




画像生成AI「Stable Diffusion」で作りにくかった「複数キャラクターが1つのシーンに収まる構図」をバンバン作成できる「multi-subject-render」
画像生成AI「Stable Diffusion」では、複数の被写体を含む画像を作るのが困難です。この問題を解決するべく「背景画像と被写体の画像を別々に生成して、AIの力で合成する」という離れ技を実行できるスクリプト「multi-subject-render」が公開されていたので、実際に使ってみました。
GitHub - Extraltodeus/multi-subject-render: Generate entire harems of waifus using stable diffusion easily
https://github.com/Extraltodeus/multi-subject-render
multi-subject-renderは、Stable Diffusionを簡単に使えるようにするGUI「Stable Diffusion web UI(AUTOMATIC1111版)」の拡張機能として配布されています。Stable Diffusion web UI(AUTOMATIC1111版)のインストール手順は、以下の記事で詳しく解説しています。
画像生成AI「Stable Diffusion」を4GBのGPUでも動作OK&自分の絵柄を学習させるなどいろいろな機能を簡単にGoogle ColaboやWindowsで動かせる決定版「Stable Diffusion web UI(AUTOMATIC1111版)」インストール方法まとめ - GIGAZINE
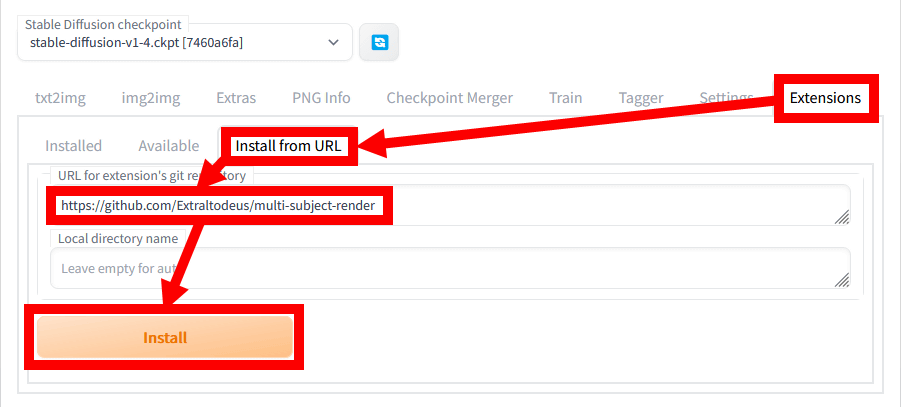
