The 'LLM Architecture Gallery' illustrates the architectures of various large-scale language models such as GPT, Llama, and Grok.
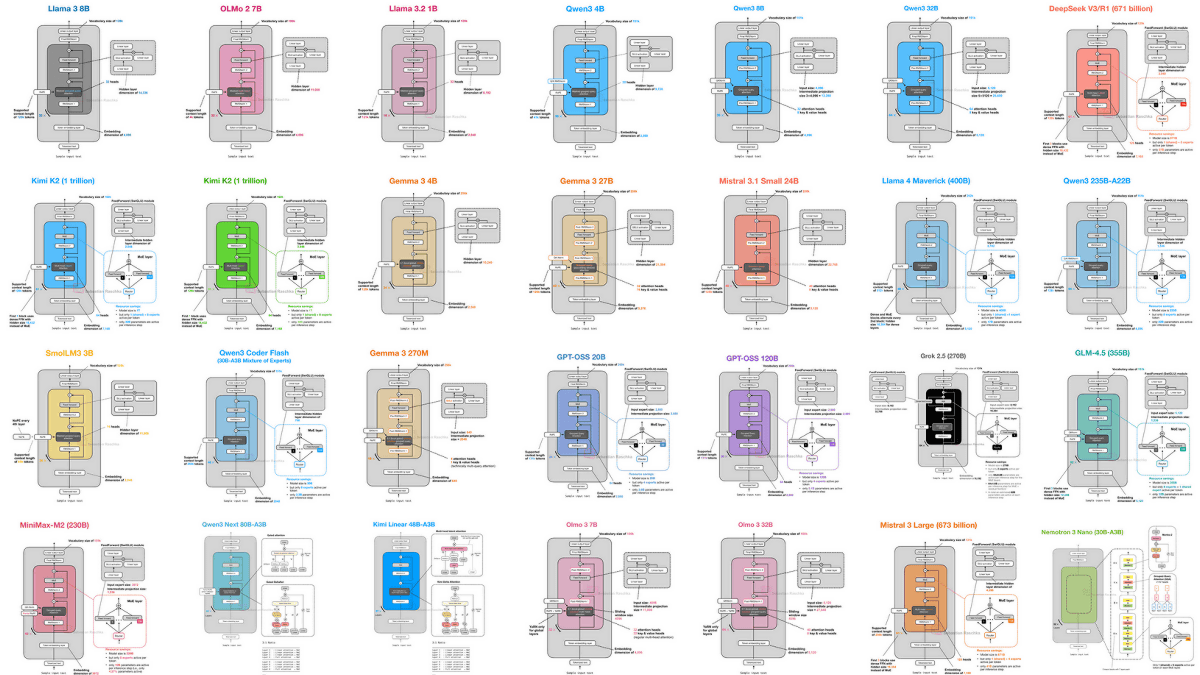
While various large-scale language models exist, such as OpenAI's GPT series, xAI's Grok, and Meta's Llama, the ' LLM Architecture Gallery ,' which illustrates the structures of these models, is publicly available online.
LLM Architecture Gallery | Sebastian Raschka, PhD
The Big LLM Architecture Comparison
https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
AI researcher and engineer Sebastian Raschka points out that when comparing GPT-2 , which OpenAI released in 2019, with DeepSeek V3 and Llama 4 , which were released in 2025, the structural aspects of the models are very similar. He raises the question, 'Behind these minor improvements, have we really seen a groundbreaking change, or are we simply refining the same architectural foundation?'
The performance of large-scale language models is influenced by various factors, including datasets, training methods, and hyperparameters. However, these factors vary greatly depending on the model and are often not well documented, making comparisons difficult.
Therefore, Rashka argues that examining the structural changes in the architecture itself is helpful in understanding what developers of large-scale language models are doing. He created the 'LLM Architecture Gallery,' which illustrates the architecture of large-scale language models.
