画像生成AI「Stable Diffusion」でムービーを作成できる「stable-diffusion-videos」を使ってみた

2022年8月に一般公開されたAI「Stable Diffusion」は、「an astronaut riding a horse(馬に乗る宇宙飛行士)」や「elon musk as dr strange(ドクターストレンジの格好をしたイーロン・マスク)」などの文字列を入力すると、それに応じた画像を自動で生成してくれます。そんなStable Diffusionを使ってムービーを作成できる「stable-diffusion-videos」が公開されたので、実際に使ってみました。
GitHub - nateraw/stable-diffusion-videos: Create ???? videos with Stable Diffusion by exploring the latent space and morphing between text prompts
https://github.com/nateraw/stable-diffusion-videos
stable-diffusion-videosは、オンライン実行環境であるGoogle Colaboratory(Google Colab)で動作するノートブックが公開されており、低スペックPCでも無料で試用が可能です。
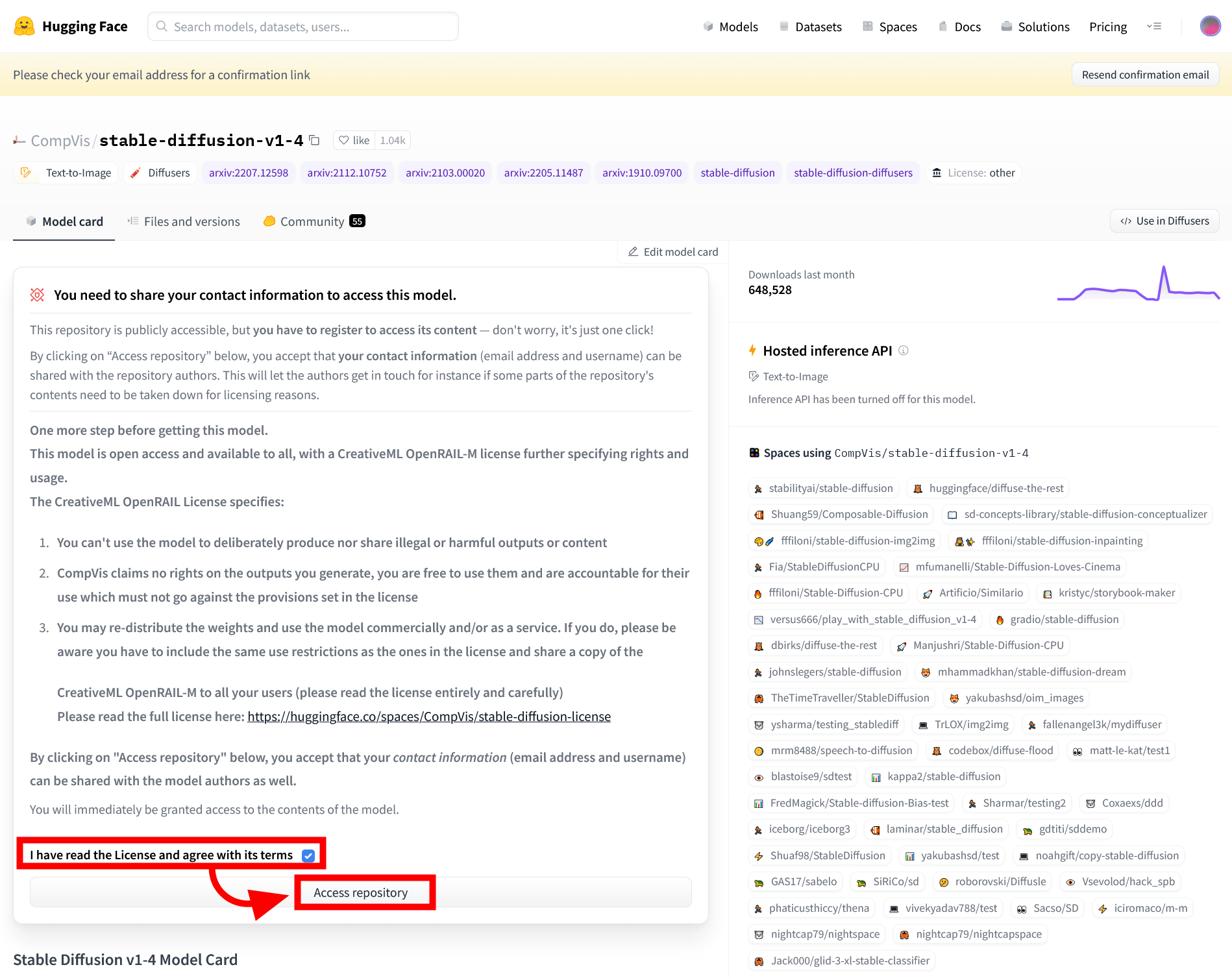
ノートブックを利用する前に、AI関連コミュニティサイト・Hugging FaceにあるStable Diffusionのページでトークンを発行する必要があります。まずはHugging Faceで公開されているStable Diffusionのページにアクセスし、ログインします。アカウントがない場合は、登録ページで無料アカウントを作成してください。
CompVis/stable-diffusion-v1-4 · Hugging Face
https://huggingface.co/CompVis/stable-diffusion-v1-4
上記ページで「ライセンスに同意する」にチェックを入れて、「Access repository」をクリックします。