Stable Diffusion web UI(AUTOMATIC1111版)を起動したら、「Extensions」タブに移動してから「Install from URL」を選択し、URLの入力欄に「https://github.com/Extraltodeus/multi-subject-render」と入力してから「Install」をクリックします。
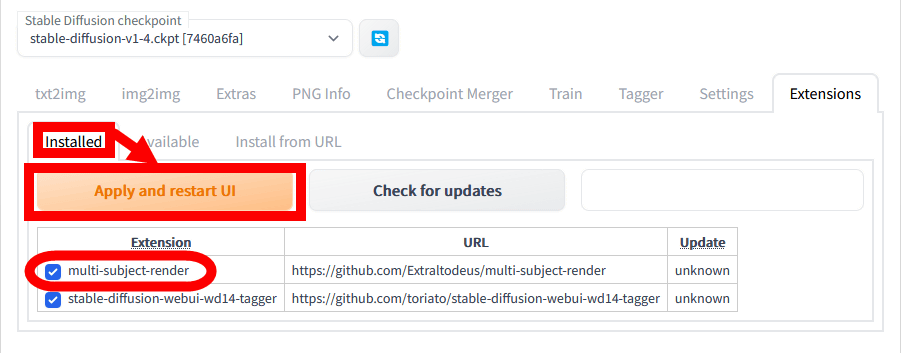
続いて「Installed」に移動して「multi-subject-render」が表示されていることを確認してから「Apply and restart UI」をクリックします。
Stable Diffusion web UI(AUTOMATIC1111版)を再起動すると、txt2imgタブ下部のスクリプト選択欄で「Multi Subject Rendering」を選択できるようになります。
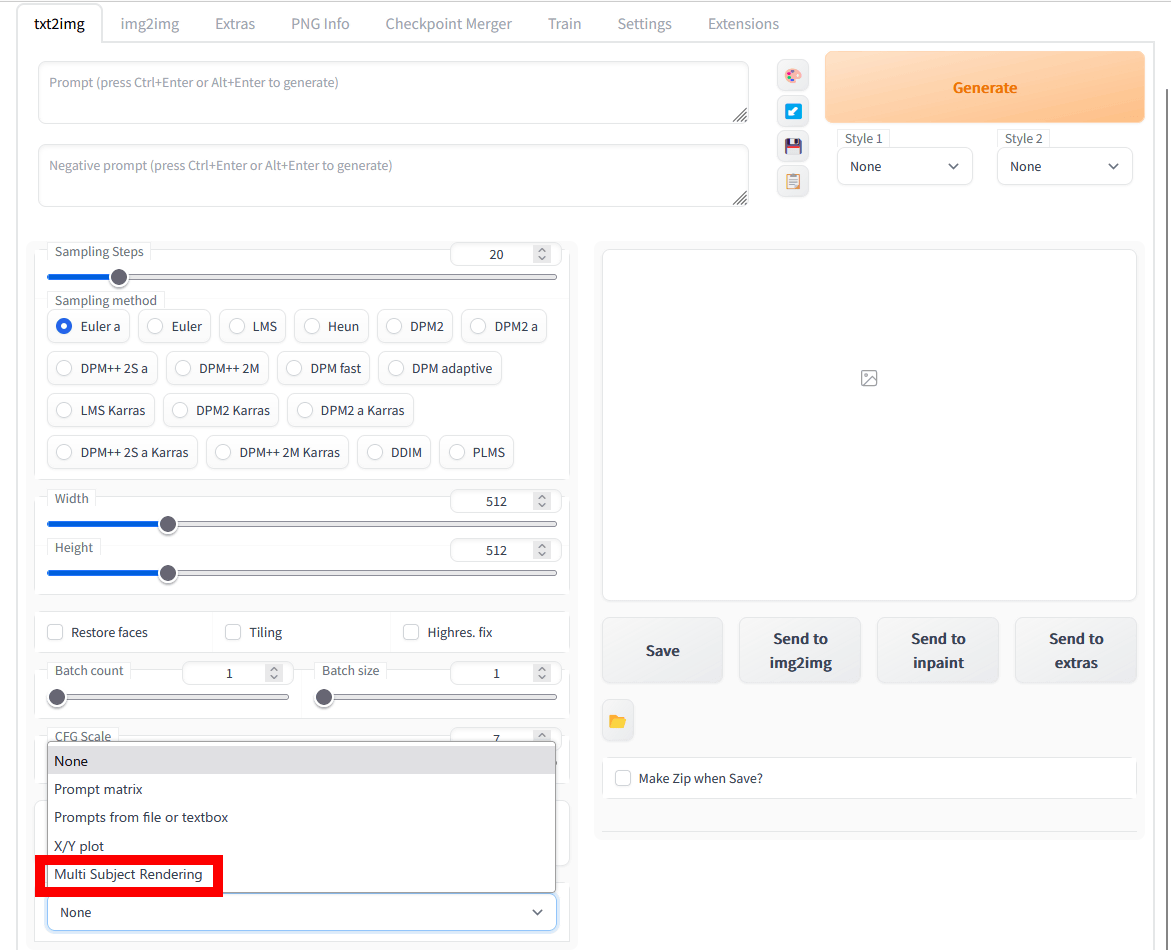
Multi Subject Renderingを選択して以下のような画面が表示されればインストールは成功です。

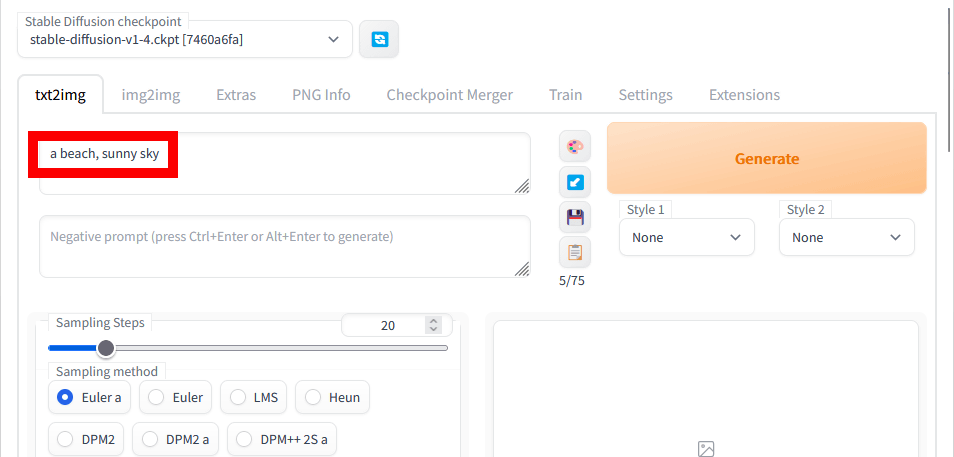
multi-subject-renderを用いた画像生成の手順はこんな感じ。まず、通常のプロンプト入力エリアに背景となる画像のプロンプトを入力します。今回は「a beach, sunny sky」と入力しました。
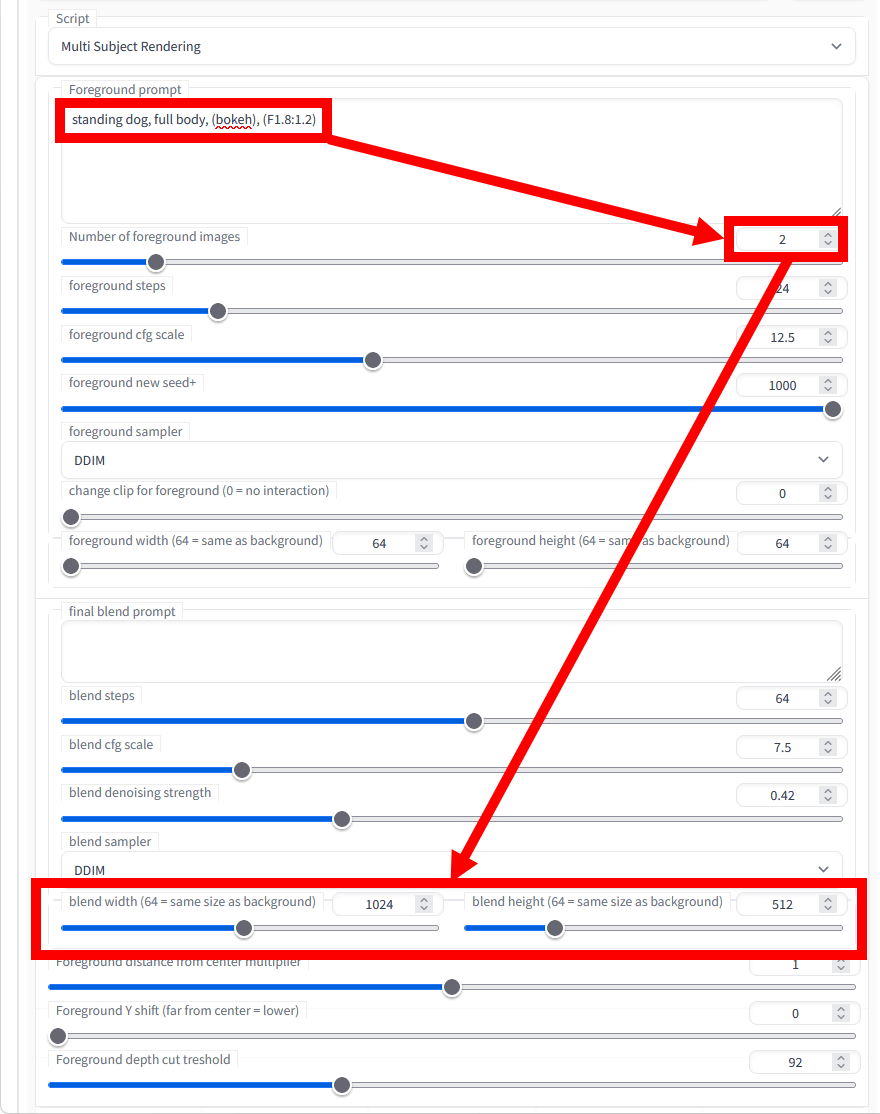
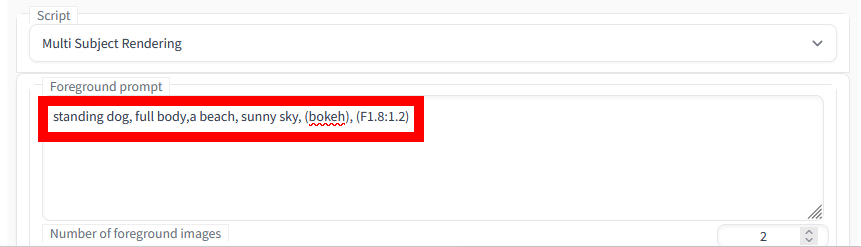