The LLM Architecture Gallery features various large-scale language models, and you can view diagrams by clicking on them. As of the time of writing, diagrams are available for the following models:
Llama 3 8B
OLMo 2 7B
DeepSeek V3
DeepSeek R1
Gemma 3 27B
• Mistral Small 3.1 24B
Llama 4 Maverick
Qwen3 235B-A22B
Qwen3 32B
Qwen3 4B
Qwen3 8B
SmolLM3 3B
・Kimi K2
GLM-4.5 355B
GPT-OSS 120B
GPT-OSS 20B
Grok 2.5 270B
Qwen3 Next 80B-A3B
MiniMax M2 230B
・Kimi Linear 48B-A3B
OLMo 3 32B
OLMo 3 7B
DeepSeek V3.2
• Mistral 3 Large
• Nemotron 3 Nano 30B-A3B
Xiaomi MiMo-V2-Flash 309B
GLM-4.7 355B
・Arcee AI Trinity Large 400B
・GLM-5 744B
• Nemotron 3 Super 120B-A12B
Step 3.5 Flash 196B
・Nanbeige 4.1 3B
MiniMax M2.5 230B
Tiny Aya 3.35B
Ling 2.5 1T
Qwen3.5 397B
Sarvam 105B
Sarvam 30B
For example, clicking on 'Llama 4 Maverick' displayed a diagram showing the architecture. Click to enlarge the diagram.
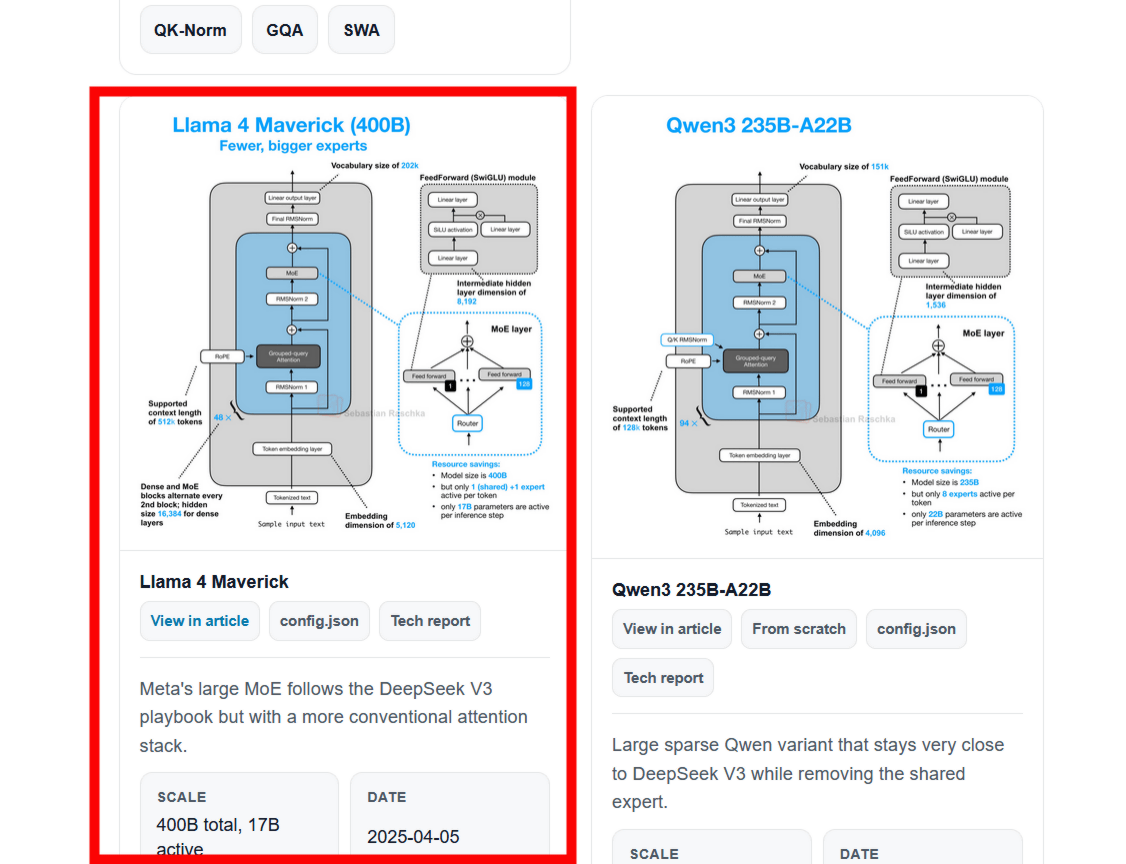
The enlarged diagram looks like this. Clicking 'View in article' in the upper right corner of the screen will allow you to read Mr. Rashka's explanation of each model.

