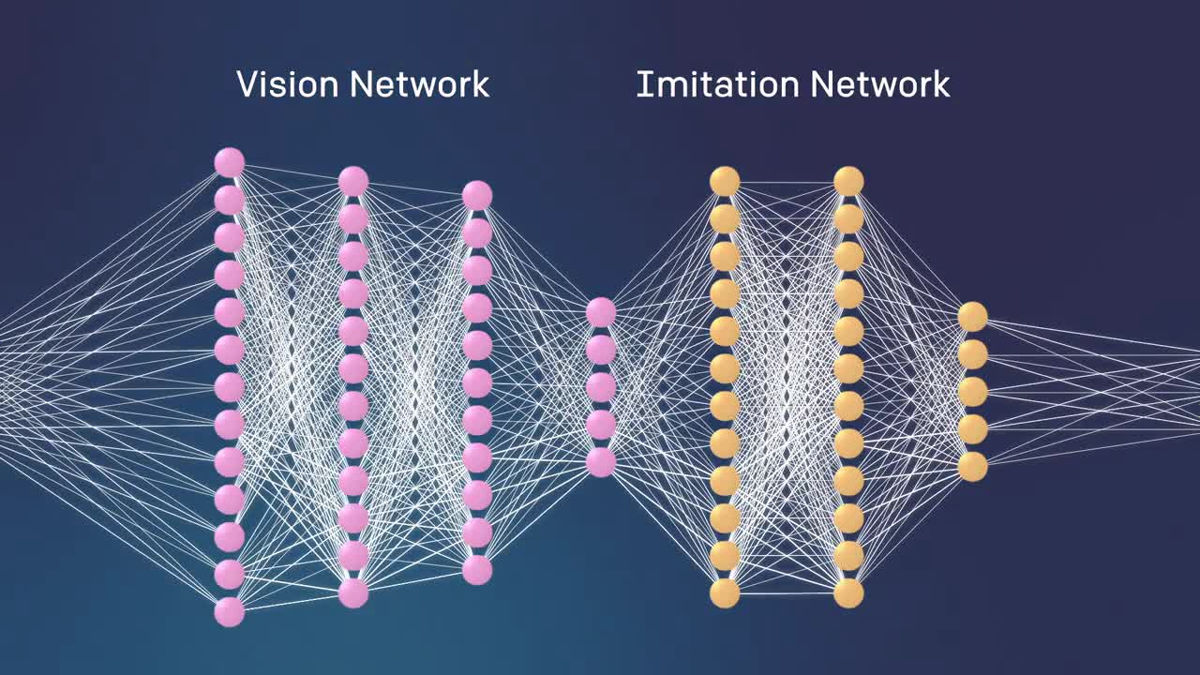
Imitation Networkはデモンストレーションで何が行われているかの情報を処理し、タスクの目的が何なのかを推測します。単に動きをまねするのではなく「目的」が推測されるので、例えブロックの置かれている位置が異なっても、タスクを完了できるわけです。

・関連記事
ロボットやAIが「権利を持つに等しい存在」になった時、人間はどう考えるべきなのか? - GIGAZINE
「セックスロボットは人間を過度に刺激する可能性がある」と専門家が警鐘を鳴らす - GIGAZINE
セックス用ロボットがまもなく現実のものに、実現に向けた課題とは? - GIGAZINE
ついに「痛み」を感じて反応するロボットが開発される - GIGAZINE
Pepperたちロボットの抱えるセキュリティリスクを研究者らが警告 - GIGAZINE
ボストン・ダイナミクスのロボット「Handle」は華麗にジャンプし45kgの荷物を運び雪道も難なく走行できることが判明 - GIGAZINE
・関連コンテンツ





in 動画, ハードウェア, Posted by darkhorse_log
You can read the machine translated English article An artificial intelligence research orga….