What are the new AI LLM architecture techniques 'Key-Value Sharing,' 'mHC,' and 'Compression Attention'?

As open-weighted large-scale language models (LLMs) evolve beyond prompt-based question-and-answer to autonomous and highly accurate problem-solving, inference models and agent workflows are indispensable techniques. However, the need to hold many tokens for extended periods means that resources such as key-value cache (KV cache) size, memory bandwidth, and attention cost become major constraints on execution. LLM developers have incorporated various techniques into the LLM architecture to reduce resource costs, but LLMs released between April and May 2026 tend to place a strong emphasis on optimizing long-text contexts, as LLM research engineer
Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention
https://magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures
◆Examples of new techniques
Raschka cites the following four LLMs as examples of new architectural techniques that he is particularly interested in:
• Gemma 4 : Key Value Sharing and Layer-Specific Embedding (PLE)
• Laguna XS.2 : Attention budget per layer
ZAYA1-8B : Compression Convolution Attention (CCA)
DeepSeek V4 : CSA/HCA, mHC, compressed attention cache
Many of the changes seen in the above LLM may appear as minor adjustments in the diagram provided by Mr. Raschka, but some of them are actually quite complex design changes that require closer examination.
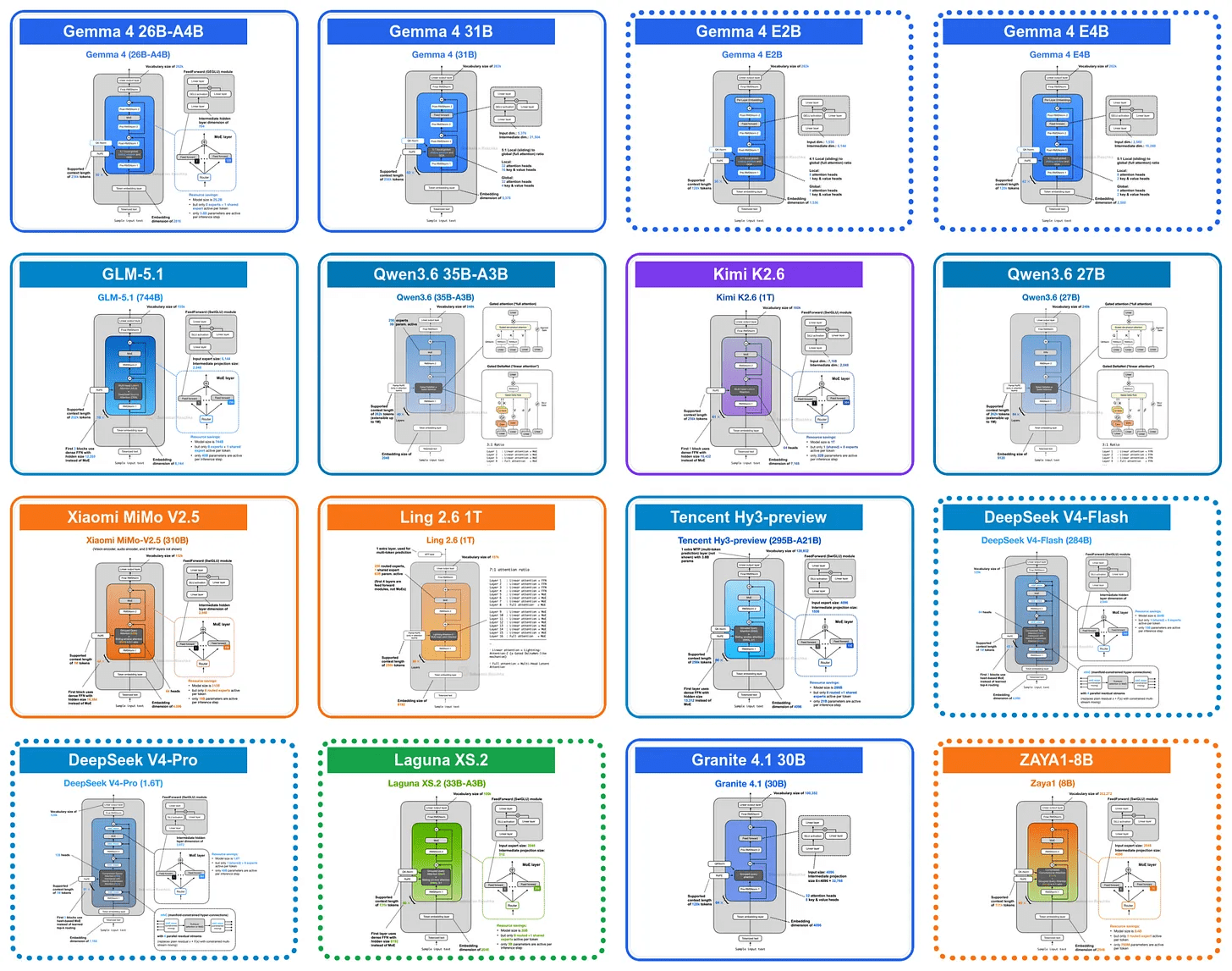
◆Gemma 4
One of the architectural changes in the E2B and E4B variants of Gemma 4 is '
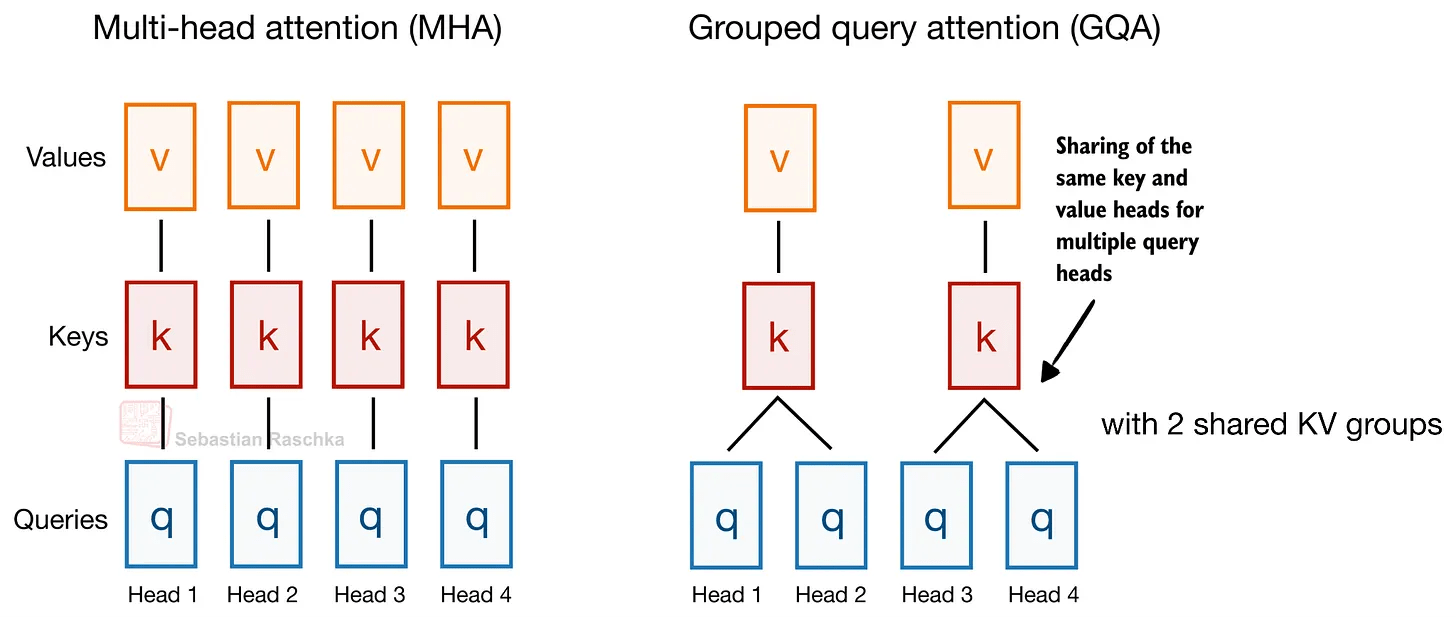
In addition to sharing key values (KVs) between queries using GQA, Gemma 4 also shares KV projections across different layers. This KV sharing method is also known as cross-layer attention (see diagram on the right below).