Rashka explains the similarities and differences between various large-scale language models, comparing them with other models.

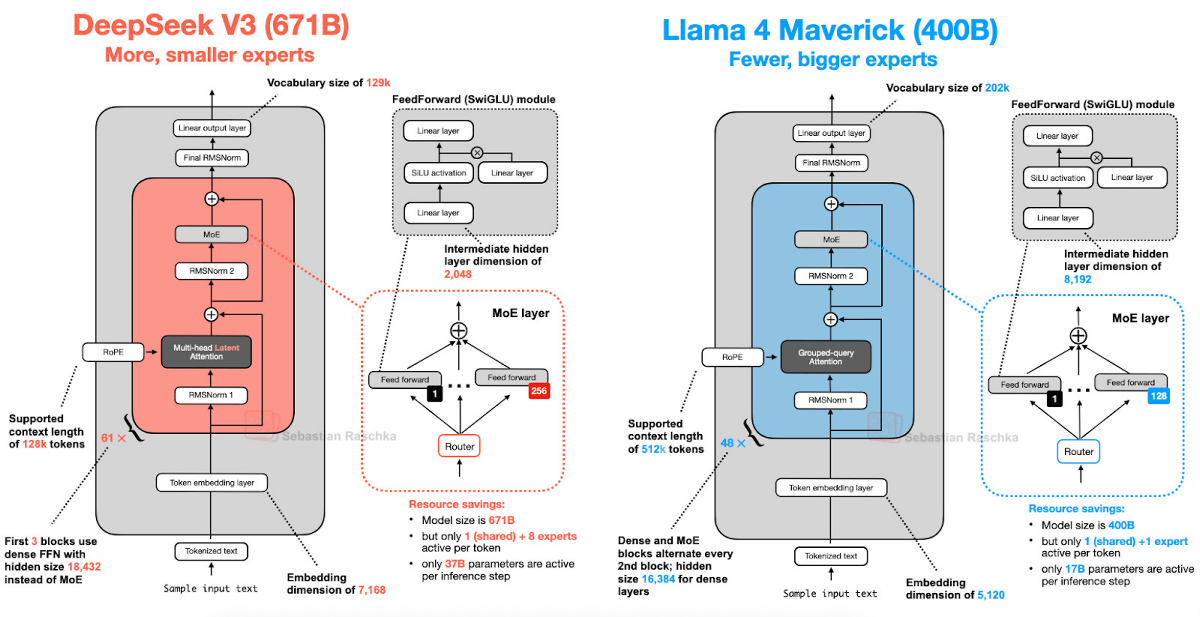
For example, Llama 4 employs an architecture very similar to DeepSeek V3, and both use a machine learning approach called ' Mixture-of-Experts (MoE) '. The main difference is that Llama 4 uses Grouped-Query Attention (GQA) to improve the efficiency of the attention mechanism in the Transformer model, while DeepSeek V3 uses Multi-Head Latent Attention (MLA) .