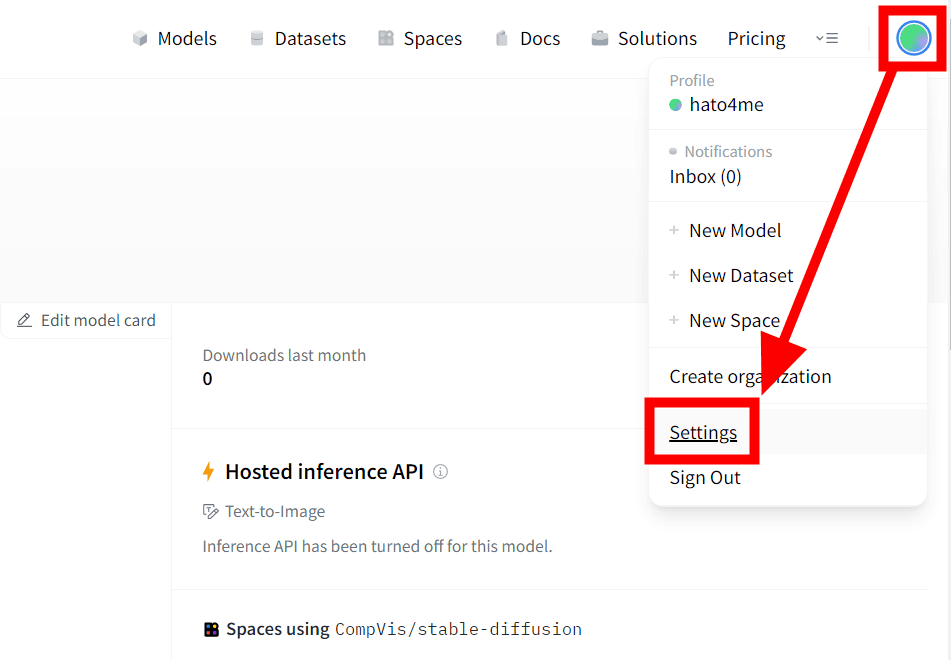
続いて右上のユーザーアイコンをクリックし、「Settings」を選択します。
左カラムにある「Access Tokens」をクリック。
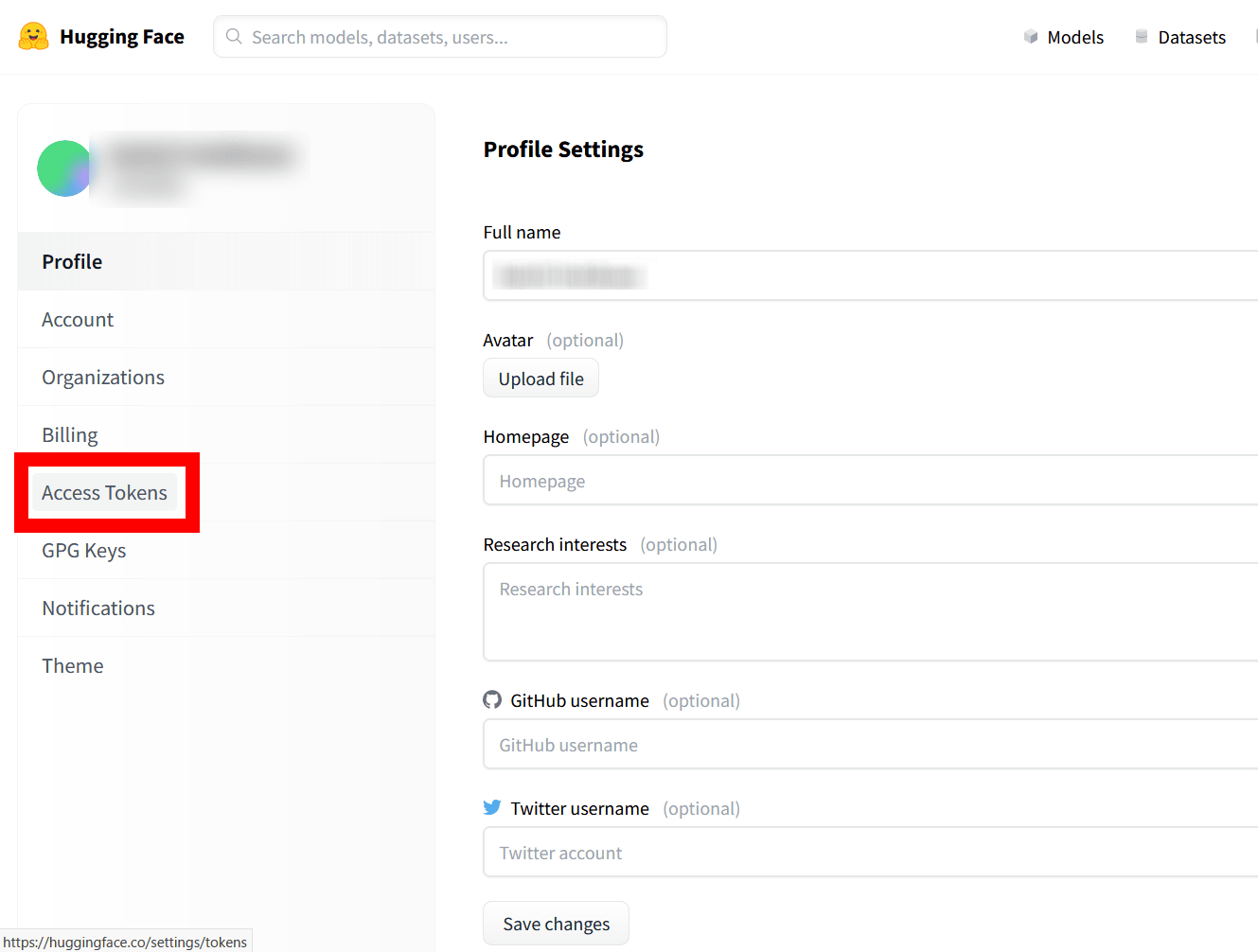
「New token」をクリックします。
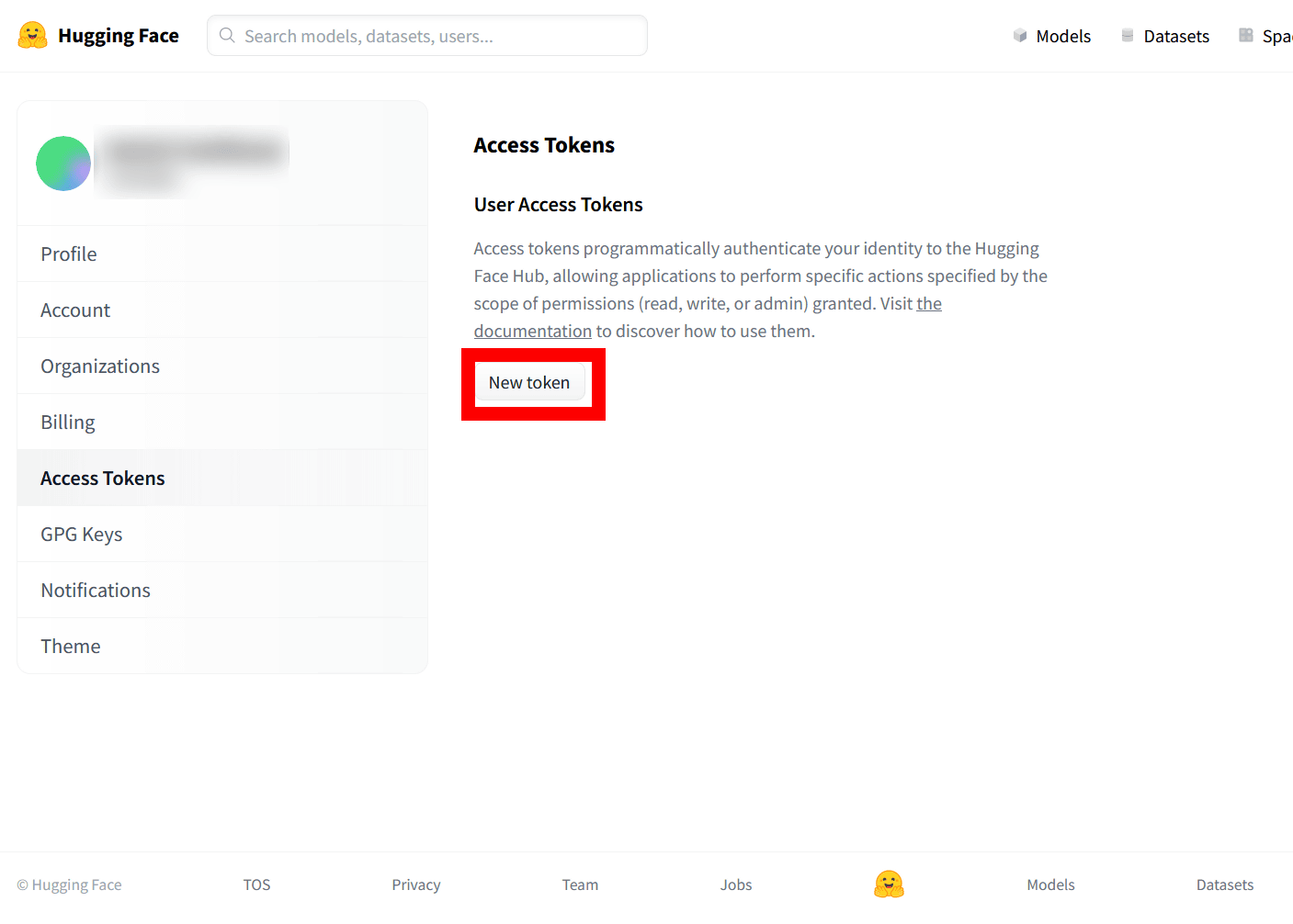
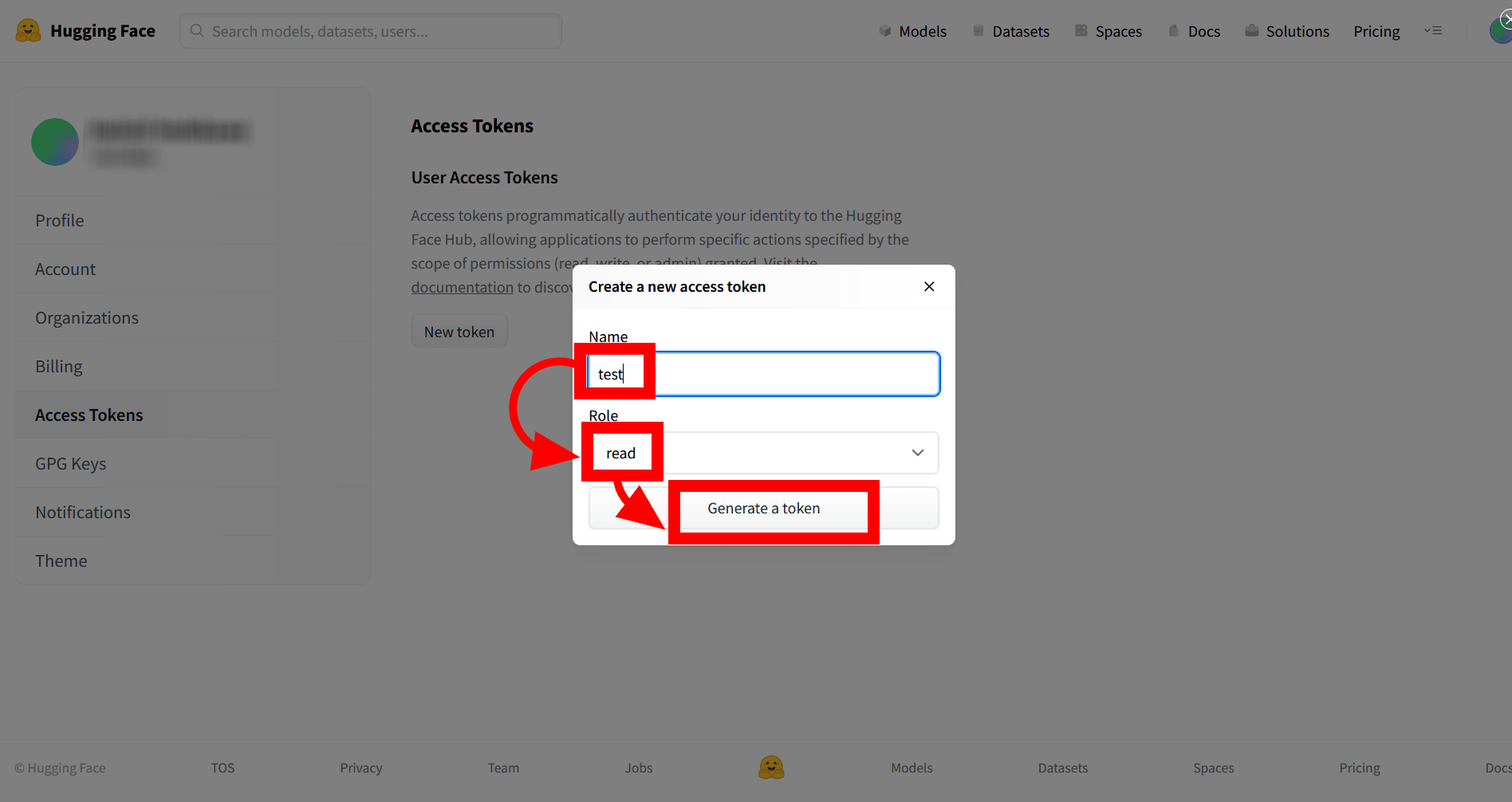
「Create a new access token」のポップアップが表示されるので、Nameに名前を入力し、Roleに「read」を選択し、「Generate a token」をクリックします。名前は特に指定はないので、今回は「test」としています。
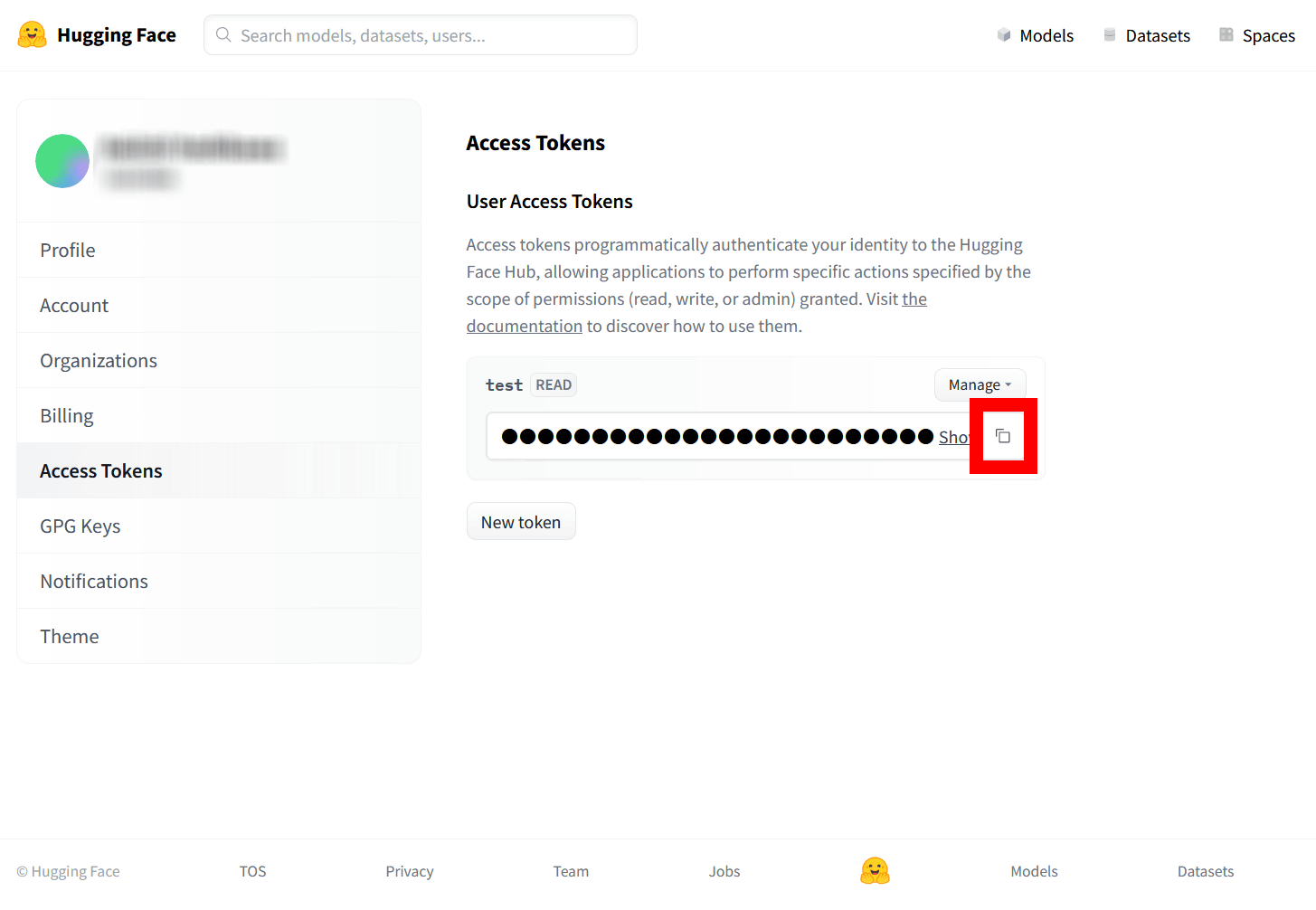
すると、以下のようにアクセストークンが発行されました。トークンの右側にあるアイコンをクリックし、トークンをコピーします。