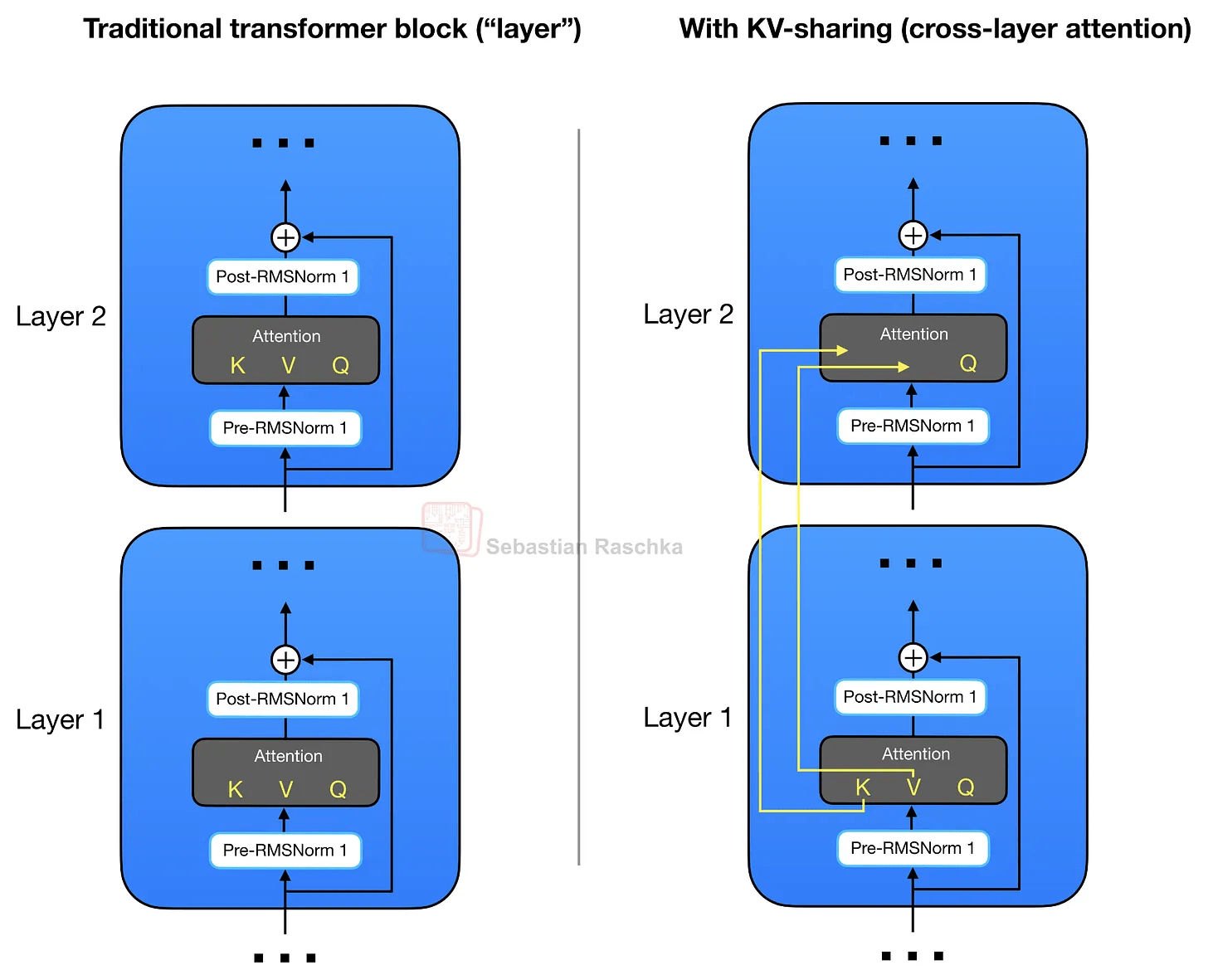
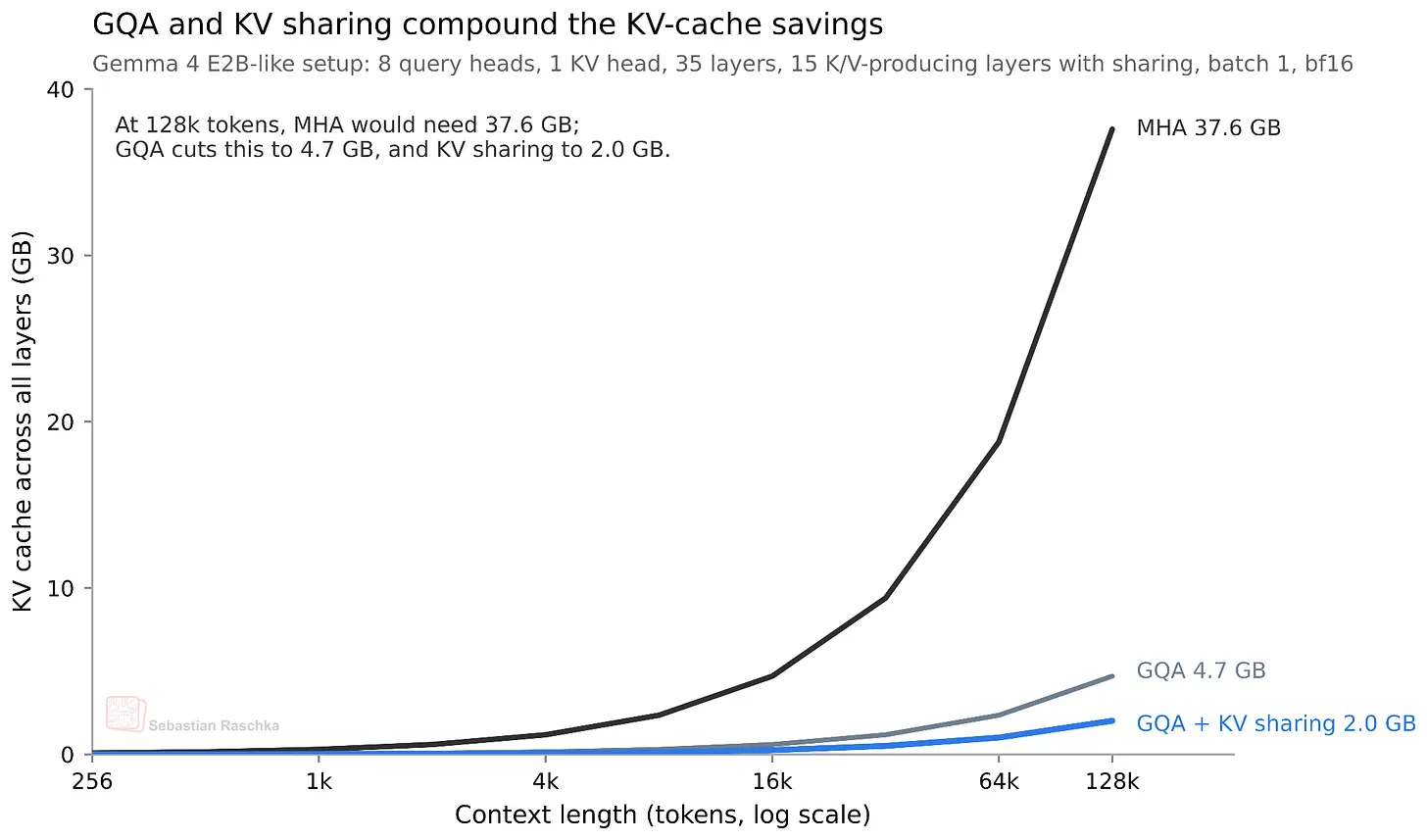
By sharing approximately half of the key value (KV) between layers, the KV cache size can also be reduced by about half. This results in a KV cache size reduction of approximately 2.7GB for the E2B model and approximately 6GB for the E4B model in a 128K long text context.
