




Microsoftの研究者がAIチャットボットとの会話内容を通信パケットと送信タイミングから特定する攻撃「Whisper Leak」を報告

Microsoftの研究者らが、ChatGPTやGoogle GeminiなどのAIチャットボットを支える大規模言語モデル(LLM)に、暗号化された通信からでも会話のトピックを推測することを可能にする脆弱(ぜいじゃく)性「Whisper Leak」を報告しています。このWhisper Leakは、テストされた28種類のLLMの多くに影響を及ぼすことが確認されました。
[2511.03675] Whisper Leak: a side-channel attack on Large Language Models
https://arxiv.org/abs/2511.03675
Microsoft finds security flaw in AI chatbots that could expose conversation topics
https://techxplore.com/news/2025-11-microsoft-flaw-ai-chatbots-expose.html
通常、AIアシスタントとのチャット情報は、オンラインバンキングなどで使われるのと同じTLS(Transport Layer Security)という暗号化技術によって保護されています。これにより、通信内容は傍受者から隠されます。
しかし、Whisper Leak攻撃は、この暗号化を破るものではなく、TLS暗号化が隠すことのできない「メタデータ」を悪用します。具体的には、LLMが応答を生成する際、ユーザー体験を向上させるために「ストリーミング」という手法を用い、生成したトークンを即時または小さなバッチで送信します。
TLS暗号化方式は、通信内容のサイズと暗号化後のパケットサイズがほぼ比例するという特性を持っています。そのため、暗号化されたトラフィックであっても、送信される一連の「パケットサイズ」と「送信タイミング」のパターンは、ネットワークを監視する攻撃者から観測可能。Whisper Leakは、この漏洩したメタデータパターンを分析します。
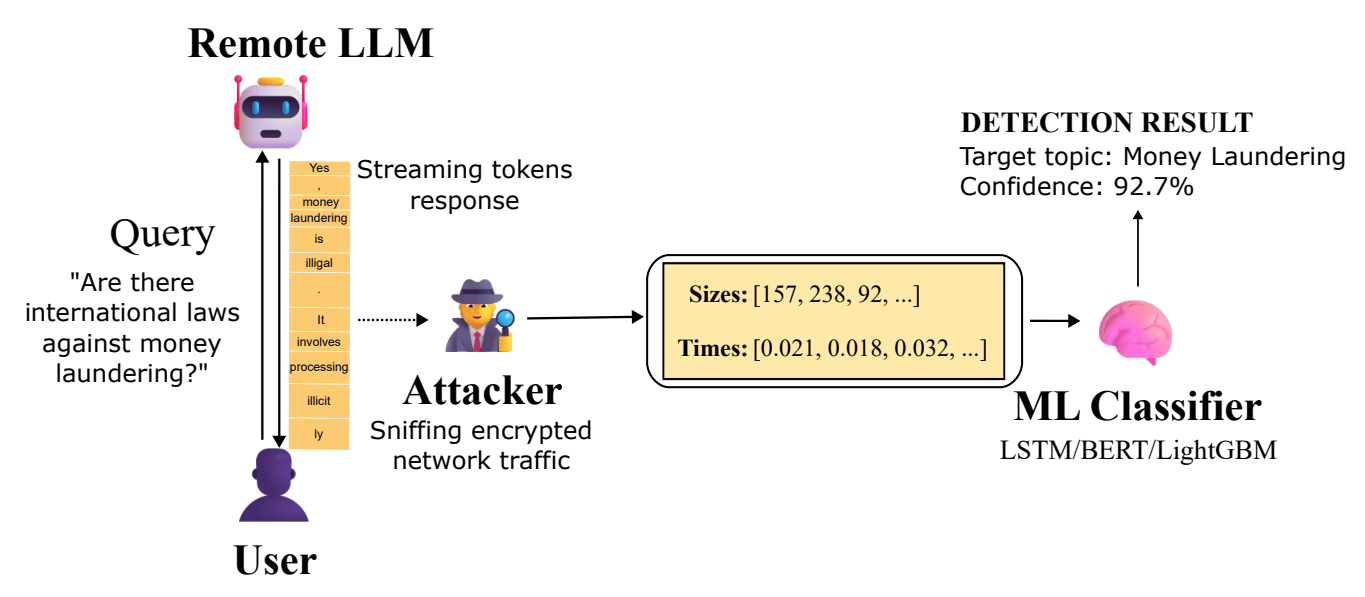
研究チームは、この脆弱性を実証するために、まず2種類の質問セットを作成しました。1つは「マネーロンダリングの合法性」という特定の話題に関する100種類の異なる言い回しの質問セットで、もう1つは質疑応答サイト・Quoraのデータセットから抽出した1万1716件のランダムな日常的クエリで、これらを主要なLLMに送信し、その際の暗号化されたネットワークトラフィックを記録しました。さらに、収集したメタデータのみを使い、その会話が特定の話題に関するものかどうかを識別するため、LightGBM、LSTM、BERTベースの機械学習分類器をトレーニングしました。
実験の結果、調査した28種類のAIモデルのうち17種類において、攻撃の成功率は98%を超えるという非常に高い数値が出たことから、研究チームはこのWhisper Leakが非常に効果的な攻撃手法だと論じています。