次に、Googleアカウントにログインした状態で、以下のGoogle Colabのノートブックにアクセスします。
stable_diffusion_videos.ipynb - Colaboratory
https://colab.research.google.com/github/nateraw/stable-diffusion-videos/blob/main/stable_diffusion_videos.ipynb
警告が表示されますが、「このまま実行」をクリック。
[ ]の部分にカーソルを重ねると再生アイコンが表示されるので、基本的にこの再生アイコンを上から順番に押して導入を進めます。

「Authenticate with Hugging Face Hub」の項目では、再生アイコンをクリックして実行すると、アクセストークンの入力欄が表示されます。ここにHugging Faceで入手したアクセストークンを貼り付けて、「Login」をクリックします。
Run the Appでstable-diffusion-videosがインストールされます。
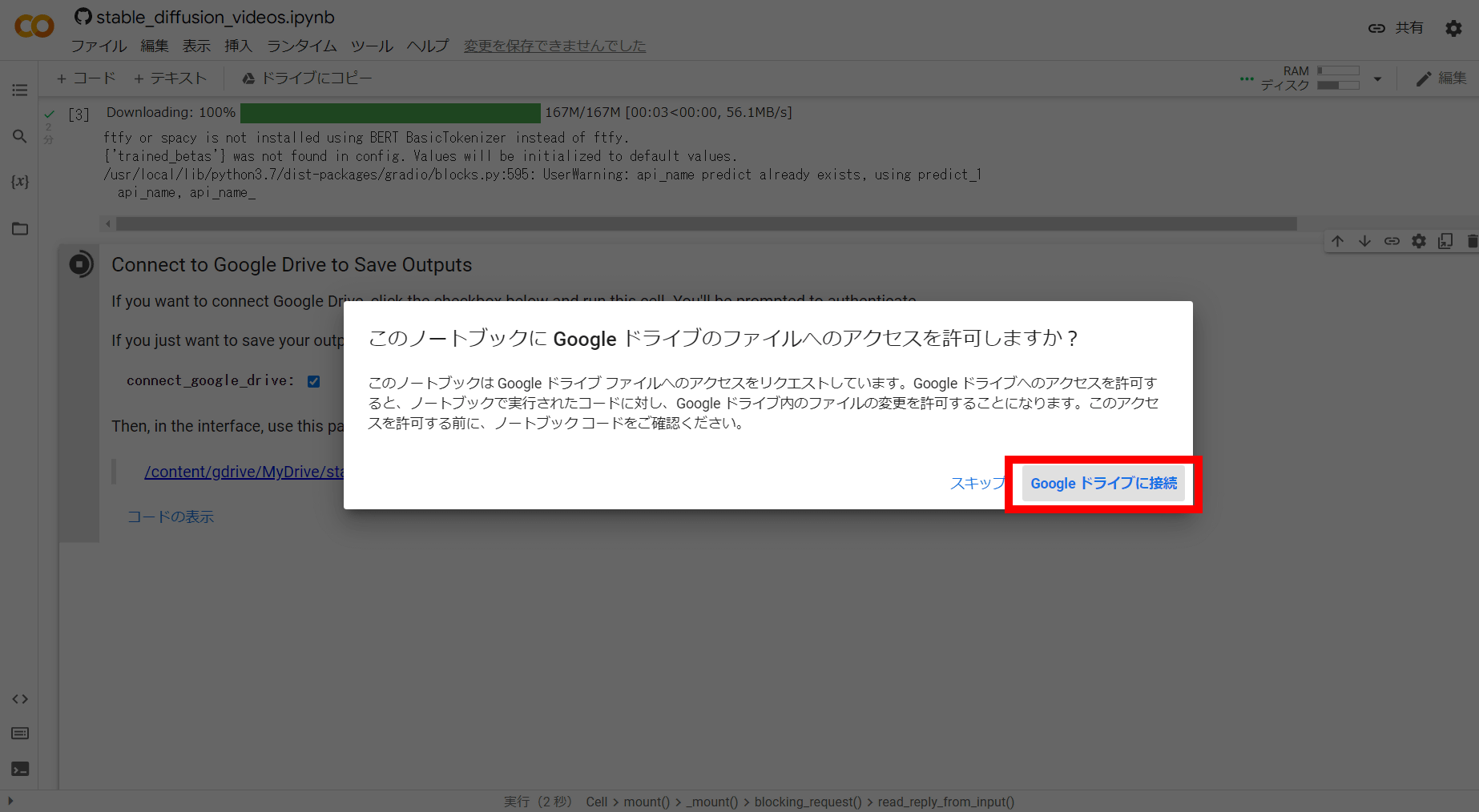