In addition to KV sharing, the E2B and E4B variants of Gemma 4 also employ a design option called ' Layer Embedding (PLE) ' that prioritizes efficiency. PLE is designed with parameter efficiency in mind, allowing smaller Gemma 4 models to utilize more token-specific information without incurring the same cost on the main transformer stack as high-density models with the same total number of parameters.
Conceptually, the PLE pass computes attention and feedforward residual updates, then gates the layer-specific PLE vectors, which are projected onto the model's hidden size, normalized, and added as additional residual updates. PLE construction takes two inputs: a per-layer embedding lookup of token IDs and a linear projection of normal token embeddings onto a packed PLE space. These two are added, scaled, and reshaped to form a tensor with one slice per layer, where each block receives its own slice.
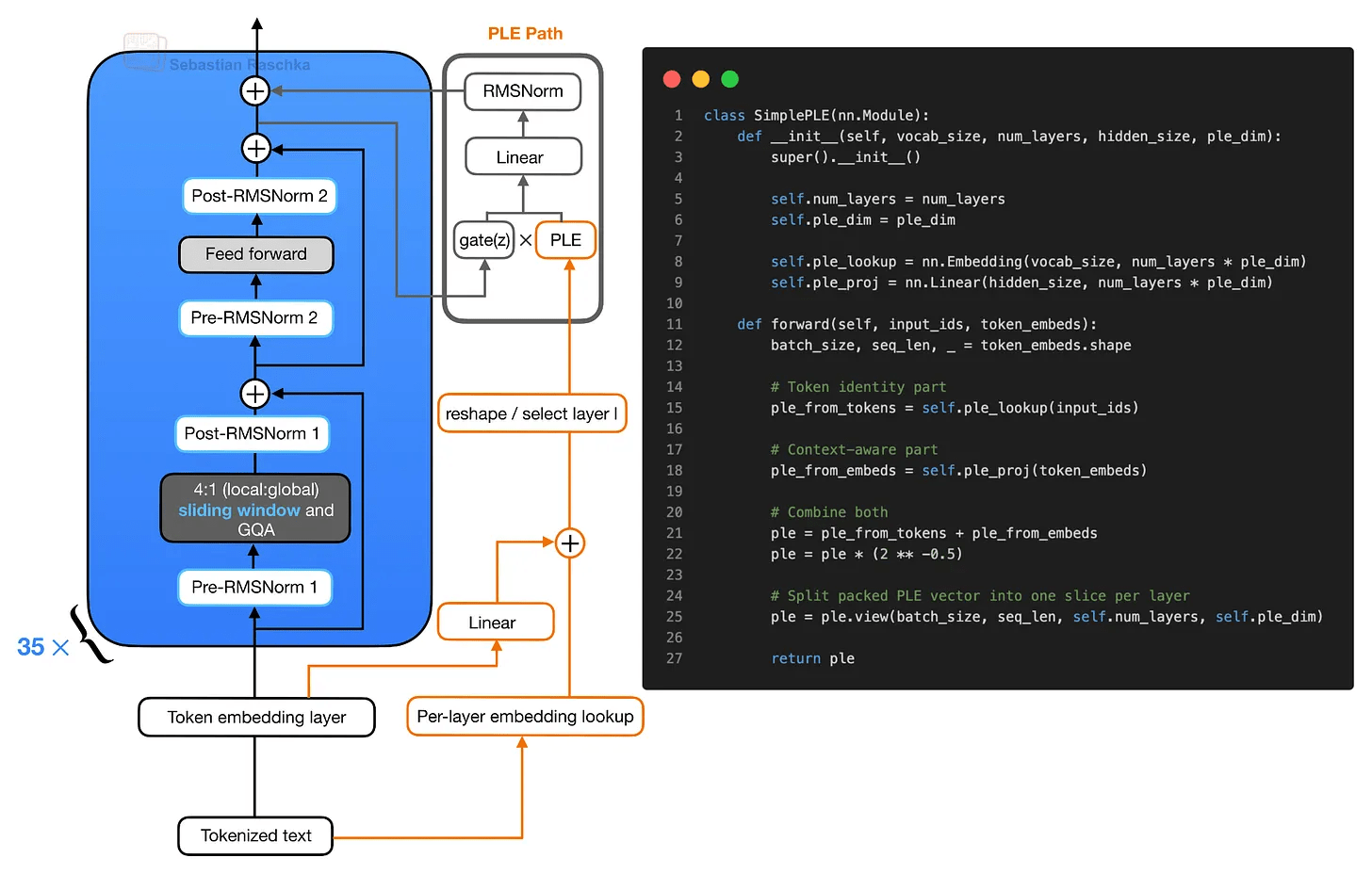
Instead of giving each transformer block a completely independent copy of the normal token embedding layer, PLE computes the embedding lookup for each layer only once, providing each layer with a small, token-specific embedding slice. PLE enhances the model's expressiveness by embedding parameters and small projections while keeping computational overhead low.
◆Laguna XS.2
While the architecture of Laguna XS.2 may appear very standard at first glance, it incorporates the concept of ' attention budget per layer .'