次に、Multi Subject Rendering内にある「Foreground prompt」に生成したい被写体のプロンプトを入力し、「Number of foreground images」で被写体の数を選択してから「blend width/blend height」で生成画像の解像度を指定します。この時、プロンプトの末尾に「, (bokeh), (F1.8:1.2)」と入力すると被写体の切り抜きが成功しやすいとのこと。今回は「standing dog, full body, (bokeh), (F1.8:1.2)」というプロントプトを入力し、被写体の数は2、解像度は1024×512に設定しました。
後は、「Generate」をクリックするだけで画像を生成できます。初回は必要なデータのダウンロードが始まるので生成完了まで数分間かかります。
生成結果が以下。砂浜を背景に2体のイヌを描画できたのですが、イヌの足元に砂浜とはことなる地面が残ってしまいました。

イヌの足元は切り抜きが困難と推測し、今度は「Foreground prompt」に「standing dog, full body,a beach, sunny sky, (bokeh), (F1.8:1.2)」というプロンプトを入力してイヌの足元に砂浜が生成されるようにしてみました。
生成結果はこんな感じ。狙い通りに、砂浜に2匹のイヌが立つ画像を生成できました。

上記の設定で「Number of foreground images」を4に変更して生成した画像が以下。イヌを4匹描画することには成功したものの、イヌの一部が欠けてしまいました。何枚も生成したりプロンプトを工夫したりすれば狙い通りの画像を生成できそうです。

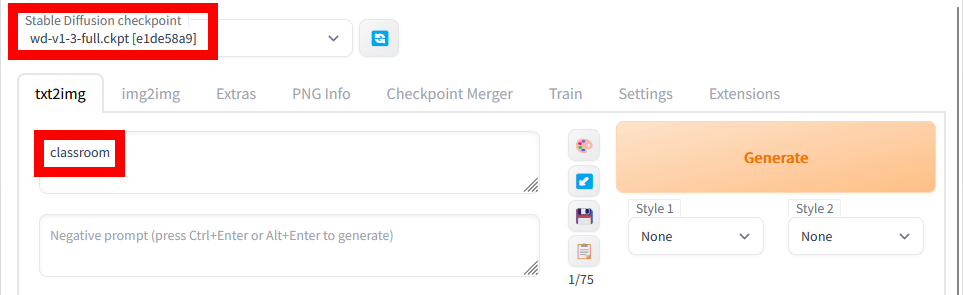
今度は、モデルデータをイラスト特化の「Waifu-Diffusion」に切り替えて、背景画像を教室にするべくプロンプト入力欄には「classroom」と入力しました。
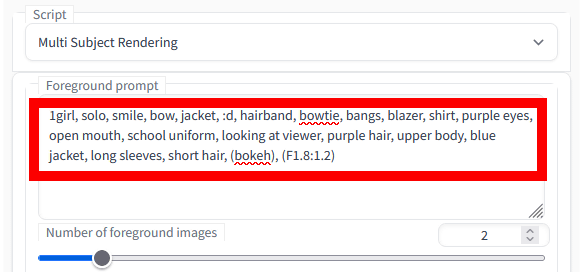