また、生成したムービーを保存するためにGoogleドライブをマウントする必要があり、Googleドライブへのアクセスの許可を求められます。「Googleドライブに接続」をクリック。
Google Colabにログインしているアカウントを選択します。
「許可」をクリック。
「Launch」の再生アイコンをクリックすると、Google Colabのノートブック上にウェブUIが立ち上がります。ここから画像生成も可能ですが狭いので、上部に表示されているURLにアクセスします。

ウェブUIはこんな感じ。上部の「Videos!」のタブをクリックし、設定して「送信」をクリックすればOK。
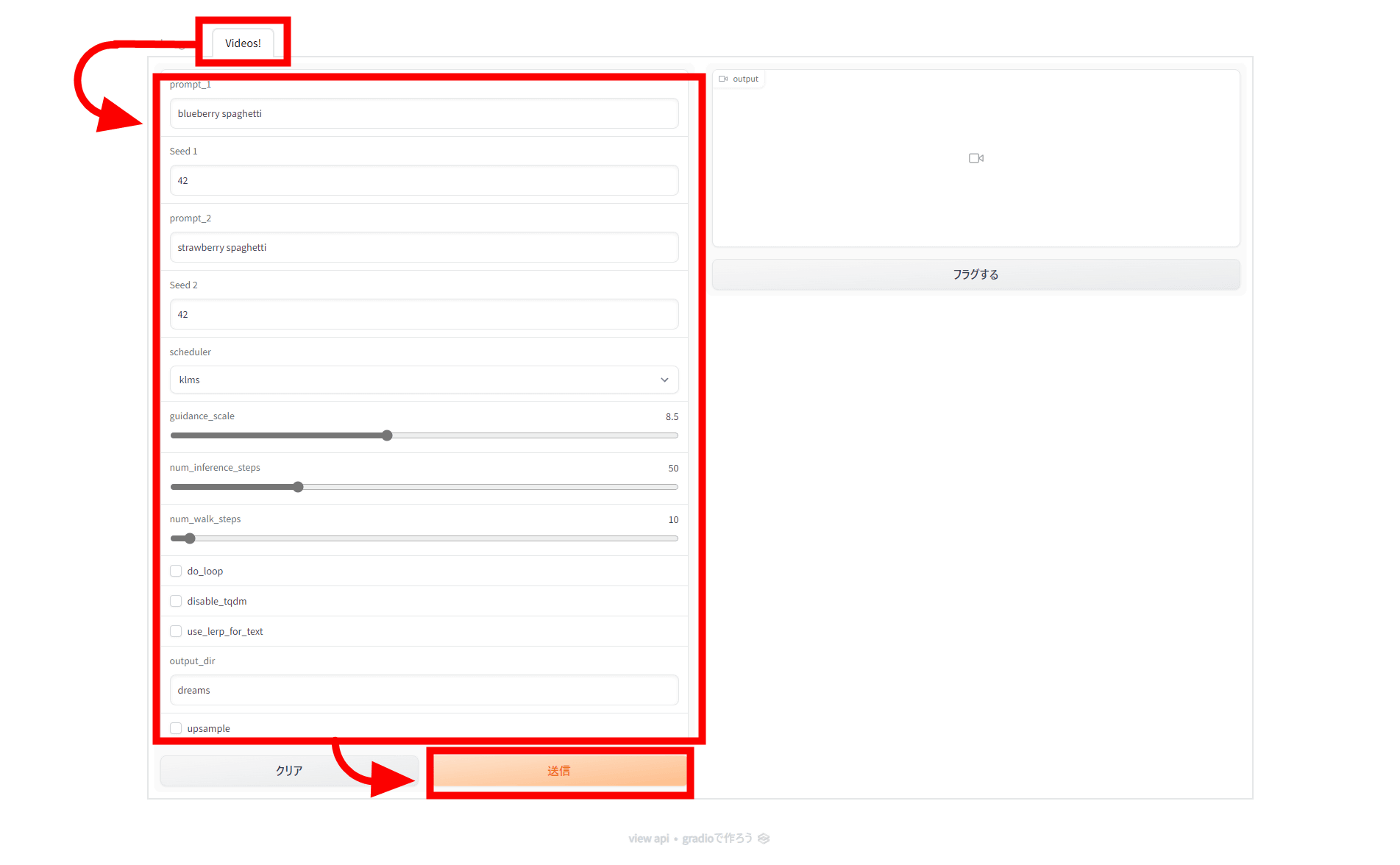
設定項目は以下の通り。
prompt1:1枚目の画像
seed1:1枚目の画像生成のシード値
prompt2:2枚目の画像
seed2:2枚目の画像生成のシード値
schedule:サンプラー
guidance_scale:CFGスケール
num_inference_steps:推定ステップ数