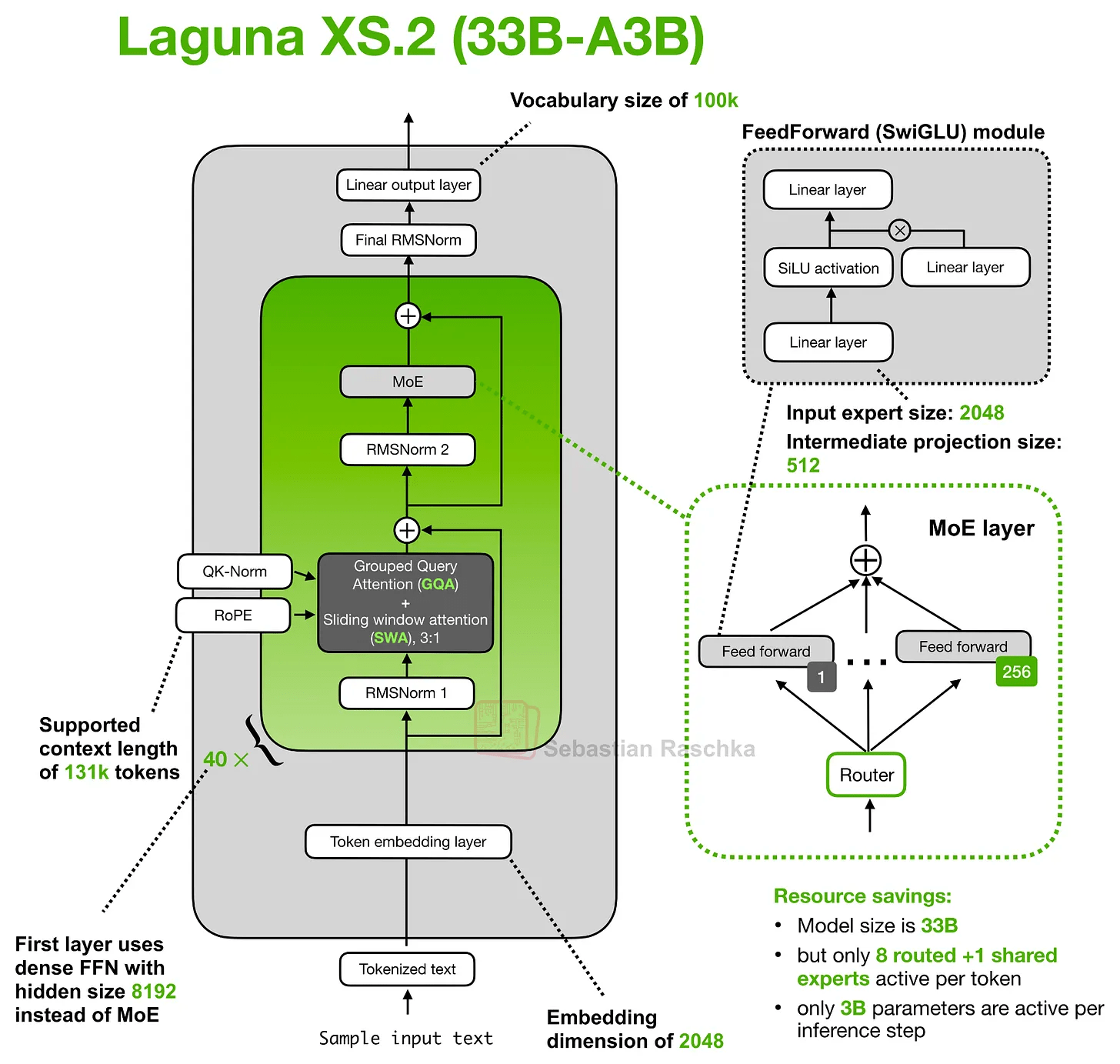
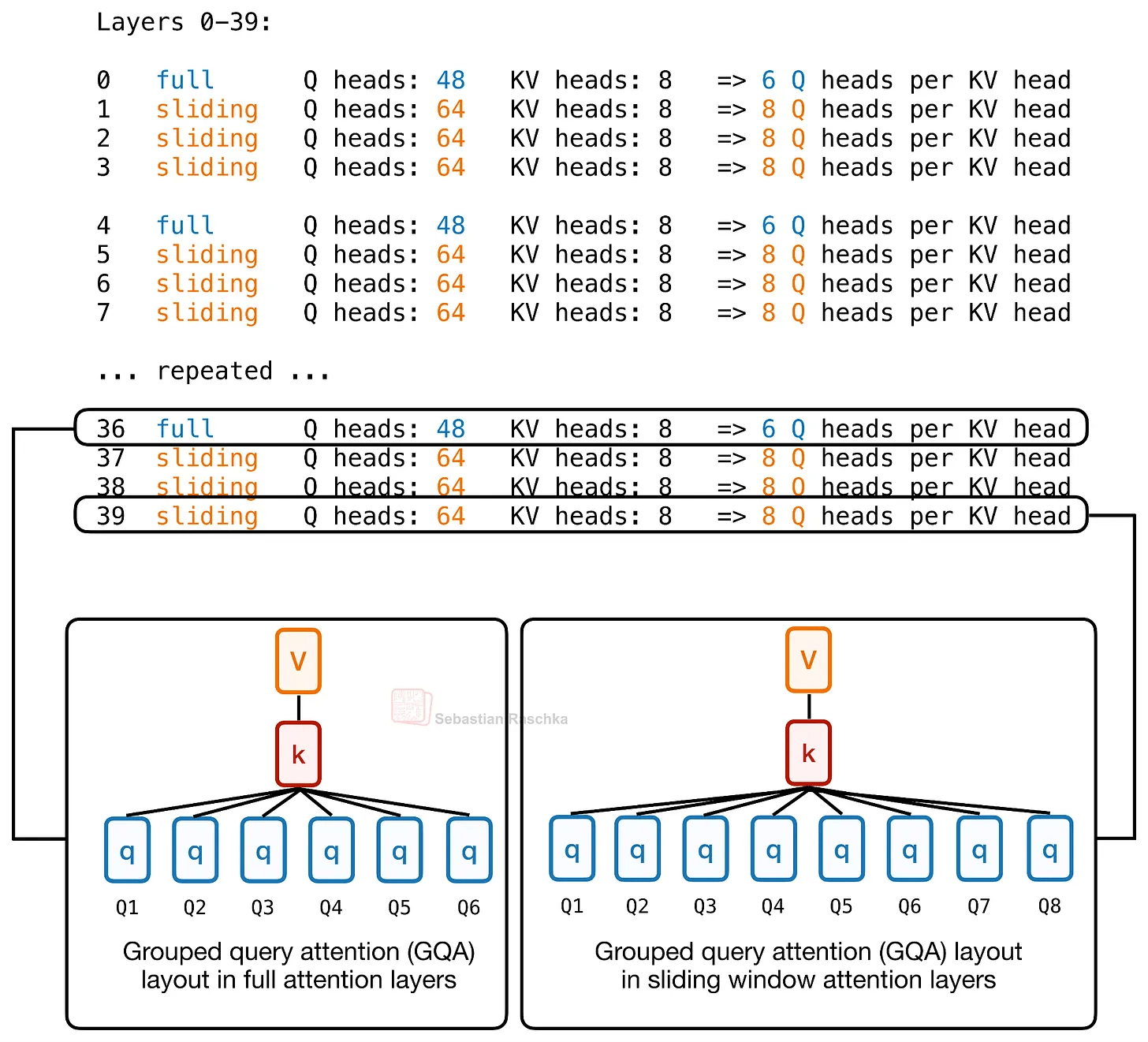
'Per layer' means that instead of allocating the same attention budget to all layers, the attention cost varies for each layer. Specifically, Laguna XS.2 has 30 Sliding Window attention layers and 10 Global/Full attention layers. The Sliding Window layers only apply attention to local windows, thus reducing the cost of KV caching and attention calculations. In contrast, the Global layers are more expensive, but they maintain the ability to access all information within the context window.
On the other hand, looking at the number of query heads per layer, Laguna XS.2 allocates many query heads to the sliding window layer and fewer to the global layer, which is costly because it scans the entire context. In other words, by adjusting the number of query heads per layer, attention capabilities are concentrated where they are most useful.