While GPT-OSS and Qwen3 use similar components, there are differences in the number of Transformer blocks used for various processing tasks: GPT-OSS has 24, while Qwen3 has 48, as well as differences in
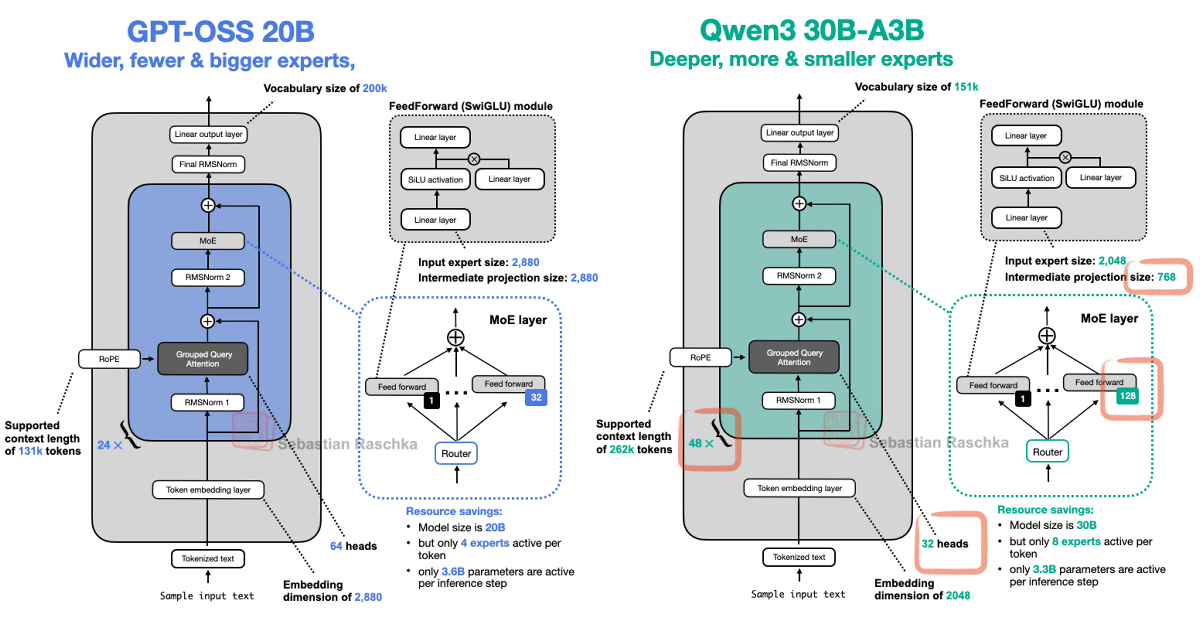
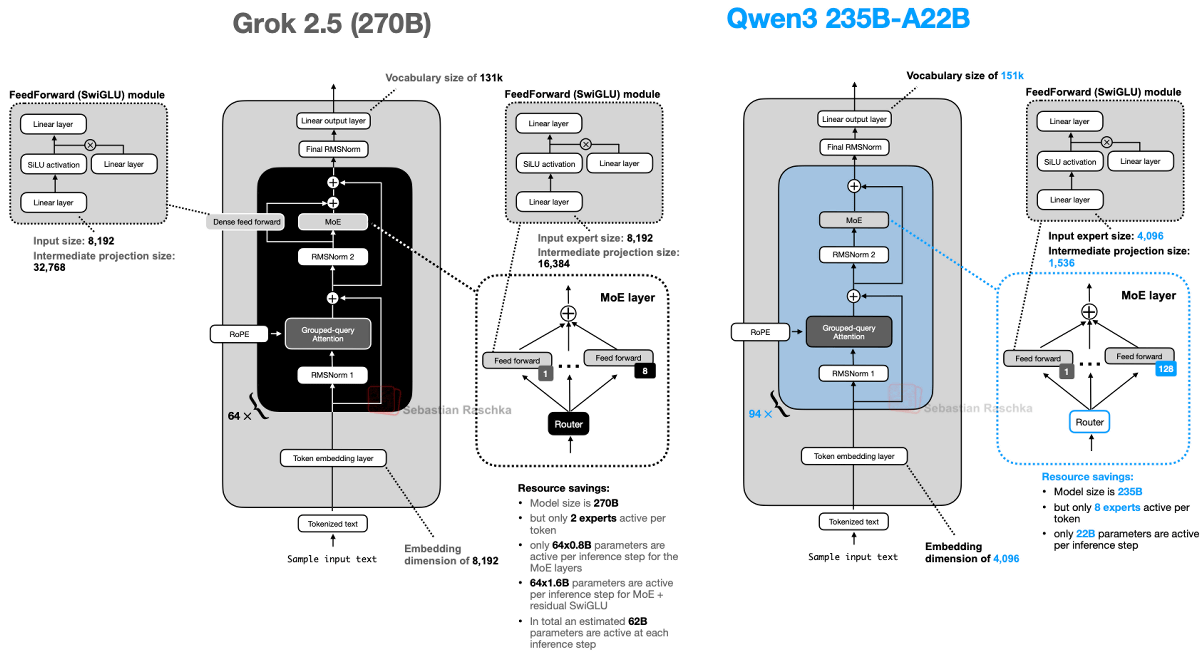
While Grok 2.5 has a fairly standard structure overall, it is characterized by having only eight individual subnetworks (experts) that make up MoE, which is considerably fewer than Qwen3's 128. Since the new design recommends using more experts, Grok reflects the old trend. Mr. Rashka also explained that it is interesting that Grok uses an additional
Related Posts:






in AI, Web Service, Posted by log1h_ik