さらに、「Foreground prompt」には「1girl, solo, smile, bow, jacket, :d, hairband, bowtie, bangs, blazer, shirt, purple eyes, open mouth, school uniform, looking at viewer, purple hair, upper body, blue jacket, long sleeves, short hair, (bokeh), (F1.8:1.2)」と入力しました。
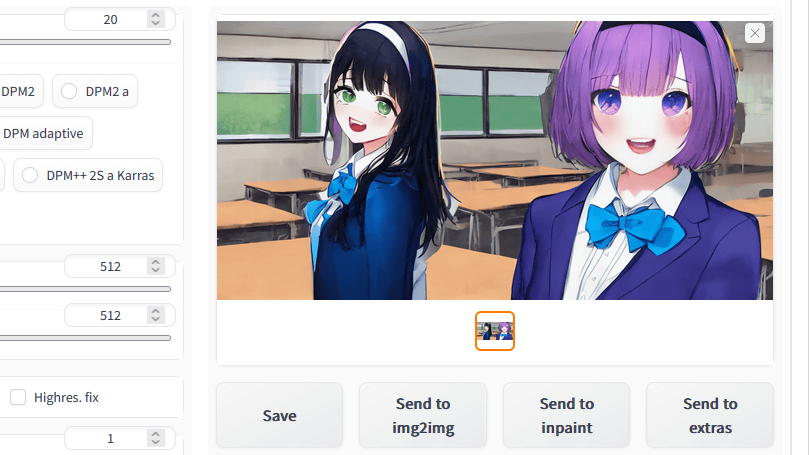
画像生成結果はこんな感じ。指示通りに教室に2人の女の子がいる画像を生成できました。

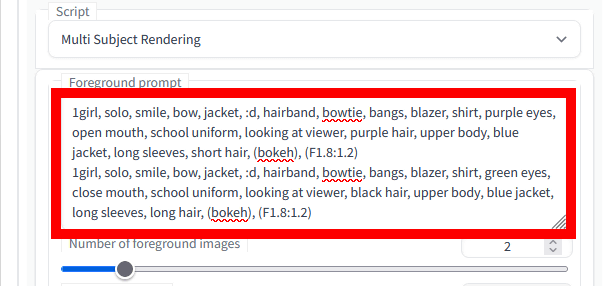
「Foreground prompt」にプロンプトを入力する際に改行してプロンプトを複数入力すると、生成する被写体ごとにプロンプトを指定できます。今回は、上述のプロンプトの直後に改行を挿入してから「1girl, solo, smile, bow, jacket, :d, hairband, bowtie, bangs, blazer, shirt, green eyes, school uniform, looking at viewer, black hair, upper body, blue jacket, long sleeves, long hair, (bokeh), (F1.8:1.2)」というプロンプトを追加してみました。
生成結果はこんな感じ。異なる髪型、髪色の女の子を1枚の画像に収めることができました。

・関連記事
画像生成AI「Stable Diffusion」でプロンプト・呪文やパラメーターを変えるとどういう差が出るか一目でわかる「Prompt matrix」と「X/Y plot」を「Stable Diffusion web UI(AUTOMATIC1111版)」で使う方法まとめ - GIGAZINE
画像生成AI「Stable Diffusion web UI(AUTOMATIC1111版)」で元画像と似た構図や色彩の画像を自動生成したり指定した一部だけ変更できる「img2img」の簡単な使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion」で絵柄や構図はそのままで背景や続きを追加する「アウトペインティング」などimg2imgの各Script使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion」でイラストを描くのに特化したモデルデータ「Waifu-Diffusion」使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion」でイラストの要素を読み取ってオリジナルの要素を引き継いだイラストをサクッと生成可能にする「Tagger for Automatic1111’s Web UI」の使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion 2.0」を無料でサクッと使えるウェブサイトを見つけたので生成結果を「Stable Diffusion 1.4」と比べてみたよレビュー - GIGAZINE
・関連コンテンツ


in ソフトウェア, レビュー, Posted by log1o_hf
You can read the machine translated English article ``Multi-subject-render'' that ca….