◆ZAYA1-8B
A key architectural feature of ZAYA1-8B is the ' Compressed Convolution Attention (CCA) ' used in combination with
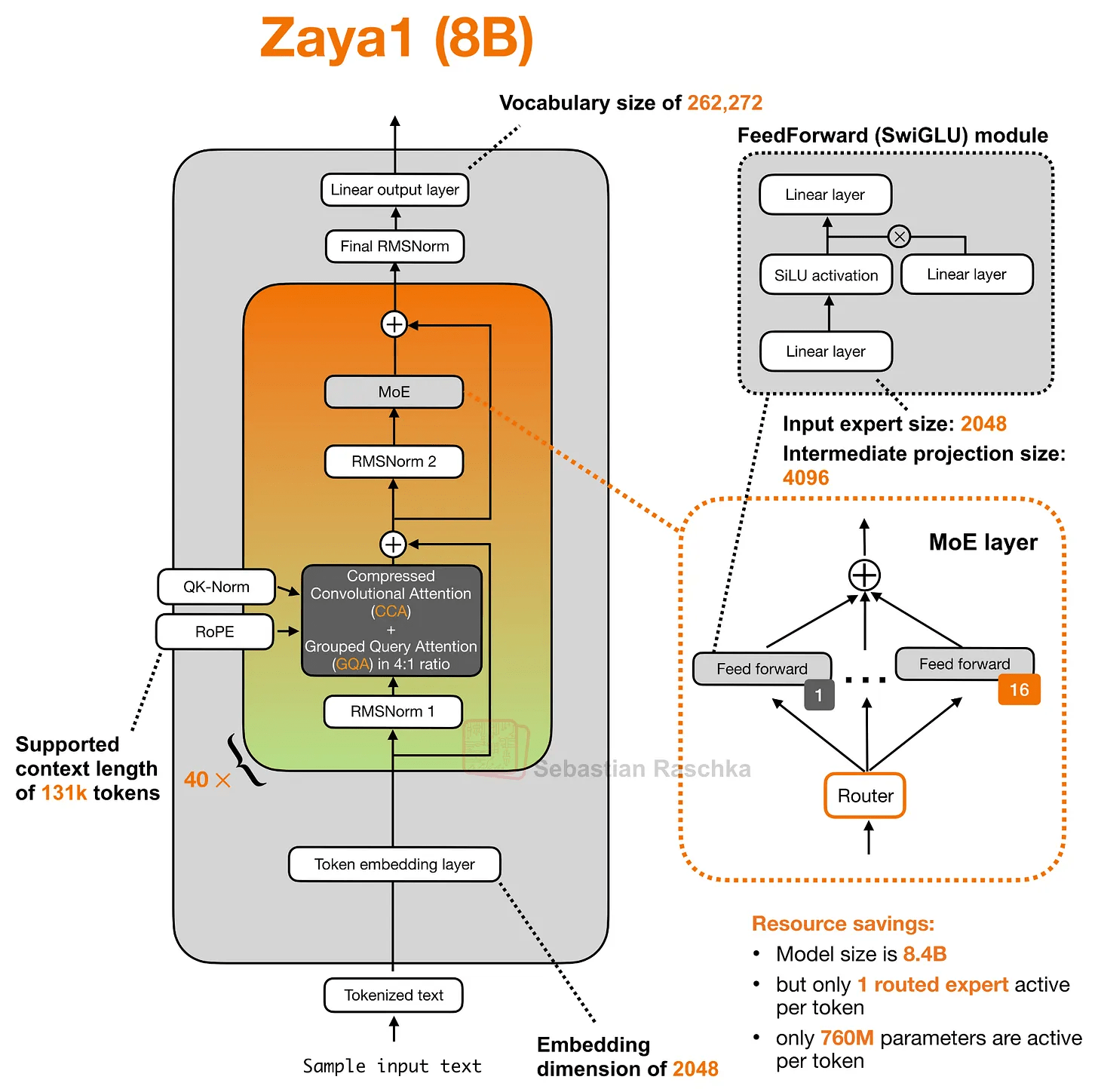
While CCA is similar to Multi-Head Latent Attention (MLA) in that it introduces a compressed latent representation into the attention block, MLA's main focus is on addressing the issue of increasing KV cache size, which was a problem with
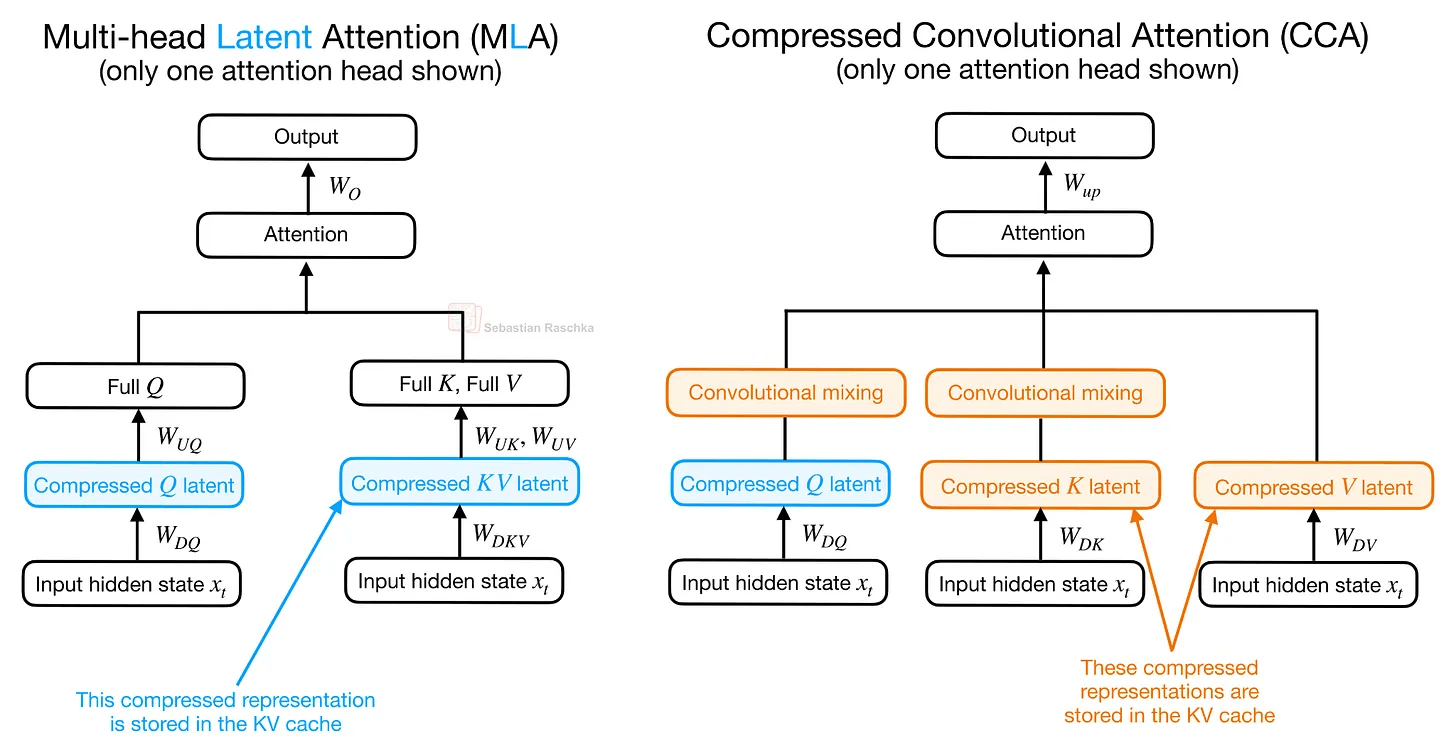
In
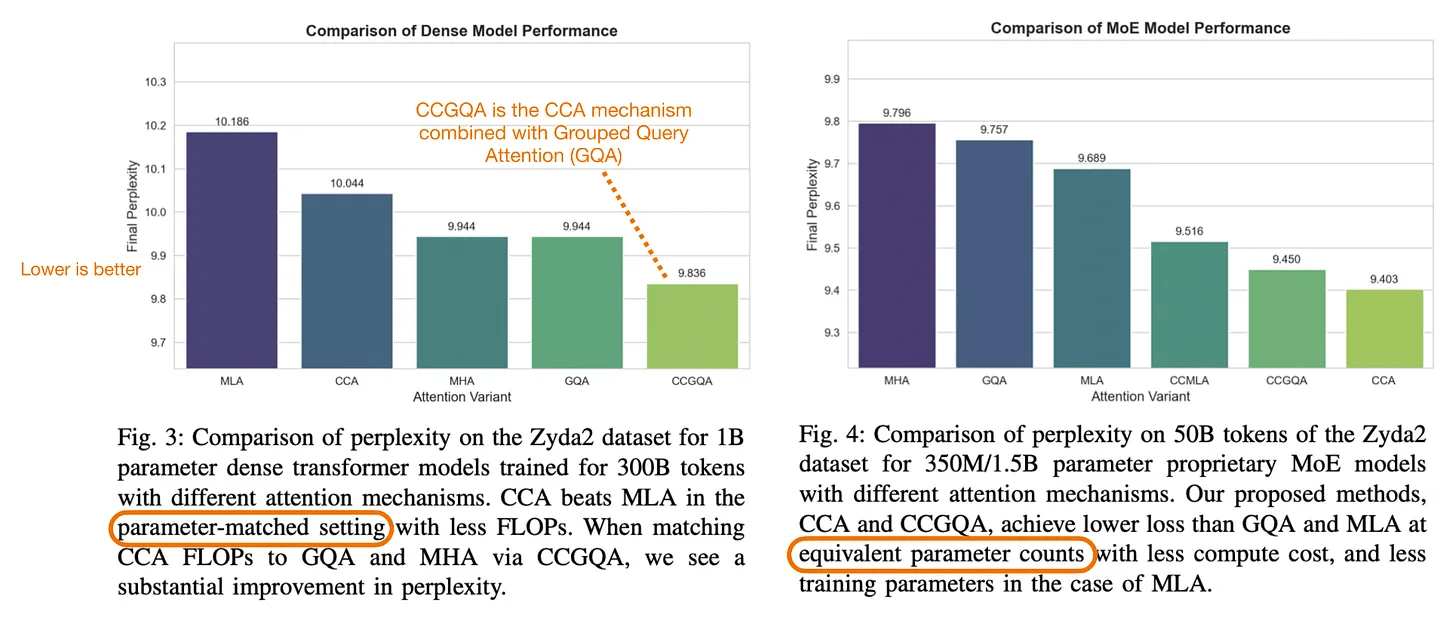
◆DeepSeek V4
While the architecture of DeepSeek V4 appears complex and intertwined when illustrated, it becomes easier to understand if you separate and consider the changes in the residual path (mHC), the changes in the attention path (CSA/HCA), and the compressed attention cache.