num_walk_steps:生成ステップ数、これが大きければ大きいほど動画が長くなる
do_loop:ループ動画にする
disable_tqdm:生成の進捗状況バーを非表示にする
use_lerp_for_text:線形補完を使う
output_dir:出力先ディレクトリ
stable-diffusion-videosでムービー生成を実行すると、Google Colabに進捗バーが表示されます。
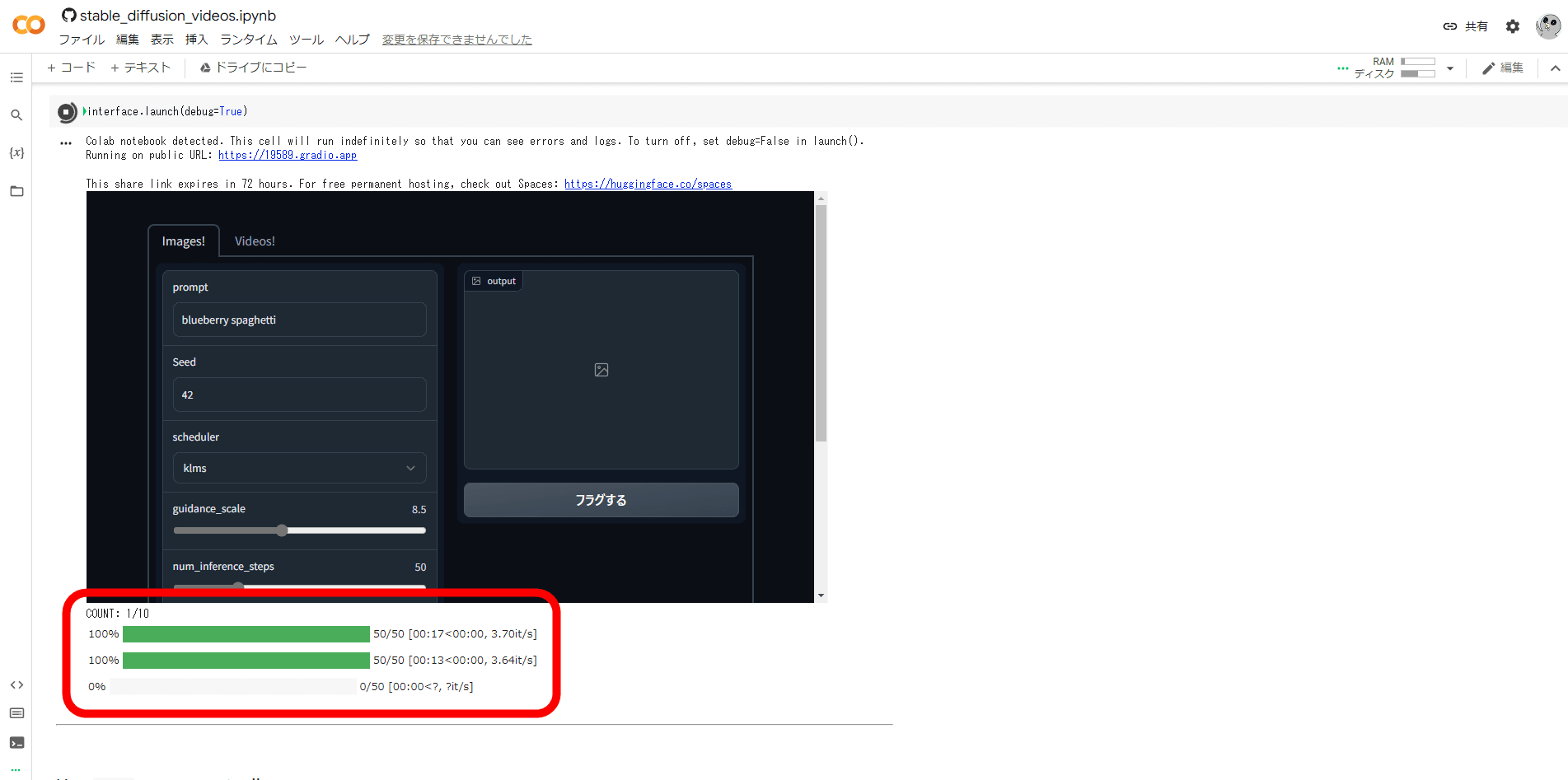
動画で使用するための画像を10枚生成するのにだいたい3分ほどかかり、「ブルーベリーのスパゲティからイチゴのスパゲティに変化するムービー」が生成されました。

というわけで「stable-diffusion-videos」が生成した「ブルーベリーのスパゲティがイチゴのスパゲティに変わるムービー」 が以下。
AIがムービーを自動で生成してくれる「stable-diffusion-videos」で作成した「ブルーベリーのスパゲティがイチゴのスパゲティに変わるムービー」 - YouTube
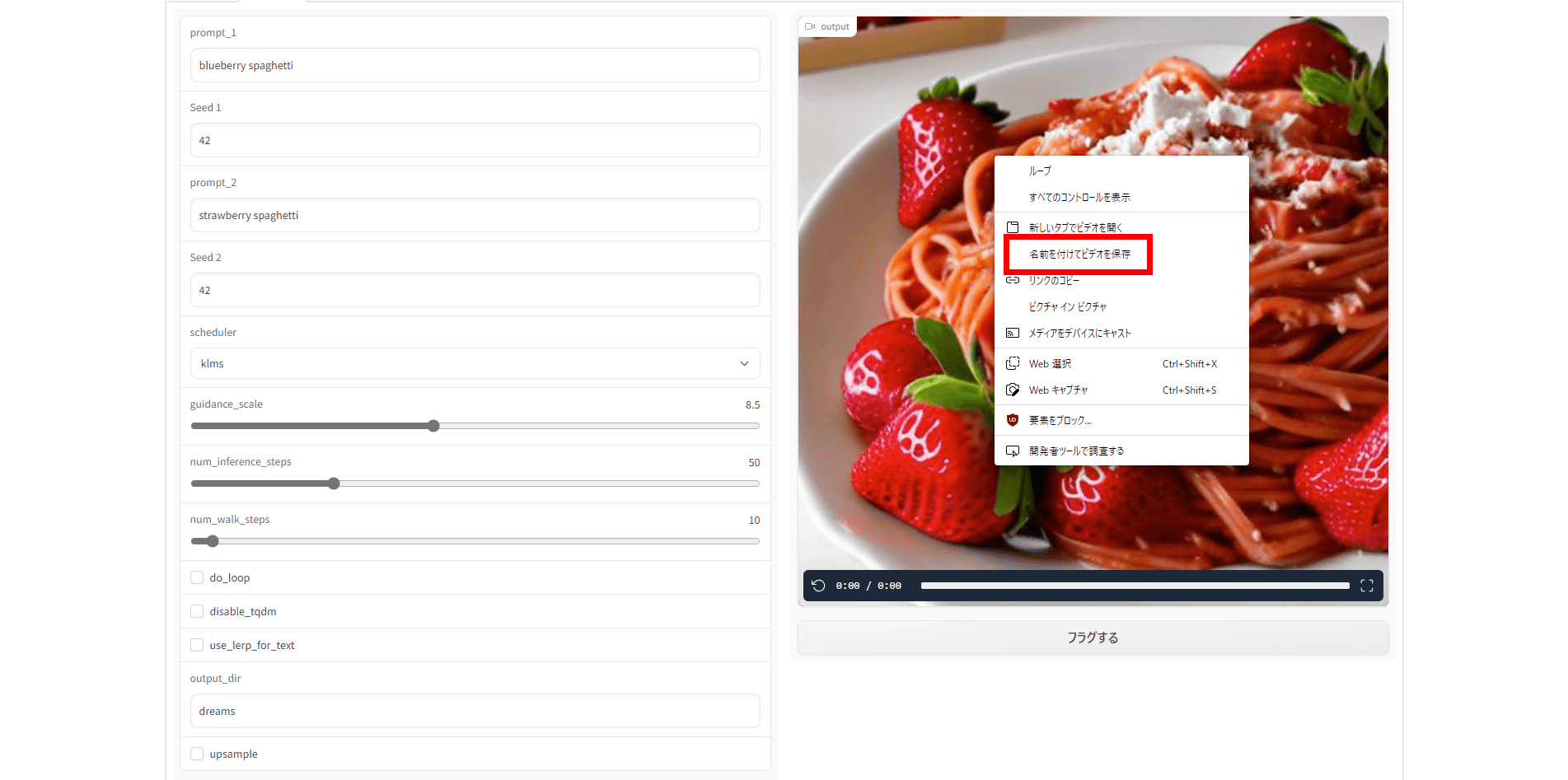