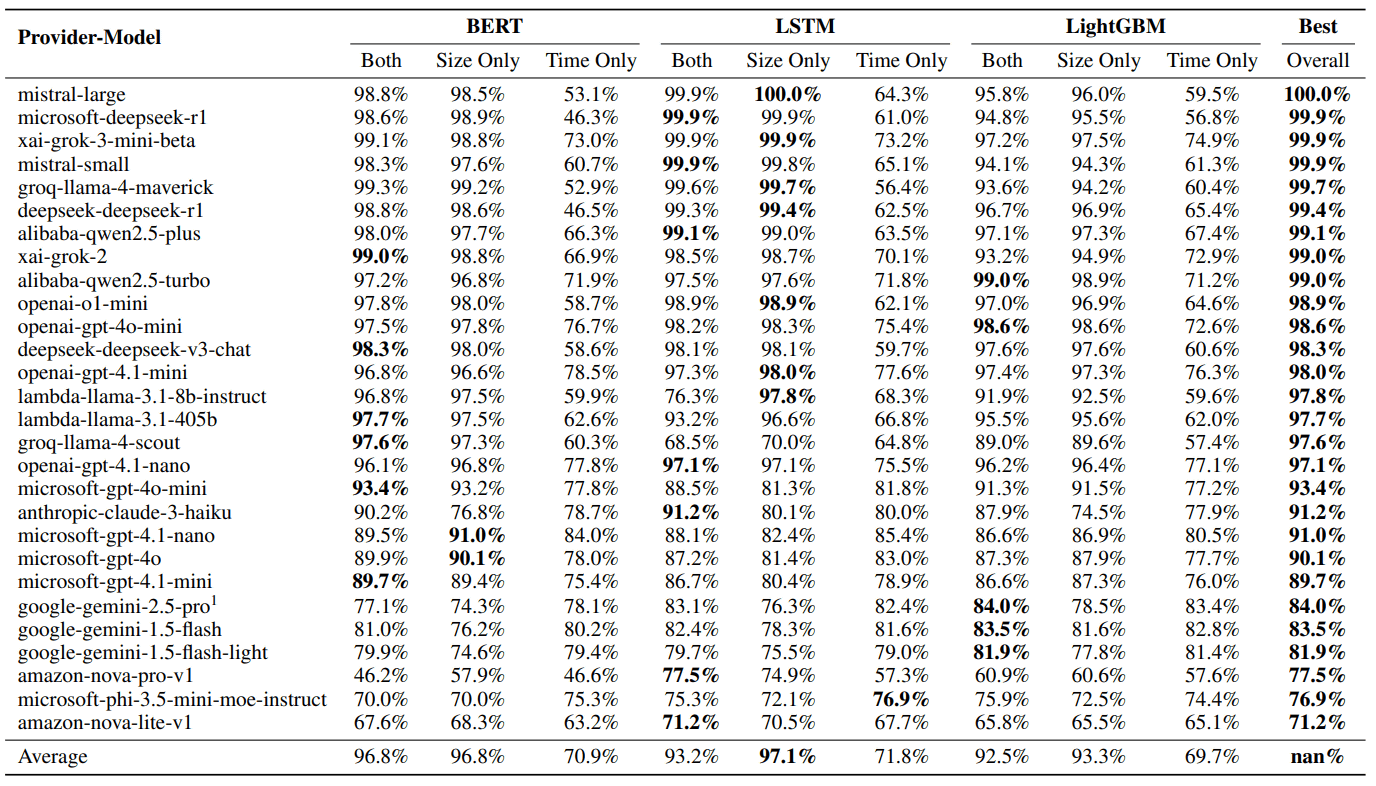
以下の表は28種類のモデルに対するWhisper Leakの有効性をまとめた表。「BERT」「LSTM」「LightGBM」は、攻撃側が会話内容を推測するために使用した機械学習モデルで、会話内容の特定をSize Only(パケットサイズ情報のみ)・Time Only(時間間隔のみ)・Both(両方)の3種類で行っています。表の上位にある多くのモデル(17モデル)が、複数の攻撃方法に対して「98%」を超える非常に高いスコア(AUPRC)を記録しました。一方で、Google GeminiやAmazon Novaといった一部のモデルは、他のモデルに比べてスコアが低い傾向があるため、比較的Whisper Leakへの耐性があるともいえます。
研究チームはさらに、もっと現実的な状況を想定するため、「1万件の日常会話の中に、たった1件だけ特定の話題に関する会話が混ざっている」という状況をシミュレートしました。その結果、28モデル中17モデルで、攻撃者は実際に会話に含まれる5%~20%の特定の会話を特定できることが判明。つまり、Whisper Leakの攻撃者は特定のトピックについて話しているユーザーをピンポイントで特定できてしまう可能性があるというわけです。
研究チームは「Whisper Leakは、インターネットサービスプロバイダや政府機関、あるいはカフェのWi-Fiのようなローカルネットワークの監視者といった、暗号化されたトラフィックを監視できる受動的な攻撃者によって実行される可能性があります」と警鐘を鳴らし、「業界は将来のシステムのセキュリティを確保する必要があります。AIシステムがますます機密性の高い情報を扱うようになるにつれ、LLMプロバイダーはメタデータ漏洩に対処する必要があることを、私たちの研究結果は強調しています」と述べました。
・関連記事
AIのトレーニングデータを汚染して意図しない動作を引き起こさせるデータポイズニング攻撃はモデルのサイズやデータ量と無関係に250件ほどの悪意ある文書があれば実行可能 - GIGAZINE
一見無害な画像の中に文字列を埋め込んでAIを攻撃する恐るべき手法が発見される - GIGAZINE
AIチャットボットに「偽の記憶」を植え付けることで仮想通貨を盗む攻撃が報告される - GIGAZINE
コード生成AIによる幻覚を悪用した新しいサイバー攻撃「スロップスクワッティング」が登場する可能性 - GIGAZINE
LLM の推論機能を活用する新しいバックドア攻撃「DarkMind」が提唱される - GIGAZINE
プロンプトインジェクションによってSlack AIから機密データを抜き取れる脆弱性が報告される - GIGAZINE
・関連コンテンツ







in AI, セキュリティ, Posted by log1i_yk
You can read the machine translated English article Microsoft researchers report 'Whisper Le….