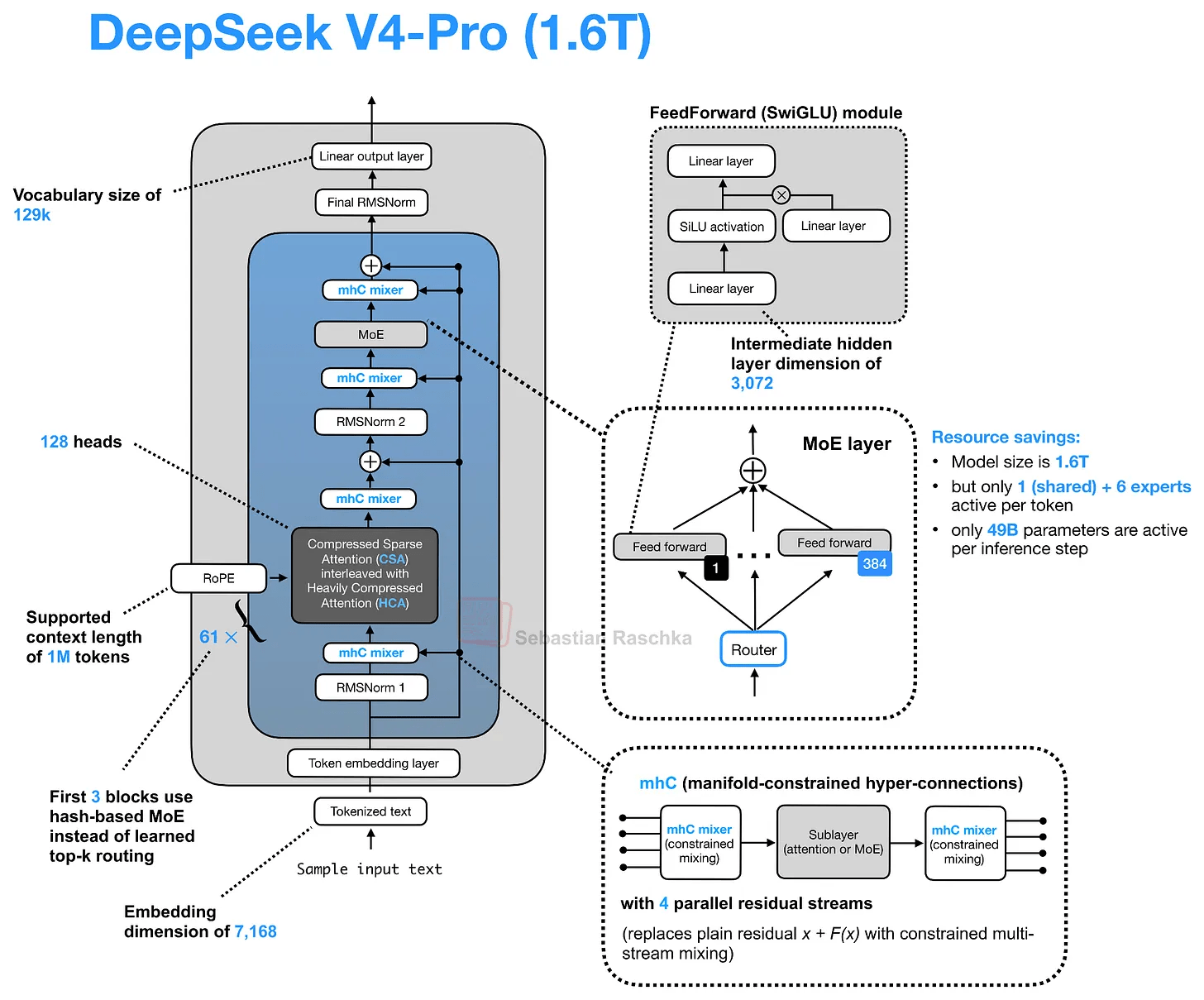
The primary objective of ' Multi-Method Hyperconnection (mHC) ' is to modernize residual connections within transformer blocks, and as the name suggests, it is based on research into
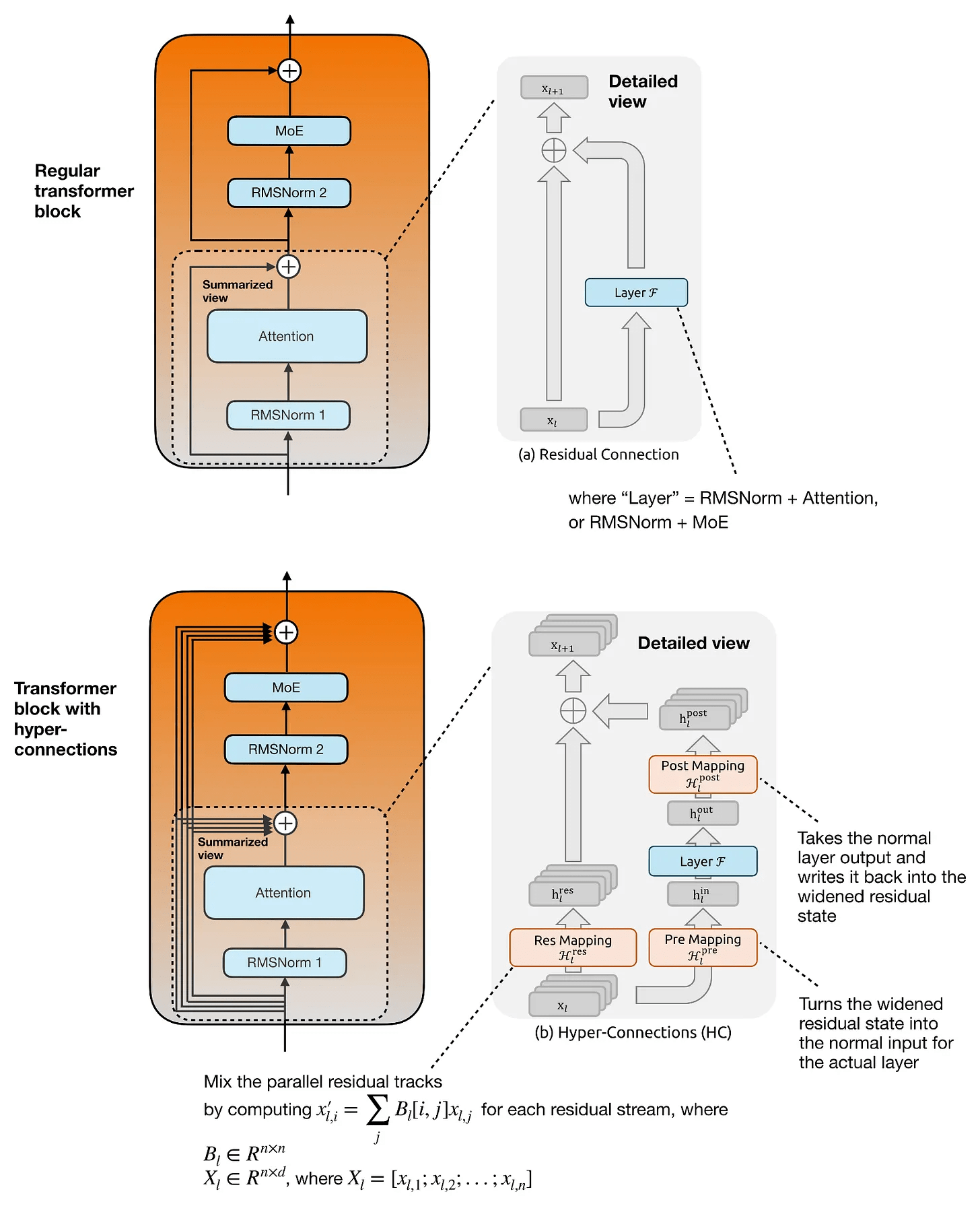
The most significant difference between a regular hyperconnection and mHC is that 'mapping is no longer unconstrained.' Unlike residual mapping using pre-trained matrices in a regular hyperconnection, in mHC, residual mapping is projected onto a manifold of double-stochastic matrices. This imposes constraints that 'all entries are non-negative' and 'the sum of each row and column is 1.' These constraints cause the residual mixture to behave