ムービーをローカルに保存したい時は、ムービーの上で右クリックをして、「名前を付けてビデオを保存」を選択すればOK。
今度はベートーヴェンからモーツァルトに顔が変わるムービーを作ってみました。prompt1を「beethoven」、prompt2を「mozart」、guidance_scaleを10に、num_inference_stepsを60に、num_walk_stepsを15に設定。

実際に作ってみた「ベートーヴェンからモーツァルトにモーフィングするムービー」が以下。ステップ数は合計30で、わずか1秒のムービーを作るのにかかった時間はおよそ3分弱でした。
画像生成AI「Stable Diffusion」でムービーが作れる「stable-diffusion-videos」でベートーヴェンからモーツァルトのモーフィングムービーを作ってみた - YouTube
・関連記事
画像生成AI「Stable Diffusion」を4GBのGPUでも動作OK&自分の絵柄を学習させるなどいろいろな機能を簡単にGoogle ColaboやWindowsで動かせる決定版「Stable Diffusion web UI(AUTOMATIC1111版)」インストール方法まとめ - GIGAZINE
画像生成AI「Stable Diffusion」で絵柄や構図はそのままで背景や続きを追加する「アウトペインティング」などimg2imgの各Script使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion」でイラストを描くのに特化したモデルデータ「Waifu-Diffusion」使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion」をGoogle Colaboratoryで動かして画像の保存先をGoogleドライブにする方法 - GIGAZINE
画像生成AI「Stable Diffusion」を使いこなすために知っておくと理解が進む「どうやって絵を描いているのか」をわかりやすく図解 - GIGAZINE
画像生成AI「DALL・E 2」で絵柄はそのままに背景や続きを追加する新機能「アウトペインティング」が登場 - GIGAZINE
・関連コンテンツ