as a stable redistribution of information across the entire stream. Furthermore, pre-mappings and post-mappings are also constrained to be non-negative and bounded, preventing cancellation when reading and writing from the extended residual state. In short, the key point for large-scale models is that mHC adds constraints that allow for safer scaling while maintaining the rich residual mixture of a hyperconnection.
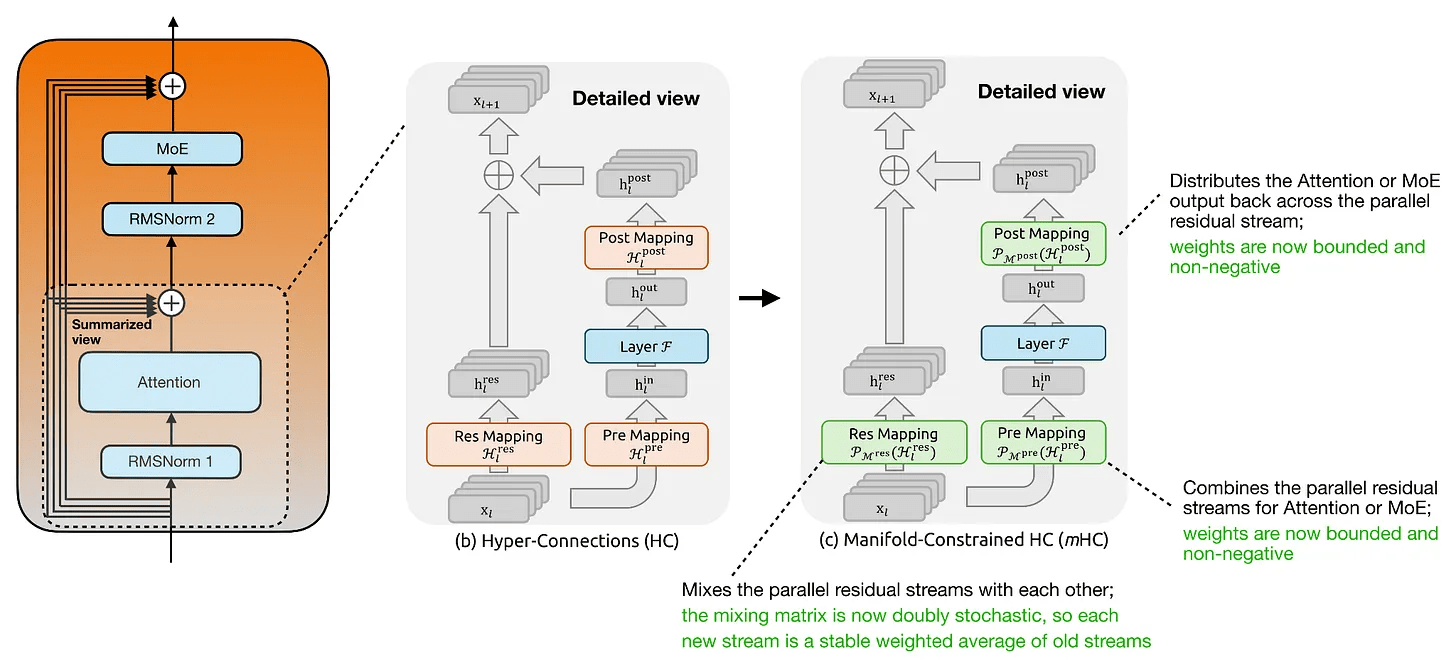
In summary, mHC modifies the way information is passed between layers and applies stability constraints while minimizing computational overhead. Furthermore, mHC is said to be well-suited to the attention changes in ' CSA/HCA, ' another major change in the DeepSeek V4 architecture.
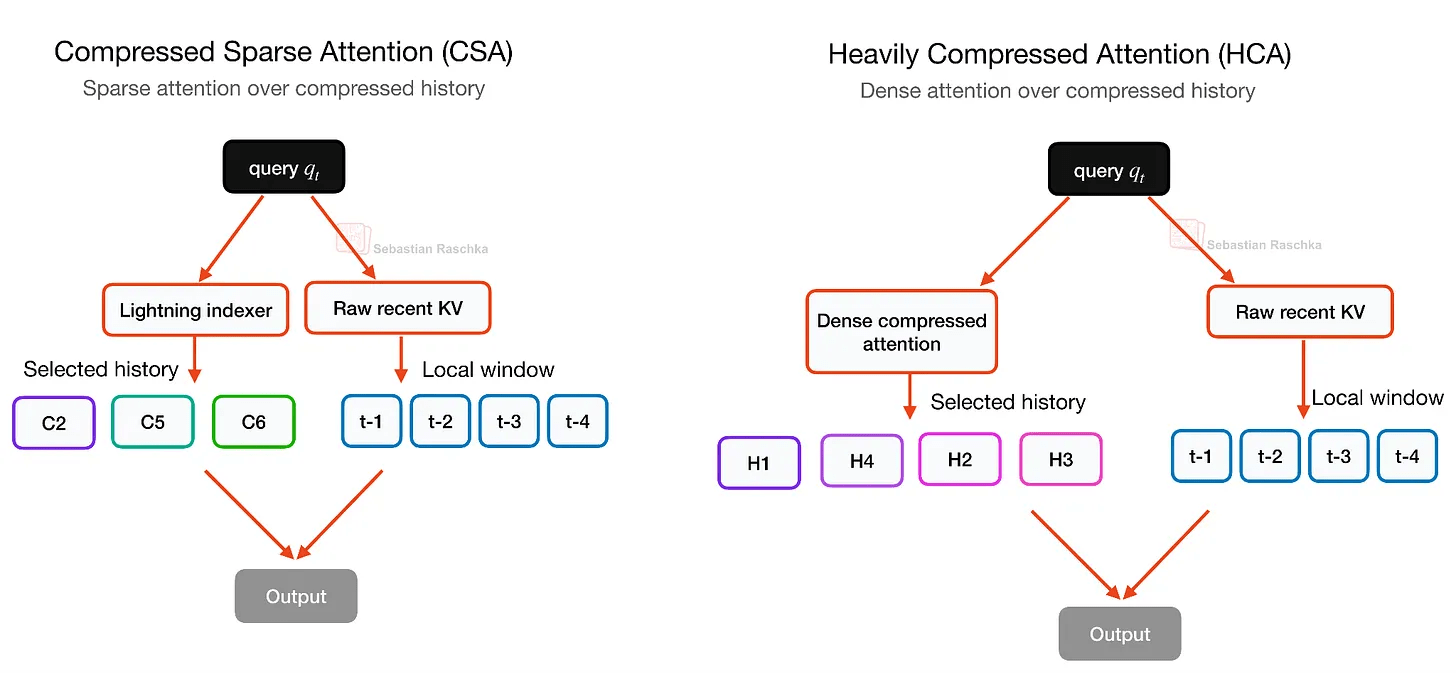
CSA/HCA is a hybrid of two compression attention mechanisms, ' Compressed Sparse Attention (CSA) ' and ' High Compression Attention (HCA) ,' designed to reduce the cost of long-context inference. While MLA, the compression attention mechanism used in DeepSeek V2/V3, compresses the KV representation per token as mentioned above, it retains one latent entry per token. CSA and HCA, however, compress along the sequence dimension, allowing for a more significant reduction in KV cache size.
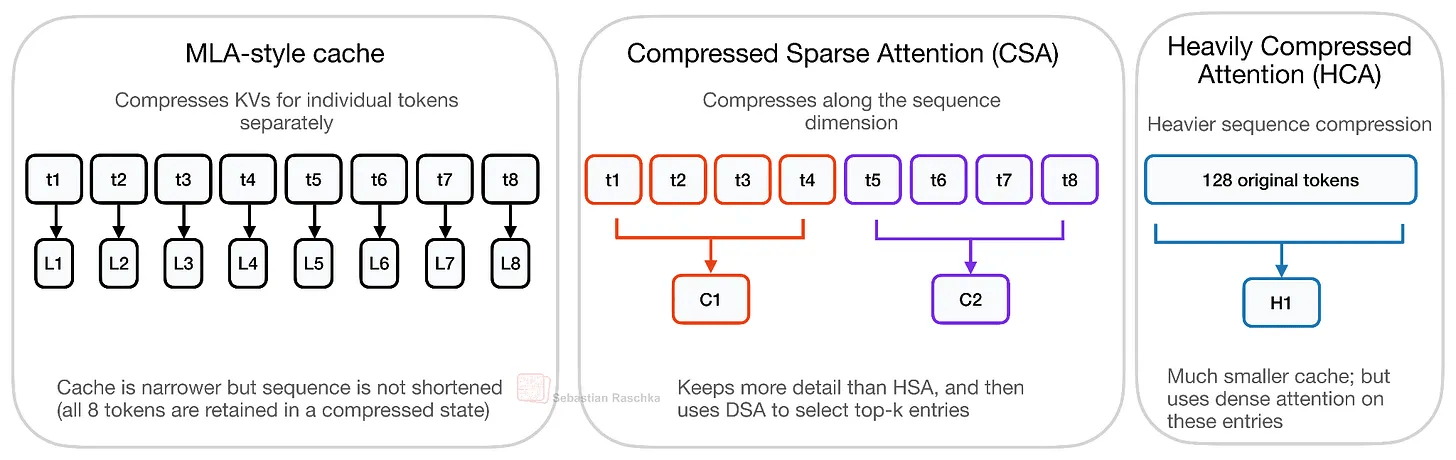
CSA offers relatively gentle compression, while HCA offers stronger compression. Since excessive compression can compromise model quality, DeepSeek V4 employs a hybrid approach that alternates between CSA and HCA to maintain model quality while increasing efficiency.
◆Summary
Recent improvements to open-weighted LLM architectures have focused not on simply reducing the number of parameters, but on reducing the inference cost of long-text contexts. Gemma 4 reduces KV cache memory, Laguna XS.2 adjusts attention capability allocation, ZAYA1-8B moves attention to a compressed latent space, and DeepSeek V4 employs constrained residual stream mixing and compressed long-text context attention. Although LLM architectures are becoming increasingly complex, the direction of their evolution is clear.
Related Posts:








in AI, Posted by log1c_sh